
17 Nov 2025
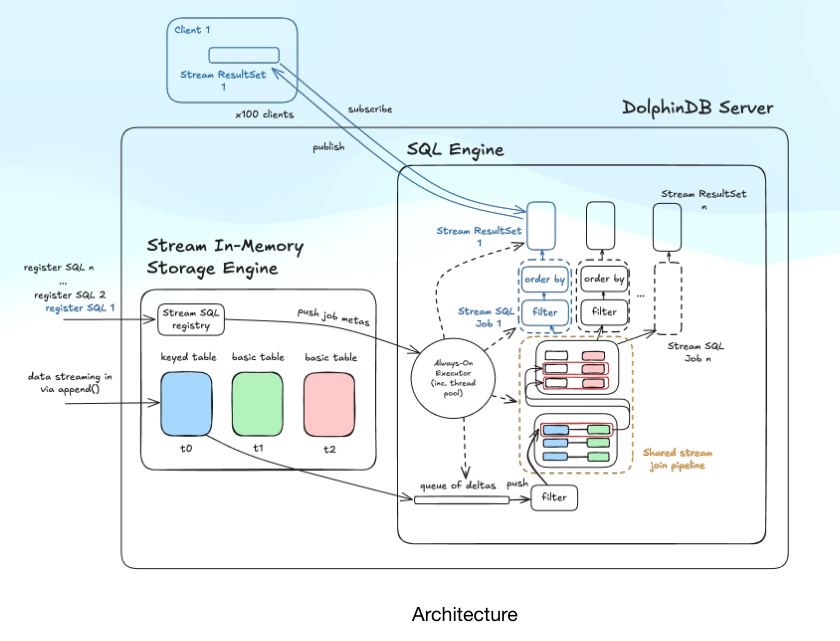
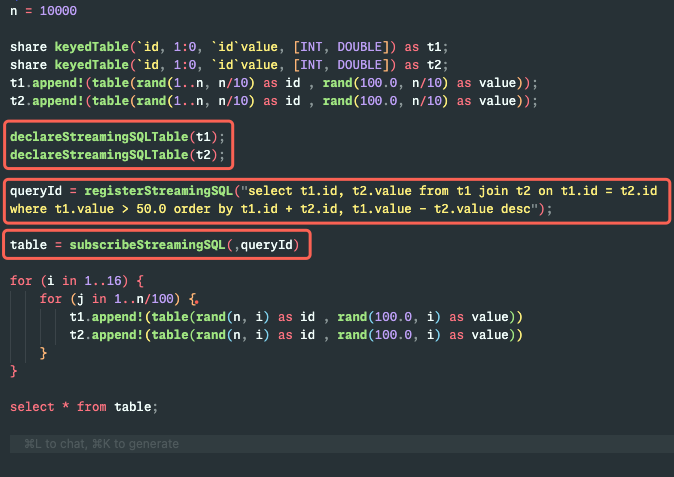
🧐Rerunning the same query for every user? Maintaining complex streaming pipelines by hand? DolphinDB Streaming SQL lets you write SQL once and receive live, incremental results as data changes.
medium.com/@DolphinDB_Inc/do…
Learn more and try it in the latest #DolphinDB release. dolphindb.com/product#downlo…
#StreamingSQL #TimeSeriesDatabase #RealTimeAnalytics #StreamProcessing #LowLatency #QuantTrading #DataEngineering
3
51

14 Aug 2025
What happens when Materialize R&D gets a day and a half to build whatever they want?
🔹WASM UDFs
🔹 S3-backed upsert
🔹 Formal verification
🔹 EXPLAIN ANALYZE (now live!)
All from our hackathon 🔗 bit.ly/4oGdXTu
#streamingSQL #databases #rustlang

3
262
8 Aug 2025
👏Just wrapped up the very first #DolphinDB Tech Deep Dive livestream! We spent an hour diving deep into streaming SQL — the tech that's making real-time, high-frequency data processing actually possible.
For everyone who joined live (and those catching up later), here's what we explored:
⚡ Our recipe for speed:
→ Process only new data (skip costly full scans)
→ Keep data hot in memory (no I/O bottlenecks)
→ Supercharge queries with hybrid indexing
✅ The numbers? We're talking 1,000 mixed operations per second with just 7ms from start to finish. That's the kind of speed that lets companies react to market changes, sensor data, or customer behavior in real-time.
👍Huge thanks to everyone who joined and brought such sharp questions — the Q&A was a highlight.
🔜 Next session: JIT-accelerated computation — you’ll want this on your calendar.
🌐 More info: dolphindb.com/
#RealTimeComputing #StreamingSQL #BigData #TechTalk #DataEngineering #JIT #FinTech #IoT #SmartManufacturing
1
5
34
5 Aug 2025
💭DolphinDB Tech Deep Dive | #1: Streaming SQL Processing
We’re excited to kick off our new “#DolphinDB Tech Deep Dive” series — a three-part tech talk designed to unpack the core technologies behind DolphinDB, built for high-performance real-time computing at scale.
In this series, we’ll explore:
1️⃣ Streaming SQL Processing
2️⃣ Just-In-Time (JIT) Compilation
3️⃣ GPU Acceleration
🔹 Episode 1 Details
🗓 Date: Thursday, August 7 | 7:30 PM (GMT 8)
🎙 Speaker: Dr. Xuntao Cheng, Deputy Director of R&D
Don't miss this opportunity to hear directly from our engineering team about the technical innovations driving real-time data processing.
📩 Register via email: info@dolphindb.com
🌐 More info: dolphindb.com/
#RealTimeComputing #StreamingSQL #BigData #TechTalk #DataEngineering #JIT #GPU #FinTech #IoT #SmartManufacturing

1
3
44

20 May 2025
Day 1 at #Current2025 ✅
“Batch to streaming, data integration & GenAI in real data platforms — hot topics for a reason.”
– @ESchmiegelow
We’re back tomorrow.
Come by the booth U1 — Kafka, Iceberg & real-time infra that works.
#Kafka #StreamingSQL #GenAI #HivemindTechnologies

1
2
94
20 May 2025
🚨 Today at #Current2025:
MASTERING STREAMING.
POWERING SIMPLICITY.
KAFKA AND BEYOND.
Come see us at the Hivemind booth — and let’s talk real-time data, GenAI, and scalable infrastructure.🗓
📍 Booth U1, 20–21 May
#Kafka #StreamingSQL #ApacheIceberg #GenAI #ModernDataStack

1
2
94

26 Dec 2023
Read most read article on PACMMOD, "What's the Difference? Incremental Processing with Change Queries in Snowflake" by Tyler Akidau, Paul Barbier, Istvan Cseri, Fabian Hueske, et al. bit.ly/47dX4Xa #datamanagement #streammanagement #streamingSQL #openaccess @SnowflakeDB

2
4
579

20 Nov 2023
What sets transactional apart from analytical stream processing?🎙️
Find out in Ep.32 of the Real-time Analytics Podcast, as @tlberglund shares his insights on #StreamingSQL, @ApachePinot, and @apachekafka
📺 YouTube: stree.ai/youtube
🎧 Podcast: stree.ai/podcast
1
3
665

5 Oct 2023
🔍 Diving Deeper into Caching & Computation Graphs! 🚀
When dealing with intricate computation graphs, the key lies in:
Granular Change Tracking: Using CDC, we can capture not just that a change occurred, but specifically what changed. This granularity is pivotal for dependency management.
Real-time Dependency Management with Streaming SQL: Modern streaming SQL platforms allow for on-the-fly data processing. As CDC captures changes, they're fed into these platforms. By implementing logic within our streaming SQL, we can track which parts of our computation graph are affected by a change.
Scoped Memoization: Store intermediate computations and, when a change occurs, recompute only the affected parts of the graph. Efficiency at its best!
In essence, combining CDC's detailed change tracking with the real-time processing capabilities of streaming SQL provides a robust solution to the challenges of caching in complex computation environments.
#Caching #CDC #StreamingSQL #DataManagement
4
154

I just started a new YouTube series `Learn Streaming SQL in 3 min` youtube.com/playlist?list=PL… For anyone wants to get started with #datastreaming and #streamingsql or just #realtime #dataprocessing, hopefully you can learn something new(and useful) in each 3min short video
3
146

2 Aug 2023
1/ We're back with a new post in our #streamingSQL series, this time exploring the Sliding Window Hash Join (SWHJ) algorithm. Shout out to @ApacheArrow and #DataFusion for providing us a great foundation on which we built our implementation.
synnada.medium.com/the-slidi…
1
13
29
5,409

7 Sep 2022
In this article, we compare running the same job in Flink's Datastream and Table APIs and discuss how the job's performance differs depending on the chosen API.
Follow us in this journey of beating #FlinkSQL's performance 👇
bit.ly/3wfwL2a
#SQL #streamingSQL
2

2 Aug 2022
if you are remotely working on #datastreaming , you don't want to miss this talk by Hojjat Jafarpour, founder and CEO of DeltaStream.io. @DeltaStreamInc
#kafka #kinesis #flinkforward #flink #streamingsql #streamingdatabase #deltastream
2 Aug 2022

If you are attending #FlinkForward tomorrow and are interested in streaming SQL don't miss my talk.
#FlinkForward #eventstreaming #RealTime @DeltaStreamInc

2

29 Jul 2022
You know T-SQL? Then you're ready for stream processing with #AzureStreamAnalytics - Ok there's a thing or 2 more to know but the good thing is I'm going over it on Sept 23 at @dataaisummit - and it's free! dataplatformgeeks.com/dps202… @AzureStreaming #Azure #StreamingSQL

4
2
20 May 2022
This articles showcases how you can build real-time applications with Flink #SQL and the use of MATCH_RECOGNIZE without touching a line of Java or Scala code
Find out more 👇
bit.ly/3lbSPVB
#ApacheFlink #FlinkSQL #streamingSQL
1
2

22 Mar 2022
We the use of #FlinkSQL, we perform #realtimeanalytics on Apache Flink’s very own git repository.
Follow the article below and learn how to do that with the use of #UDFs in Ververica Platform: bit.ly/3CJqvSp
#SQL #streamingSQL
2
4
9 Feb 2022
Using an ad tech #usecase, we showcase how you can leverage #FlinkSQL to build a monitoring system for the advertising industry.
Check the details: bit.ly/3ouKdve
#SQL #streamingSQL #realtimedata
1
2

3 Feb 2022
Throwback to #flinkforward Global 2021 when Olena Babenko from @aiven_io discussed how #FlinkSQL can be used for both one-off analysis and for streaming #datapipelines.
Check the recording: bit.ly/3KXKb8B
#SQL #streamingSQL
6
18 Jan 2022
📺 🎧 Listen to our very own @MartijnVisser82 explaining how #dataanalysts can use Flink #SQL to explore and transform data into insights and actions, without writing any Java or Python code in this #flinkforward talk: bit.ly/3fl5OBi
#streamingSQL #FlinkSQL #ApacheFlink
4