
AI Research @ ellamind
Joined January 2017
- Tweets 66
- Following 780
- Followers 102
- Likes 345
11 Photos and videos





Base checkpoint 10,000 lands. Within minutes, forward passes stream the Tier-0 suite; per-domain fitted curves update; the slope monitor flags that the recovery-margin trajectory on the agentic precursor benchmark family is diverging from the sibling run with the alternate code mix. The dashboard doesn't say "MMLU 83.1"; it says "predicted post-probe SWE-style outcome: 41% ± 4.1, up 2.6 from last week, driven by the world-model axis". The data mixing agent picks up on the result. It submits a new sibling run to the queue, eager to continue the hillclimb.
1
32
Great to see a tech report with some details on data. Even better to see propella being put to good use
May 26

Today we’re publishing the technical report behind Laguna M.1 and Laguna XS.2.
This report opens up more of what went into them: Model Factory, pre-training data, distributed training, post-training, agent RL, quantization, and evaluation.
poolside.ai/assets/laguna/la…

12
1,479
Max Idahl retweeted

May 4
Huge news: @prior_labs has signed a definitive agreement to be acquired by @SAP.
€1B invested over four years to build a globally-leading frontier AI lab for structured data — in Europe, in the open.
Independent entity. Same team, same mission, same open models. A massive boost to what we can do. The mission just got accelerated.
Founders’ statement: priorlabs.ai/blog-posts/prio…
(Deal subject to regulatory approval; terms not disclosed.)
36
32
510
51,733
Going up the stairs to Christo redentor the day before @iclr_conf, everyone talks about GPU clusters
2
77
Just landed in Rio. A few days early to clear the head before @iclr_conf . Ping me if you want to chat about agents, evals, data, or to get out for some hiking/sightseeing
1
81
Find me here today.

GPU MODE (@GPU_MODE) & PyTorch Foundation are organizing an ML systems hackathon in Paris on April 9, immediately following PyTorch Conference Europe 2026.
Researchers and engineers will compete across two tracks:
-Distributed training (LLM speedrun) and inference optimization (leaderboard)
- Access to a B300 cluster from Verda and H200 instances from Sesterce
- Cloud credits as prizes, including 48-hour access to a GB300 NVL72 rack
- Talks from PyTorch (Helion), vLLM, Prime Intellect, and more
- Food and refreshments
Doors open at 9:30, with the closing ceremony at 20:00. Attendees can join with a pre-formed team or match on-site. Location details are shared upon registration.
Spots are limited. Register: luma.com/gpu-mode-paris-2026
#OpenSourceAI #PyTorchCon #PyTorch #vLLM #Helion

92
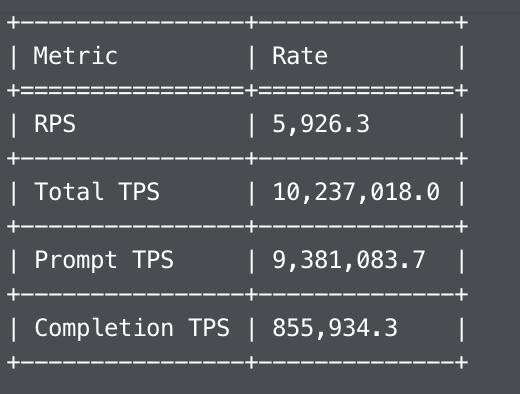
This cluster is great. Loads 1T Kimi-K2 from disk to GPU in 108 secs. 512 GPU job, no crash ~5 days in.
4 Nov 2025

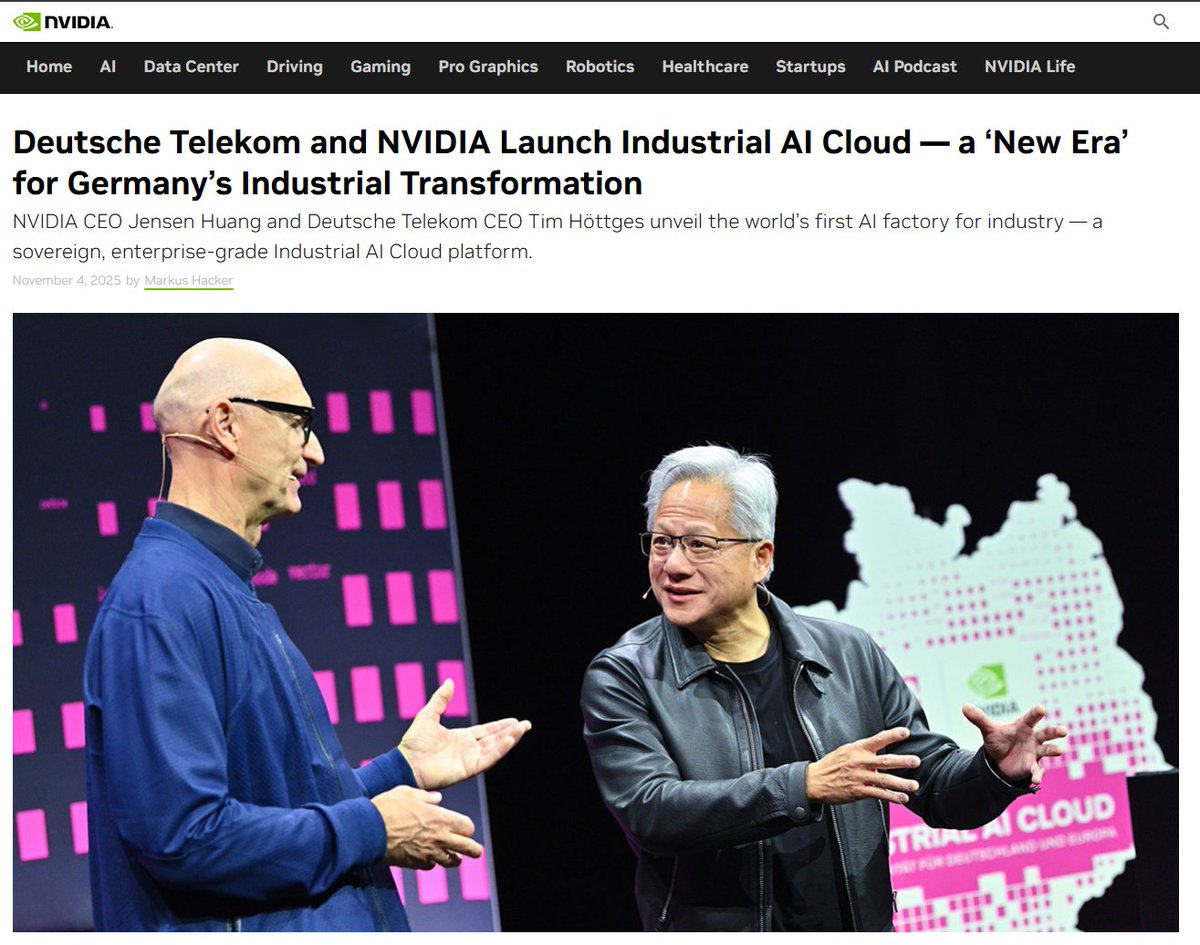
Telekom and NVIDIA building a $1.1B datacenter in Munich with 10k GPUs including DGX B200 and RTX PRO Servers
7
729
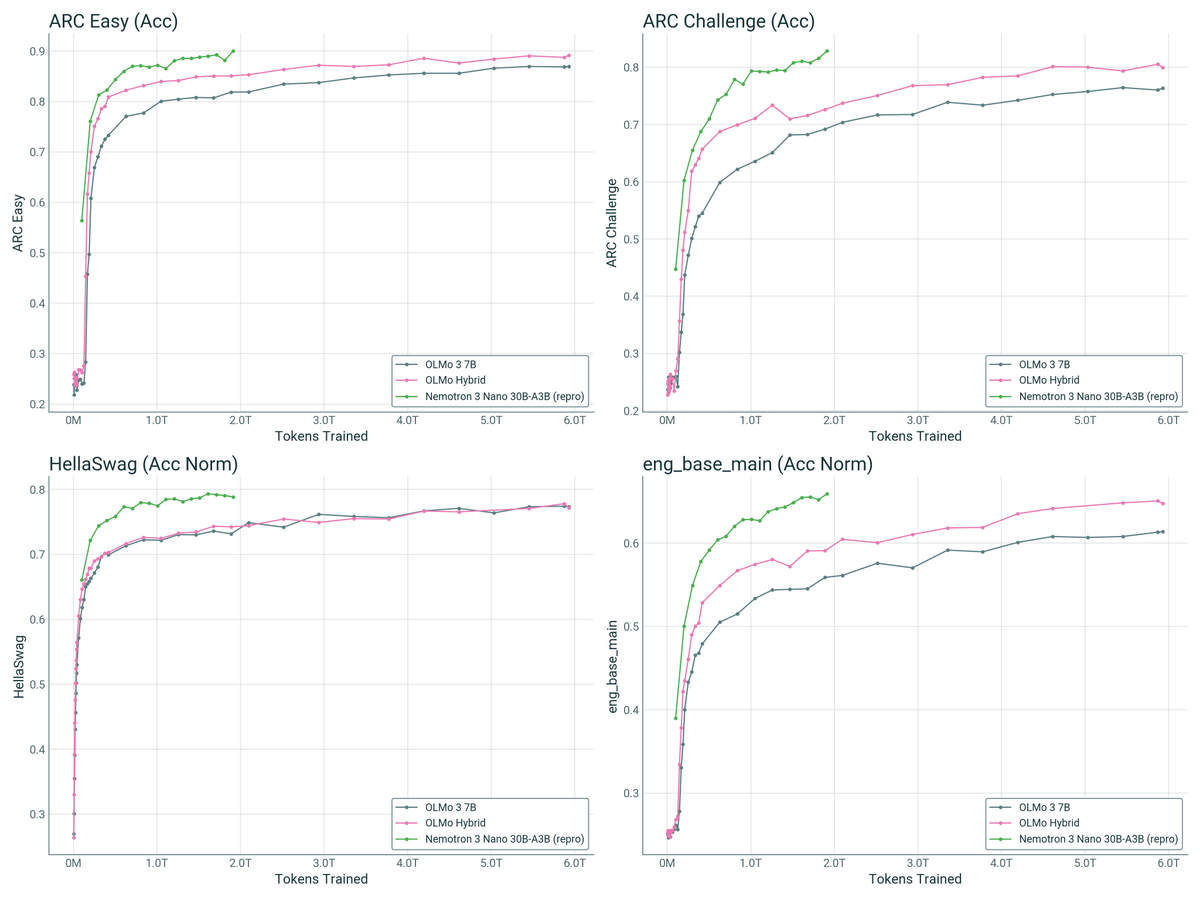
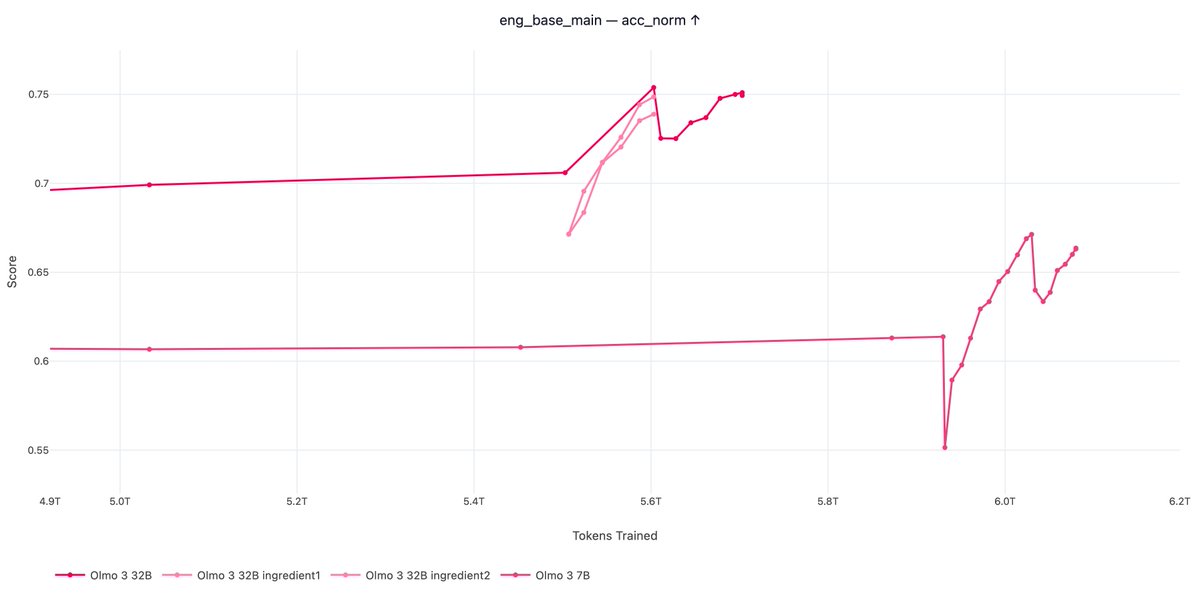
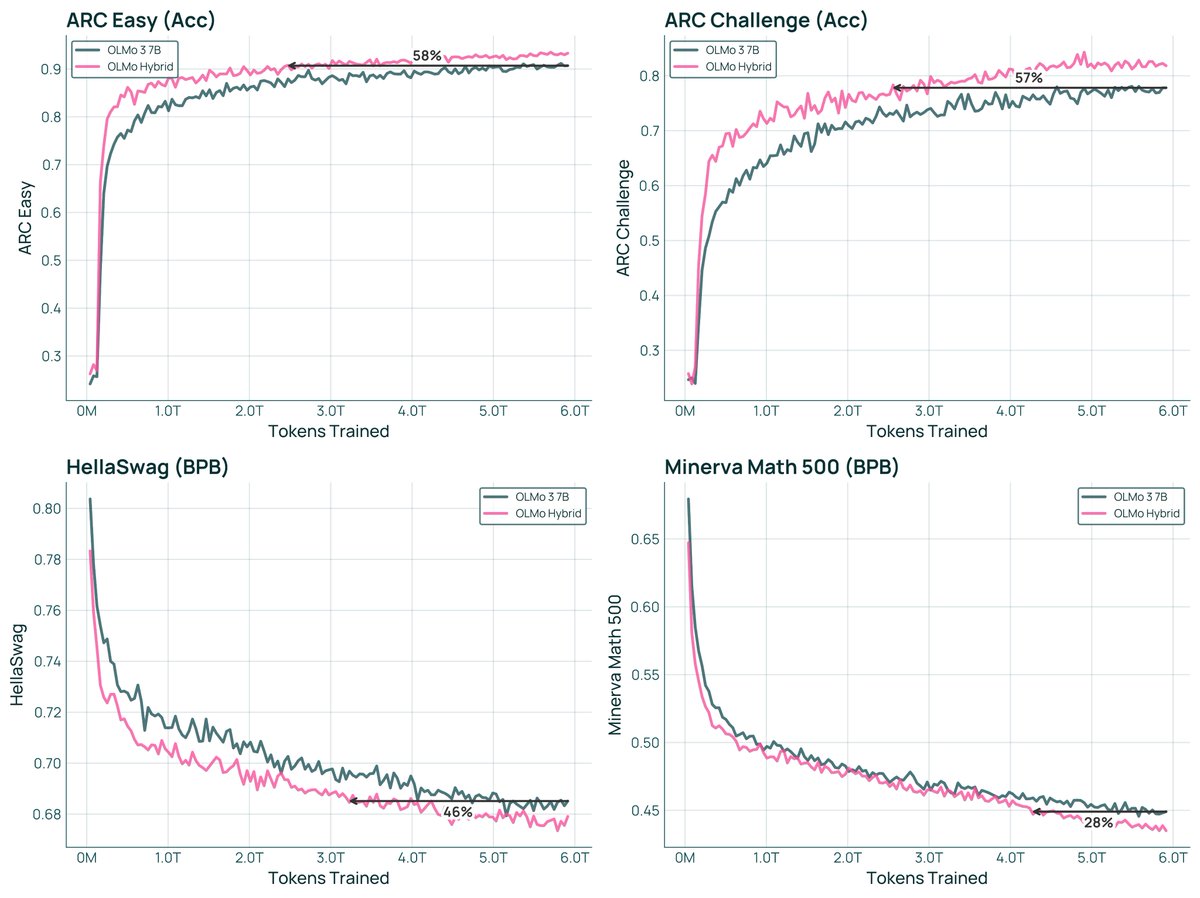
Joe Nemotron also has a pretty good compute multiplier it seems.
Mar 5

This plot undersells how much of a compute multiplier Olmo Hybrid is: 2x compute multiplier on many downstream tasks (and solid LC performance!!!)
2
1
9
1,257
Note that these are not official nemotron checkpoints, but independent reproduction. More on that later. Maybe we could get some official base model checkpoints? Even just a few would be great for comparison
@llm_wizard
1
1
90
Max Idahl retweeted

Mar 20
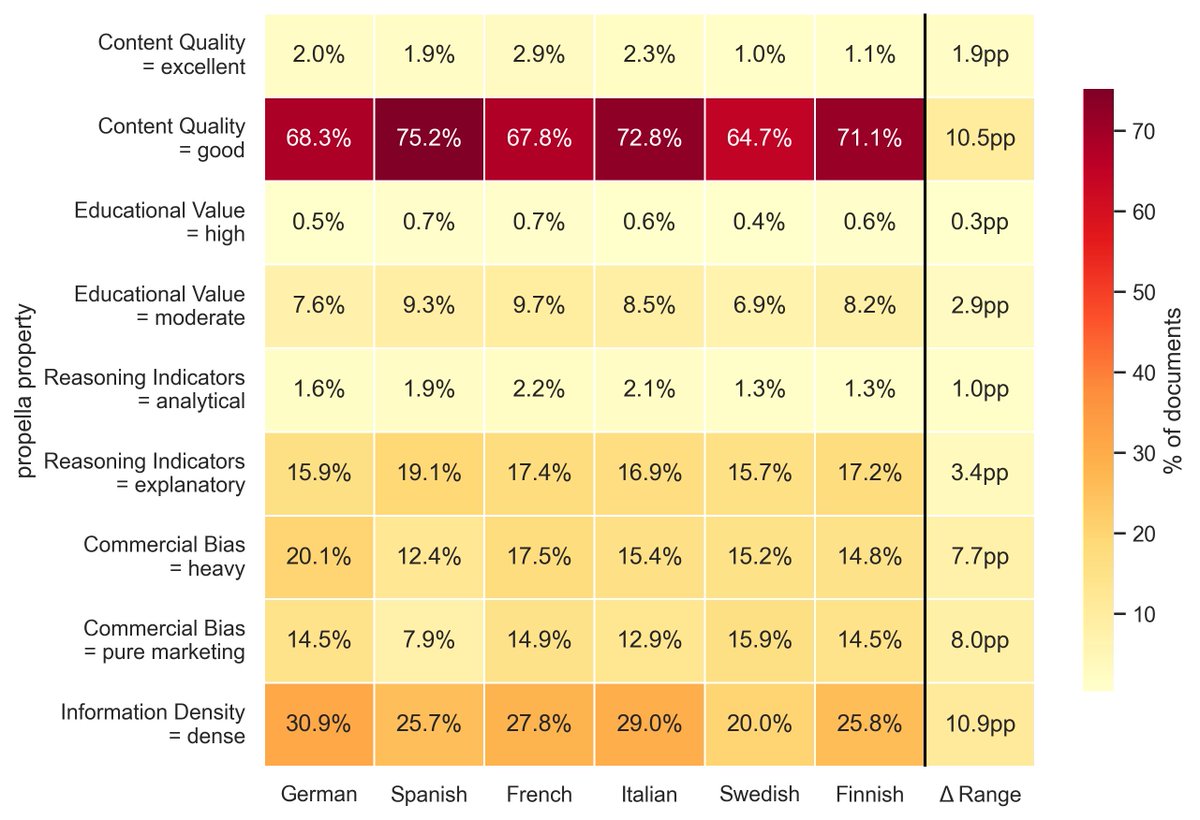
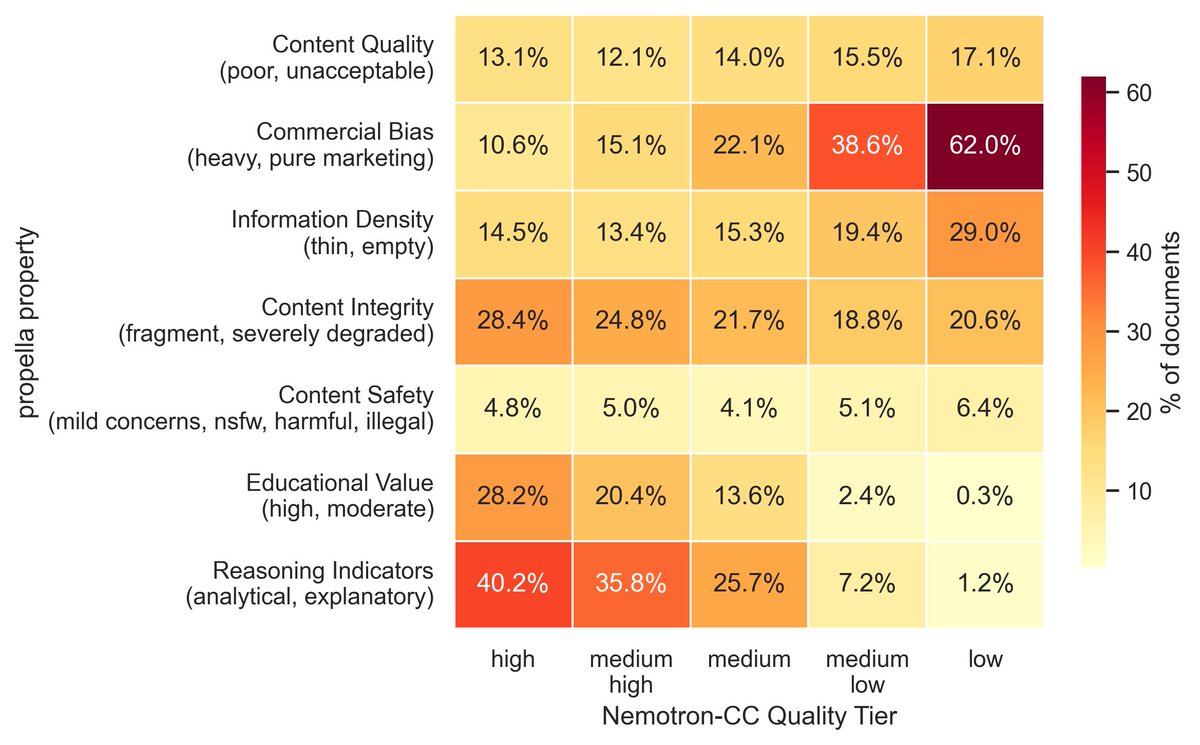
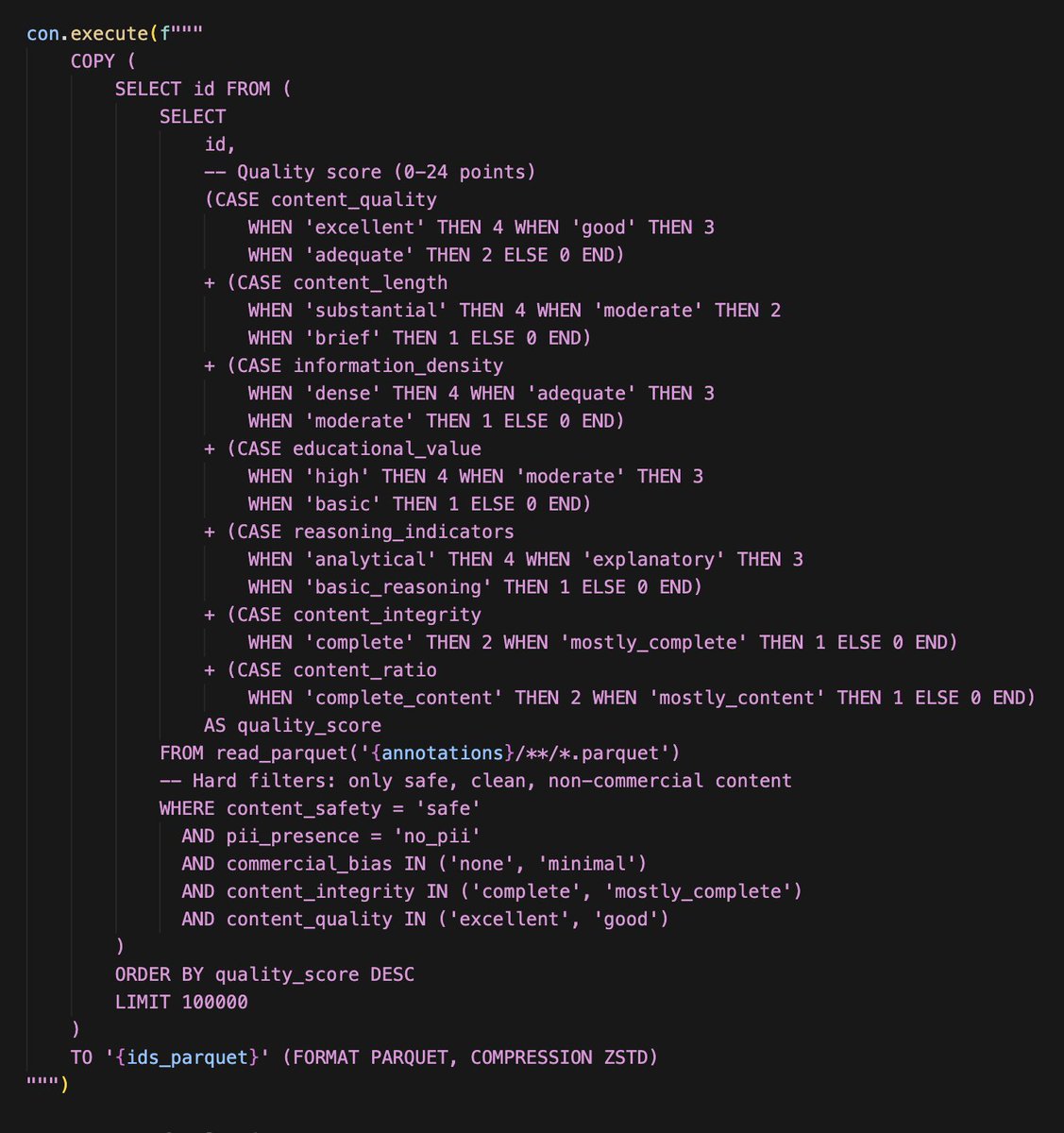
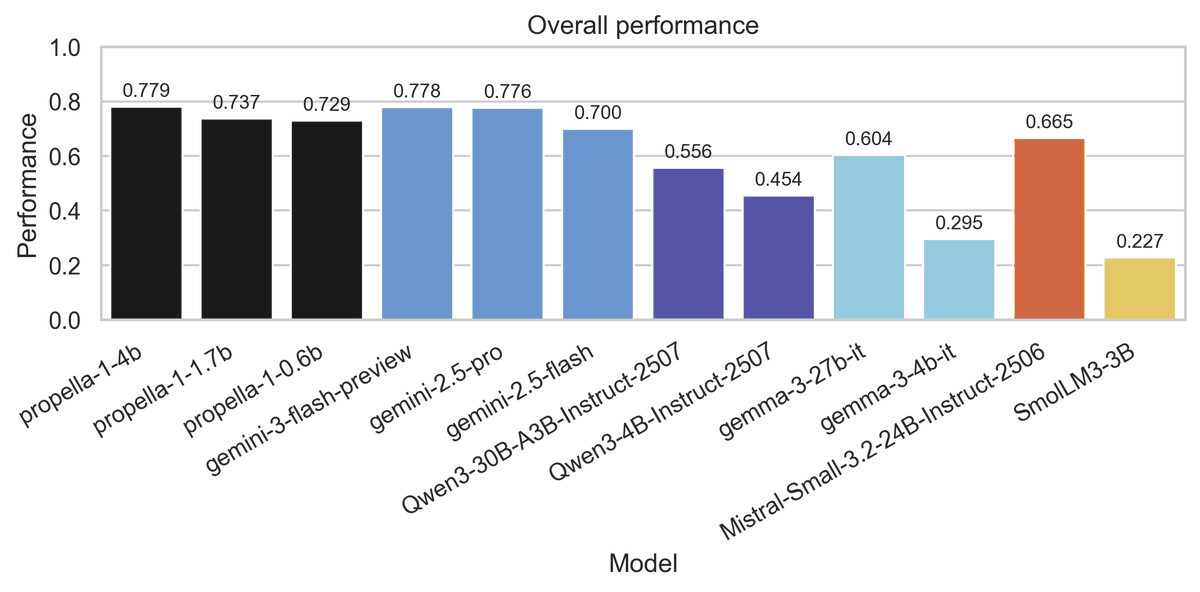
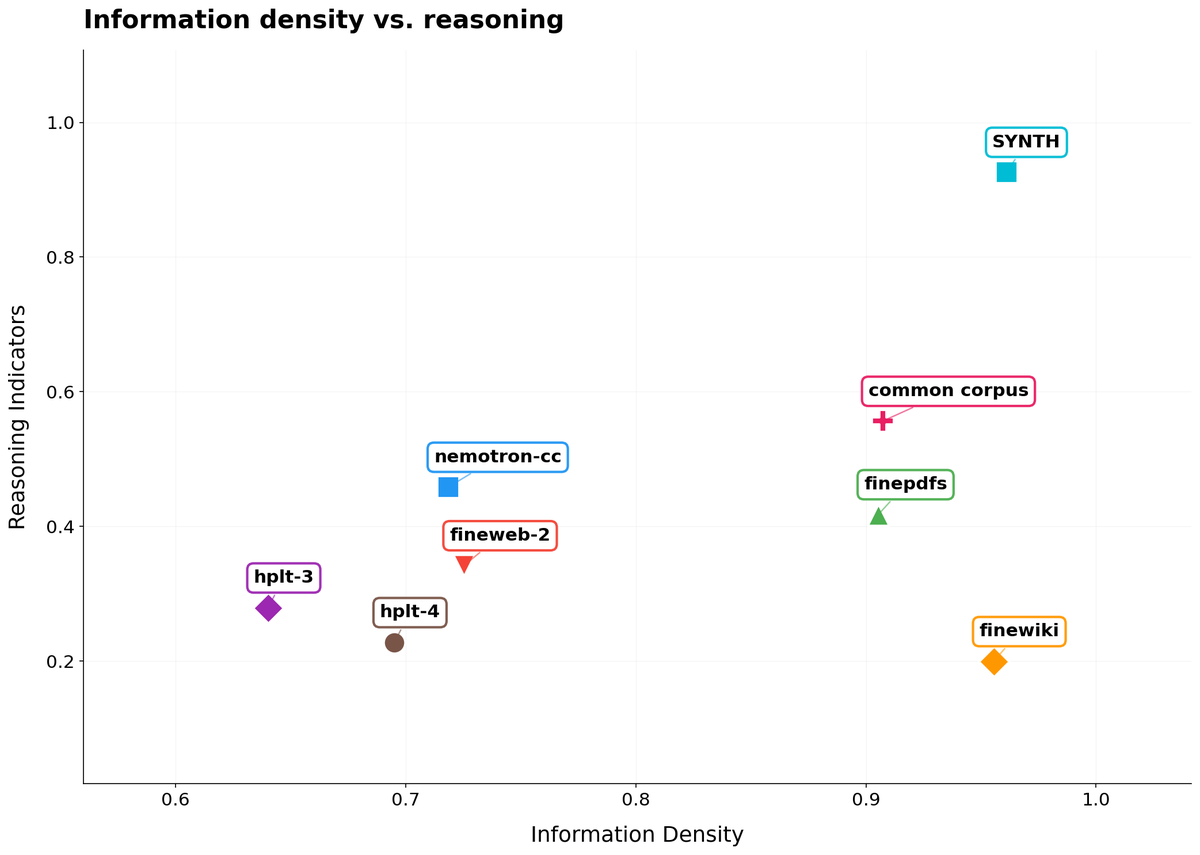
Actually we have started to use Propella internally to curate common corpus subcollections and run comparisons with other pretraining dataset. Really filling a missing piece of training/synthetic infra in Europe. huggingface.co/ellamind/prop…
Mar 20

Great annotation work from @ellamindAI / OpenEuroLLM on French-Science-Commons less than 24 hours after release!
3
6
44
3,556
Annotations are already available. Looks to be very good data. Now go ahead and curate the best seed docs for synth data.
Mar 19
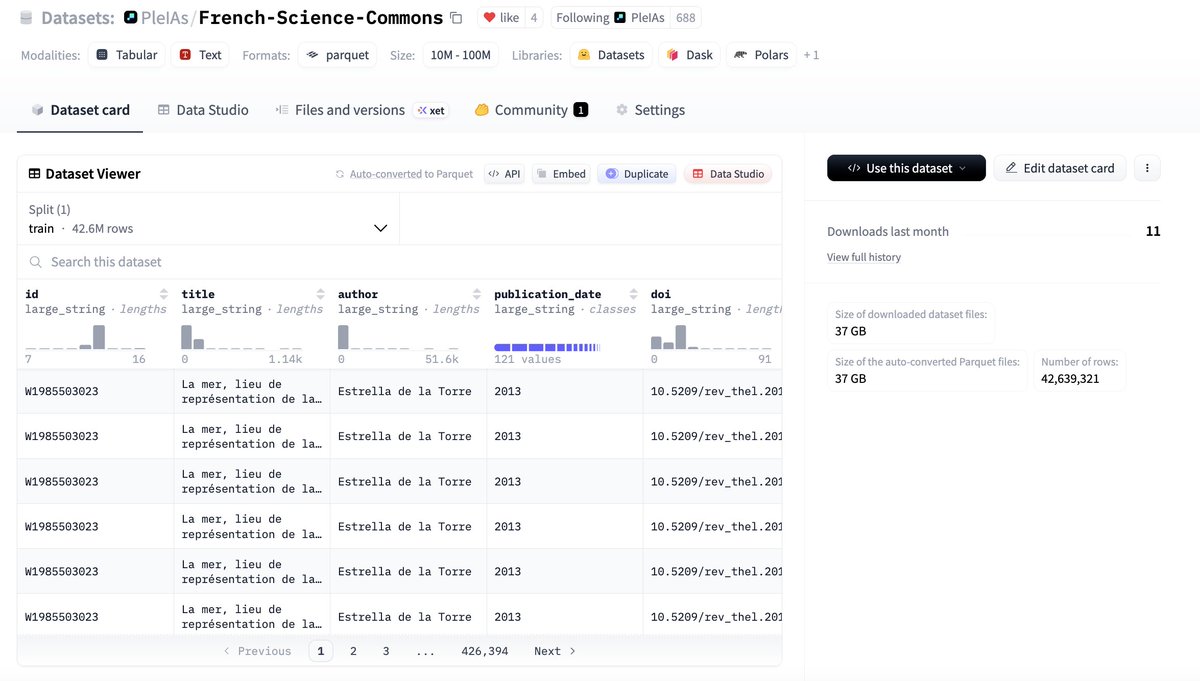
And new data release: French-Science-Commons, the largest scientific corpus in French in open access including 1.25 million documents/42 million pages re-digitized with VLM (dots ocr).
1
5
2,187
Annotations on @huggingface: hf.co/datasets/openeurollm/p…
Could maybe be useful for the exploration tool at french-science-commons.pleia…
@Dorialexander ?
2
91