
We build models for agentic coding and long-horizon tasks. Try Laguna: poolside.ai/get-started
Joined May 2023
- Tweets 117
- Following 2
- Followers 6,363
- Likes 426
37 Photos and videos









Pinned Tweet

18h
As AI becomes more capable, the question is not only who builds the best models.
It is who gets to build them at all.
A founder’s view from @eisokant on where Poolside stands today.

4
28
2,619
Jun 8
another banger from @pupposandro and the @luceboxai team
Luce Spark runs Laguna XS.2 in 14.6 GiB at ~100 tok/s on an RTX 3090, versus ~119 tok/s fully resident.
you can now run Laguna below the 16 GiB line and use it for local evals, agent traces, routing analysis, quantization, and serving experiments.
Jun 8

Excited to launch Luce Spark: now a 35B MoE runs on a 16GB GPU, with no offload tax.
An A3B model fires ~8 of its 256 experts per token, but to keep it resident you pay VRAM for all 256. Spark pins the experts your traffic actually hits, offloads the rest to CPU, and decodes the whole token in one fused graph, so offload stops costing speed.
▸ Qwen3.6 35B-A3B: ~20.5 → 13.3 GiB
▸ Laguna XS.2 33B-A3B: 18.8 → 14.6 GiB
Decode holds ~100 tok/s, close to the 119 you get with every expert resident on a 24 GB card. No calibration step. It tunes itself from live traffic.
5
11
43
3,989
Poolside retweeted

Jun 6
Just finished reading the latest technical report released by @poolsideai for Laguna. It is so well written and information-dense, covering all stages of a large-scale training run. Each decision and assumption was clearly explained and concisely referenced.
The Model Factory was a very interesting piece, describing how they turned the whole pipeline of training, checkpointing, ablating, and data versioning into an industrial process. This made it easier for researchers to focus on coming up with hypotheses and testing them. My favourite sections were the Model Factory, Data Versioning, and the infrastructure setup (i really love the DevOps stuff). What did you guys like?


7
4
108
7,922
Jun 3
those GPUs are waiting
go build something fun with Laguna XS.2!

This month, Poolside’s Laguna XS.2 is free to train on Prime Intellect Lab. First come, first serve while reserved capacity lasts.
1
36
3,735
Jun 2
Love seeing the work @RedHat_AI and @vllm_project are doing to make Laguna XS.2 easier to run.
Red Hat AI trained a DFlash speculator: a 0.6B drafter that predicts 8 tokens per pass, with Laguna verifying the output.
So builders get faster generation without changing output quality.
With vLLM support and FP8/NVFP4/INT4 checkpoints through LLM Compressor, it’s also easier to tune for different latency, memory, and hardware constraints.
Grateful for the team building the infra that makes open models easier to use, serve, and improve!
May 30

Laguna XS.2 from @poolsideai is a 33B MoE built for agentic coding.
Red Hat AI trained a DFlash speculator for it: 0.6B drafter, 8 tokens per pass, no quality loss.
FP8, NVFP4, and INT4 checkpoints via LLM Compressor.
Models in comments. Speedup with @vllm_project:
2
4
26
2,517
Poolside retweeted

Super comprehensive writeup that covers many frameworks & case studies on async RL. I learned a lot from the discussion of adding bias to the objective and how techniques that introduce bias (e.g., TIS CISPO) help stabilize smaller batches but scale more poorly.
Jun 1

New blog! Is frontier asynchronous RL solved?
The blog covers Async RL theory and infrastructure, surveying 8 open-weight frontier labs for the algorithmic techniques and systems fixes to handle train-inference mismatch. Also answered: why do current methods still fail at high policy lag? Which methods scale with horizon and compute?

5
3
57
11,600
May 31
London raised the bar. SF, gear up 👀
May 31

The level of the @poolsideai hackathon in London was higher than the average in SF.
We tried distilling Laguna XS.2 into a dense model. A ~11x parameter reduction from 33B to 3B.
huggingface.co/poolside-lagu…
Many thanks to the organizers @poolsideai @eloquake @Badiaserra



1
29
4,137
Poolside retweeted

May 31
this week I was at the @poolsideai talk hosted by @CrusoeAI and heard @varunrandery discuss what he calls the "agent API."
tldr; we stop sending text and getting text back, and start sending a unit of work and getting the finished result back, technically it's clean, and I liked it.
then I thought about it longer and started to wonder what's left for the rest of us to build, and what it means for SaaS more broadly.
wrote it up: dennisy.me/notes/from-chat-c…
2
4
587
May 30
What a weekend. Around 30 teams showed up to build on Laguna XS.2, and the bar was very, very high.
Winners below 🏆
1st: Overthinking Machines Labs
@emilfristed
Pseudo-full-duplex with text-only models through dialogue modeling with silence tokens.
huggingface.co/spaces/poolsi…
2nd: Coding Kernels by the Pool
Charlie Masters, Evan O’Leary, Jessica Mak
Laguna-Dense: a ~3B fully dense distillation of Laguna XS.2 for generating CUDA kernels from PyTorch.
huggingface.co/EvanOLeary/la…
3rd: attnvq
@alaradirik
Attention-aware product vector quantization of KV caches.
huggingface.co/spaces/adirik…
Honorary mention: Laguna Vision
Aaron Kazah @aaronkazah
A SigLIP vision encoder resampler LoRA adapters, trained on 300k examples to give Laguna XS.2 a native visual input path.
huggingface.co/poolside-lagu…
Huge congrats to the winners, and thank you to everyone who hacked, demoed, judged, helped, and pushed Laguna XS.2 in directions we would not have found on our own!
@nvidia @PrimeIntellect @adaption_ai @huggingface



7
14
101
21,390
May 29
London cookers are taking Laguna XS.2 to the moon 🚀
Huge shout to @PrimeIntellect @nvidia @huggingface @adaption_ai for making this possible!
May 29

Full house at the @poolsideai London office today for our first Research Hackathon💚
So excited to see what people do with Laguna XS.2 🚀🏖️




4
6
55
6,554

Loving the @latentspacepod breakdown of our Laguna M.1/XS.2 Technical Report! The Latent Space paper club just did a deep dive, and their takeaways perfectly capture what we set out to build with our Model Factory. A few quotes from the video 🧵👇 (1/6)
youtu.be/QLfZamyMls0
1
8
47
10,988
May 28
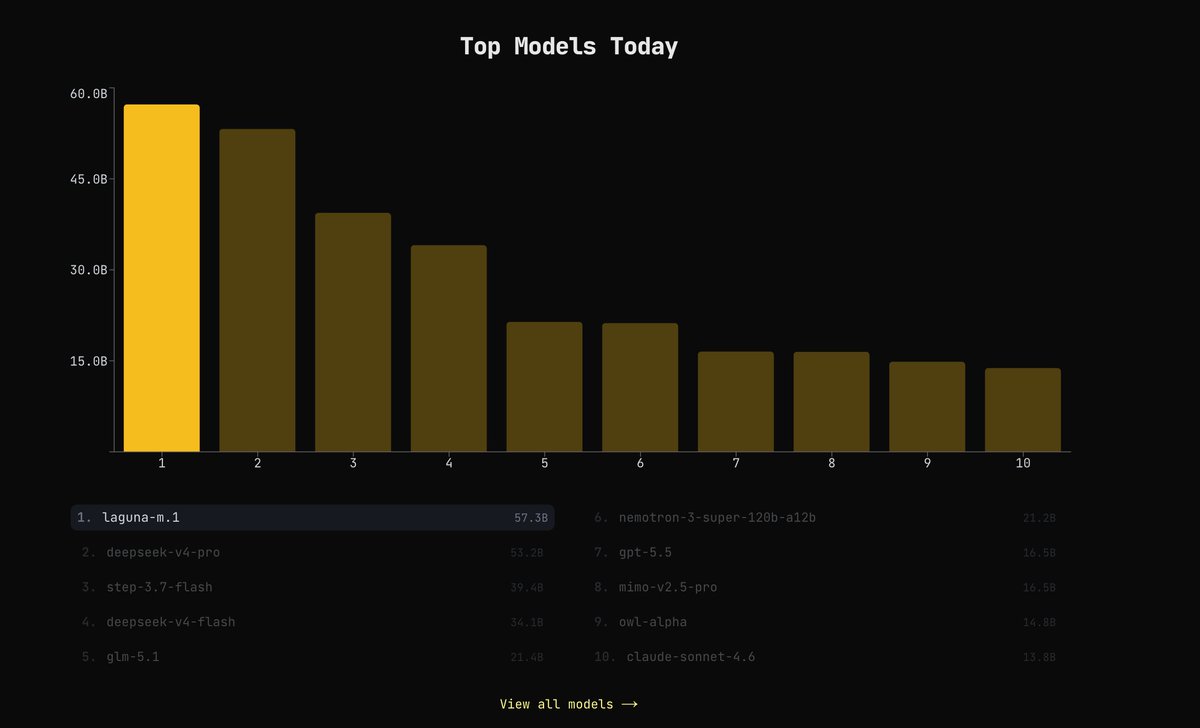
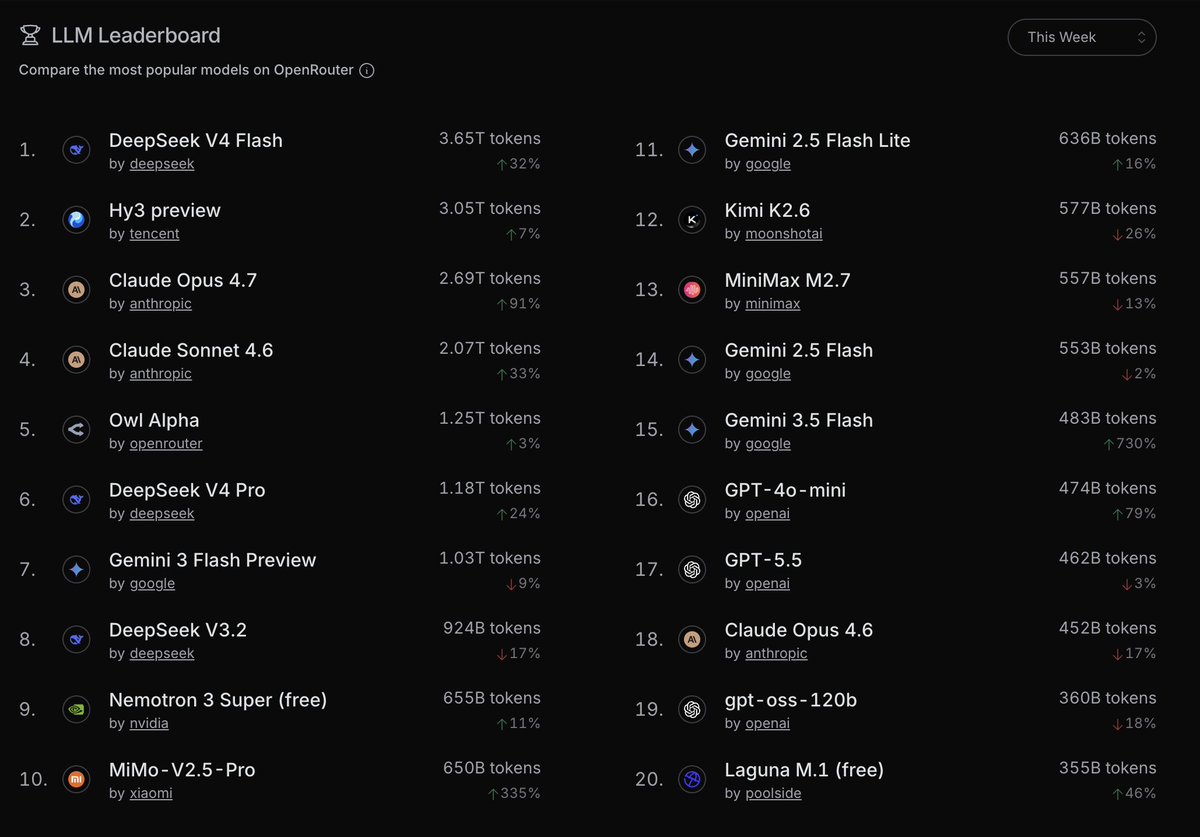
Laguna M.1 is now top 20 on @OpenRouter by weekly tokens served.
Please keep on cooking.
7
37
2,005
May 28
If you’re in London tonight, come hear @varunrandery at @CrusoeAI Talks!
He’ll unpack harnesses, agent APIs, and the blurring boundaries between models, tools, and products.
May 28

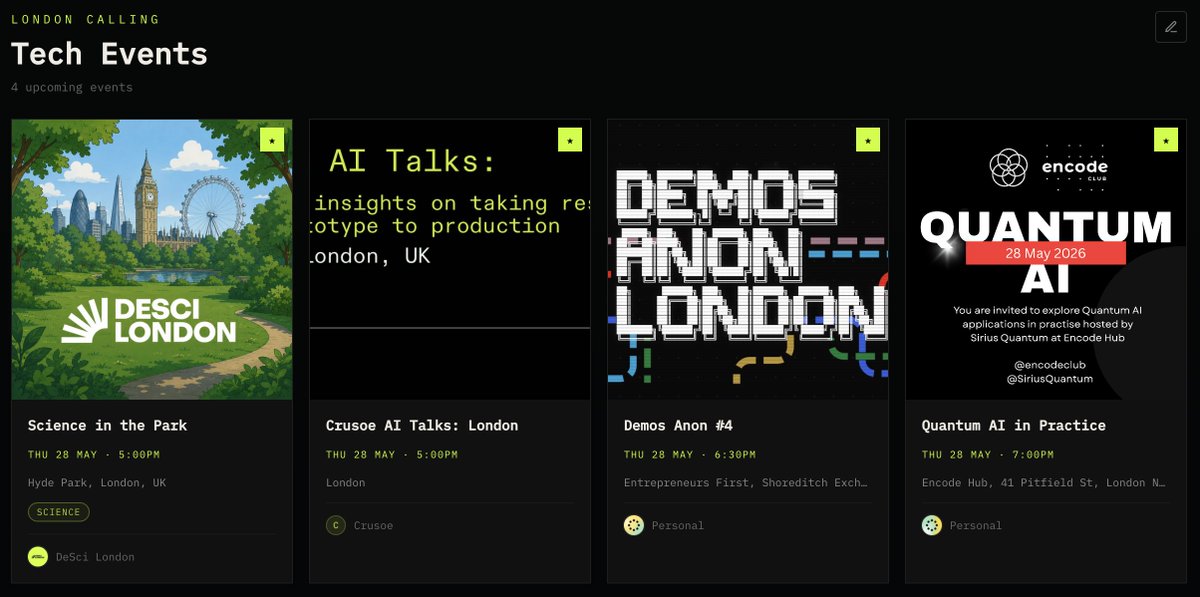
Turned into a busy thursday today!!!
you'll catch me in sunny Hyde Park at the @DesciLondon picnic.
But you can get technical with @CrusoeAI and @nvidia & @poolsideai before their hack this weekend
or watch some cool demos from @LynettaWang126 & @Tomasmrky at @join_ef
or dive into the weeds of quantum AI with @SiriusQuantum at @encodeclub (rumour has it there might be a members rooftop party as well 👀)
find them all on londoncalling [dot] guide
3
18
1,531
May 27
Honored to be included in @Redpoint 2026 InfraRed 100, recognizing the companies shaping the future of infrastructure and AI.
Congratulations to all the companies featured this year!

The Redpoint InfraRed 100 is now live.
These are the companies building the infrastructure that powers everything happening in AI right now, from world models and agent runtimes to the sandboxes, databases, and security tools agents depend on.
Congratulations to this year's honorees!
Read the full 2026 InfraRed Report: our state of the union on AI and cloud infrastructure 👉 redpoint.com/reports/the-inf…

1
1
32
2,484
May 26
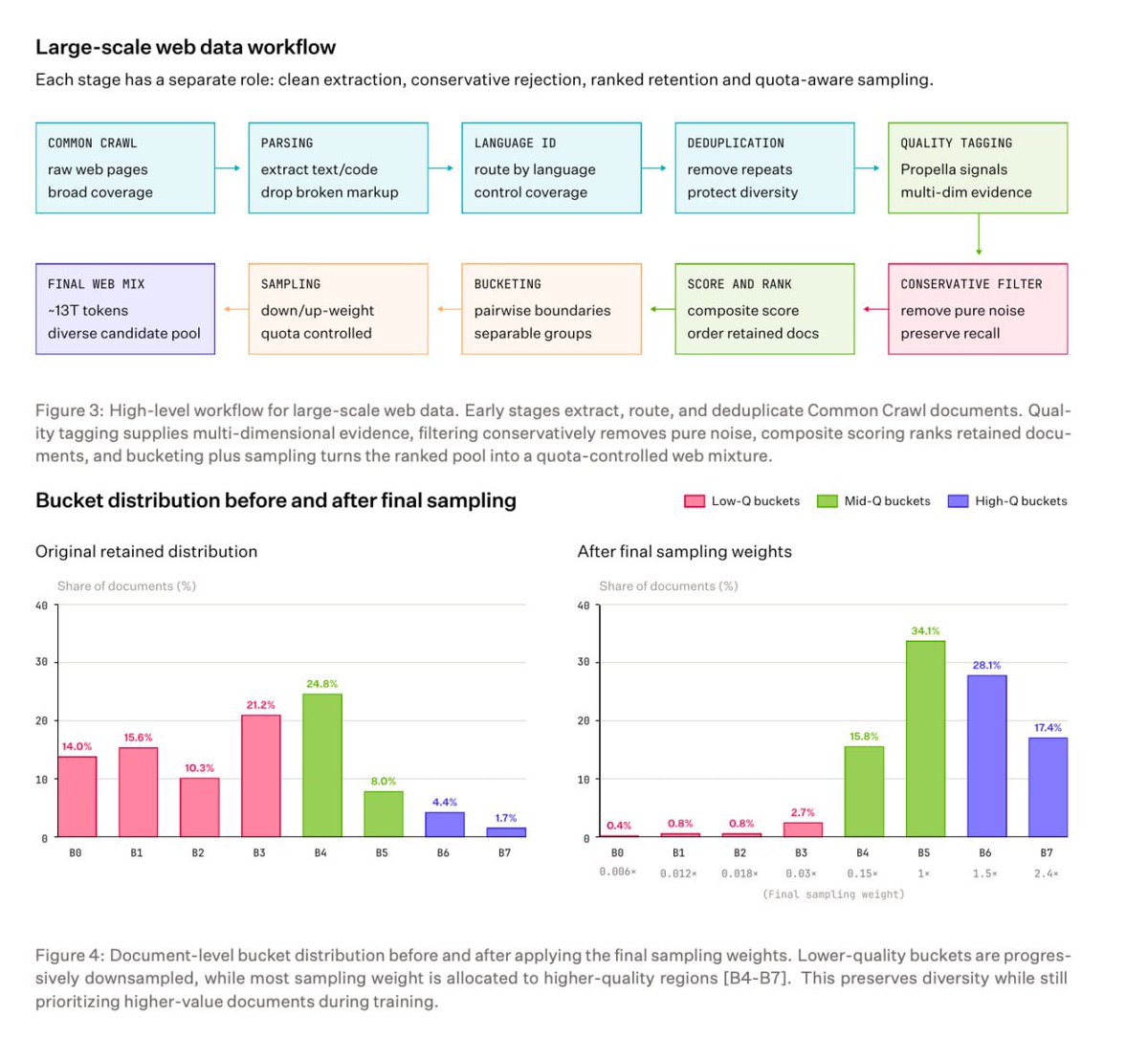
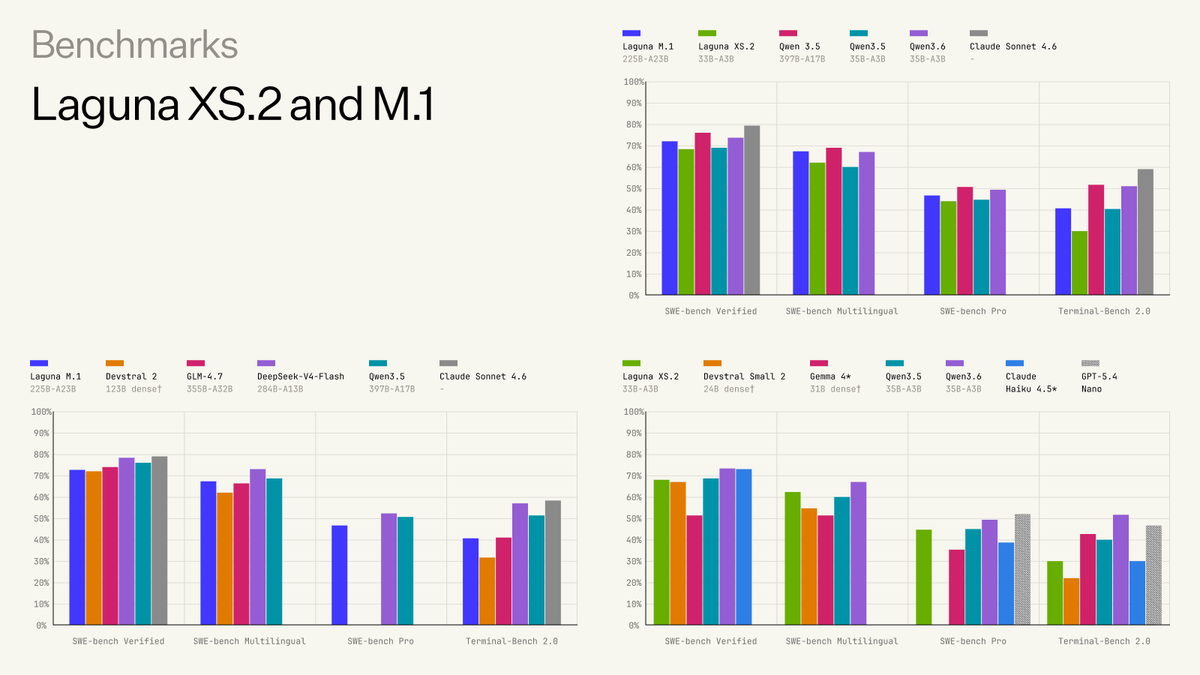
Today we’re publishing the technical report behind Laguna M.1 and Laguna XS.2.
This report opens up more of what went into them: Model Factory, pre-training data, distributed training, post-training, agent RL, quantization, and evaluation.
poolside.ai/assets/laguna/la…
15
87
423
304,923
May 26
Laguna M.1 and XS.2 now support 256K context.
Laguna M.1 is now live with a 256K context window on the Poolside API and OpenRouter.
With this update, it reaches 45.8% on Terminal-Bench 2.0, improving long-horizon performance.
Laguna XS.2 is also moving to 256K today, with the updated config already available on Hugging Face.
Both models remain free to use.
Over 1T tokens have been processed since launch 4 weeks ago. Excited to see what people build with the longer context window.
4
17
78
6,995
May 26
Get started immediately:
Blog: poolside.ai/blog/long-contex…
Hugging Face: huggingface.co/poolside/Lagu…
Poolside API: platform.poolside.ai
OpenRouter: openrouter.ai/poolside/lagun…
pool: github.com/poolsideai/pool
Shimmer: shimmer.run
1
6
829