
AI Research Scientist @Meta FAIR. Prev. ELLIS PhD Student @ JKU Linz & PhD Researcher @nx_ai_com, Research Scientist Intern @Meta FAIR
Joined June 2021
- Tweets 309
- Following 869
- Followers 1,170
- Likes 966
49 Photos and videos






Pinned Tweet

19 Mar 2025
Yesterday, we shared the details on our xLSTM 7B architecture. Now, let's go one level deeper🧑🔧
We introduce
⚡️Tiled Flash Linear Attention (TFLA), ⚡️
A new kernel algorithm for the mLSTM and other Linear Attention variants with Gating.
We find TFLA is really fast!
🧵(1/11)

3
59
344
47,947
Maximilian Beck retweeted

New paper "On Subquadratic Architectures: From Applications to Principles" 🙌
On commonsense & reasoning benchmarks, xLSTM, Mamba-2 & Gated DeltaNet perform nearly indistinguishably.
Therefore, we analyse them where structure genuinely matters: on code & time series.👇

3
10
27
5,529
Maximilian Beck retweeted

Jun 7
We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t 1}) → m_{t 1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: akarshkumar.com/smt/
arXiv: arxiv.org/abs/2606.06479

17
119
784
173,116

Maximilian Beck retweeted

We unlocked the working memory of LLMs 💥
Reasoning in Memory (RiM) replaces autoregressive "thinking out loud" with fixed memory blocks that form a task-specific workspace for latent reasoning.
The key idea is simple: reasoning should happen inside the LLM, not in its output!
27
52
314
57,492
May 14
Life update: A few weeks ago, I moved to Paris 🇫🇷 to start a new position as AI Scientist at Meta FAIR. I am excited about this new chapter and look forward to the opportunities ahead.✨
7
48
1,633


Maximilian Beck retweeted

# GREAT news!!! 4 papers from our group got accepted at ICML 2026!!! #
- 🧬 Contrastive Geometric Learning Unlocks Unified Structure- and Ligand-Based Drug Design
- 🔁 xLSTM Distillation: Achieving Teacher-Student Parity Through Efficient Hybrid Architectures
1
4
19
2,923
Maximilian Beck retweeted

RNNs like xLSTM with vertically chunked inference strategy for efficient memory: arxiv.org/abs/2604.18199
Chunking enables a linear-time and constant-memory like TFLA for xLSTM arxiv.org/abs/2503.14376
To chunk blocks via recurrent updates and speed up computation considerably.
1
14
90
9,026
Apr 12
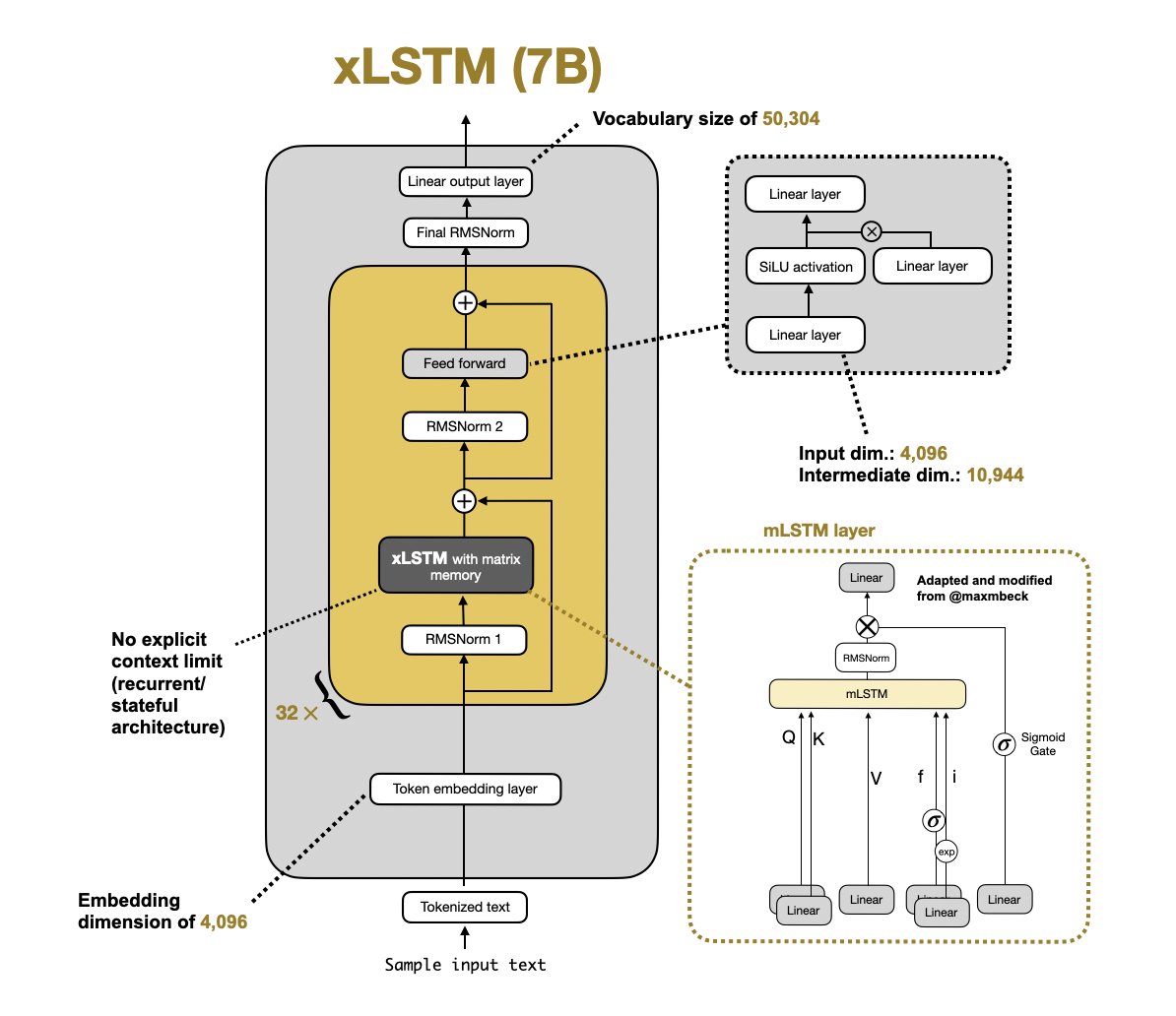
We’ve released 35 xLSTM checkpoints from our scaling law study, spanning 160M to 7B parameters and trained on 3B - 1.5T tokens from the DCLM dataset.
huggingface.co/NX-AI/xlstm_s…
3 Oct 2025

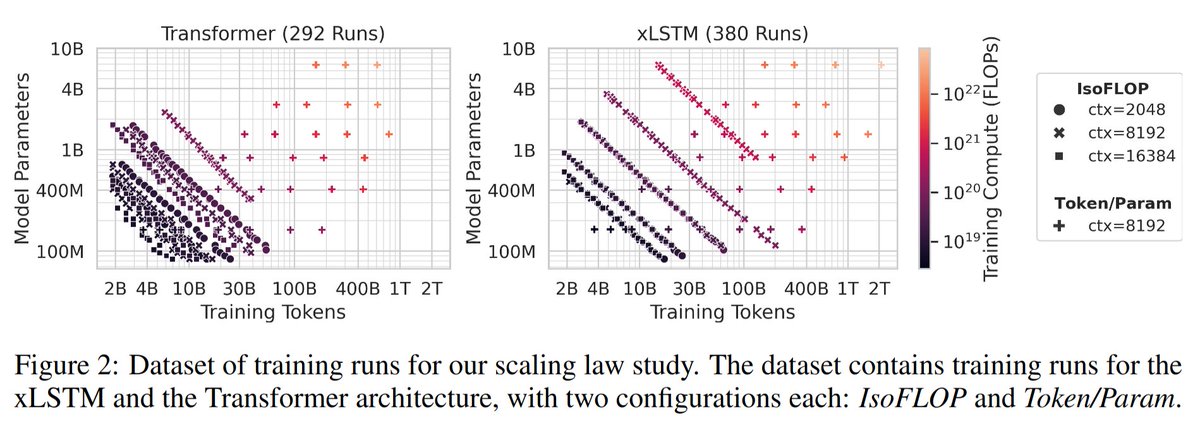
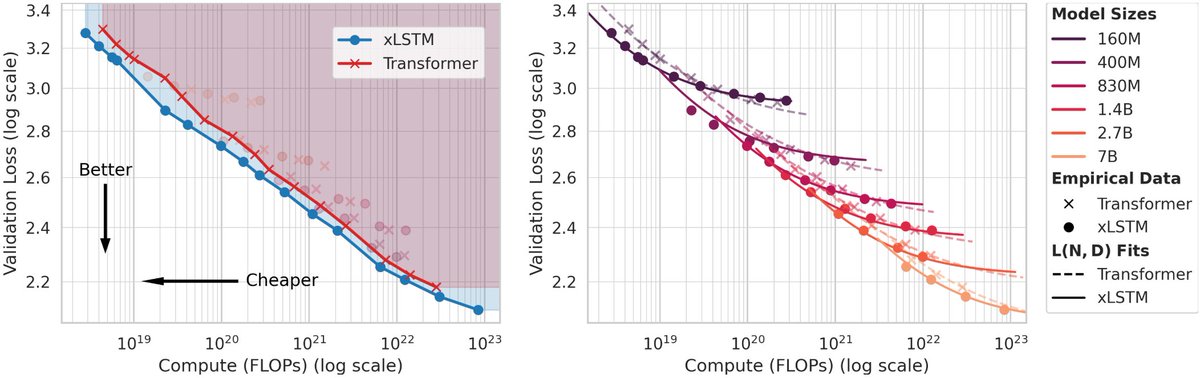
🚀 Excited to share our new paper on scaling laws for xLSTMs vs. Transformers.
Key result: xLSTM models Pareto-dominate Transformers in cross-entropy loss.
- At fixed FLOP budgets → xLSTMs perform better
- At fixed validation loss → xLSTMs need fewer FLOPs
🧵 Details in thread
2
13
116
12,404
Apr 12
These checkpoints come from our token-per-parameter training setup and are fully compatible with the xLSTM-7B Hugging Face implementation:
huggingface.co/NX-AI/xLSTM-7…
1
337
Mar 27
👨🎓Last week, I successfully defended my PhD thesis - an incredibly exciting and rewarding milestone after 3.5 years of work on
xLSTM: Recurrent Neural Network Architectures
for Scalable and Efficient Large Language Models
16
3
138
8,662
Mar 27
And of course many thanks to @KorbiPoeppel for being an amazing co-author on nearly all xLSTM papers.
I also want to thank all collaborators, friends, and family for their support.🤗
1
3
346
Mar 27
Now, I’m looking forward to a relaxing Easter break and I’m excited for what comes next 🚀
📄 Thesis: maxbeck.ai/resources/phd_the…
🎤 Defense slides: maxbeck.ai/resources/talks/2…
1
11
977

Maximilian Beck retweeted

Mar 17
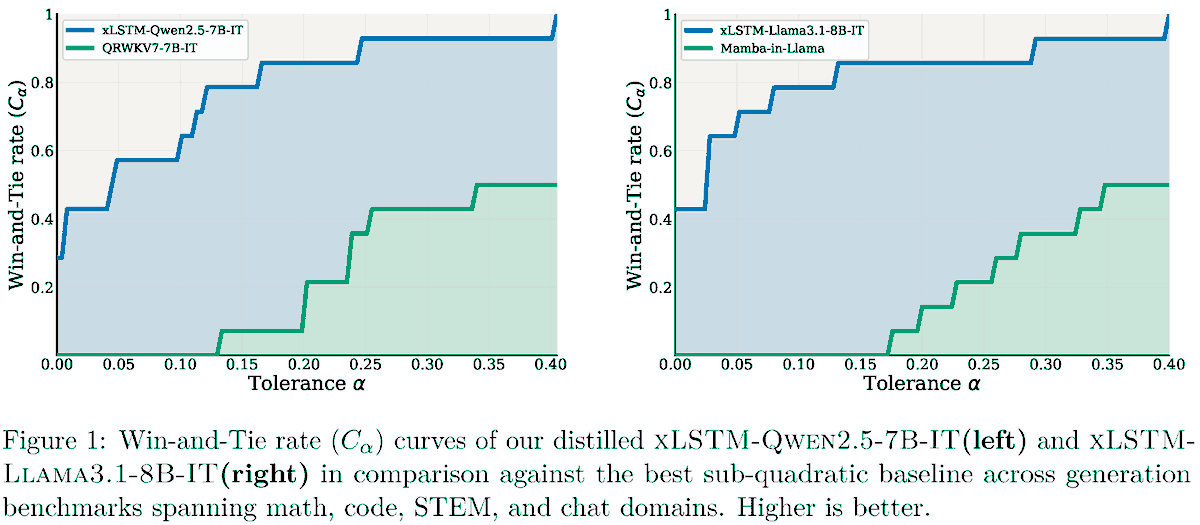
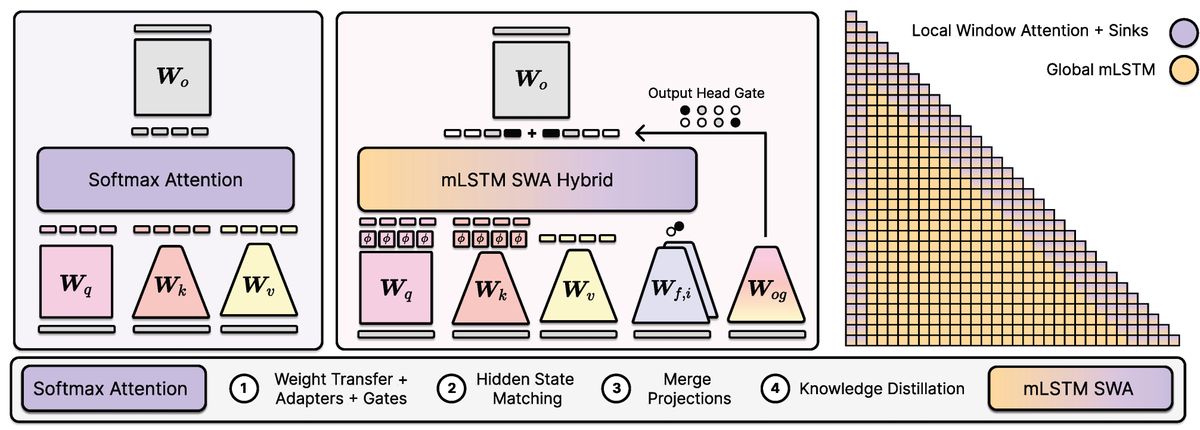
Excited to share our new paper: Effective Distillation to Hybrid xLSTM Architectures.
TL;DR: we retrofit / graft / distill / linearize Transformers into xLSTM-SWA hybrids with fixed-size states.
This gives a practical path to studying linear and hybrid architectures starting from already strong pretrained models.

xLSTM Distillation: arxiv.org/abs/2603.15590
Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance.
xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
1
6
15
1,252
Mar 17
🆕 New xLSTM models! 🔥
⚗️ This time distilled from Llama, Qwen & Olmo!
xLSTM Distillation: arxiv.org/abs/2603.15590
Near-lossless distillation of quadratic Transformer LLMs into linear xLSTM architectures enables cost- and energy-efficient alternatives without sacrificing performance.
xLSTM variants of instruction-tuned Llama, Qwen, & Olmo models.
1
6
34
2,612
Mar 16
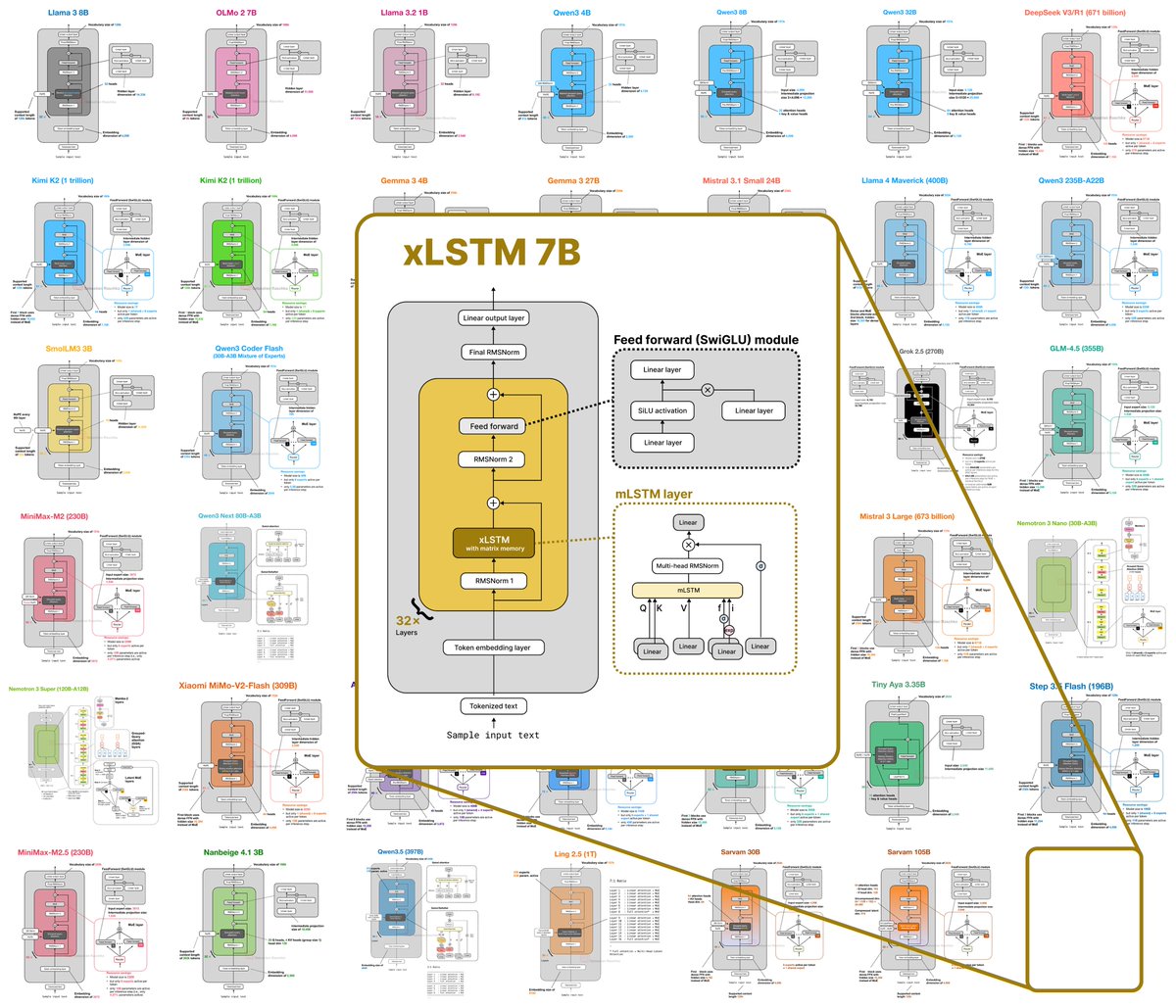
Thanks @rasbt for the great overview — and for leaving a little spot for xLSTM 7B 😉
📄Paper: arxiv.org/abs/2503.13427
Mar 15
I (finally) put together a new LLM Architecture Gallery that collects the architecture figures all in one place!
sebastianraschka.com/llm-arc…

3
10
59
7,313