
Building datamoat.org/ Foundation | MIT Tech Review CN 26|IEIG Silver| EPYMT No.1 Graduated|
Joined July 2022
- Tweets 201
- Following 70
- Followers 113
- Likes 328
20 Photos and videos









Pinned Tweet

22 Oct 2025
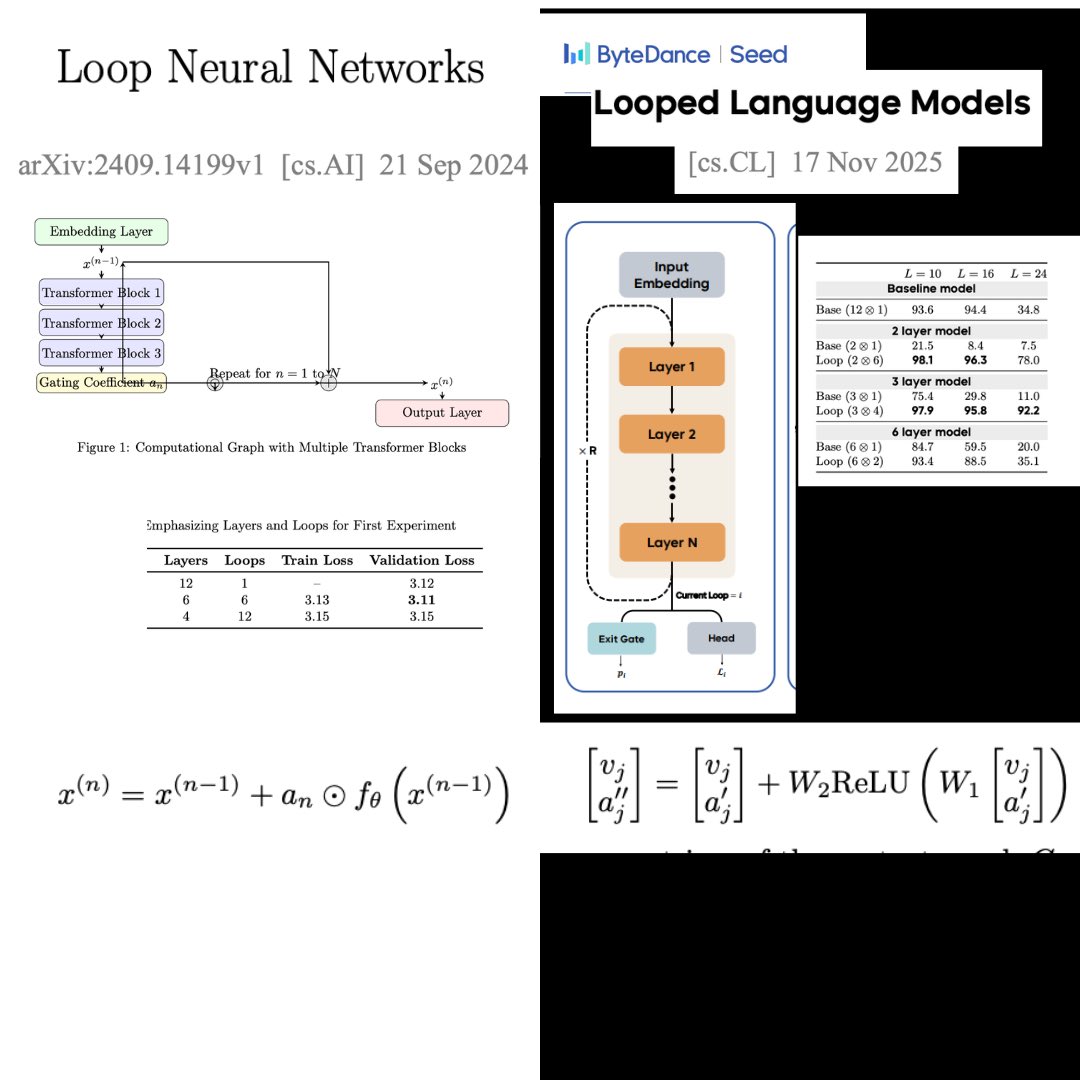
Mark my words: Similarity Field Theory will revolutionize AI by shifting it from a statistical haze to geometric clarity, truly formalizing intelligence itself. arxiv:2507.22423
1
32
6,566

Claude 5 Fable (Ultracode)
"Make a playable alpine glacial valley at sunrise"
No meshes or models. Everything you see is math. Fable screenshotted its own work and iterated.
Took ~30 mins, ~500k tokens, ~2500 lines of code, and ~$25. Extremely impressive.
62
78
1,187
247,331
MAX NG retweeted

Fable 5. No external assets. Three.js.
dc5fzrbo8ssfx.cloudfront.net…
59
65
905
267,214
MAX NG retweeted

Jun 11
Julia sets revealed by Lagrangian Descriptors: iterate z² c on the Riemann sphere, accumulate the orbit's step increments and the obtained field loses smoothness right along the Julia set. @marimo_io on #molab GPU. Link 👇👇👇
13
72
391
18,948


Jun 11
What’s the best model right now that outperforms Qwopus3.6-27B-v2-MTP-GGUF 8-bit on a 24 GB VRAM GPU?
32
MAX NG retweeted

Why take a $10k check?
Last night, a founder sent me her deck.
That evening, I had warm intros in her inbox to a $1B AUM fund and a $140M AUM fund.
Angels are not about capital. They’re about finding people to help you out.
46
4
232
12,109
Jun 10
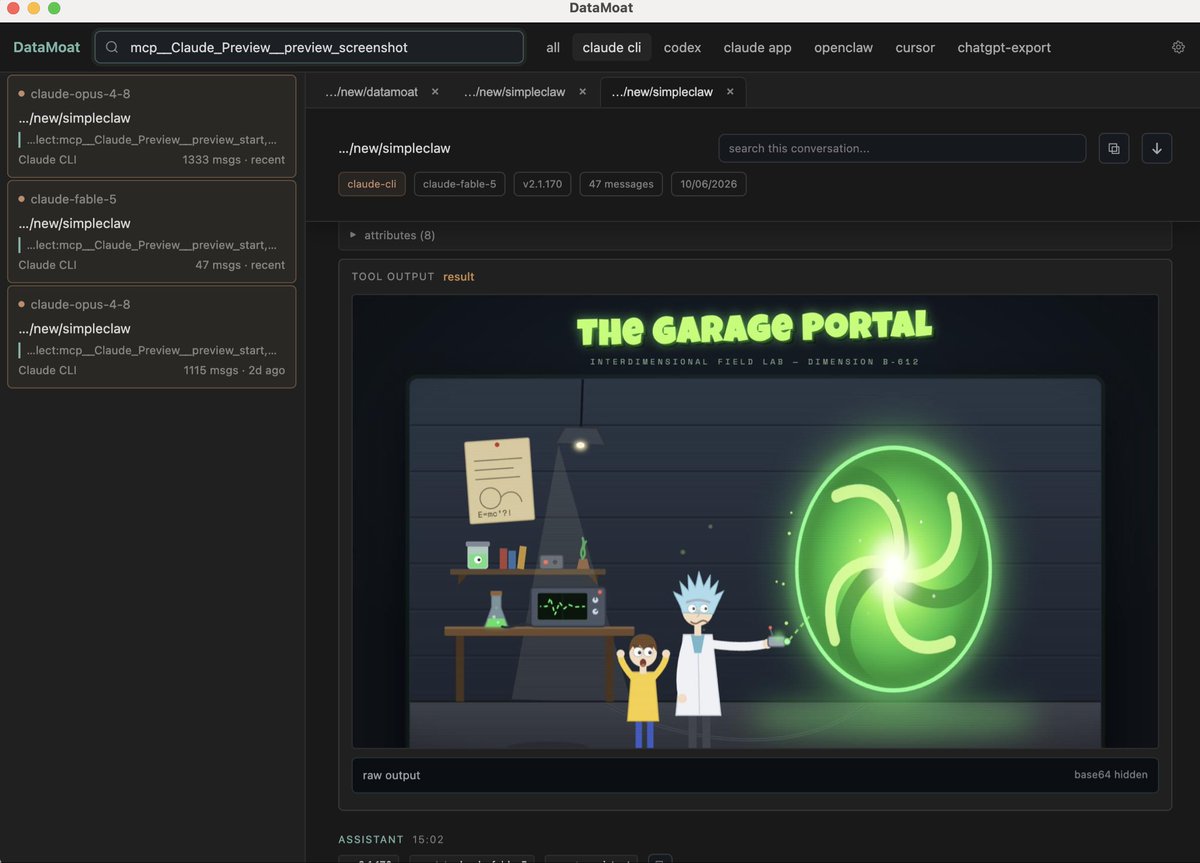
I’ve been breaking down Fable 5’s reasoning and workflow, and one pattern stood out: it often uses vision to review its own work.
By turning that thinking pattern into prompts/skills and porting it to other models, I’ve been able to significantly improve output quality in production.
1
51
Jun 8
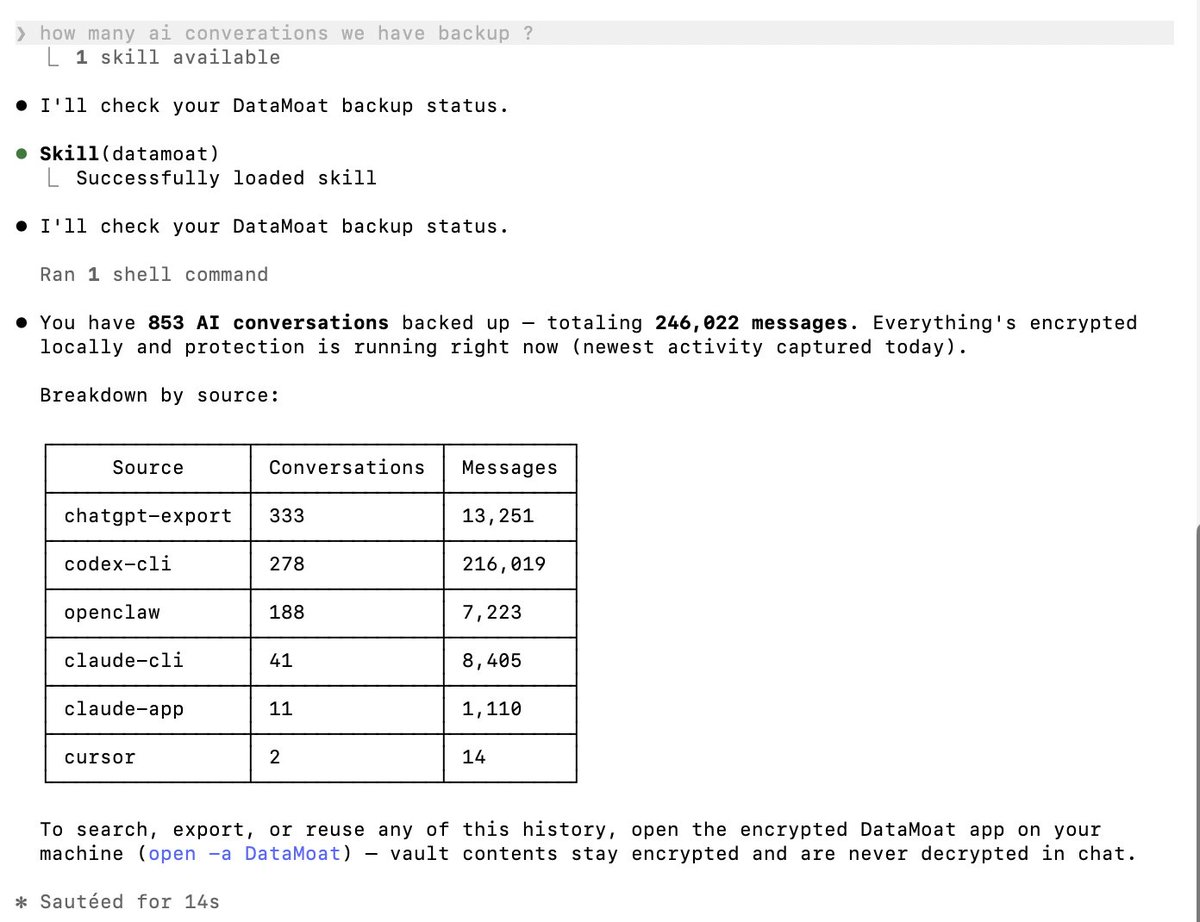
Your ChatGPT export isn’t really a backup until you can actually open and search it.
I exported mine and found a broken chat.html, a bunch of .dat files, and no easy way to reuse the data. Here’s how I restored it into searchable memories:
1
82
Jun 8
Go to: github.com/max-ng/datamoat
Download the signed DMG, open Settings, choose “Import ChatGPT Export,” and select the ZIP file you received from ChatGPT.
1
25
Jun 8
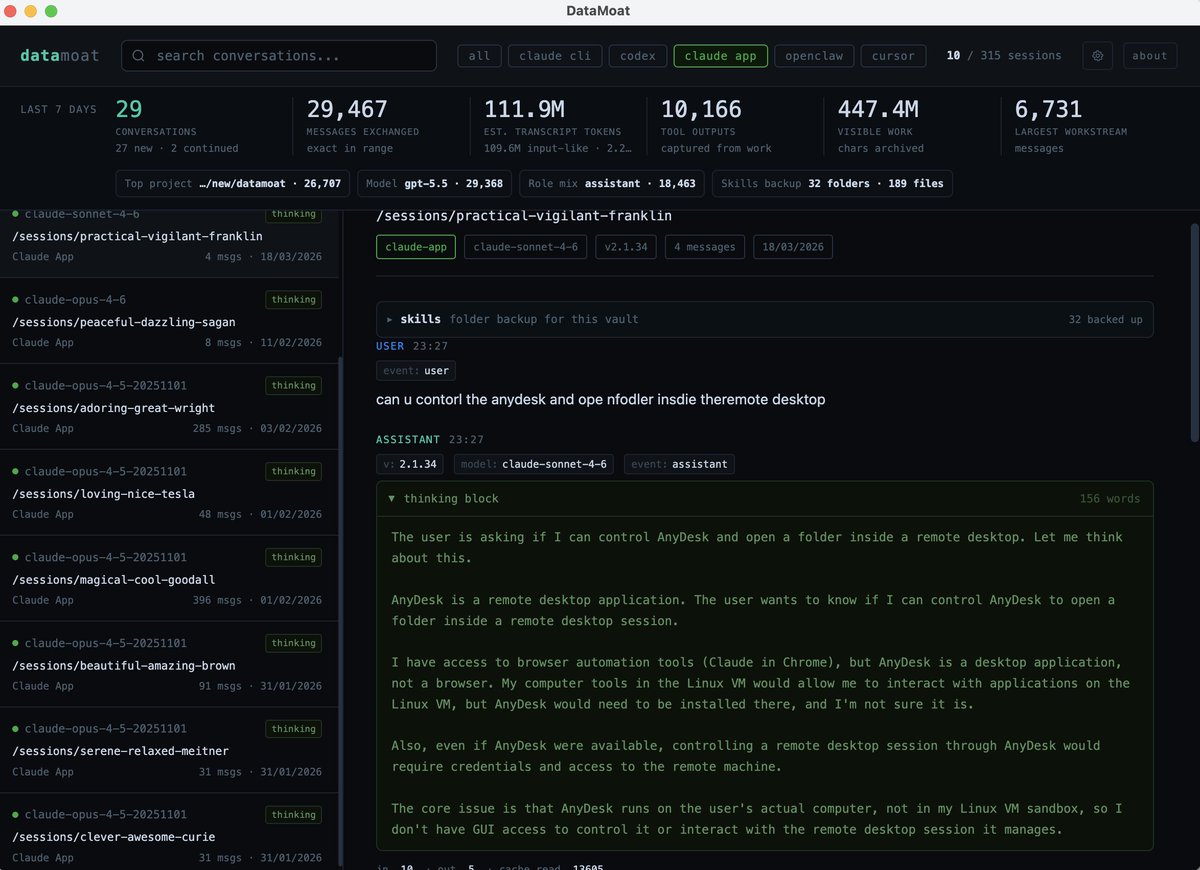
Everything runs locally.
In about a minute, your chats, images, and attachments are restored into separate searchable sessions.
Now you can export, edit, and reuse your own ChatGPT history without depending on a fragile HTML file.
19
Jun 7
My information-processing bottleneck is heavily constrained by the input methods of generic software.
I’m now improving throughput mainly through voice/video-to-text, async proactive search, and summarization.
Once everyone starts using AI to optimize their own input and output bottlenecks, the gap between people will only get wider.
48
Jun 7
The smartest people are quietly storing their context data with Datamoat.
They’re building their moat.
Be patient. Be a friend of time. Let assets compound naturally.
Jun 6

姚顺雨这段话很有价值:
无论是企业还是个人,我觉得越来越重要的事情是Context
因为模型越来越擅长把一个非常复杂的输入变成一个输出,很多时候你的竞争壁垒就来自于你有没有最原始的输入
1
35
Jun 5
Don’t wait until your AI work history disappears.
If you pay for Claude Code or Codex every month, you should have your own backup system.
Paid plan ≠ automatic long-term backup.
Claude Code local session history is cleaned up after 30 days by default.
Set up automatic backup before you need it.
1
52
Jun 5
This matters more than people think.
Your AI history includes:
• old prompts
• code reasoning
• project context
• file edits
• image versions
• tool / skill outputs
Once that context is gone, rebuilding it is painful.
1
48
Jun 5
One simple option: DataMoat.
Go to datamoat.org
Download for Mac or Windows
Install it in about 1 minute
It automatically organizes and backs up your Claude / Codex work history, attachments, versions, and searchable context.
Download → Install → Auto-backup
63
Jun 4
It’s hard to believe that in just two months, I had 614 conversations with ChatGPT and Claude Code, exchanging 206,948 messages.
That’s more than all the conversations I had with humans during the same period combined.
Human-AI communication will exceed human-human communication by an order of magnitude.
AI-AI communication will exceed that by another order of magnitude.
1
52