
product @cloudera | prev product @aws @dremio @verticaunified • #data #analytics #design #tech for 🌍
Joined October 2012
- Tweets 1,435
- Following 4,871
- Followers 888
- Likes 3,161
20 Photos and videos













Mark Lyons retweeted

26 Mar 2024
Microsecond-accurate time is now available in EC2 US East. So many cool things this makes possible: aws.amazon.com/about-aws/wha…
5
18
148
19,401

29 Jun 2023
Anyone looking for a new SA opportunity DM me and I can intro you to Roger Frey! (Great team & Roger is fantastic!!) lnkd.in/edKZsu-b
2
1
4
147
27 Apr 2023
Verifying myself: I am markclyons on Keybase.io. 2RdVlnBARFNGHkBQEWYYppwhlr0zvyetUhBV / keybase.io/markclyons/sigs/2…
145

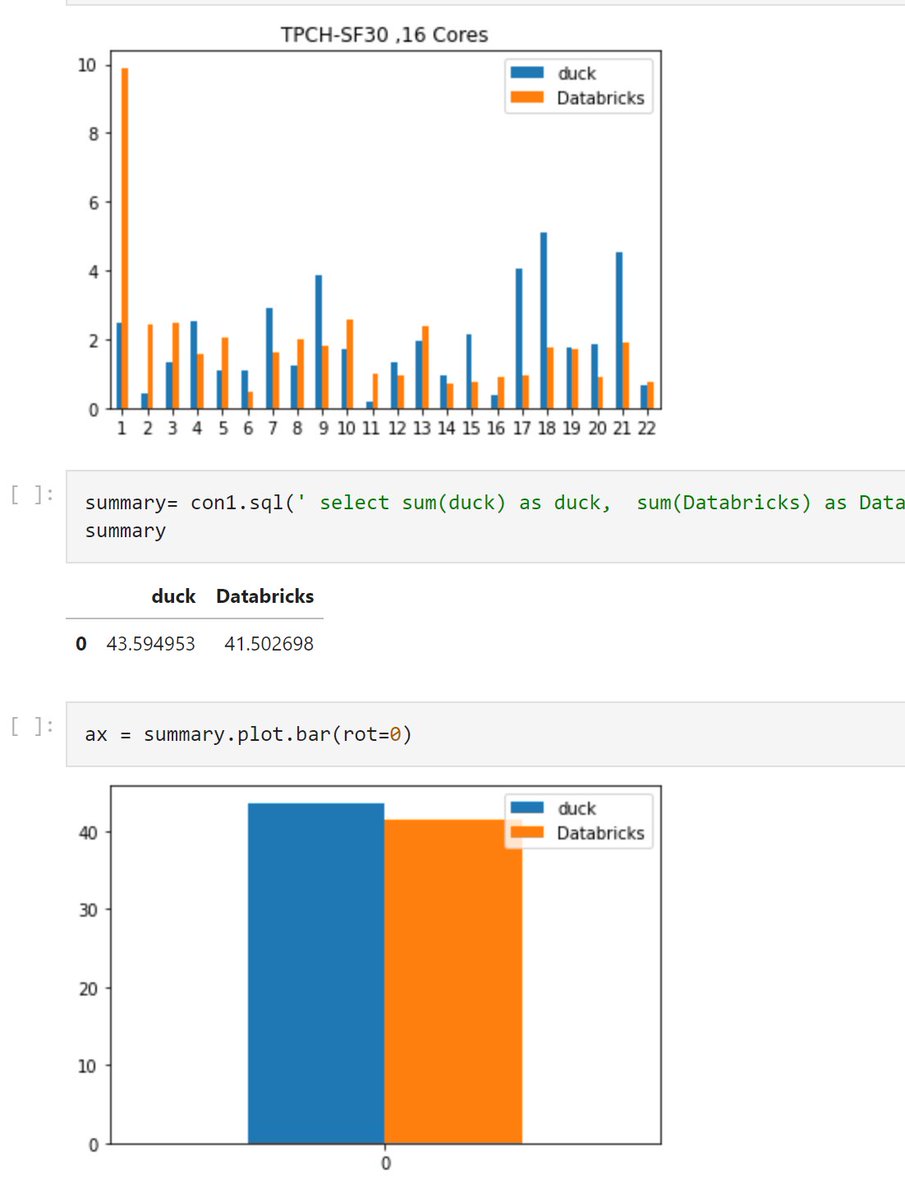
TPCH-SF30 ; 180 million rows
#AZURE D16DS_V5; 16 Cores, 64 GB RAM
#Databricks Photon 41 S
#DuckDB : 43 second
Query Parquet files from the VM SSD, no Azure storage involved
Databricks Software cost (not hardware) 4.4 $/Hour
github.com/djouallah/Testing…
4
4
42
8,317
Mark Lyons retweeted

1 Dec 2022
Join @dremio’s Tech advocacy & Eng team for the very first installment of the @ApacheIceberg Office Hours 📆 🚀
We will kick-off with a brief presentation on Copy-on-Write Vs Merge-on-Read strategies, followed up by Q&A on anything Iceberg related.
When: December 7th, 12 PM

1
4
14
Mark Lyons retweeted

Reminder, if you want to learn more about Apache Iceberg I have loads of resources plus a video series all curated in this article. -> dremio.com/subsurface/apache… #BigData #DataLake #DataLakehouse
6
11
Mark Lyons retweeted
17 Nov 2022
Query planning in @ApacheIceberg
Being able to efficiently plan queries is super critical for faster execution of the queries run by analysts 🧑🏻💻
This is specifically critical when dealing with large-scale data such as data in data lakes. Read @IcebergDevs 👇
#dataengineering

1
3
18
Mark Lyons retweeted
15 Nov 2022
The @ApacheArrow project has grown in all axes 🚀
In fact, more & more tools/libraries in the #dataanalytics space have started using Arrow.
In this blog post, we go through the evolution of Apache Arrow from usage, capability & community angles.
dremio.com/blog/apache-arrow…
1
3
19
Mark Lyons retweeted
My latest article on Apache Iceberg compaction strategies -> dremio.com/subsurface/compac… #BigData #dataengineering #datalake #DataLakehouse
6
9
Mark Lyons retweeted
10 Nov 2022
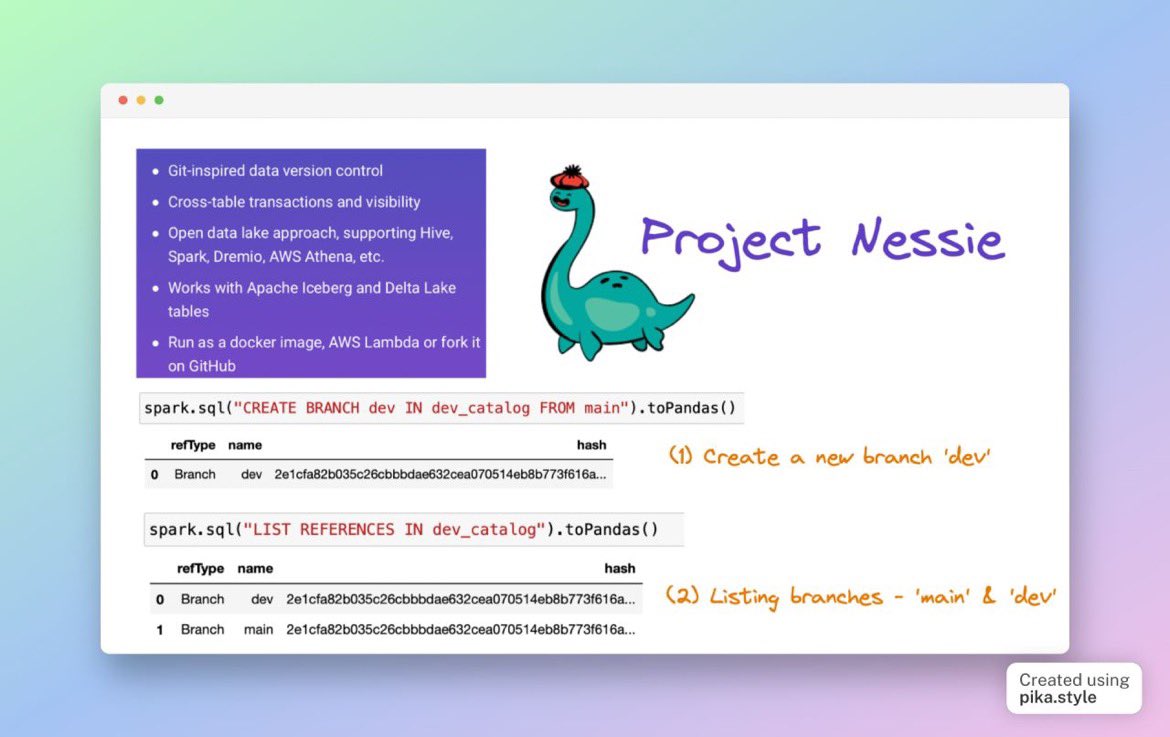
Manage data as code?
Just like Git but for Data?
That's right!
@projectnessie is an open source work that brings the capabilities of Git-like branching to the world of data & specifically to data lake table formats like #ApacheIceberg
#dataengineering
2
3
9

We're thrilled to announce that we've been named to @CNBC’s ‘Top Startups for the Enterprise’ Inaugural List 🎉
Read more about our open data lakehouse and this inaugural list here:
bwnews.pr/3UehuIN
#CNBC #TopStartup #Tech
6
7
Are you heading to AWS re:Invent later this month? Check out this link for all the details on how you can:
➡️ Schedule a meeting with us
➡️ Enter our Dremio Cloud data challenge (for a chance to win a PS5!)
➡️ RSVP to our cocktail reception
awsreinventdremio2022.splash…
#AWSreInvent

3
2
Mark Lyons retweeted
If you find what you see interesting here is a tutorial I wrote giving you a step by step guide getting setup and doing an example exercise -> dremio.com/blog/managing-dat…
1
1
4
Mark Lyons retweeted
27 Oct 2022
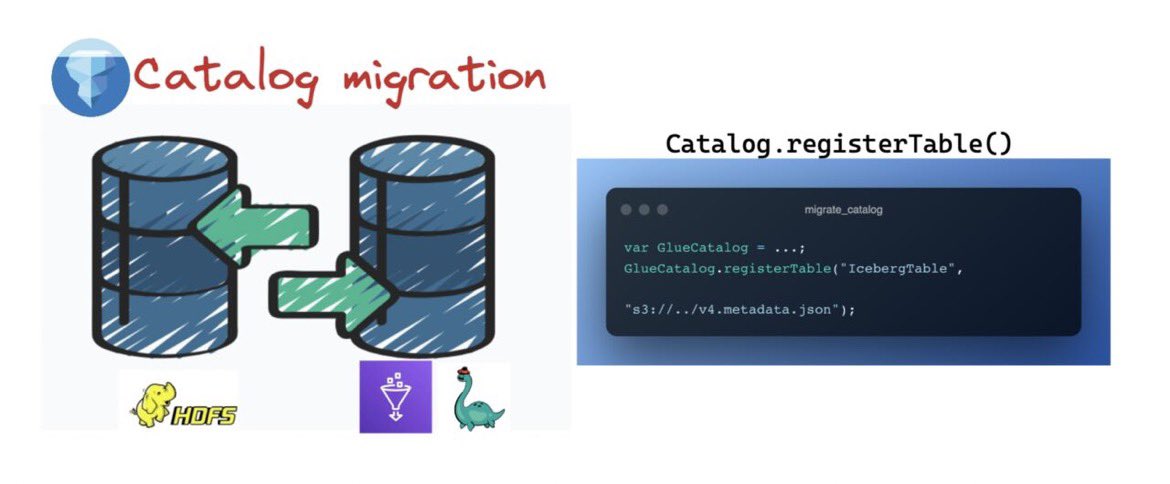
How do we migrate from one catalog to another for @ApacheIceberg tables?
if you are already using a catalog (say HDFS) & want to change it to something else (say AWS Glue), how is that possible?
A 🧵 for @IcebergDevs
#dataengineering
2
4
13
With all the recent news about #ApacheIceberg we thought we'd share this video from last year's Subsurface Conference. We're looking for speakers for our event happening in spring 2023 🎤 submit your talk today!
sessionize.com/subsurface-li…
#CallForSpeakers
4
7
Mark Lyons retweeted
11 Oct 2022
Merge-On-Read (MOR) Vs Copy-On-Write (COW) in @ApacheIceberg.
Both these approaches are used to deal with deletes & updates of data files in the Data lake.
Let’s break down @IcebergDevs👇
#DataEngineering #data

1
5
16
Don't miss your chance to take the stage at Subsurface LIVE, coming in the Spring of 2023 🎉
We’re accepting proposals now for key topics. See details submit your proposal now 🎤
lnkd.in/gMXtSTSJ
#CallForSpeakers #Data #ApacheIceberg #DataLakehouse

1
3
1 Oct 2022
Always great to catch up with people who have depth in the data space to share the stories from academic papers to how companies have been created. Thanks @juansequeda @TimGasper
1 Oct 2022

A Data Catalog is like the parent to the data who makes sure that you go grow, be successful, have fun while being safe.
This is the result of our beer discussion with @TimGasper and
@mcl5tech in Austin (after Big Data London)

3
Subsurface LIVE is back! Coming in the Spring of 2023 🎉
We’re accepting proposals now for key topics. See details submit your proposal now 🎤
lnkd.in/gMXtSTSJ
#CallForSpeakers #Data #ApacheIceberg #DataLakehouse

1
2