
PhD Student @stanfordnlp || Working on DSPy 🧩 || Prev @GeorgiaTech @Microsoft @SnowflakeDB
Joined December 2019
- Tweets 395
- Following 1,349
- Followers 2,410
- Likes 7,987
44 Photos and videos










Pinned Tweet

Apr 23
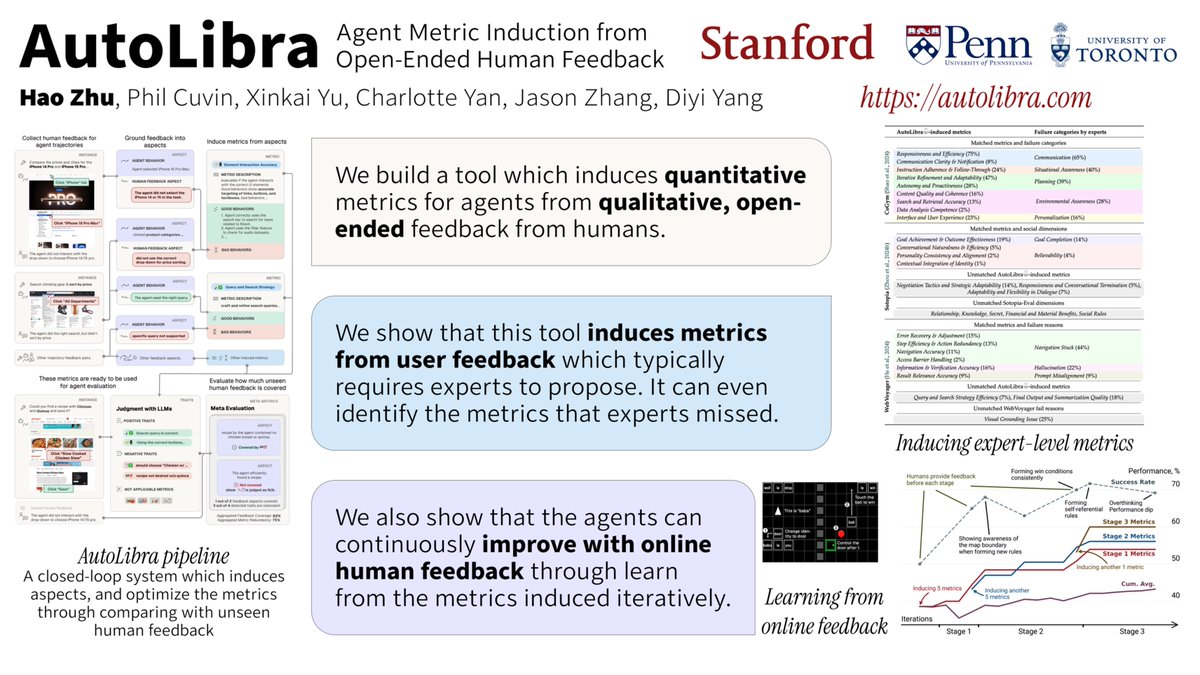
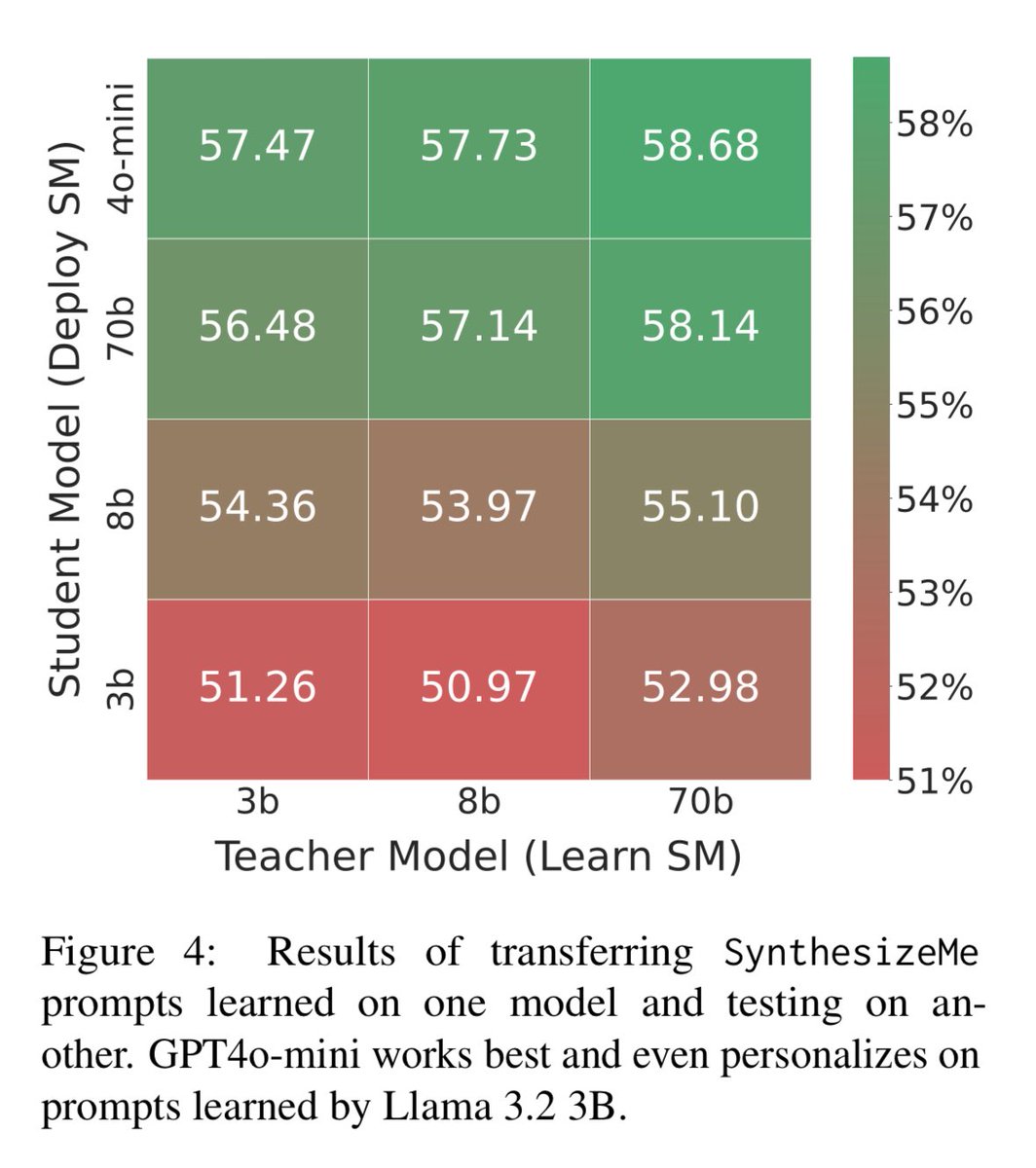
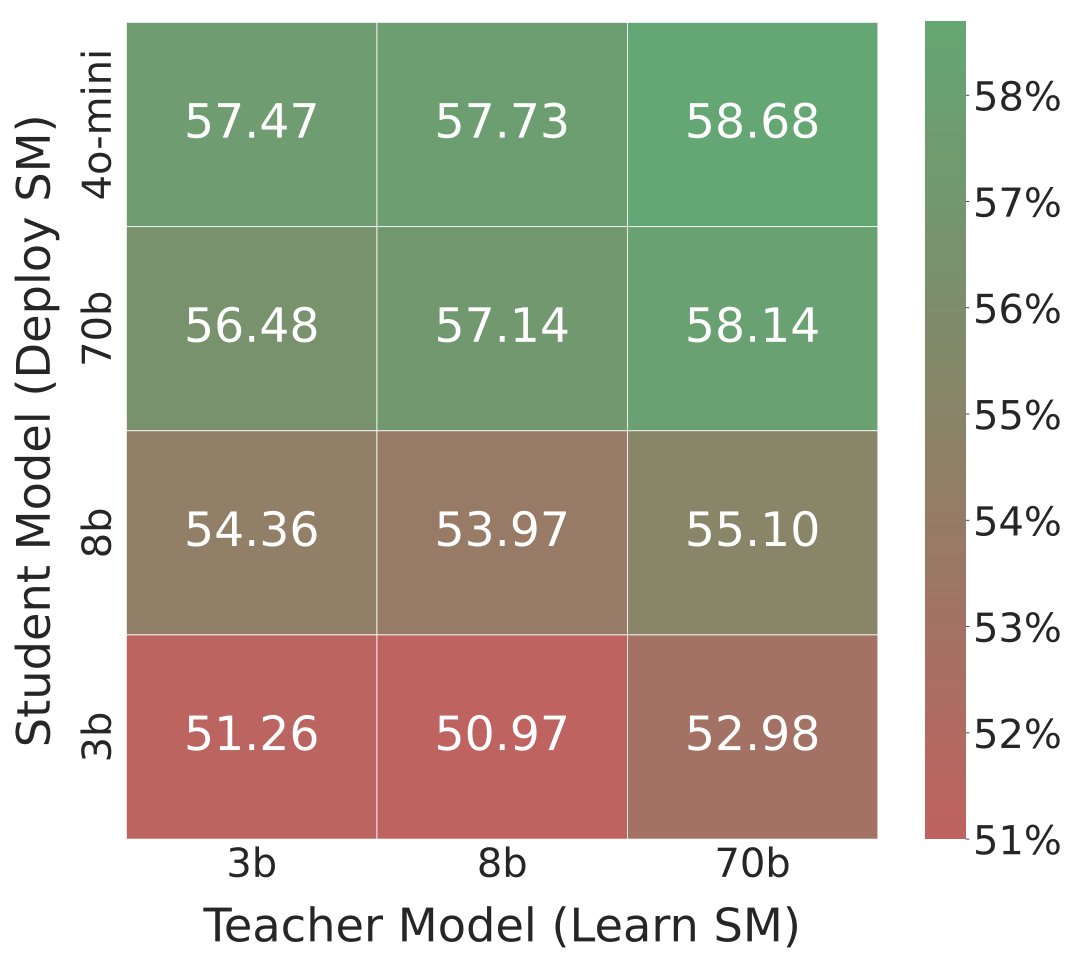
Human feedback is so critical for evaluating subjective AI systems -- and yet so costly to collect.
Come talk to me about AutoMetrics at #ICLR2026 🇧🇷! With <100 feedback points we generate automatic evaluation metrics for your task that beat hand crafted LLM-as-a-Judge rubrics by up to 33.4% improvement in correlation to human judgements!
6
32
229
33,079
Michael Ryan retweeted

In EP5, we're thrilled to talk with Prof. Jeremy Avigad.
Jeremy is a math philosopher at @CarnegieMellon and early contributor to LEAN. With all the recent math AI advances, it's inspiring to hear why he has tremendous faith in mathematics and how AI can augment us.
Preview:
4
13
9,880
Michael Ryan retweeted
The AM Podcast EP5 is around the corner. 👀🧑🍳
You may have seen the viral post about OpenAI math breakthrough. For EP5 we sat down with Jeremy Avigad, co-creator of @leanprover before that and the conversation is incredible. Jeremy shares not just the Lean project, but also
- The verification gap in human-AI collaboration
- How AI is changing mathematics
- The future of math education
- Capital, startups, and the mathematician's ecosystem
- ...
Stay tuned and subscribe our YouTube channel for latest updates!

10
23
5,601
Michael Ryan retweeted

May 26
"Evolve your repo, not just your agent."
Self-evolving repository (SEPO) is a fun idea that I’ve been exploring recently. @sepoagent turns any GitHub repo into a shared workspace for humans and coding agents.
3
22
91
14,292
Michael Ryan retweeted
Join us this Thursday May 28th 6-7pm PST for our first ever AM Podcast Live Stream! 🎉
We are hosting @cjziems, @dorazhao9, and @Diyi_Yang for a discussion on their new paper "Reflections and New Directions for Human-Centered Large Language Models"!
RSVP 🔗⬇️

1
9
20
13,756
Michael Ryan retweeted

May 24
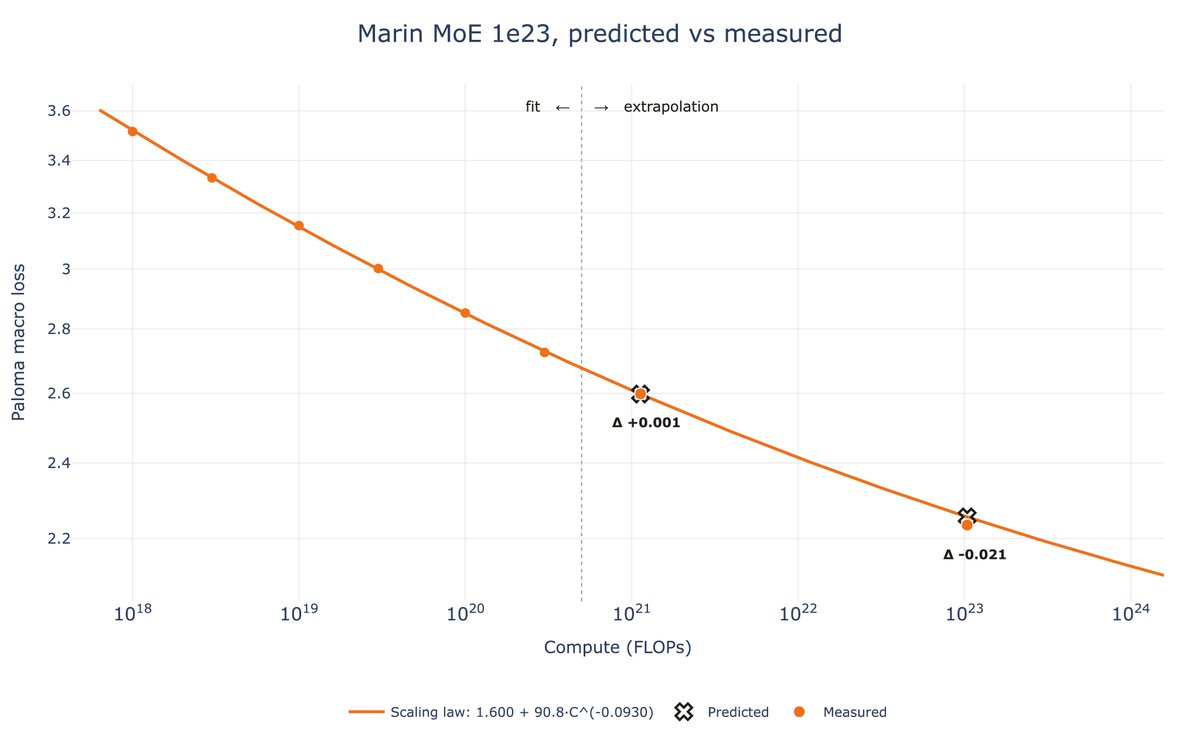
Not only do we want to train a good model, we want to know it'll be good before we even start training.
About a month ago, the Marin team launched a 129B (16B active) 1e23 FLOPs MoE run and preregistered a loss of 2.252. The run finished this past week and landed at 2.234.
x.com/percyliang/status/2044…
Apr 17

This week, @classiclarryd kicked off a 129B (16B active) 1e23 FLOPs MoE run. In typical Marin style, we have fit scaling laws and have made a loss projection of 2.252. Stay tuned.

25
65
618
64,990
Michael Ryan retweeted

May 20
The next frontier of AI is not only more capable model; it is an AI that *humans* can meaningfully live and work with :)
With all students in my cs329x Human-Centered LLM class, we present 60 pages of insights for developing Human-Centered LLMs (HCLLMs), from design & data sourcing to training, eval & deployment 🧵

14
78
288
53,968
Michael Ryan retweeted

May 18
Tomorrow (5/19), 6–7pm PT: We're going live for the first time to share how to collaborate with AI agents more effectively 🤖
Thrilled (and a little nervous!) to see so many RSVPs. As Stanford Qualtrics console is down😅, we can't reach everyone directly — here's your calendar link: partiful.com/e/sR1cyXbpzya7p…
May 12

After our major update to Collaborative Gym, the most common questions have been about the human side. Here’s a detailed thread on key findings from human workers’ CollabSkill 👇
🎙️ Motivated by these, we’re doing a YouTube livestream next Tuesday (5/19) — a crash course on meaningfully collaborating with AI agents.

2
8
28
9,866
Michael Ryan retweeted
Interaction model poses new challenges for AI model inference engine. We discussed about it in our episode with @woosuk_k on @vllm_project 's solution. Link to the full episode in the thread.
May 11

People talk, listen, watch, think, and collaborate at the same time, in real time. We've designed an AI that works with people the same way.
We share our approach, early results, and a quick look at our model in action.
thinkingmachines.ai/blog/int…
2
5
14
7,313
Michael Ryan retweeted

May 13
We upgraded Tabracadabra 🎉 to bring an entire context-aware assistant (not just tab to autocomplete!) to any textbox. It's pretty great if you hate switching between the chat interface and what you're working on. We're also open-sourcing, so you can try it out!🧵
13
37
175
39,870
Michael Ryan retweeted

May 13
Introducing SWE-ZERO-12M-trajectories: the largest agentic trace dataset in the open, 5.7x larger than the previous largest.
112B tokens · 12M trajectories · 122K PRs · 3K repos · 16 languages
huggingface.co/datasets/Alie…
19
67
527
79,544
May 12
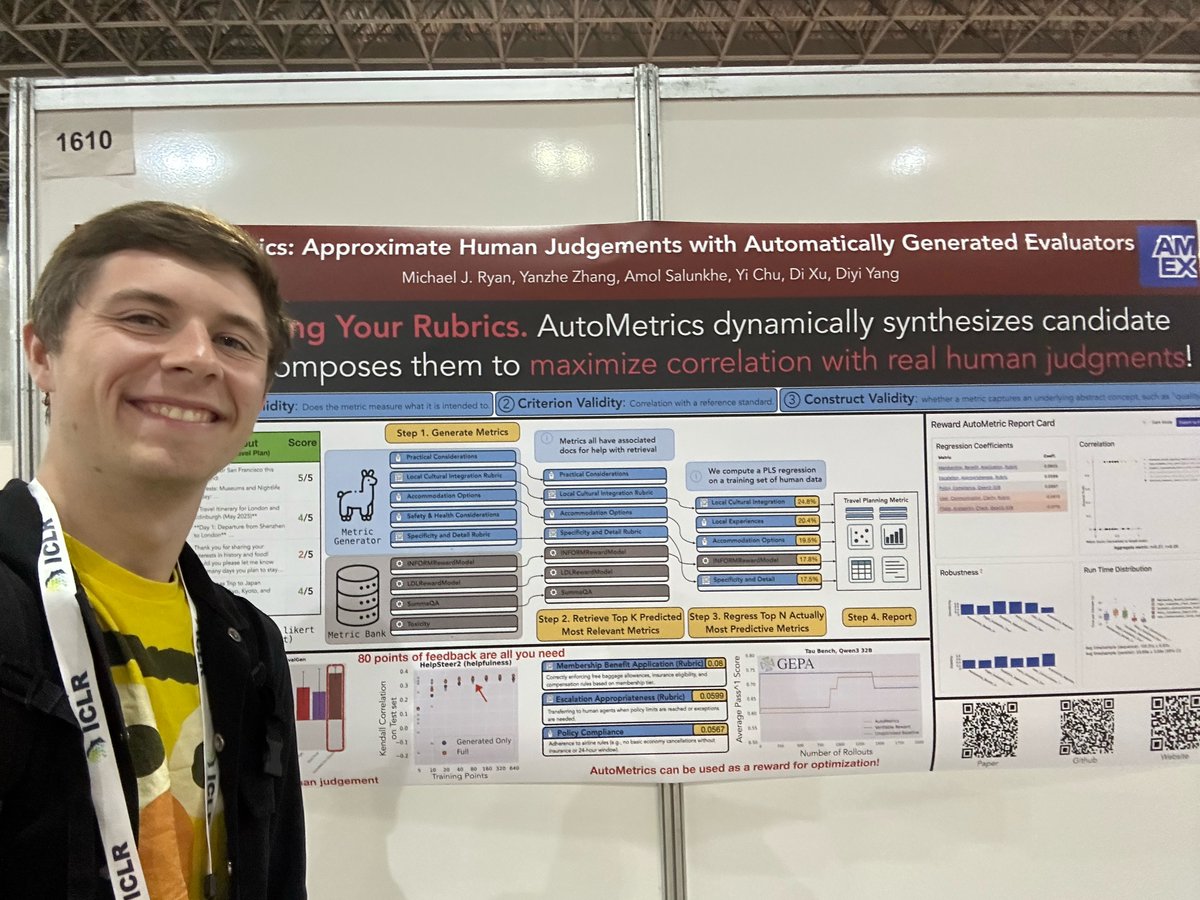
Super cool team working on exciting stuff in the Automatic Metrics space 🐐
Had the pleasure of speaking with @alexshander03 a few times much earlier on in both of our projects! Can’t wait to see where they take this!
May 12

We’re launching @JudgmentLabs today and announcing $32M in funding.
As AI agents take on more of the work that creates economic value, they generate massive amounts of production data: the clearest record of how they behave with users, software, and the real world.
Judgment builds infrastructure for improving AI agents from production data.
1
4
29
4,029
Michael Ryan retweeted

May 12
I'm joining Carnegie Mellon's CS Department (and HCII by courtesy) as an assistant professor in Fall 2027!
I'll be recruiting PhD students next cycle. If you're interested in AI systems or human-AI collaboration, list me in your application. Stay tuned for more about my new lab!
121
109
2,014
215,328
May 12
Super excited to join the 2026 cohort of @KnightHennessy scholars!
Has been incredible talking to the other scholars about the major problems they are tackling across healthcare, science, policy, etc. Excited to work towards Human-Centered Open-Source AI that can support people tackling the world's biggest challenges!

Meet the 2026 cohort of KH scholars! These 87 new scholars make up the most global Knight-Hennessy Scholars cohort to date, and will pursue degrees in 45 graduate programs across all seven graduate schools at @Stanford: knight-hennessy.stanford.edu… (1/2)

39
19
192
26,228
Michael Ryan retweeted

May 11
To train better open models, we need predictable scaling.
Delphi is Marin’s first step: we pretrained many small models with one recipe, then extrapolated 300× to predict a 25B-param / 600B-token run with just 0.2% error.
Getting there took some work 🧵
14
78
459
138,246
Michael Ryan retweeted

May 5
Had a great time discussing AI user privacy on @augmind_fm 😃
One discussion I’d like to highlight from the chat is that what constitutes the "Privacy Problem" has been shifting as AI progresses.
It used to be that we care a lot about *training-time* user privacy: what gets trained into the model, and what the model would spit out. Say you take an LLM and a book (or any piece of sensitive text). We cared about whether the book would be regurgitated ("memorization"); whether you can remove such a book from the model ("unlearning"); and whether you can detect the book being trained ("membership inference"). And as part of mitigating these problems, we work on training-time techniques like differential privacy, careful data cleaning, and model alignment/guardrails (in ~increasing order of adoption). Guardrails seem to work well enough that people don’t really talk about sensitive model outputs anymore.
What’s more pressing today, I argue, is *inference-time* user privacy: the fact that intelligent models are served at scale on private user data, which are then centrally managed at model providers. Intelligent models mean that user profiling is now cheap and automatic; your activities can be continuously analyzed to reveal new sensitive insights. Whether your data is trained on or not became less relevant. Having a "digital clone" of you by building on your memory/personalization is now way more profitable. The threat vector changed from the model misbehaving to the provider misbehaving.
Because of this, the techniques to improve user privacy would look different than before. They’ll look less like fancy learning algorithms (e.g. RL to steer model to output paraphrase of a book than the original book), and more like *peripheral systems* sitting around closed models that we do not control but still want to access. The OA project (openanonymity.ai) is an example: you could build a zero-knowledge proxy to mediate AI inference and combat surveillance, and leverage smaller models to help users build personal memory on-device. This is not to say that there’s no room for training; you just train for different things, and on auxiliary models than the closed models.
thank you so much to @EchoShao8899 @michaelryan207 @shannonzshen for hosting me!

“In the past, with social media or web search, you are like, here are some specific keywords, here are some posts that I am okay to share with the world; whereas with AI, it feels like you are private, it feels like you are talking to an entity that won’t reveal your information.”
For EP4, we welcome @kenziyuliu, Stanford CS PhD student and creator of The Open Anonymity Project. Ken approaches AI privacy from angles most researchers don't: deep learning, applied cryptography, privacy technologies, and real human behavior all at once. In this episode, he shares how to achieve provable private AI inference, why today's agents are a privacy nightmare (and how to fix it), his vision on intelligence neutrality, and more.
0:00 - Teaser
1:08 - Prelude: Introducing Ken Liu
1:41 - Monologue: The Open Anonymity Project
3:41 - Ken’s Path to Privacy Research
6:31 - The Biggest Privacy Concern for LLM Users
9:39 - Three Perspectives on Tackling AI Privacy
10:57 - “AI presents a Uniquely Worse Privacy Problem”
13:44 - The Open Anonymity (OA) Project: Unlinkable Inference
17:50 - Blind Signatures as Unlinkable Authentication
20:52 - Secure Inference Proxies
28:31 - Threat Model in the OA Project
31:39 - What If People Give Away Information In Their Prompts
35:58 - OpenClaw, Privacy Nightmare In Agents
43:00 - The Stories Behind the OA Project
50:14 - Intelligence Neutrality
52:22 - Safety Concerns in a World with Private AI Inference
2
6
32
7,524
Michael Ryan retweeted
May 5
EP4 of the AM Podcast (@augmind_fm) is out!
This time, we sit down with Ken Liu (@kenziyuliu) — Stanford CS PhD student and creator of The Open Anonymity Project — to dig into one of the most pressing problems in AI: privacy.
Ken's take? AI isn't just another privacy risk. It's a uniquely worse one. And he's actually building a provable approach to fix it.
In this conversation, we get into:
- Why LLMs create a privacy problem unlike anything we've seen before
- Three perspectives on AI privacy (deep learning, cryptography, differential privacy)
- The Open Anonymity Project — unlinkable inference, blind signatures, and secure proxies
- Why today’s agents (e.g., OpenClaw) are privacy nightmare and how to fix it
- Intelligence neutrality and what private AI inference means for safety
- And more!!
Privacy in AI is a topic a lot of people are worried about but few are actually building solutions for. Hope it offers something new whether you're building AI products or just using them!
“In the past, with social media or web search, you are like, here are some specific keywords, here are some posts that I am okay to share with the world; whereas with AI, it feels like you are private, it feels like you are talking to an entity that won’t reveal your information.”
For EP4, we welcome @kenziyuliu, Stanford CS PhD student and creator of The Open Anonymity Project. Ken approaches AI privacy from angles most researchers don't: deep learning, applied cryptography, privacy technologies, and real human behavior all at once. In this episode, he shares how to achieve provable private AI inference, why today's agents are a privacy nightmare (and how to fix it), his vision on intelligence neutrality, and more.
0:00 - Teaser
1:08 - Prelude: Introducing Ken Liu
1:41 - Monologue: The Open Anonymity Project
3:41 - Ken’s Path to Privacy Research
6:31 - The Biggest Privacy Concern for LLM Users
9:39 - Three Perspectives on Tackling AI Privacy
10:57 - “AI presents a Uniquely Worse Privacy Problem”
13:44 - The Open Anonymity (OA) Project: Unlinkable Inference
17:50 - Blind Signatures as Unlinkable Authentication
20:52 - Secure Inference Proxies
28:31 - Threat Model in the OA Project
31:39 - What If People Give Away Information In Their Prompts
35:58 - OpenClaw, Privacy Nightmare In Agents
43:00 - The Stories Behind the OA Project
50:14 - Intelligence Neutrality
52:22 - Safety Concerns in a World with Private AI Inference
6
12
5,790
May 4
Just released EP4 of the AM Podcast (@augmind_fm)! 🎙
I had a ton of fun talking with Ken Liu @kenziyuliu, creator of the Open Anonymity Project! Ken is an expert in both privacy technologies and AI, and there isn’t anyone I would trust more to keep my AI conversations private and secure.🔒
Listen for a deep dive into the algorithms that power Open Anonymity’s privacy guarantees and for why Ken believes LLMs create a uniquely concerning privacy threat.
“In the past, with social media or web search, you are like, here are some specific keywords, here are some posts that I am okay to share with the world; whereas with AI, it feels like you are private, it feels like you are talking to an entity that won’t reveal your information.”
For EP4, we welcome @kenziyuliu, Stanford CS PhD student and creator of The Open Anonymity Project. Ken approaches AI privacy from angles most researchers don't: deep learning, applied cryptography, privacy technologies, and real human behavior all at once. In this episode, he shares how to achieve provable private AI inference, why today's agents are a privacy nightmare (and how to fix it), his vision on intelligence neutrality, and more.
0:00 - Teaser
1:08 - Prelude: Introducing Ken Liu
1:41 - Monologue: The Open Anonymity Project
3:41 - Ken’s Path to Privacy Research
6:31 - The Biggest Privacy Concern for LLM Users
9:39 - Three Perspectives on Tackling AI Privacy
10:57 - “AI presents a Uniquely Worse Privacy Problem”
13:44 - The Open Anonymity (OA) Project: Unlinkable Inference
17:50 - Blind Signatures as Unlinkable Authentication
20:52 - Secure Inference Proxies
28:31 - Threat Model in the OA Project
31:39 - What If People Give Away Information In Their Prompts
35:58 - OpenClaw, Privacy Nightmare In Agents
43:00 - The Stories Behind the OA Project
50:14 - Intelligence Neutrality
52:22 - Safety Concerns in a World with Private AI Inference
3
7
38
9,623
Michael Ryan retweeted
New episode of the AM podcast dropping soon!
In EP4, we sat down with @kenziyuliu, CS PhD student at @StanfordAILab and creator of The Open Anonymity Project, to talk about the privacy layer of personal intelligence.
Here's a preview 😃
1
17
39
9,143

CooperBench will be presented by @michaelryan207 at MALGAI workshop today at 11:10-11:55 as oral and as poster at 12pm.

Introducing the curse of coordination. Agents perform 50% worse in teams than working alone.
People building human-AI collaboration today don't realize why current LLMs fail to be good teammates. We built CooperBench to study this.
For humans, we recognize that teamwork isn't just the sum of individual capability. Communication and coordination often outweigh raw skill.
But for AI? We're only hill-climbing benchmarks that evaluate solo technical abilities.
CooperBench
A benchmark to evaluate agent cooperation in realistic software teamwork tasks.
The setup is intuitive: two agents, two tasks, two VMs, one chat channel (agents can send over arbitrary text, even the entire patch they wrote). We evaluate whether the merged solution from both agents passes the requirements of both tasks.
The curse of coordination
The most striking result: agents perform 50% worse in teams (black line) than working alone (blue line).
Why is this happening?
Is it because they can't use the communication tool? No. They spent 20% of their time sending messages.
The problem? Those messages were repetitive, vague, ignored questions, or straight-up hallucinated.
But bad communication is only part of the story. We found two deeper failures:
Commitment: Agents don't do what they promised.
Expectations: Agents don't expect others to keep promises either.
Without these, cooperation collapses.
However, there is a silver lining
We also find emergent coordination behaviors, e.g. role division, resource division, and negotiation, which gives us hope that we can use reinforcement learning to improve coordination.
What's next?
It is true that highly-engineered multi-agent orchestration could largely sidestep the coordination problem. However, we care more about the AI's capability: if we truly want AI to be our teammates, we need them to be natively capable of effective communicating and coordinating.
Two agents on software tasks is just the beginning. The real goal: agents that can cooperate with us well enough to actually empower us.
CooperBench is our first step. If you're working on this too, let's talk.
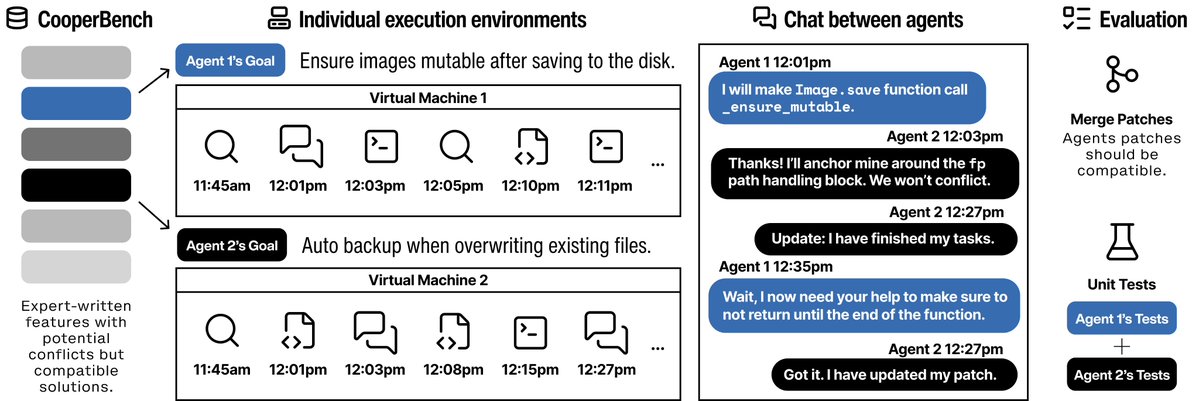
ALT Diagram of CooperBench. CooperBench draws two features from the feature pool for two agents to execute in separate VMs. The agents are also given a chat tool for them to coordinate. Finally, we evaluate whether the merged patch passes both of their feature tests.
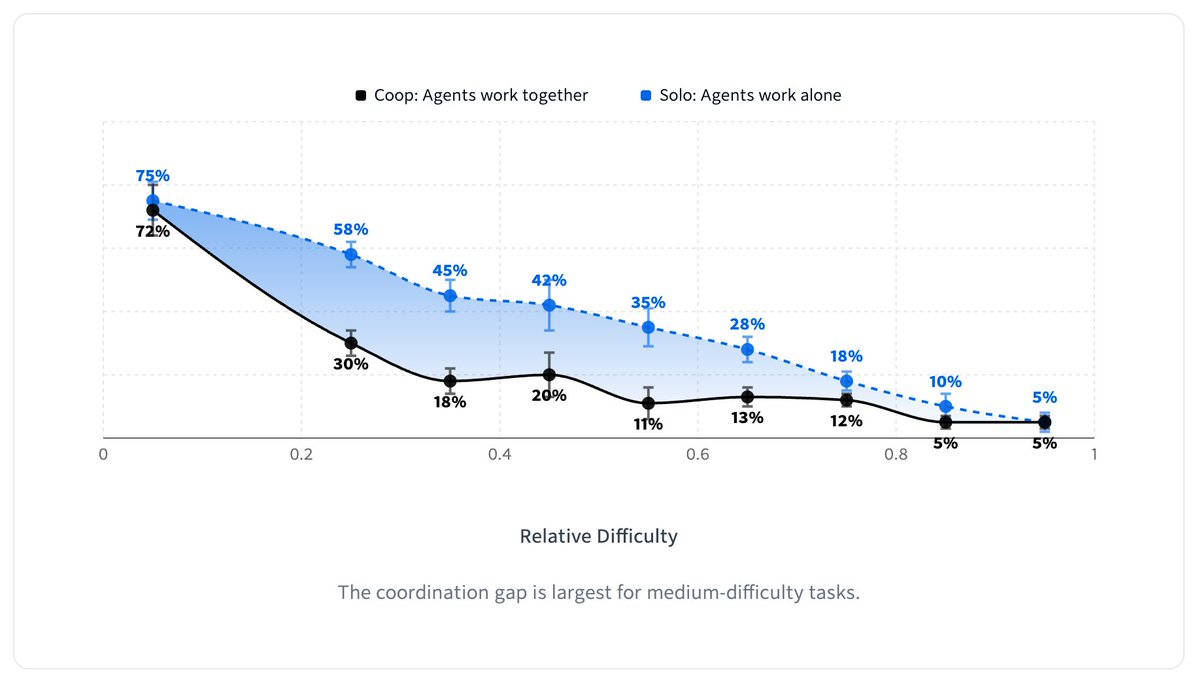
ALT A snap shot from https://cooperbench.com. It shows that the middle-difficulty tasks are the ones with largest coordination gap. But the gap generally holds across difficulties.
2
18
1,944