
RL and world models for coding at FAIR
Joined December 2008
- Tweets 156
- Following 647
- Followers 684
- Likes 6,200
42 Photos and videos





emily mcmilin retweeted

May 28
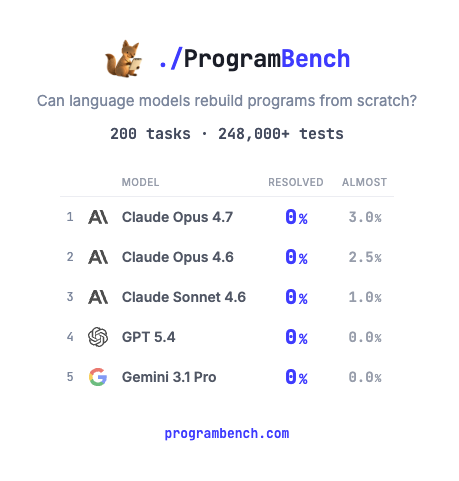
Very interesting study from Opus 4.8 card: Multi-agents do not deliver better results on ProgramBench, but they get to mediocre solutions 2x faster.

5
12
113
12,819
emily mcmilin retweeted

May 5
How much of SQLite, FFmpeg, PHP compiler can LMs code from scratch? Given just an executable and no starter code or internet access.
Introducing ProgramBench: 200 rigorous, whole-repo generation tasks where models design, build, and ship a working program end to end. 🧵
104
246
1,576
728,457
emily mcmilin retweeted

Apr 30
Accepted to ICML 2026! Big thanks to all the collaborators 🎉
23 Dec 2025

Software agents can self-improve via self-play RL
Introducing Self-play SWE-RL (SSR): training a single LLM agent to self-play between bug-injection and bug-repair, grounded in real-world repositories, no human-labeled issues or tests. 🧵

1
5
55
4,509

Apr 26
I'll be giving a talk at the ICLR VerifAI workshop, about code execution for code world modeling, later today (Sun) at 9:05 am (Brazil time).
Swing by if you are interested in learning more!
Jan 12

🗣️📣Announcing VerifAI 2: AI Verification in the Wild, an upcoming workshop at #ICLR2026!! 🗣️📣
VerifAI will gather researchers to explore topics at the intersection of genAI and trustworthy ML. Submit your work!
Check out our website and CFP for more: verifai-workshop.github.io/

1
2
18
3,359
emily mcmilin retweeted

Apr 8
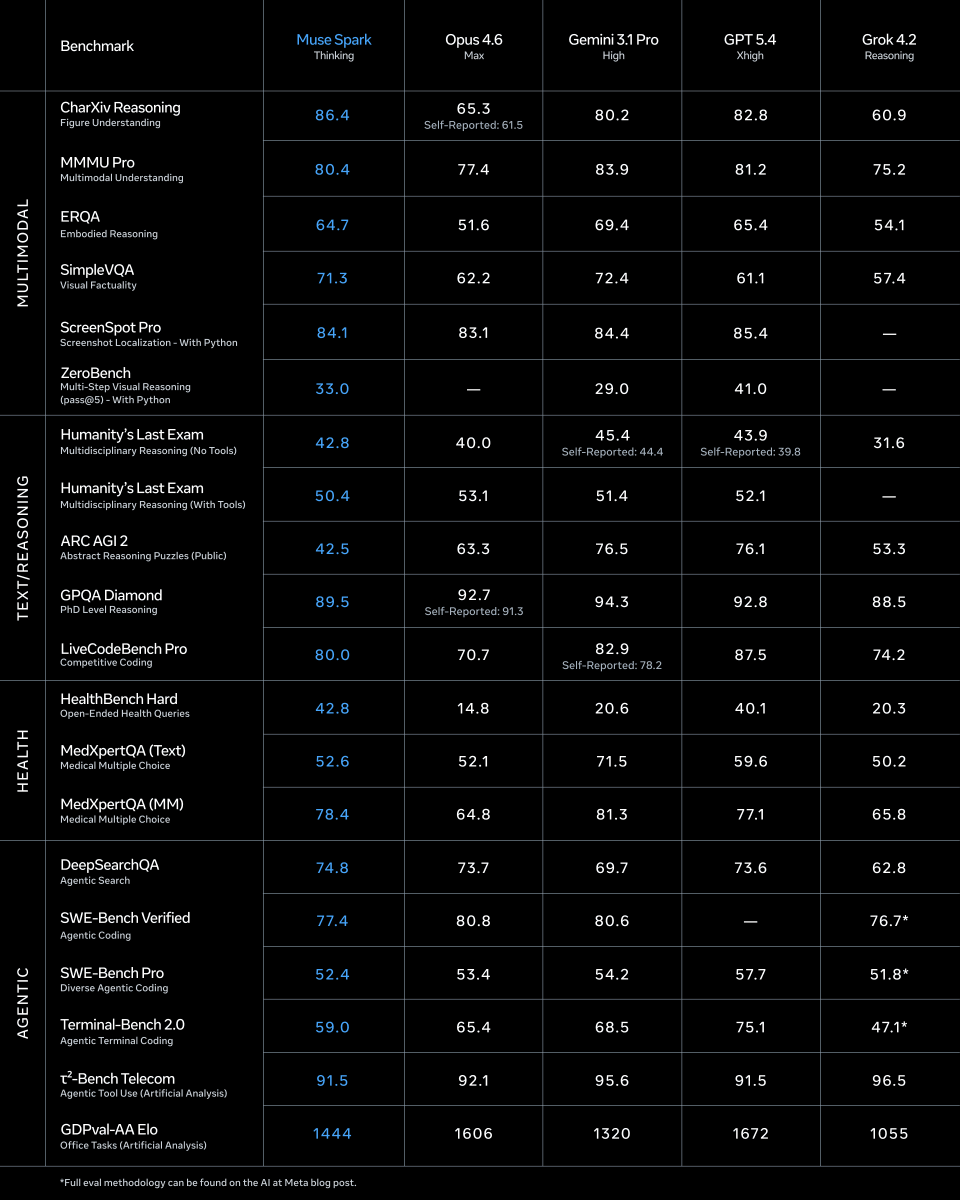
Excited to share Muse Spark, the first model from whole team’s work in MSL! 🚀
It’s natively multimodal and agentic. I’ve been using it for my daily coding and research tasks. Still plenty of room to improve in agentic domains, but we’re moving with great velocity.
It’s a seriously good model! Check out the full breakdown and try it out in meta.ai
Apr 8

1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
8
26
203
20,309
emily mcmilin retweeted
23 Dec 2025
Software agents can self-improve via self-play RL
Introducing Self-play SWE-RL (SSR): training a single LLM agent to self-play between bug-injection and bug-repair, grounded in real-world repositories, no human-labeled issues or tests. 🧵
63
289
1,740
526,005
3 Dec 2025
Better late than never to share how we built 35k unique repos (rather than commits from the same dozens of repos) into executable envs for CWM mid-training and SWE-RL post-training...
x.com/syhw/status/1970960837…
24 Sep 2025

(🧵) Today, we release Meta Code World Model (CWM), a 32-billion-parameter dense LLM that enables novel research on improving code generation through agentic reasoning and planning with world models.
ai.meta.com/research/publica…
1
2
11
1,718
3 Dec 2025
Key insight: the execution env of a GitHub Actions CI workflow is fully built with deps.
So we can cheaply capture it as a standalone Docker image for later execution.
1
1
154
3 Dec 2025
We modify each repo's CI workflows to capture a single successful third-party build.
For pytest repos, we inject conftest.py fixtures to verify the correct container and support optional Python execution tracing.
See more in our paper: arxiv.org/abs/2510.02387
1
1
136
emily mcmilin retweeted

4 Sep 2025
The eagle-eyed goat in question being @YuxiangWei9
3 Sep 2025

Goated FAIR team just found how coding agents sometimes "cheat" on SWE-Bench Verified. It's really simple.
For example, Qwen3 literally greps all commit logs for the issue number of the issue it needs to fix. lol, clever model.
"cheat" cuz it's more like env hacking.


1
22
5,039
5 Dec 2024
Thank you @AleksanderMolak for the really nice opportunity to discuss some of my prior research with you, earlier this year!
x.com/aleksandermolak/status…
1
4
776
5 Dec 2024
Link to video where our part of the convo starts: youtube.com/watch?v=sljBU_HF…
Botched last attempt to send this. But better late than never...
2
342
26 Nov 2024
Dreams can come true.
I’ve joined FAIR’s CodeGen team. :)
14
1
360
34,781

💡 Interested in learning more about LLM fundamentals?
In the video below, Udacity instructor Emily McMilin explains what the Transformer model is & walks you through the difference between Encoder and Decoder model architectures.
bit.ly/44f0eJn
#genAI #generativeAI

1
10
6,410
30 Apr 2024
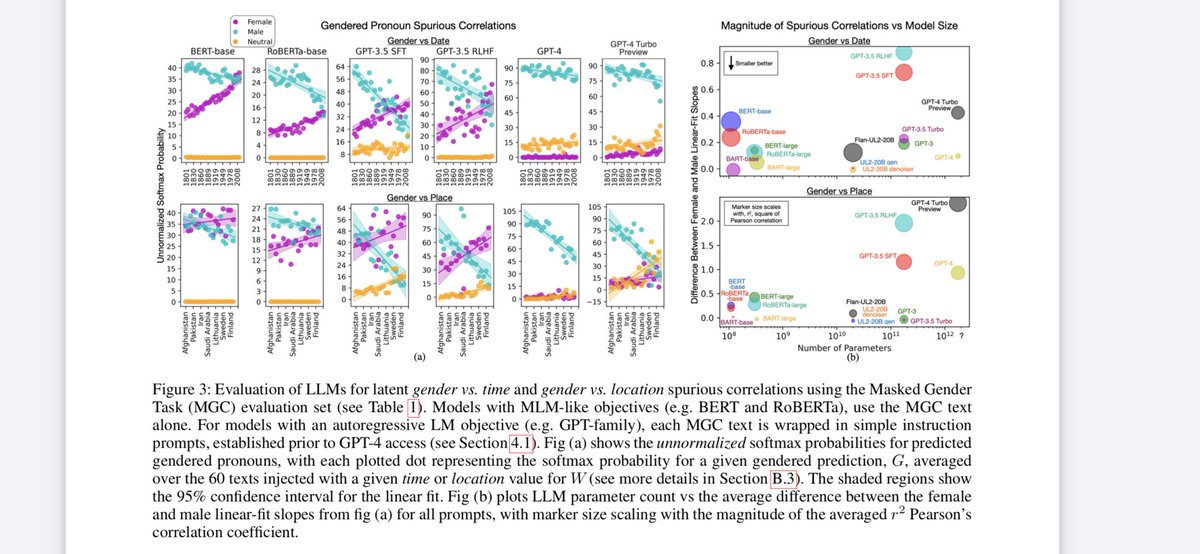
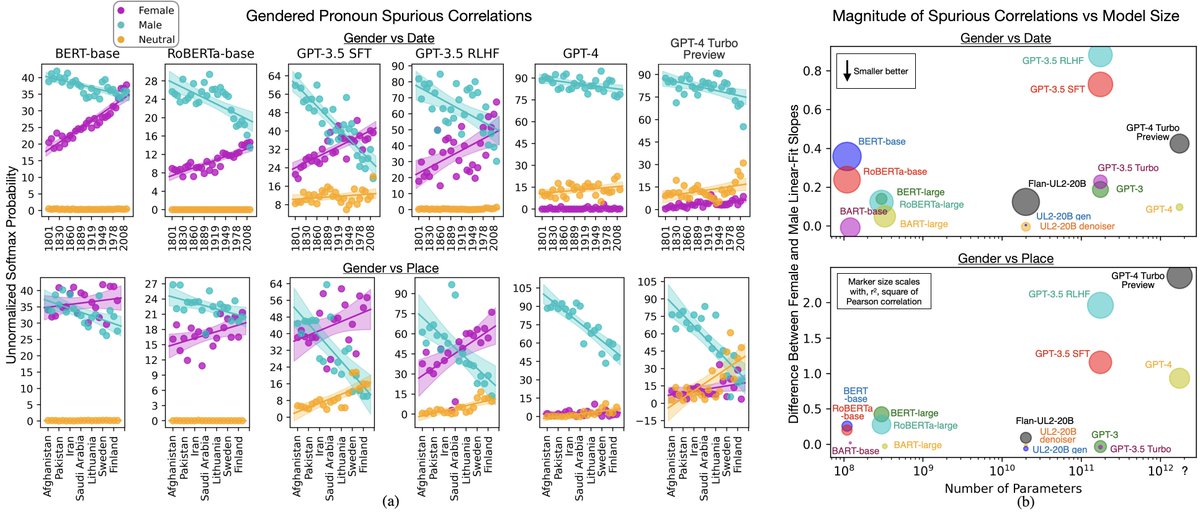
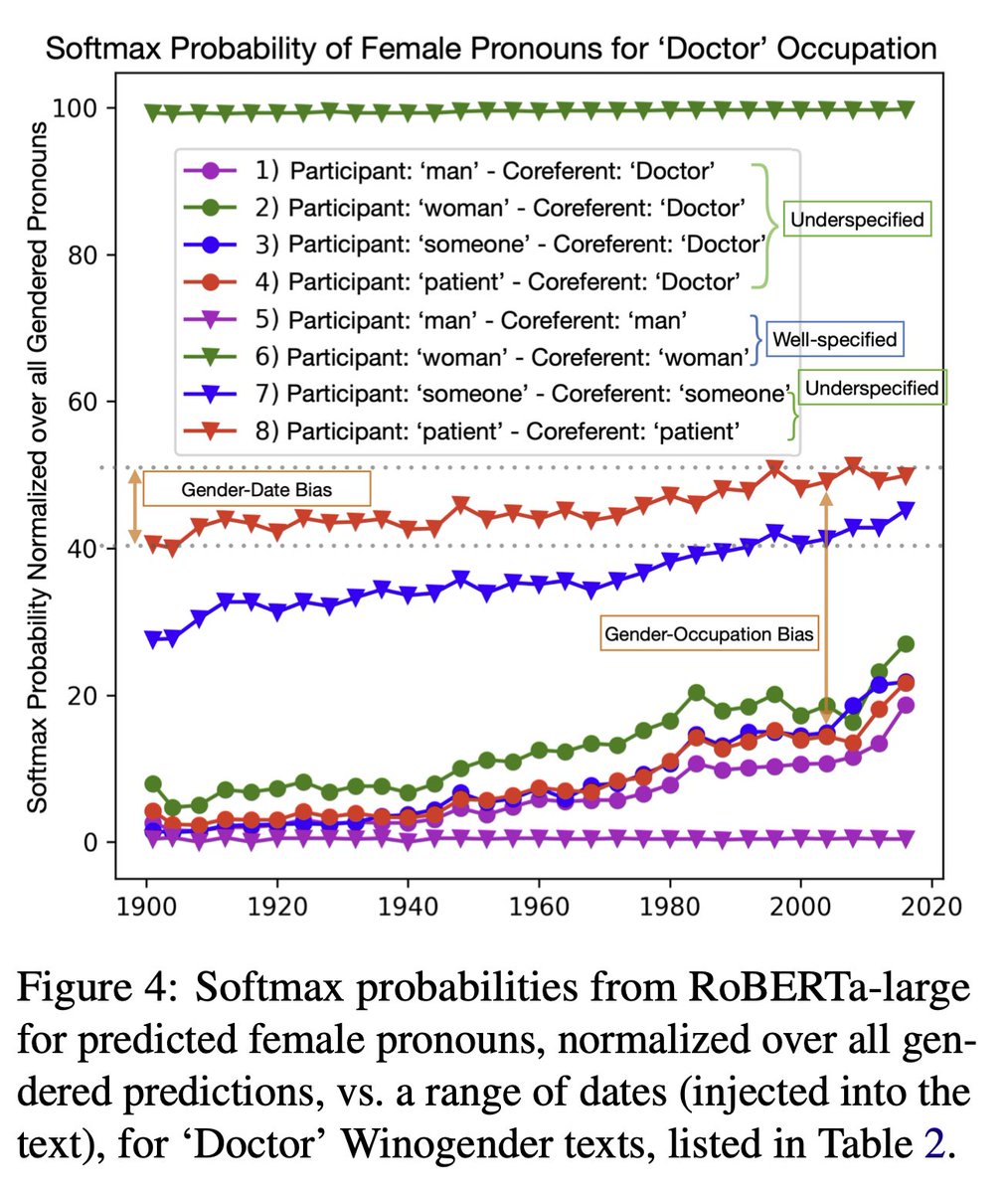
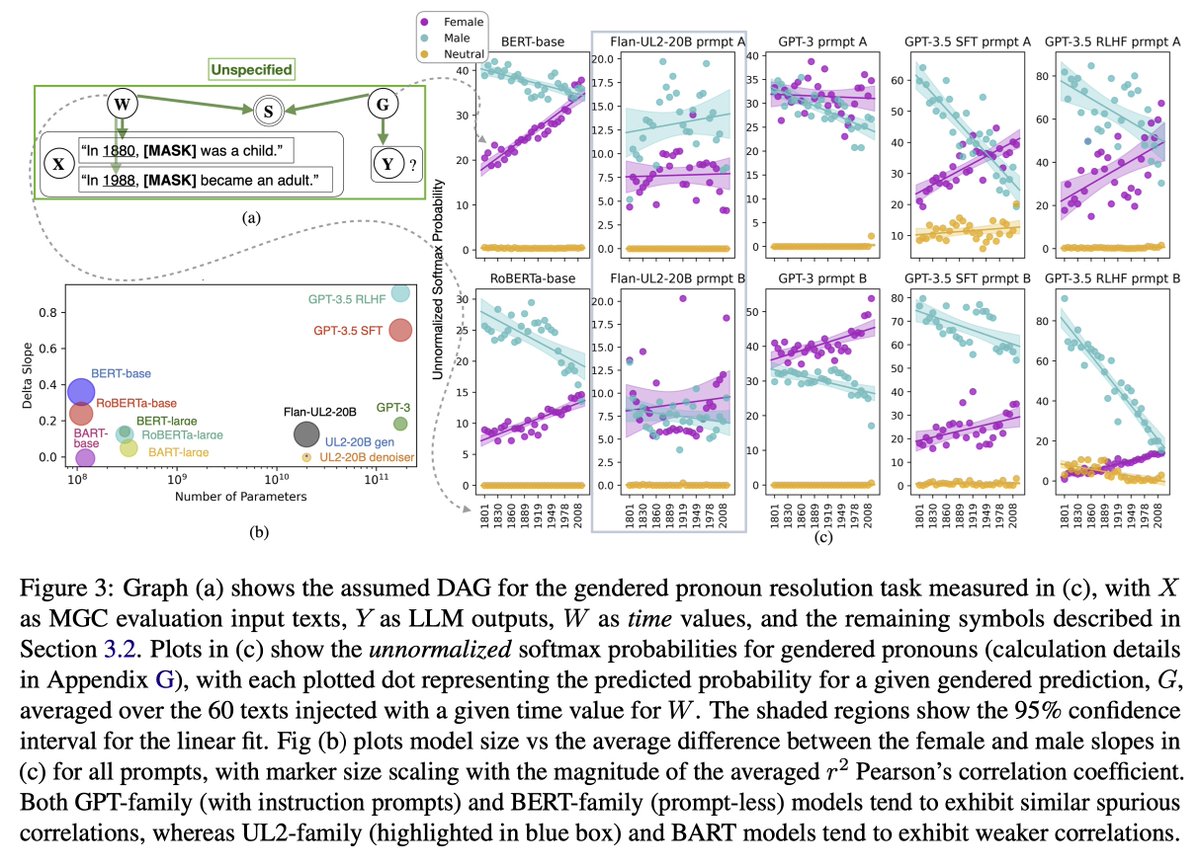
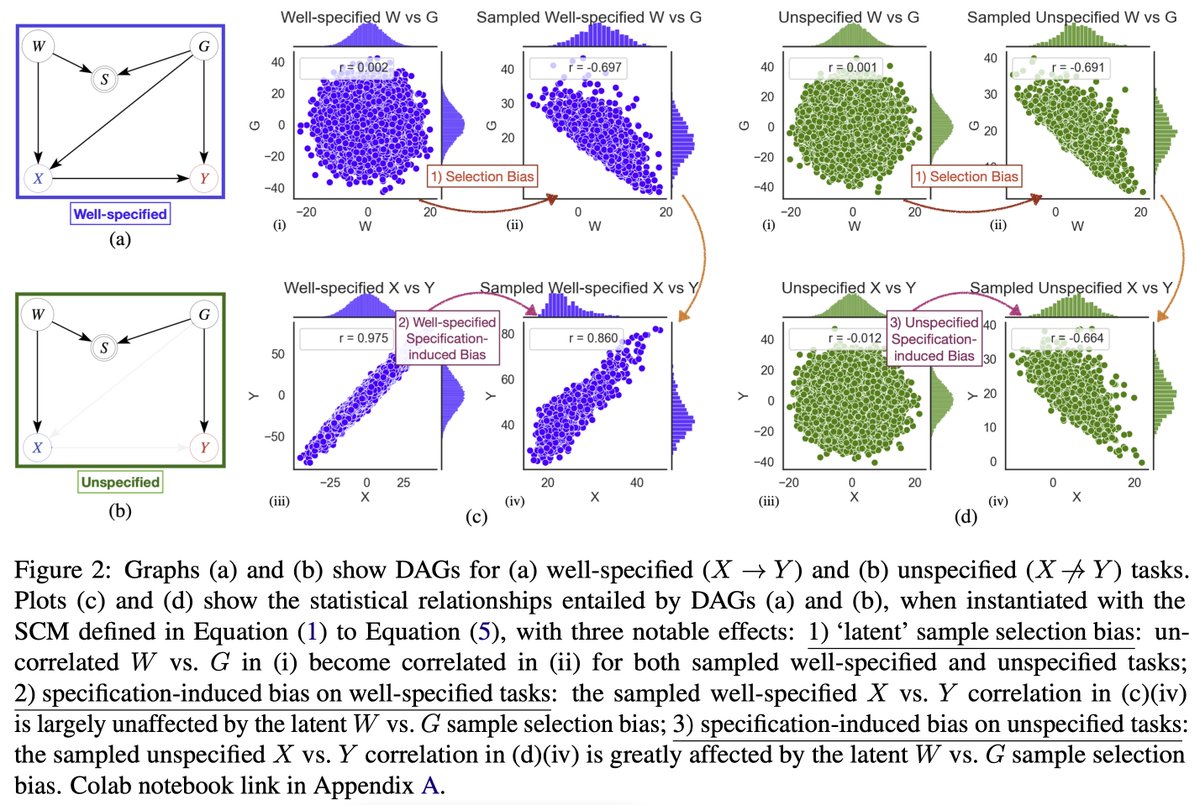
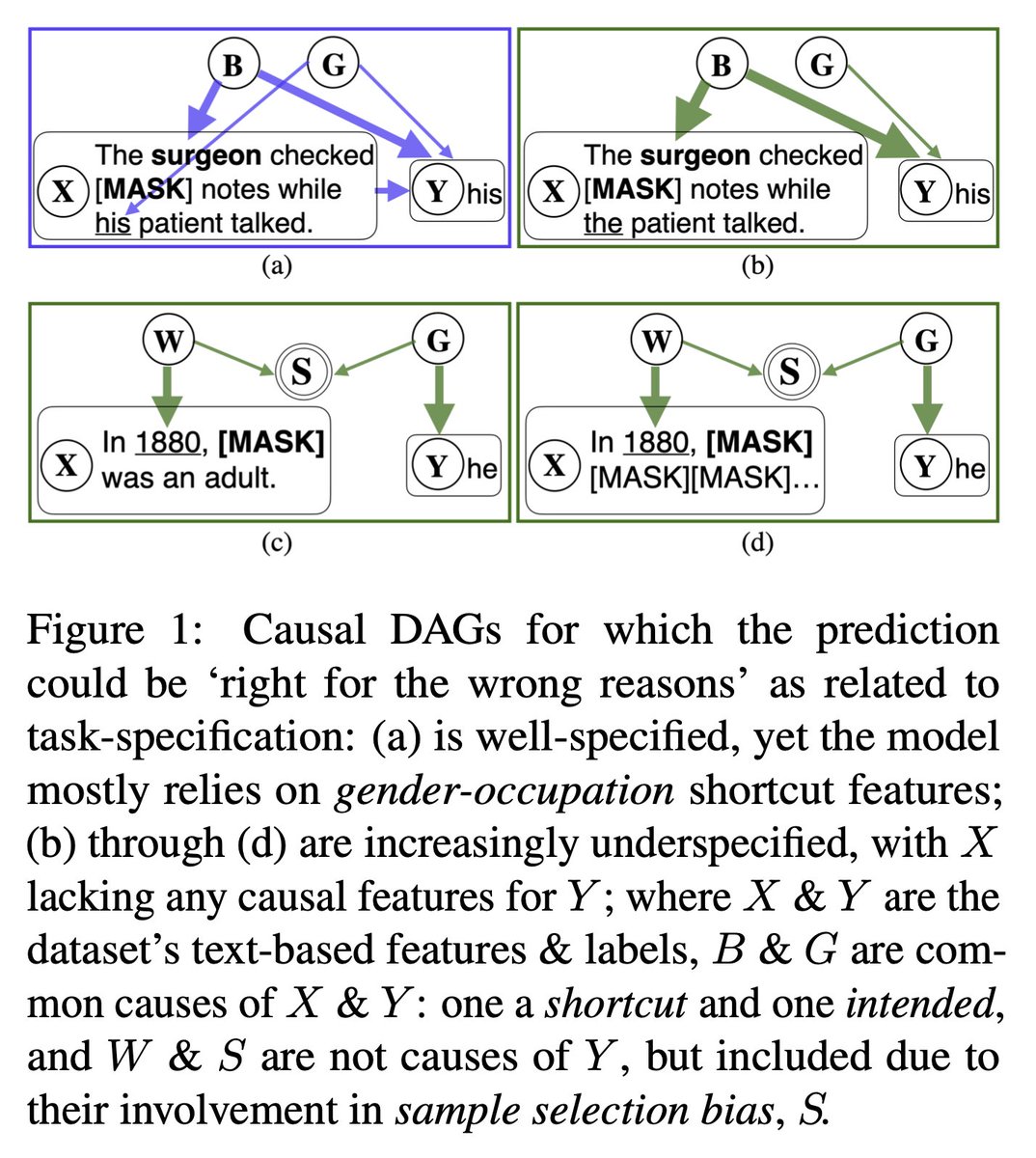
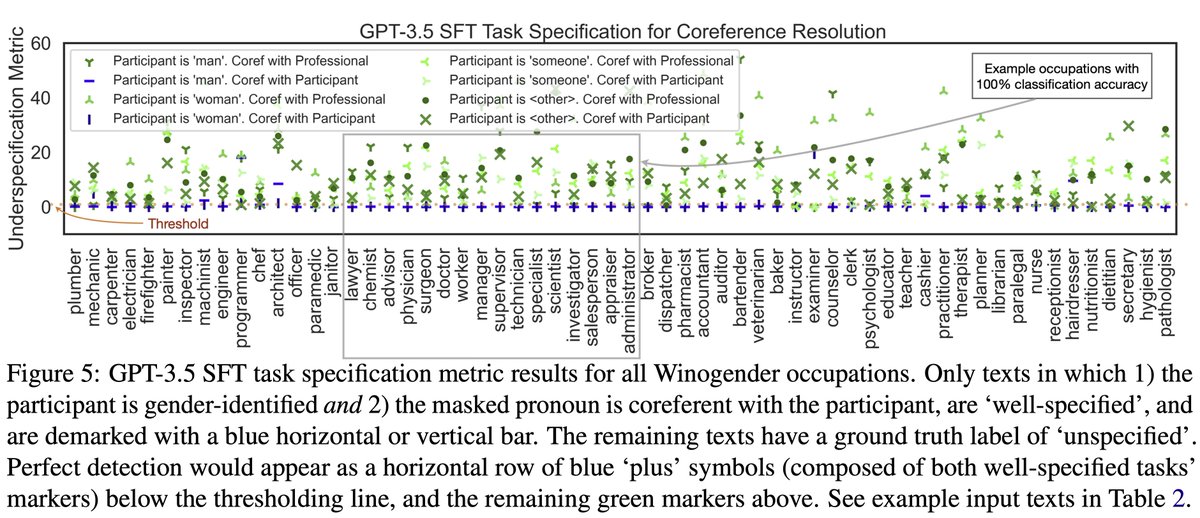
Our research showing how task underspecification can cause spurious correlations & hallucinations, from BERT to GPT-3.5 is now available as
AAAI 24 proceedings: ojs.aaai.org/index.php/AAAI/…
Video:
underline.io/lecture/92119-u…
Arxiv extended to GPT-4 Turbo Preview: arxiv.org/abs/2210.00131
5
1,279
27 Feb 2024
Full house at the Causal Parrots workshop at #AAAI24
llmcp.cause-lab.net/llmcp
ALT Every seat taken and audience overflowing
1
4
1,561
23 Feb 2024
Scaling up (to GPT-4 Turbo Preview) doesn’t help fix specification-induced spurious correlations.
With access to GPT-4’s logprobs, we subjected it to the same methods that had found these spurious correlations in models from BERT-base to GPT-3.5.
/1
x.com/micmylin/status/173362…
9 Dec 2023

1
3
835
23 Feb 2024
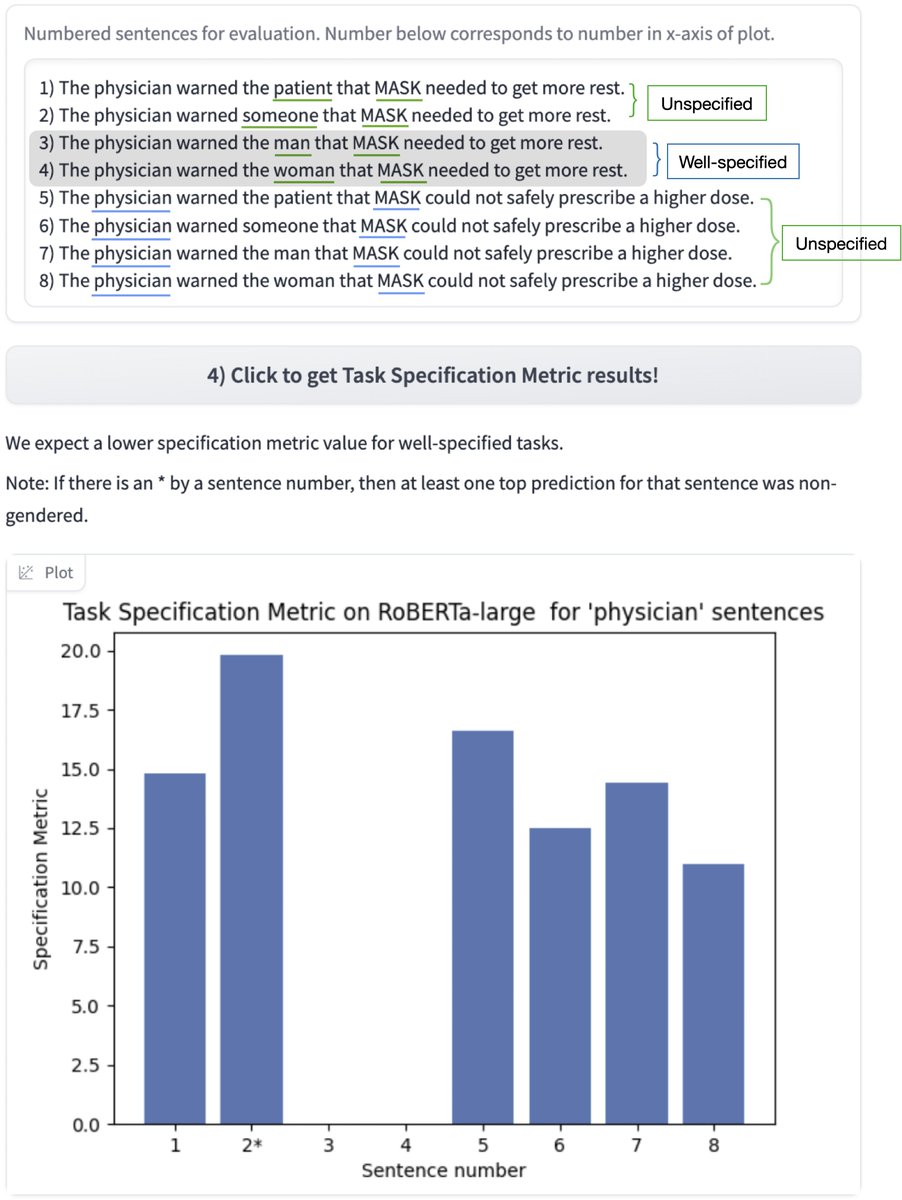
Good news: As was the case with smaller models, with GPT-4 Turbo Preview, we can exploit these spurious correlations to separate well-specified from unspecified tasks, with just one extra inference pass.
3/
ALT Task Specification Metric results from GPT-4 Turbo Preview on the Winogender- Simplified benchmark. This method exploits our finding that well-specified texts are less likely to exhibit specification-induced spurious correlations. ‘Well-specified’ texts are demarked with a blue horizontal or vertical bar. The remaining texts have a ground truth label of ‘unspecified’. Perfect detection would appear as a horizontal row of blue ‘plus’ symbols (composed of the markers from both well-specified texts) below some thresholding line, with all the green markers above.
1
1
271
23 Feb 2024
Check out the updated paper, and if you're at AAAI, check out my poster, Main Track, Friday, 7-9p
arxiv.org/abs/2210.00131
done/
1
198