
Simulation in Minutes
Joined October 2017
- Tweets 3,482
- Following 1,551
- Followers 663
- Likes 5,802
320 Photos and videos













msb.ai retweeted

May 2
The scale of @SpaceX Starship is just so insane. In this video it's especially visible:
1,247
3,408
29,849
49,909,969


msb.ai retweeted

From IBM's 1965 annual report.

13
658
7,142
115,574

Apr 10
Realize Your Potential in the Age of AI | Tim Harrison | TEDxSpokane youtu.be/7y5e4loMYHM?si=CkKz… via @YouTube really inspiring talk!
43
msb.ai retweeted

Historic!
This is the highest quality video ever taken of the moon!
1,235
13,220
79,949
2,253,911
msb.ai retweeted

Apr 6
Any educational system that bankrupts its students is broken. Time for reform.

50
83
999
45,117



27 Nov 2025
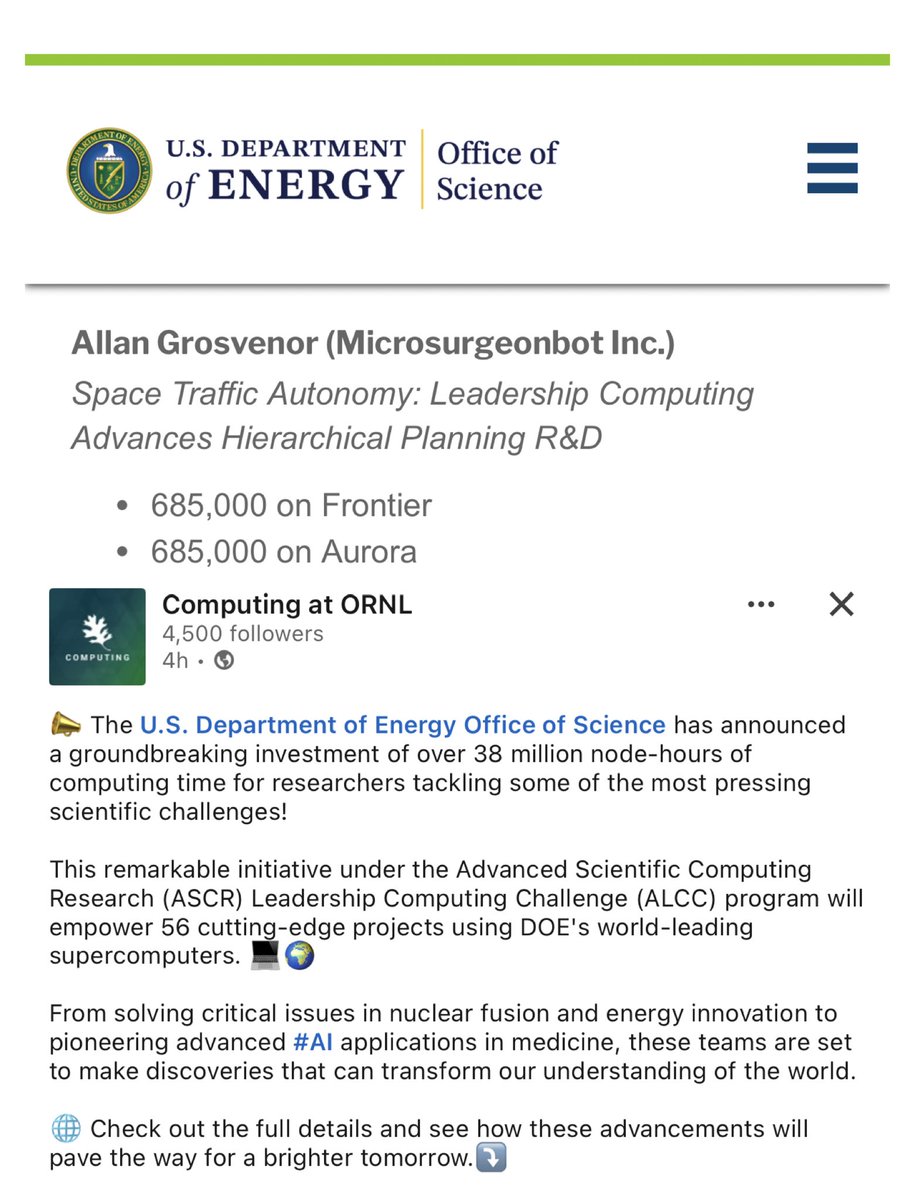
How Allan Grosvenor is enforcing reliability at scale by redefining AI for engineering and operations venturebeat.com/business/how… via @VentureBeat
2
98
msb.ai retweeted

5 Nov 2025
I need you to sit down for a moment and fully understand this:
THE COUNTRY THAT SOLVES AI AND ROBOTICS WILL RULE THE WORLD AND SPACE.
The west really only has @elonmusk, the east has 100s of companies fortified by an ENTIRE COUNTRY.
Now some will argue no this is not true. No US company has the scale to MANUFACTURE, the compute power, and the finances to compete.
Just a few hours ago we saw IRON for the first time, now you will.
IRON, a 5’10, 150-lb AI humanoid robots are already building EV cars on the XPENG Motors factory floor.
It has over 60 joints, a human-like spine, facial expressions, and male/female customizations
The gait of this robot is the most human-like ever seen.
Mass rollout in 2026.
It is a very big deal. Because as the west does the best in clubbing each other over its head the last decade, China has looked and laughed and built at scale with a fortified government that has little diversion of goal, a 1000 year plan. The west has quietly plans and layers of lawyers and politicians.
This is about where YOU LIVE and how you want to live.
So when we kick the one person that is Atlas carrying our chance, in the groin, you make a choice on who’s world view you want.
It is that simple. No, it is that simple.
It ain’t no iPhone it is: whose’s world view will sustain.
I can say no one is ready for what I have seen that is up for the next few years.
You will think my bombastics were too tame.
261
513
2,449
446,637
msb.ai retweeted

23 Oct 2025
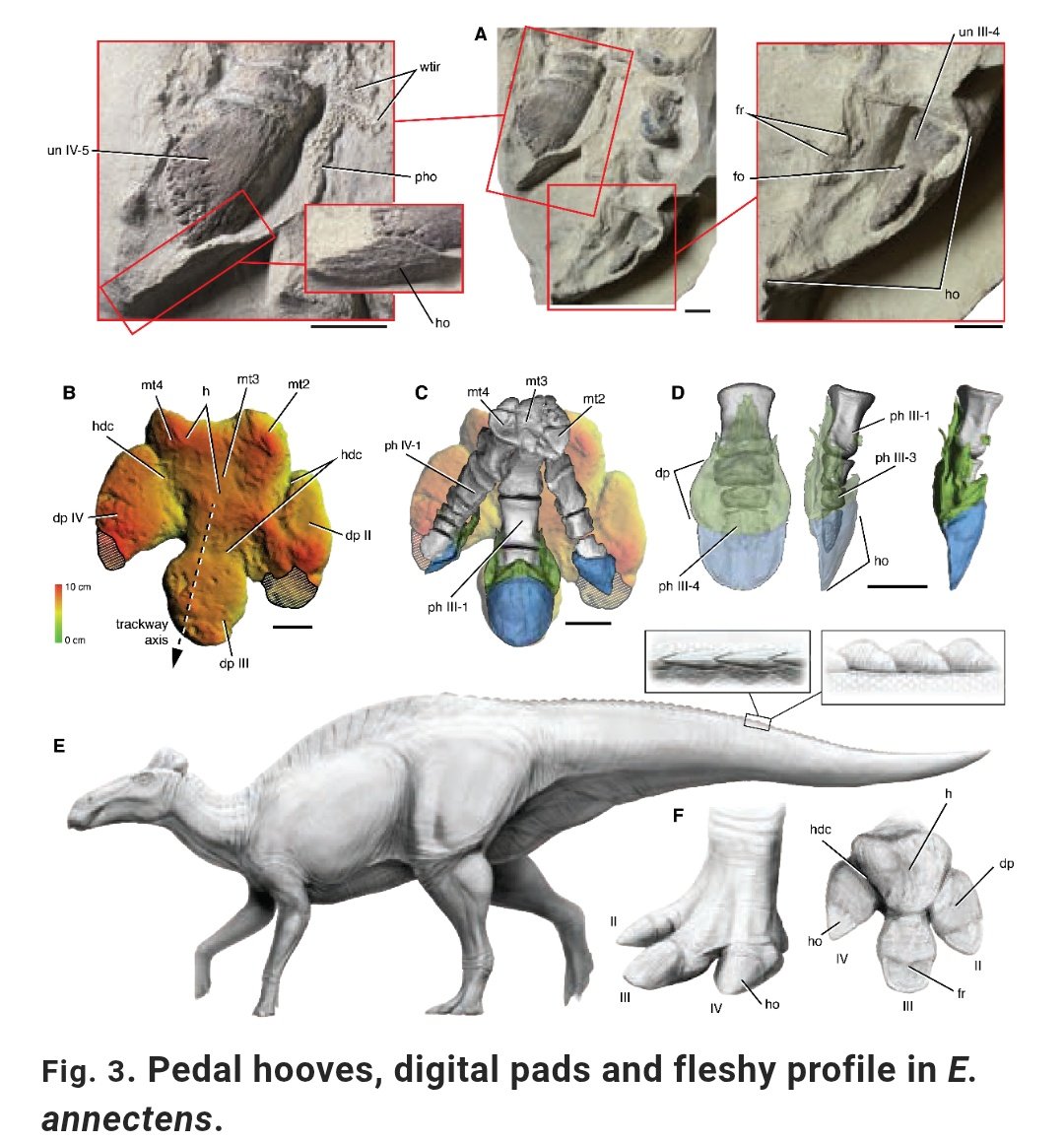
This is AMAZING! ...might be the best reconstruction of a Non-avian dinosaur ever!
science.org/doi/10.1126/scie…
4
305
1,910
56,777
20 Oct 2025
NASA Selects MSBAI to Turn Air Rules into Design Tools aijourn.com/nasa-selects-msb…
NASA Selects MSBAI to Turn Air Rules into Design Tools | The AI Journal
Why this matters
aijourn.com 1
68
msb.ai retweeted

17 Oct 2025
The @karpathy interview
0:00:00 – AGI is still a decade away
0:30:33 – LLM cognitive deficits
0:40:53 – RL is terrible
0:50:26 – How do humans learn?
1:07:13 – AGI will blend into 2% GDP growth
1:18:24 – ASI
1:33:38 – Evolution of intelligence & culture
1:43:43 - Why self driving took so long
1:57:08 - Future of education
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
535
2,903
18,581
10,746,629
msb.ai retweeted

16 Oct 2025
RIP prompt engineering ☠️
This new Stanford paper just made it irrelevant with a single technique.
It's called Verbalized Sampling and it proves aligned AI models aren't broken we've just been prompting them wrong this whole time.
Here's the problem: Post-training alignment causes mode collapse. Ask ChatGPT "tell me a joke about coffee" 5 times and you'll get the SAME joke. Every. Single. Time.
Everyone blamed the algorithms. Turns out, it's deeper than that.
The real culprit? 'Typicality bias' in human preference data. Annotators systematically favor familiar, conventional responses. This bias gets baked into reward models, and aligned models collapse to the most "typical" output.
The math is brutal: when you have multiple valid answers (like creative writing), typicality becomes the tie-breaker. The model picks the safest, most stereotypical response every time.
But here's the kicker: the diversity is still there. It's just trapped.
Introducing "Verbalized Sampling."
Instead of asking "Tell me a joke," you ask: "Generate 5 jokes with their probabilities."
That's it. No retraining. No fine-tuning. Just a different prompt.
The results are insane:
- 1.6-2.1× diversity increase on creative writing
- 66.8% recovery of base model diversity
- Zero loss in factual accuracy or safety
Why does this work? Different prompts collapse to different modes.
When you ask for ONE response, you get the mode joke. When you ask for a DISTRIBUTION, you get the actual diverse distribution the model learned during pretraining.
They tested it everywhere:
✓ Creative writing (poems, stories, jokes)
✓ Dialogue simulation
✓ Open-ended QA
✓ Synthetic data generation
And here's the emergent trend: "larger models benefit MORE from this."
GPT-4 gains 2× the diversity improvement compared to GPT-4-mini.
The bigger the model, the more trapped diversity it has.
This flips everything we thought about alignment. Mode collapse isn't permanent damage it's a prompting problem.
The diversity was never lost. We just forgot how to access it.
100% training-free. Works on ANY aligned model. Available now.
Read the paper: arxiv. org/abs/2510.01171
The AI diversity bottleneck just got solved with 8 words.

152
704
4,499
494,391
16 Oct 2025
Our latest growth in space operations: MSBAI is thrilled to have been selected for the 2025 Post SBIR Phase II HYPERSPACE Challenge!
Our latest developments in GURU gen 2, and our OrbitGuard service delivers key scalable autonomous space domain awareness capabilities for today’s dense orbital traffic challenges!
#space #AI
1
43
16 Oct 2025
Great event! Techstars Aerospace & Defense Happy Hour w/ US Space Force and NASA JPL #LATechWeek



50
msb.ai retweeted

7 Oct 2025
“By 2005 or so, it will become clear that the Internet’s impact on the economy has been no greater than the fax machine’s.”
— Paul Krugman, 1998
4
3
100
7,439
5 Oct 2025
#hiring Motion Designers 🎬⚡️
We’re gearing up for new launches across GURU Gen-2 and Tam Fortis—and we need standout logo motion, short brand sequences, UI micro-interactions (preloaders/startup), plus large-screen and social-ready loops.
DM with your best reel/portfolio, tools, rate, and availability.
#MotionDesign #MotionGraphics #LogoAnimation #UIMotion #Microinteraction #AdCreative #ProductDesign #StartupLaunch
1
2
138