
Joined August 2017
- Tweets 632
- Following 443
- Followers 1,456
- Likes 661
182 Photos and videos















Pinned Tweet

Jun 3
The world's first audio-native AI model is now available as an API.
Velma listens and understands like a human — emotions, tone, intent, rhythm, vocal stress.
Already analyzed 550M hours of conversation for Fortune 500s.
Now open to developers. 🧵
52
56
264
7,080,706
Jun 12
We’ve trained ourselves to question video.
But we still trust voice.
That’s what makes audio deepfakes so dangerous ⚠️
In this clip, our CEO @mpappas74 breaks down why voice is such a powerful attack surface - it’s how we verify identity, talk to banks, recognize people we know.
We don’t second-guess it. We assume it’s real 🤷♀️
And that’s exactly what bad actors exploit 🙅
At @modulate_ai, we’re building for that reality.
1
3
176
Jun 11
One player speaks. Four hear it.
That's roughly the dynamic we uncovered when we analyzed prosocial voice interactions in @CallofDuty®: Warzone™ alongside @Activision - a 1:4 speaker-to-exposed ratio, meaning a single moment of team-supportive communication ripples across an entire squad.
This case study is a reminder that positive social behavior is already present at scale in competitive gaming.
It doesn't need to be manufactured: it needs to be understood, measured, and amplified.
1
2
167
Jun 11
We built ToxMod to help with exactly that.
Full case study here: modulate.ai/case-studies/pro…
107
Jun 9
The hardest part isn’t building a model.
It’s making it flexible without breaking it.
Here our CTO @whuffman shares one of the biggest technical challenges we’ve tackled at @modulate_ai:
Moving from detecting a single category of behavior → to understanding any unwanted behavior, across conversations.
All while keeping accuracy high, latency low, and costs in check ✅
That meant rethinking the system entirely
Not just a model.
A configurable voice intelligence platform💡
Because real-world use cases don’t fit into fixed labels - and the tech shouldn’t have to either.
1
1
240
Jun 9
Want to see how configurable voice intelligence works in practice?
Explore more: modulate.ai/?utm_source=link…
128
Jun 8
Since launching the Velma API, we've been hearing from developers building things we didn't anticipate.
That's the best possible sign.
When you build a model that actually understands speech - not just transcribes it - the use cases don't stop at the ones you designed for.
Developers are finding signal in their audio that their previous pipelines were structurally incapable of surfacing.
That's not a feature. That's what happens when the foundation is right.
If you haven't looked at what Velma can do for your voice stack yet - now's a good time.
Test the API. 1000 free credits on us: modulate.ai/api/velma
1
2
184
Jun 5
We’re heading to CCW 2026 🙌
If you're attending, stop by and meet the team to see how Modulate is helping organizations unlock deeper voice intelligence, real-time insights, and better customer conversations.
See you there!
1
2
255
Jun 5
Ever misread someone just because of their tone? 😶
Now imagine that at scale - with AI.
In this clip, our CEO @mpappas74 gets into why voice isn’t just words. It’s pauses, emphasis, emotion - all the subtle signals people naturally interpret.
Miss that, and you’re misinterpreting the conversation itself.
That’s the layer we focus on at @modulate_ai - not just the spoke word, but the entirety of the conversation.
1
1
1
198
Jun 5
Curious: what’s one moment where tone completely changed how you interpreted something? 👀
1
107
Jun 3
The world's first audio-native AI model is now available as an API.
Velma listens and understands like a human — emotions, tone, intent, rhythm, vocal stress.
Already analyzed 550M hours of conversation for Fortune 500s.
Now open to developers. 🧵
52
56
264
7,080,706
Jun 3
3/ You define what to find. Tell Velma what to listen for in plain language — it handles the rest.
→ Detect fraud in real time from voice alone
→ Flag churn risk before a customer says "cancel"
→ Score agent performance without reading a transcript
→ Identify dozens of emotions and 150 built-in behaviors
1
5
876
Jun 3
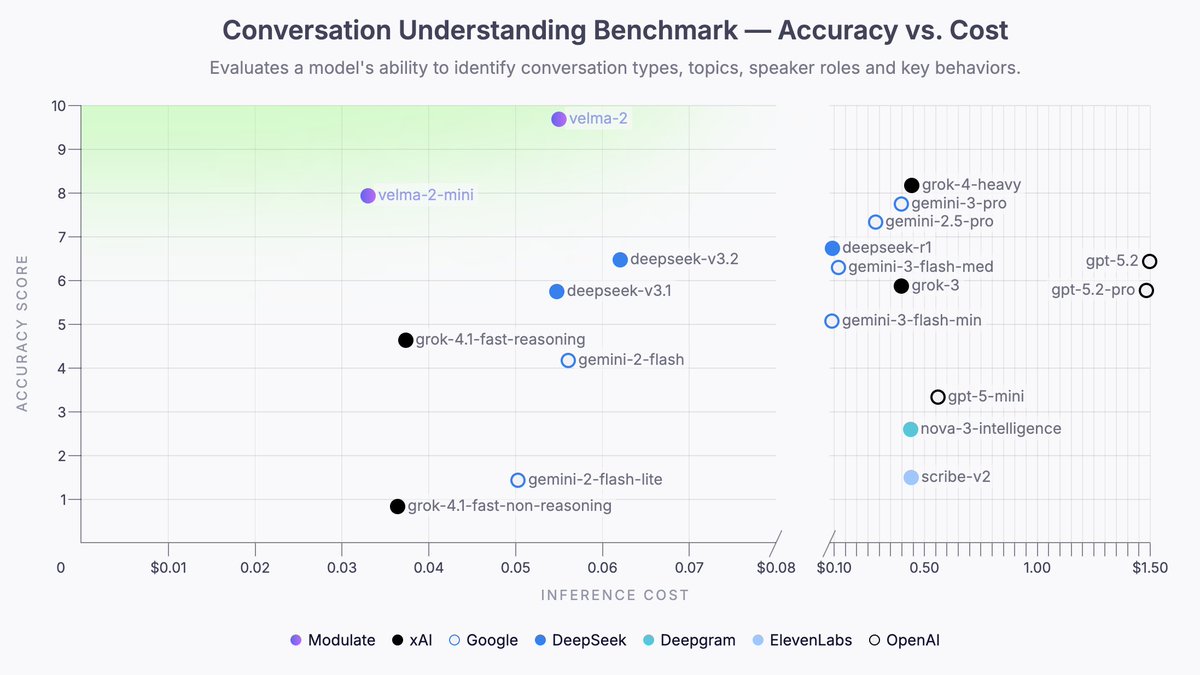
4/ Highest accuracy. 10x lower cost.
On 100 real conversations, Velma's audio-native ELM architecture out-answered frontier LLMs across dozens of questions — at a fraction of the cost.
Battle-tested on 550M hours. Built for production, not demos.
Full benchmark ↓
4
591
Jun 3
550 million hours of real-world audio.
Not clean studio recordings. Not scripted datasets.
Messy, real conversations - the kind where tone, hesitation, and what isn't said matters as much as the words.
We trained on all of it. Announcing what we built very soon 💪
1
96
Jun 2
Where’s the line between trash talk and harassment? 👀
In games like @CallofDuty, that line matters - a lot.
In this clip, our CTO @whuffman breaks down how modern systems actually tell the difference: not just by looking at words, but by understanding tone, intent, and context.
Because “you suck” can be a joke… or something very different.
That’s the challenge AND the opportunity that comes with voice intelligence.
At @modulate_ai, we’re building systems that can make that distinction and help keep spaces competitive and safe.
3
2
292
Jun 2
See how we’re building voice intelligence to understand context - not just keywords: modulate.ai/?utm_source=link…
121
Jun 2
Transcription is not comprehension.
The entire voice AI industry is built on that confusion.
We're about to make that very clear ⏱️
1
69
Jun 2
We've been sitting on something 👀
For the last few months, the question we've heard more than any other - from developers, from builders, from teams who'd seen what Velma can do - has been some version of: when can we actually use this?
The answer is almost here ⏱️
More very soon 🚀
1
67