
@MIT alum | Formerly @NASA @NASAJPL | Current CTO & Co-founder of @Modulate_ai
Joined August 2015
- Tweets 33
- Following 74
- Followers 22
- Likes 23
9 Photos and videos







Pinned Tweet

Apr 19
@elonmusk You're priced too high - SOTA transcription is already 3x cheaper modulate.ai/api-overview

3
8
405
Jun 8
Deepfake fraud attempts surged 1,300% between 2024 and 2025 📈
The reason? Synthetic voice is cheap to generate.
And most bank fraud stacks are architecturally blind to it.
They're built around transaction data - what happened after the call.
But the attack has moved. It's happening during the call.
The urgency script. The spoofed voice. The social engineering that gets an agent to bypass verification before a single flag gets raised.
A transcript won't catch that ❌
Rules won't catch that ❌
You need models that understand voice the way voice actually works - tone, cadence, stress, acoustic anomalies. Not just words.
We wrote a practical breakdown of what real-time voice AI detection looks like in banking: where it plugs in, what it scores, and how it shifts intervention from post-wire to mid-call. (Link in caption)
If you're building in this space, our API is open.
1
1
39
Jun 8
First 1,000 credits on us: modulate.ai/api/deepfake-det…
Blog: modulate.ai/blog/real-time-a…
3
Carter Huffman retweeted

Jun 3
The world's first audio-native AI model is now available as an API.
Velma listens and understands like a human — emotions, tone, intent, rhythm, vocal stress.
Already analyzed 550M hours of conversation for Fortune 500s.
Now open to developers. 🧵
52
56
265
7,125,016
Jun 2
Words are the least interesting part of a conversation.
Tone. Hesitation. What someone almost said.
That's where the meaning lives.
Voice AI that only reads transcripts will never get there.
At @modulate_ai, we built something that does 💪👀
1
6
May 25
If I had to spend the next 5 years on just one problem:
It’d be getting different AI systems to actually work together - in sync, toward a single goal, without breaking accuracy or efficiency.
Feels like we’re still early on that.
At @modulate_ai, this is a big part of how we think about building - not just better models, but better systems.
My answer’s set - curious about yours:
If you could only work on one problem for the next 5 years, what would it be?
10
May 22
The intersection of audio AI is moving fast - and some of the best people building it are right here in Boston.
@modulate_ai is joining Yamaha Music Innovations Fund next Thursday night to bring them all together. Harmonix, Suno, and more under one roof for live demos, real talk, and good conversations.
If this space is on your radar, come hang. Would love to see you there!
bit.ly/4tTLzi3
#BosTechWeek
44
May 18
I think about this a lot:
We get to build technology that impacts millions of people every day.
That’s a rare kind of responsibility - and it doesn’t feel abstract. It shows up in the small decisions, the tradeoffs, the standards we hold ourselves to.
At @modulate_ai, that’s the bar: maximize the good we can do, and be really intentional about where and if we get it wrong.
Grateful for the team, and for the chance to work on problems that actually matter❗🙌
Curious how others think about this - how do you balance moving fast with getting things right?
16
May 11
The most important thing we’re working on at @modulate_ai right now:
Moving beyond narrow detection - toward systems that truly can understand risk in context.
Real-world threats don’t show up in neat categories.
They overlap, evolve, and look different in every conversation.
So instead of building for one slice at a time, we’re focused on a unified layer of voice intelligence: one that interprets what’s actually happening, not just flags keywords.
That shift is where this becomes genuinely useful👏
1
7
May 5
We’re @hackernoon Company of the Week 🏆
As CTO of @modulate_ai, moments like this are really about the team.
Building Velma - a model that actually understands voice at scale - meant solving problems most teams avoid: data quality, architecture, and real-world accuracy in messy audio.
A few signals of what that work has unlocked:
🏅 #1 on @huggingface Speech Arena (98.9% deepfake detection accuracy)
💰 25x better cost efficiency vs foundation models
💻 40M users protected from fraud, harassment, and abuse
Proud of what we’ve built! 🛠️
2
1
1
433
May 4
I got deepfaked.
Someone cloned my voice and used it in a simulated bank transaction - and I couldn’t tell it wasn’t me.
That’s the part that sticks with you.
What did catch it?
Modulate's Velma flagged it with 99.5% confidence.
The gap between what humans can detect and what’s now possible with AI is only getting wider. And we’re not going to out-train billion-dollar labs on instinct alone.
We need technology that can meet that level - and defend against it in real time.
That’s exactly what we’re building at @modulate_ai
1
2
51
May 4
Curious how Velma detects deepfakes in real time?
Take a closer look: modulate.ai/api/deepfake-det…
1
64
Apr 14
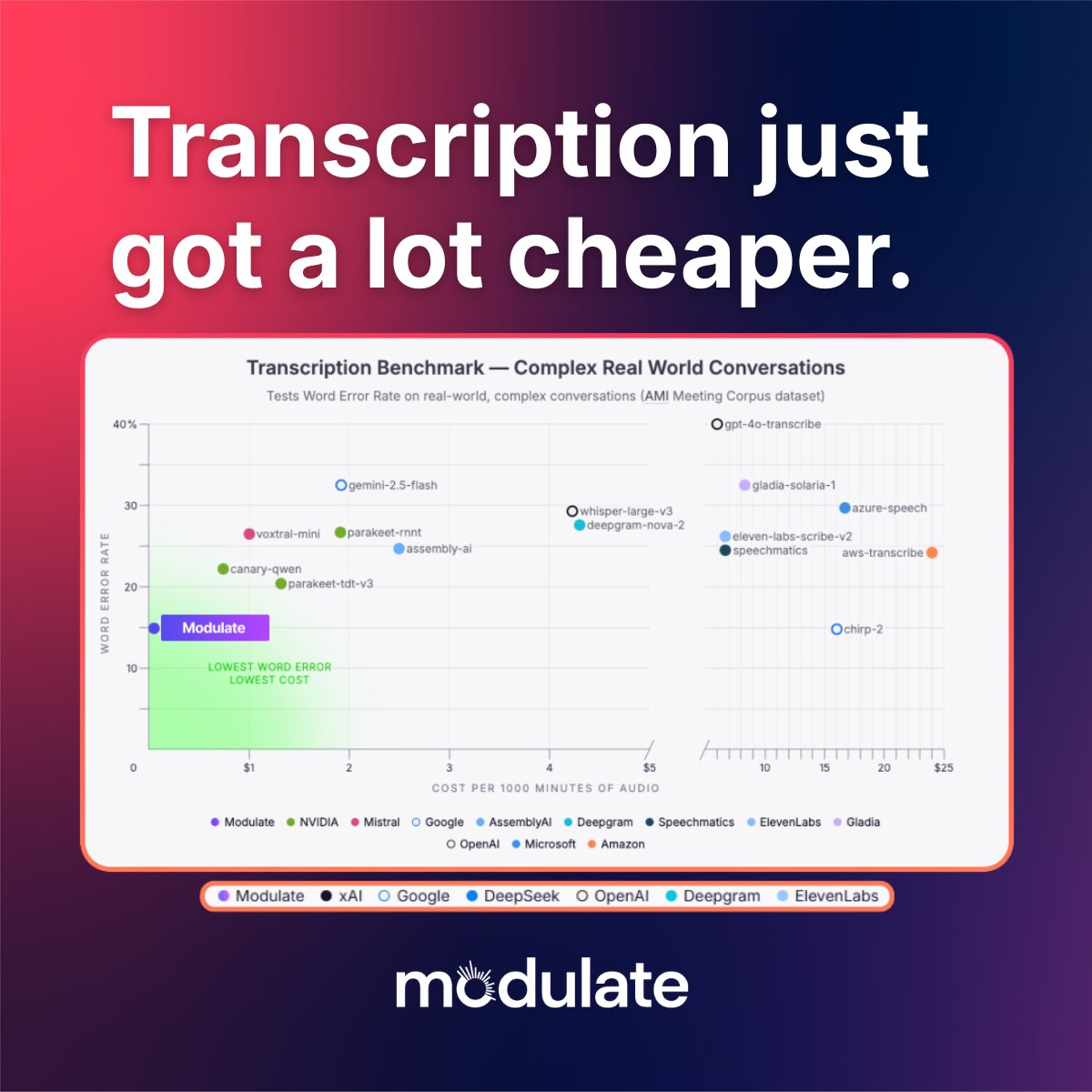
Something didn’t add up… so we ran an experiment.
Deepgram claims 5.26% WER.
We got 28.1% on real-world audio.
Not a rounding error. A reality check.
Most ASR models are tested on clean, perfect data.
But real conversations are messy.
So we tested where it actually matters.
@modulate_ai came out ~2x more accurate.
Full breakdown ↓
bit.ly/4mpyNFG
1
2
5
315
Apr 2
Most deepfake detection models don’t fail in the lab. They fail in production.
Because real-world audio isn’t clean.
It’s noisy.
Compressed.
Streamed.
That’s where detection actually breaks.
Benchmarks don’t matter if they don’t hold up in reality.
1
1
50
Apr 1
Imagine your CEO’s voice calls your finance team… but it’s fake.
Would they notice? Would you?
Deepfakes aren’t a future risk - they’re happening right now.
1
12

Here is the cheapest transcription API in the world. Period.
Let's be honest:
Transcription APIs are among the most overpriced components of voice AI infrastructure right now.
If you are building a voice agent or any sort of conversational AI, a huge chunk of your bill is just transcription.
Get more than a few users, and the cost no longer makes sense.
The Modulate team launched Velma Transcribe, and I think it's simply the cheapest API I've seen:
$0.13 per 1,000 minutes of audio transcription.
This is just ridiculous pricing, and every other API I've ever used is way more expensive than that.
If you are building voice applications, this is gold.
37
21
254
37,361
Carter Huffman retweeted

Mar 13
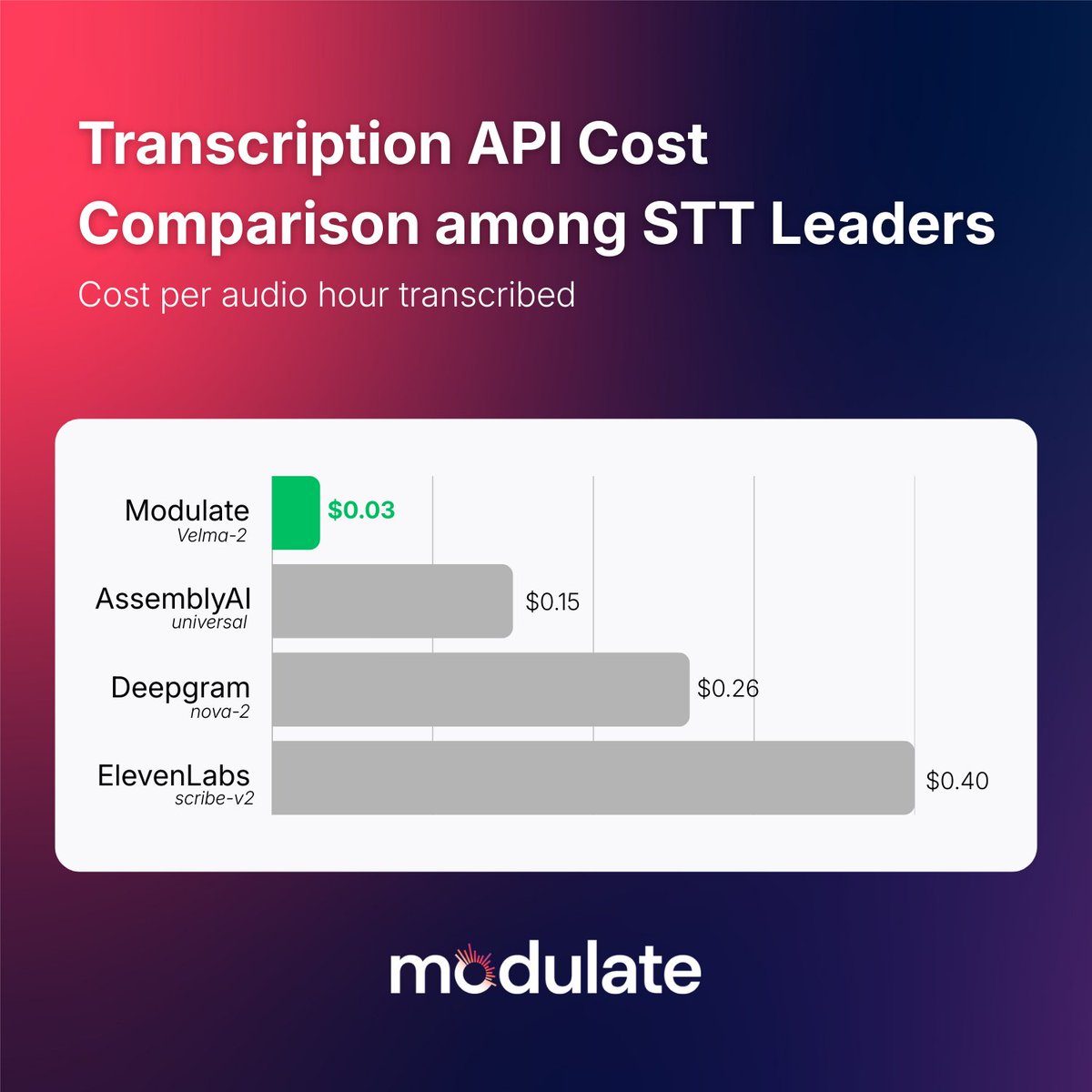
I can’t believe nobody caught this.
Speech-to-text pricing just quietly got obliterated.
A new model from @modulate_ai is charging:
$0.03 per hour of audio.
For context, that’s:
• 5× cheaper than @AssemblyAI
• 8.6× cheaper than @DeepgramAI
• 13.3× cheaper than @ElevenLabs
If you’re building:
• voice agents
• meeting assistants
• call center analytics
• conversation AI
This isn’t a small optimization.
It changes the entire economics of voice products.
Worth testing it yourself using this comparison tool:
speechtxt.com/?utm_source=x&…
Velma Transcribe API by Modulate:
modulate.ai/lp/transcription…
Mar 12

If you’re STILL paying ~$0.25/hr for transcription…
You’re probably funding someone else’s margin.
Yesterday, we launched Velma Transcribe, our transcription API - delivering best accuracy in the world, at up to 90x lower cost than @DeepgramAI
API: modulate.ai/lp/transcription… (🧵↓)
32
19
104
26,188
Carter Huffman retweeted

Mar 12
🚨 Transcription might be getting a lot cheaper.
A new speech-to-text API called Velma Transcribe just launched from @modulate_ai .
For many AI companies, transcription is one of the biggest recurring infrastructure costs.
This could change that. 🧵

21
29
66
11,983