
Physician Scientist. founder @lonlongevity. First principle biology = targeting aging.
Joined June 2009
- Tweets 1,533
- Following 869
- Followers 439
- Likes 1,406
110 Photos and videos












Trained immunity by vaccines like BCG and Shingrix are one of the best ways to prevent neuro degeneration, now with phase 2 data on diabetesand soon cancer data too

A century-old vaccine against tuberculosis helps to regulate blood sugar in people with diabetes
go.nature.com/4xlRHTb
22
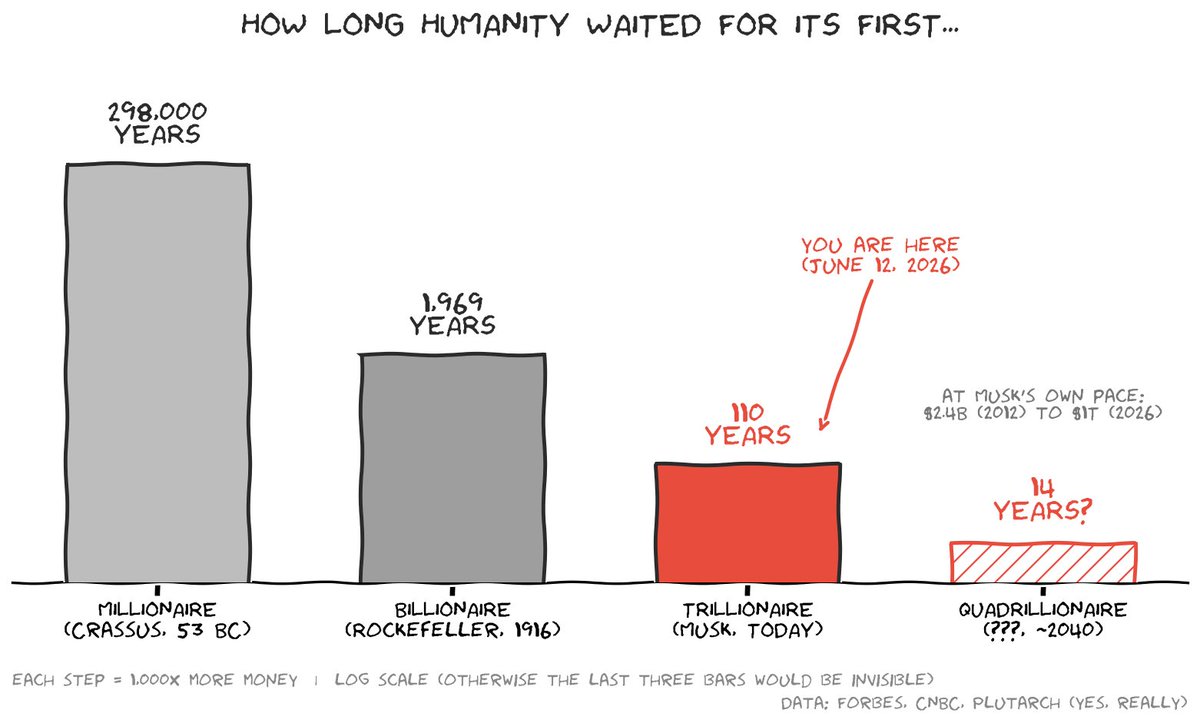
One of humanity oldest problem is still a niche today!

Only a few 100s of people are working on aging - we need an Apollo scale effort

30
Agents in the wild! Not your average Saturday!!
Great fun!!
@lachlan_xyz @unicorn_mafia @Raspberry_Pi at Blue Garage


2
1
3
83
Scaling quality bio!

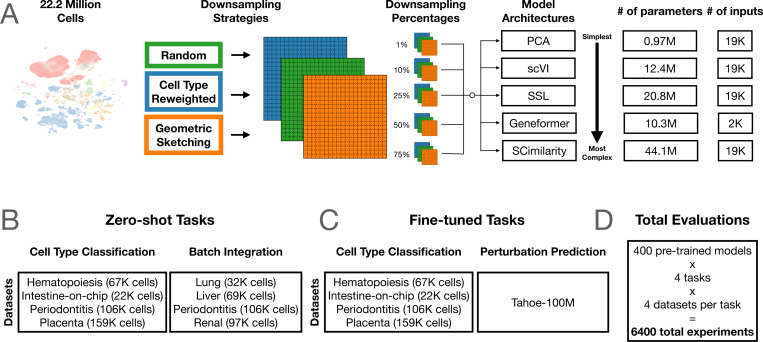
Let’s discuss the scaling law of virtual cells.
A Nature Methods paper (nature.com/articles/s41592-0…) published yesterday is being interpreted by some as evidence that scaling laws do not hold for virtual cells. I read it in detail, and here are my 2 cents:
It is a useful benchmark, but not a direct test of scaling laws in causal single-cell foundation models or perturbation-native virtual cells.
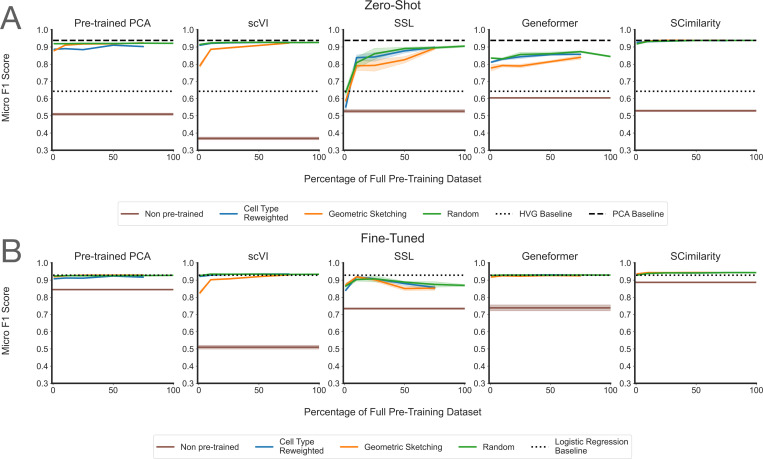
The paper mainly studies PCA, scVI, Geneformer, and SCimilarity (which are relative small models) on observational atlas-style pretraining, with perturbation evaluation limited to a narrow Tahoe small-molecule/cancer-cell-line setting. These are important baselines on scFMs that focuses on learning cell embeddings, but they are not large-scale causal perturbation models (e.g, diffusion-based virtual cells, or other modern architectures designed natively for causal perturbation biology).
The metrics also matter. Cell-type F1 and batch-integration AvgBIO are reasonable atlas/embedding metrics, but they are also tasks that can saturate quickly. They are not direct measures of causal perturbation prediction, target ranking, rare differential-expression tails, OOD genetic perturbations, or generalization across biological contexts.
The “learning saturation point” in the paper is useful, but it is not really a scaling law. It asks: what is the smallest pretraining size that reaches within 95% of the best observed score on this benchmark? That is a helpful diagnostic, but it can be overinterpreted when the downstream task itself is saturated.
The perturbation result is, IMO, limited: a few selected Tahoe-100M small molecules across several cancer cell lines, evaluated with genewise R²/MSE. The paper itself reports that a “no-change” baseline beats fine-tuned models for most drugs, which says as much about the evaluation regime as about model scaling.
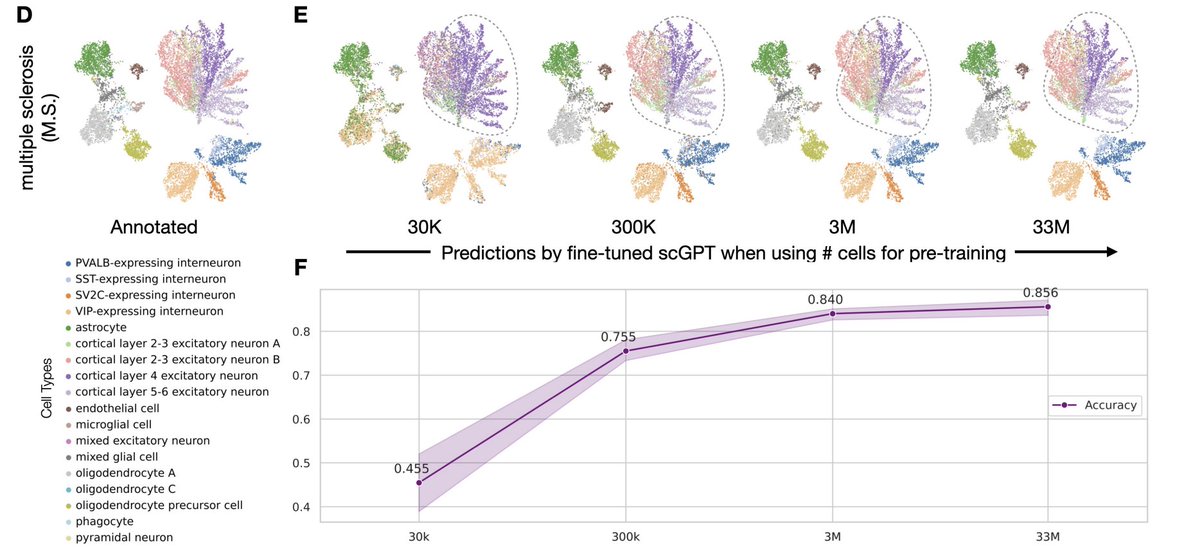
In fact, our scGPT work already showed three years ago that simply scaling the number of observational cells saturates quickly after a few million cells. So I agree with the warning: naive “more atlas cells = better virtual cell” is not enough.
But that is not the real scaling question.
In X-Cell, we study scaling across multiple axes: number of perturbation cells, number of biological contexts, perturbation diversity, and model parameters. On our Perturb-seq-scale data, we observe clear and encouraging scaling behavior. Similar trends are emerging from other perturbation-native virtual cell efforts as well.
The important question is not: can more atlas cells improve cell-type F1? It is: with larger Perturb-seq datasets, larger models, better architectures, and harder OOD splits, can we predict causal cellular responses across genes, combinations, doses, cell states, and contexts?
For X-Cell and the next generation of virtual-cell models, the goal is not just better embeddings. It is target ranking, rare DE tails, counterfactual biology, and prospective perturbation prediction.
So my reading is: this paper is a useful caution against naive scaling, not evidence that scaling laws do not apply to virtual cells.
The exciting regime is still open: scaling the right data, the right models, and the right objectives for causal cellular biology.
44
Humans also have preoptic neurons! Hibernating humans is not only sci-fi!
Jun 11

Hibernation is linked to unusually long lifespans, but natural torpor bundles lower metabolism, lower body temperature, reduced food intake, and inactivity. Causality has been hard to isolate.
We funded Sinisa Hrvatin's @hrvatin_sinisa lab through @ImpetusGrants to make progress on that front.
In their paper, they induced a torpor-like state in mice by stimulating preoptic-area neurons, then repeated torpor-wake cycles for months.
Blood epigenetic aging slowed by 36.9% over 9 months, and the mice showed improved frailty measures. But when the authors separated lower metabolism from lower body temperature, only the low-temperature condition reproduced the aging effect.
That points to hypothermia, not hypometabolism alone, as the key driver of slowed blood epigenetic aging in this model.
On our map of the field’s bottlenecks, this sits at mechanism discovery,: a way to move from “hibernation is linked to longevity” to controlled tests of which torpor features causally affect aging.
Read the paper here: doi.org/10.1038/s43587-025-0…


2
65
The superpower war on ageing will be my favourite war for life!
Jun 11

BIG anti aging news
China just launched its first large scale stem cell anti aging trial, enrolling 2,000 adults aged 50 to test whether stem cells can help preserve strength, physical function, resilience, and healthier aging.
The therapy uses umbilical cord derived mesenchymal stem cells, which may help regulate inflammation, support tissue repair, and improve age related decline.
This is a large, multicenter randomized controlled trial, exactly the kind of serious human evidence longevity medicine needs.
That's a pretty big deal.
anti aging progress is accelerating enormously in the last few weeks.
LEV is near

29
It is still too early start a techbio!!


38
This is super cool! Well done guys!!
Jun 11

pumped to announce the first AI Scientist hack in LDN!
we're teaming up w @AnthropicAI to help you build out next gen. scientific discovery
provided:
> mansion in central London
> all the tokens and pizza you can eat through
> great vibes insanely cracked people
link below
39
Congrats @vladileshko 🖖
Jun 5

Unlimited Bio won the startup pitch competition without even mentioning the Kardashian injections. We also have winning preclinics and human gene therapy combo trial coming up, not only hype!
2-minute video pitch in the comments.
1
1
118
For reference, Reviewed protein in uniprot are ~500K
nature.com/articles/d41586-0…
34
We had a blast in Athens! 🇬🇷 Last week, we brought @LongHackathons to Athens, working alongside some incredible partners AthensLifeTech Park and @EndeavorGr to run the country's first life sciences hackathon alongside Panathēnea. A huge thank you to everyone who supported especially our great sponsors at Dyania Health, @pfizer Thessaloniki, @Lovable , and @Azure
1
2
41
Longevity needs a story.
We are premiering Forever Young, an award winning documentry filmed over three years, three continents, features @prof_horvath, @NirBarzilaiMD, Eric Verdin, and 20 others leading longevity giants. Followed by live Q&A with David Donnelly and @chiara_herzog.
📍 Imperial College Business School, London
🗓 3 June 2026, 6:00pm
🎟 Free to attend. Link below!
Satellite event for the @foresightinst 's Vision Weekend UK (5–7 June), a week of longevity conversations in London.
Cohosted by @LonLongevity, London Ageing Research Network, Imperial Aging & Longevity Society, and Imperial Medtech Society
1
4
63
Immune enhancement, cancer resistance, and DNA repair keeps coming up in many human and animals models of aging
May 24

The Greenland shark genome: Insights into lifespan extremes and population dynamics
pnas.org/doi/abs/10.1073/pna…
48
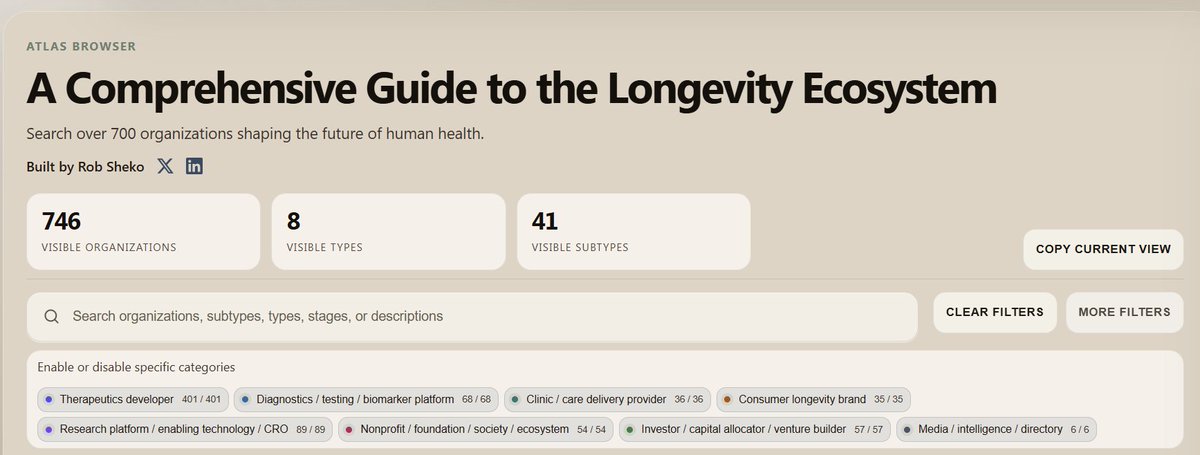
It is still early in longevity. 700 orgs only

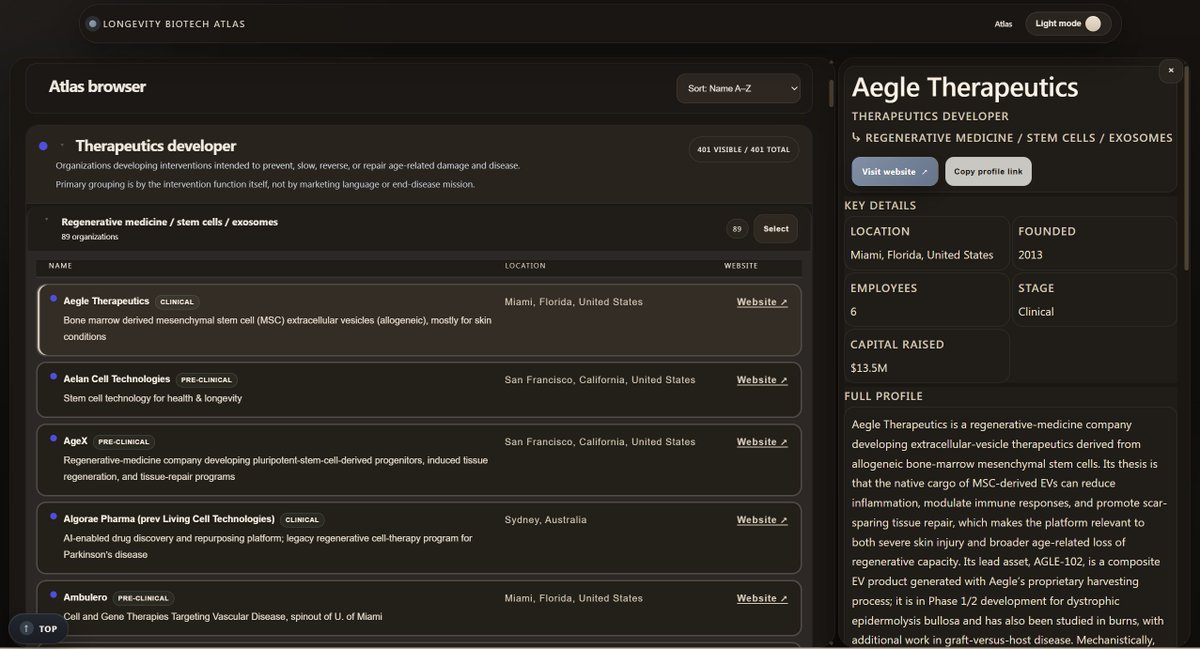
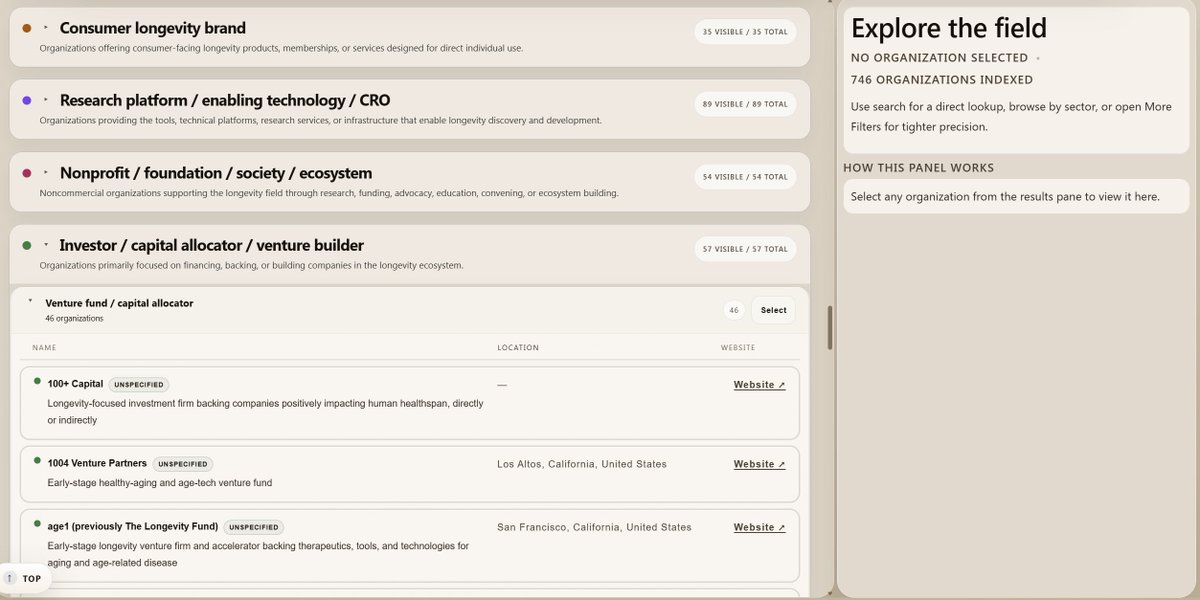
I’m excited to launch the Longevity Biotech Atlas, a personal project mapping 700 organizations across the aging and longevity ecosystem.
Longevity biotech is moving fast.
A lot of the public narrative has centered on GLP-1s, peptides, biohacking, and consumer health optimization. But beneath that, a much deeper ecosystem is forming: companies, labs, investors, and non-profits working on core technologies that will enable fundamentally new forms of measurement and rejuvenation.
The field is growing quickly, but it is still hard to answer basic questions:
Who is building what?
Which areas are crowded?
Which technologies are underexplored?
Where should founders, scientists, investors, and operators be paying attention?
To help make the space easier to navigate, I synthesized public information on 700 organizations—ranging from therapeutics developers, diagnostics, investors, and more— into a single database.
You can explore the atlas at the link in the comments.
This is still an early version, and I’ll be adding more over time: new organizations, personal accounts, bookmarks, and better ways to track how the field is evolving. My hope is to build this out into a core tool for people trying to understand, build, fund, or work in longevity.
If you’re interested in aging biology, biotech, investing, company formation, or the future of medicine, follow along. I’ll be sharing updates, maps of different subfields, and analyses of where the biggest opportunities and gaps may be. Let me know what you find useful!
93
Mo Elzek retweeted

Apr 29
No more Phase 1, 2, or 3 in clinical trials?
The FDA is proposing using AI to get trial data in real-time from EHRs and giving trial design feedback based on what it sees.
No more batch processing could eliminate the wait between phases and get therapies to market faster.

23
65
406
27,643
Mo Elzek retweeted

Apr 29
🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training ( you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000 compounds assayed at Octant, 513 held out, two tracks (pEC50 structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ huggingscience.co
55
350
1,806
198,179