
Joined October 2013
- Tweets 1,751
- Following 367
- Followers 1,838
- Likes 2,808
47 Photos and videos




Pinned Tweet

May 12
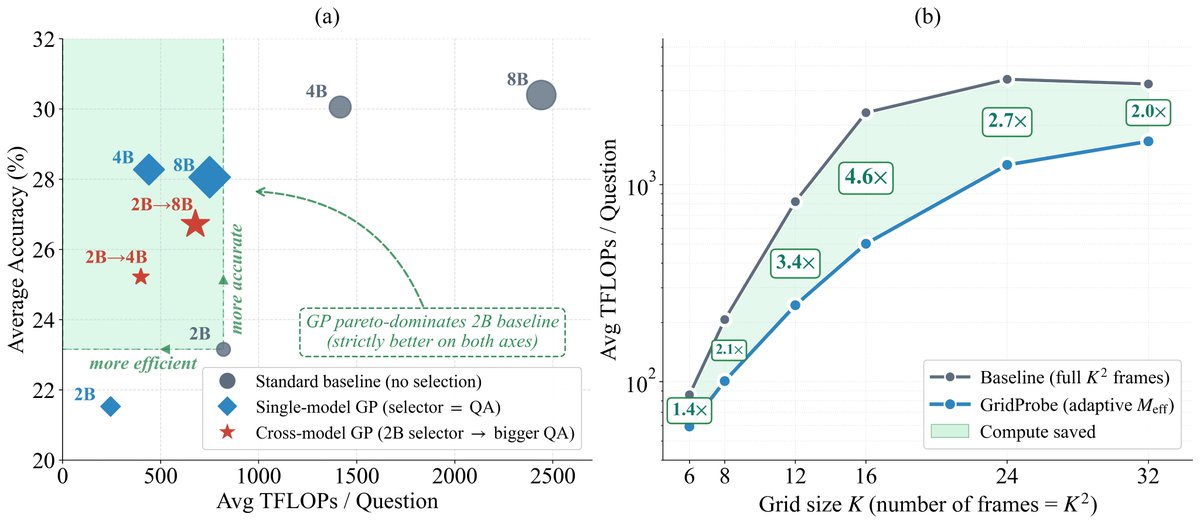
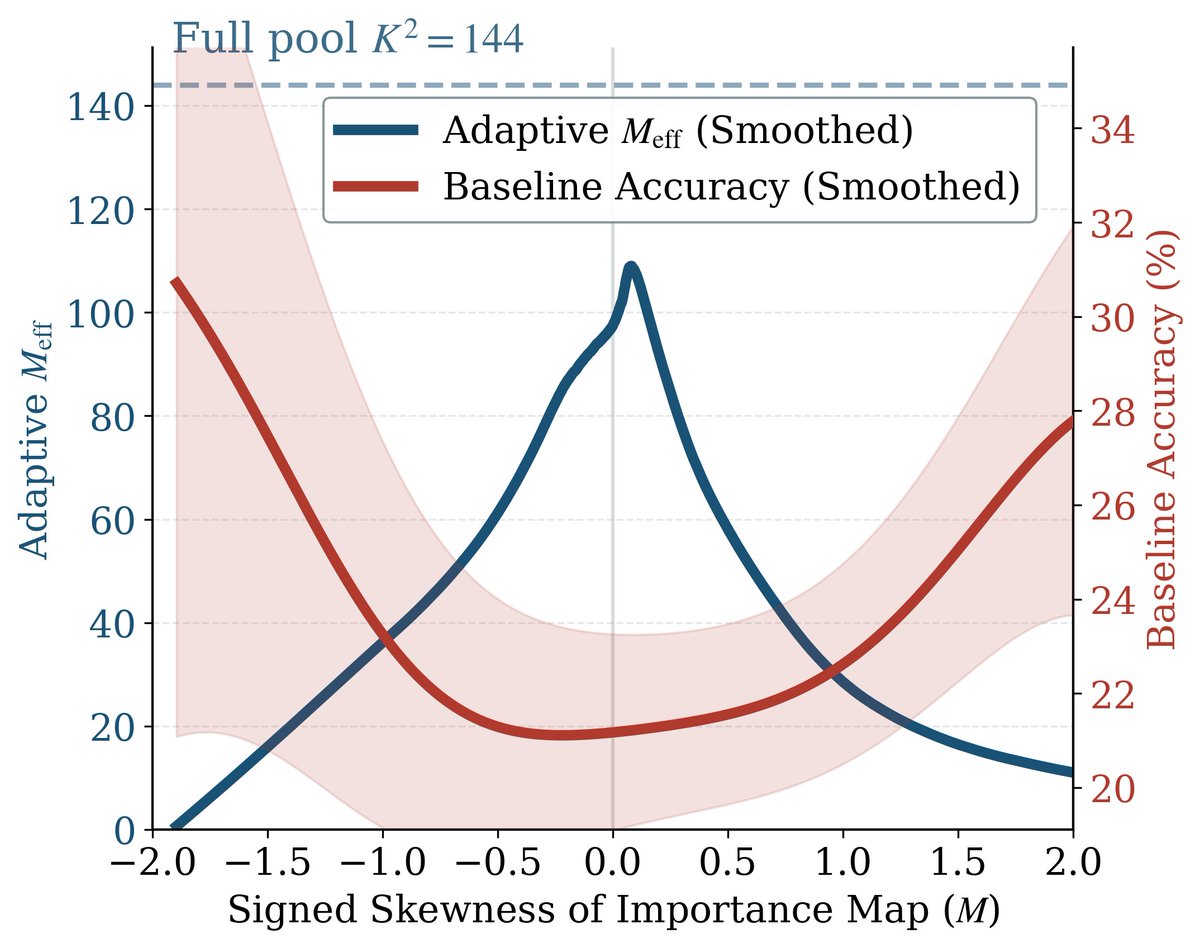
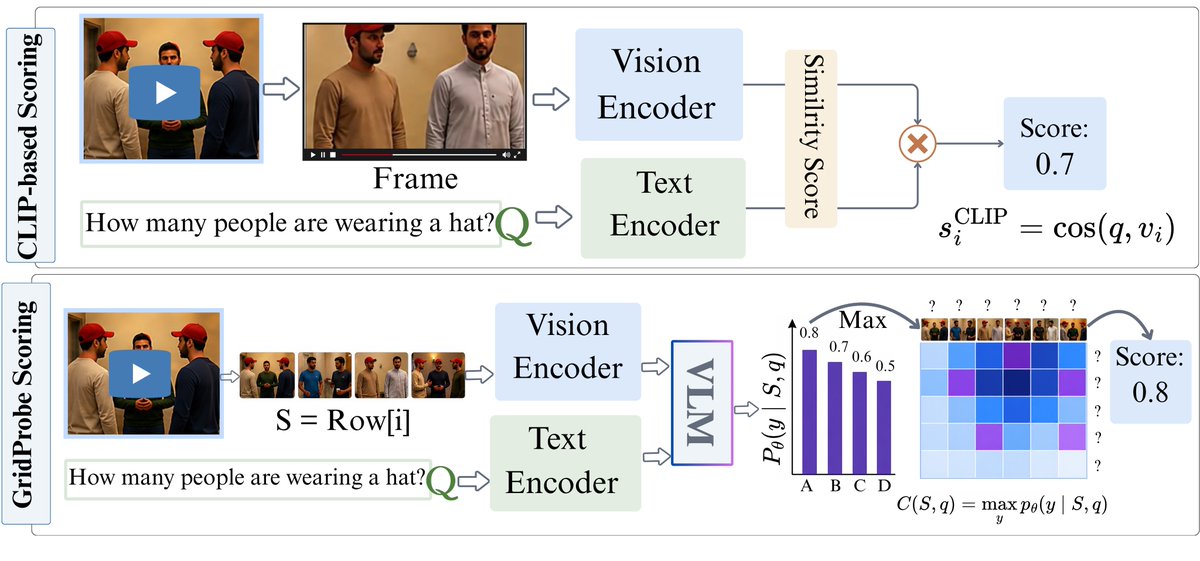
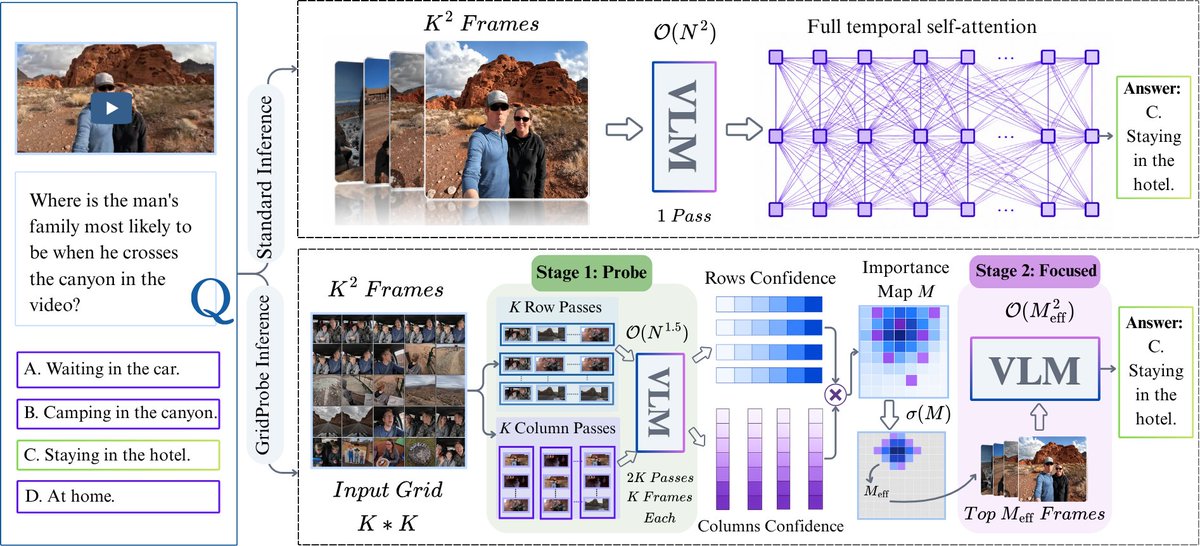
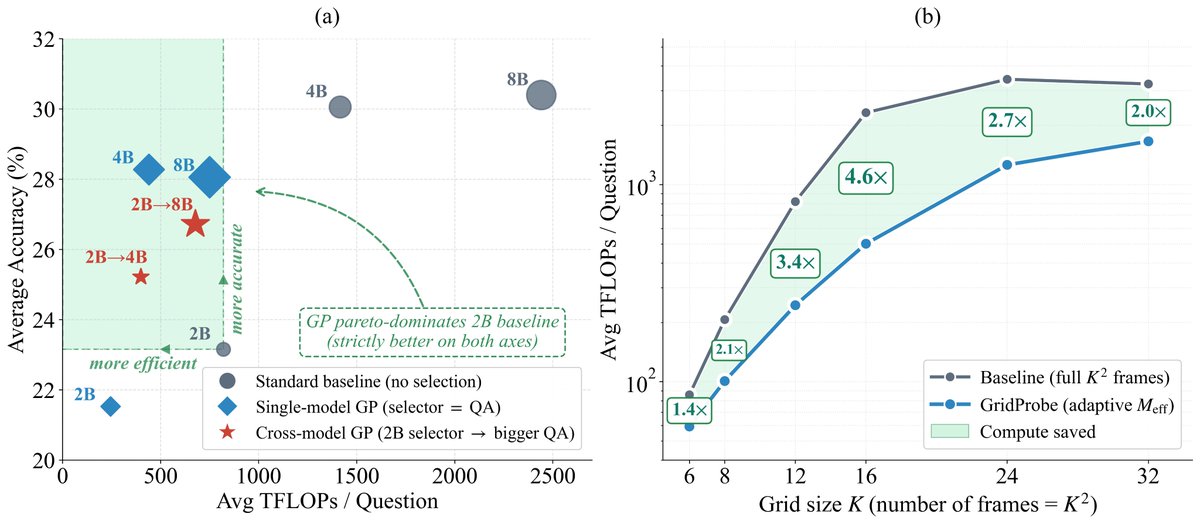
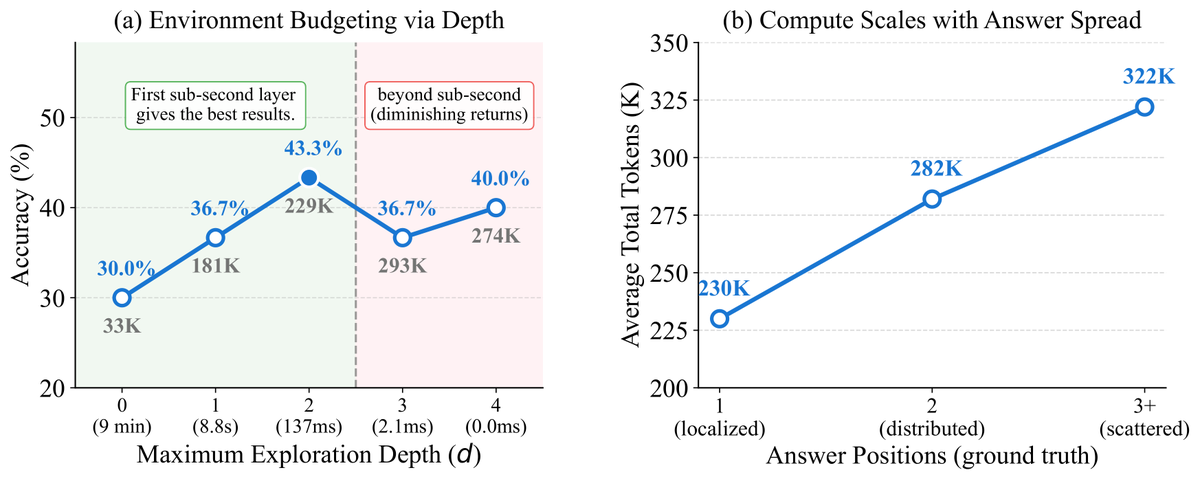
🚨 New preprint: GridProbe: Posterior-Probing for Adaptive Test-Time Compute in Long-Video VLMs
🔵TL;DR: new sub-quadratic training-free inference method for video VLMs.
➡️3.36× less compute, no accuracy loss, fully interpretable on the cell-level, adaptive frames selection using VLM reasoning rather than CLIP-like tricks!
🔥Spoiler alert: Surprisingly, question difficulty alone tells you how many frames a long-video VLM needs to answer it! We turn this into a closed-form rule!!
2
2
11
1,064
Mohamed retweeted

Jun 7
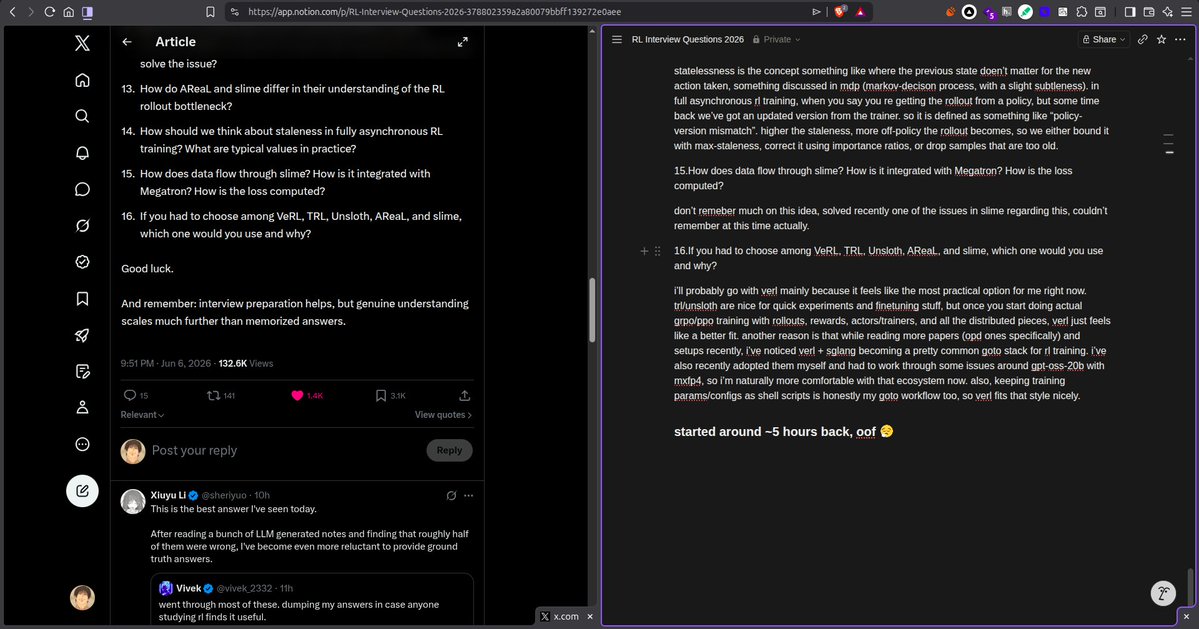
wrote my answers for this rl interview questions 2026 list here:
app.notion.com/p/RL-Intervie…
the questions were genuinely good. most of my time went into just staring at the wall and thinking through the answers properly 😅
kept the notion doc open with comments too, so feedback/corrections are very welcome if i’ve explained something wrong anywhere. raw/unfiltered notes for now -- spelling mistakes included, bear with me 😅 and setup was something like a split tab bw notion and x article

4
23
343
31,190


Jun 5
If you're attending #CVPR2026 in Denver, don't forget to pass by our teammate Ali Habibullah presenting our work on video retrieval, he'd love to chat about it!
📌 Vote-in-Context: VLMs as Explainable Zero-Shot Rank Fusers
📆 When: Saturday Morning, June 6 | 7:30 – 9:00 AM
📍 Location: Poster Session 2 — Exhibit Hall A | Poster #309
📄 Paper Link: arxiv.org/abs/2511.01617
Co-authors: Mohamed Eltahir, Ali Habibullah, Lama A., Tanveer Hussain, Naeemullah Khan.
Focus: Utilizing Vision-Language Models as explainable, zero-shot rank fusers for video retrieval, combining ranked lists from multiple retrieval systems without any additional training. Saturating most of the existing video retrieval benchmarks!
7
237
Mohamed retweeted

Jun 4
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
41
174
2,530
415,973

probably the best reward function for reasoning efficiency i've seen


19
13
322
35,428
Mohamed retweeted

Jun 3
Insightful work! ARC-AGI is really more of a vision or representation problem than a reasoning problem that requires step-by-step thinking.
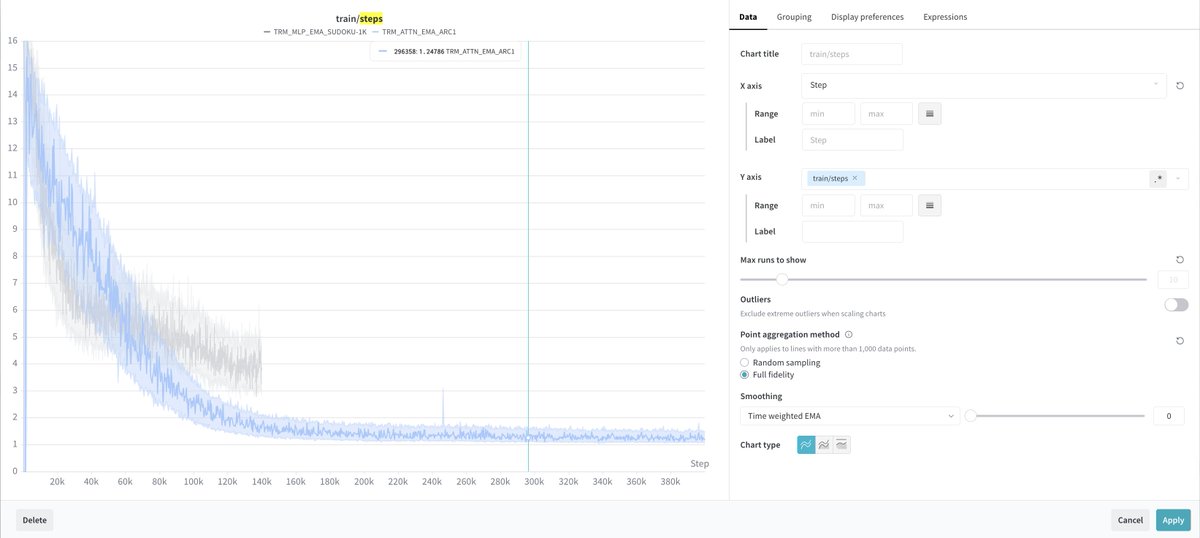
The success of HRM and TRM depends heavily on the 500M learned puzzle embeddings stored in `nn.Buffer` for each separate task. These embeddings essentially store task-specific representations, without which 7M/27M backbone will fail completely.
Another evidence comes from the dynamics of the learned computation steps assigned by the Adaptive Computation head. ARC and Sudoku exhibit very different behaviors.
- On ARC, the number of steps smoothly collapses to nearly 1
- whereas on Sudoku, the drop in steps shows a transition between two stages, with different slopes.
Jun 3

Excited to share our CVPR 2026 paper, ARC Is a Vision Problem! 🖼️
The Abstraction and Reasoning Corpus (ARC) is often approached as a language reasoning problem, despite being an inherently visual puzzle for humans.
🧩Introducing Vision ARC (VARC)🧩: we reframe abstract reasoning as an image-to-image translation problem, solved by a plain Vision Transformer.

2
7
58
10,732
Mohamed retweeted

Local minima are rare in high dimensions because a strict local minimum has to curve upward in every direction, so all Hessian eigenvalues must be positive.
In a D-dimensional toy model where eigenvalue signs are independent, that’s a 2^(-D) event. In GOE-like random matrix models, positive definiteness is even rarer, roughly exp(-cD^2).
So as dimension grows, random critical points are much more likely to be saddles than minima. This is one reason high-dimensional optimization is often a saddle-escape problem, not a bad-local-minimum problem.
Wrote up some of the math here: grantstenger.com/local-minim…

the greatest whitepill of all is that local minima are rare in high dimensional spaces
34
192
2,182
303,409

the broader implication is that there's abandoned architecture research from before Muon that failed because the empirical optimizers that worked in practice were, both literally and conceptually, stuck in element-wise local minima
May 29

For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: arxiv.org/abs/2605.29157
code: github.com/Yifei-Zuo/Paralla…
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: arxiv.org/abs/2510.01450
code: github.com/Yifei-Zuo/FlashLL…

9
22
301
40,053
Mohamed retweeted

Late-interaction retrieval is incredibly powerful, but scaling it is computationally challenging. k-means is a huge bottleneck.
Our new architecture, TACHIOM, is fully open-source and tackles this problem: up to 247x faster clustering and 9.8x faster retrieval. ⚡ 🧵👇
3
23
120
8,364
Mohamed retweeted

May 28
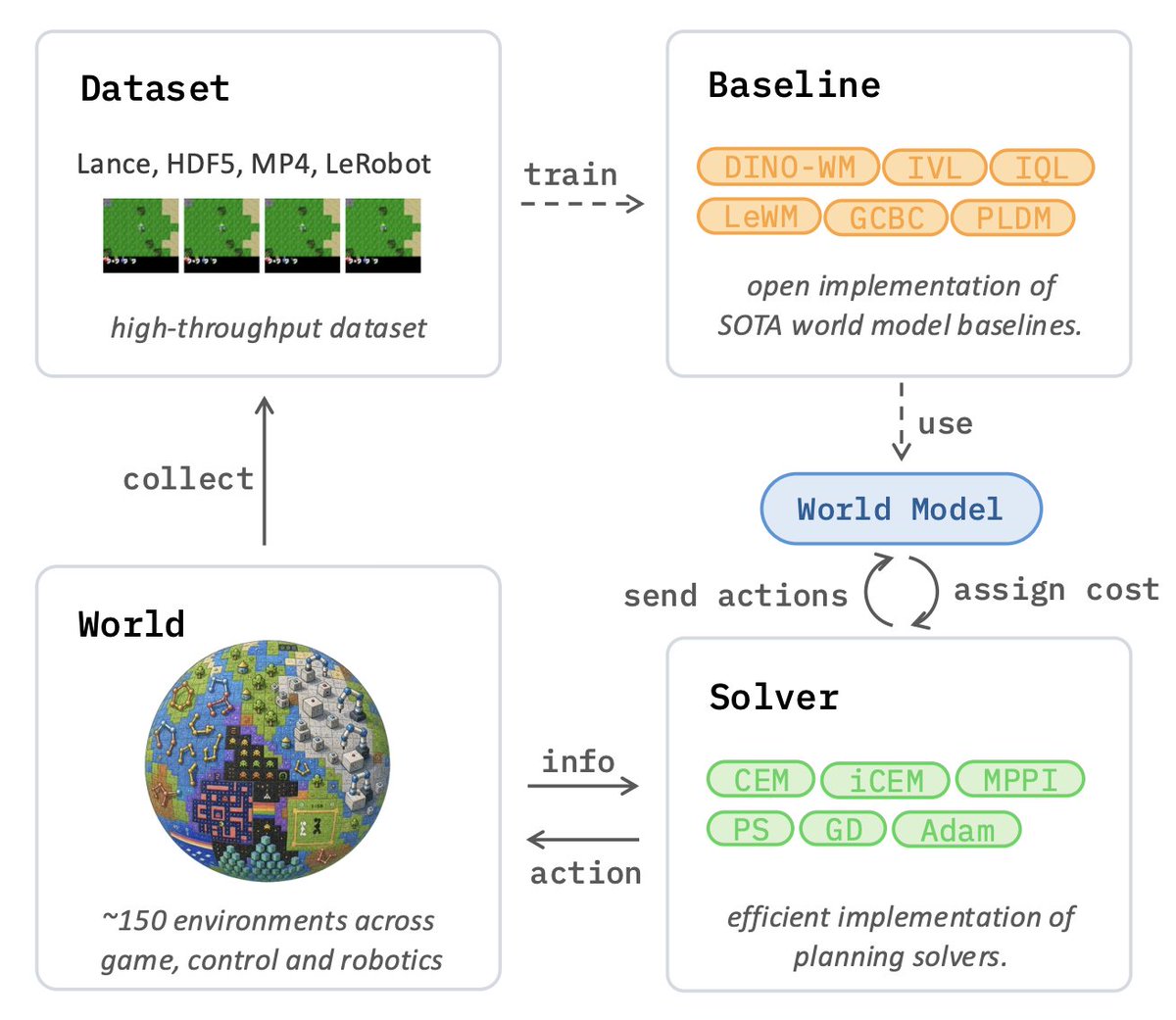
Would you like to join the research effort on JEPA and World Models easily?
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: github.com/galilai-group/sta…
40
274
1,818
113,410
Mohamed retweeted

May 28
🚨 [New Paper]
The Adam optimizer is a zombie algorithm...
It senses and adapts the learning rate, sure. But the update rule itself? Fixed, frozen. Decided before even the training starts. It works in some regions of the loss landscape and fails in others.
What if the optimizer itself was an agent, free to learn its own trajectory through the landscape and adjust its own update rule at every step? and maybe transfer its learned policy to train models on unseen datasets!
Introducing: PILOT (Policy-Informed Learned OpTimizer)
📄Preprint: arxiv.org/abs/2605.24570
🧵TLDR 👇
6
13
70
14,511
Mohamed retweeted

May 23
If you can learn one thing that's genuinely novel to you, you can learn anything.
79
85
1,182
57,384
Mohamed retweeted

May 20
🧠We introduce "Generative Recursive Reasoning"!
Recursive Reasoning Models like HRM, TRM, and Looped Transformers are deterministic — same input, same reasoning, every time. They collapse the entire space of plausible reasoning paths into a single attractor.
Our model GRAM (Generative Recursive reAsoning Models) turns recursion itself into a stochastic latent trajectory. Multiple hypotheses, alternative solution strategies, and inference-time scaling not just by depth, but by width — parallel trajectory sampling.
And here's the kicker: the same formulation that gives us conditional reasoning p(y|x) also makes GRAM a general generative model p(x).
With only 10M params:
• Sudoku-Extreme: 97.0% (TRM 87.4%)
• ARC-AGI-1: 52.0%
• ARC-AGI-2: 11.1%
• N-Queens coverage: 90%
📄 Paper: arxiv.org/abs/2605.19376
🌐 Project page: ahn-ml.github.io/gram-websit…
w/
Junyeob Baek @JunyeobB (KAIST),
Mingyu Jo @pyross0000 (KAIST),
Minsu Kim @minsuuukim (KAIST & Mila),
Mengye Ren @mengyer (NYU),
Yoshua Bengio @Yoshua_Bengio (Mila),
Sungjin Ahn @SungjinAhn_ (KAIST)



31
209
1,495
183,157
Mohamed retweeted

May 21
Information Retrieval is about making knowledge accessible.
Late Interaction is the best way to do that today. But now that we have a new kind of users, it's time to zoom out so we can plan the future of retrieval.
I gave a talk about this at @ir_tsukuba
docs.google.com/presentation…
3
29
138
19,040
Mohamed retweeted
May 20
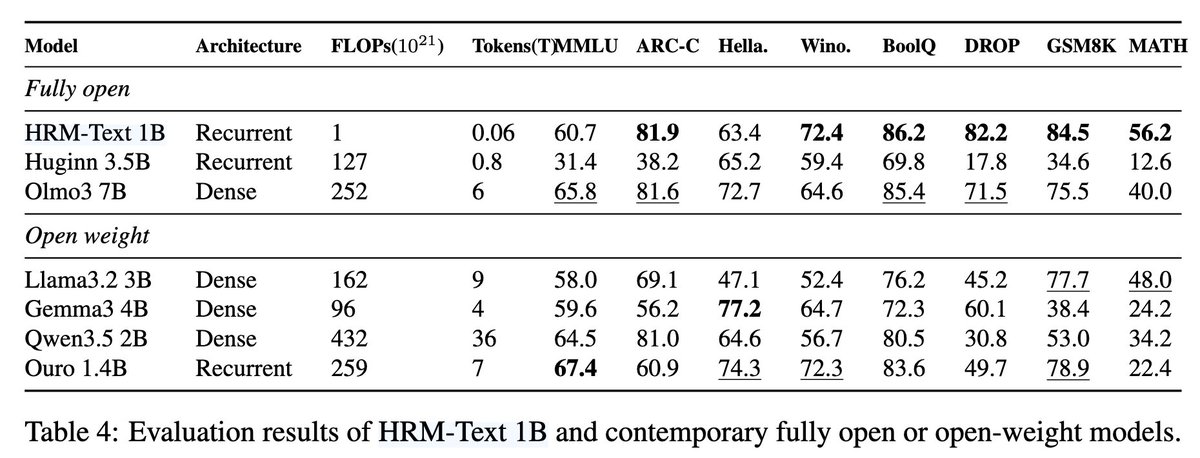
HRM-Text paper is here:
sapientinc.github.io/HRM-Tex…
Just finished reading it as a deeper dive. I went in with a connected set of researcher-style questions:
Is the gain really from HRM? To answer that, we first need to separate out the objective: how much comes from computing loss only on response tokens? Then, how much comes from PrefixLM? Finally, if we remove PrefixLM, how strong is causal-only HRM?
What I appreciate is that the paper gives enough ablations to answer this chain pretty directly.
1/ First, there is real architectural signal.
-------------------------------------------------
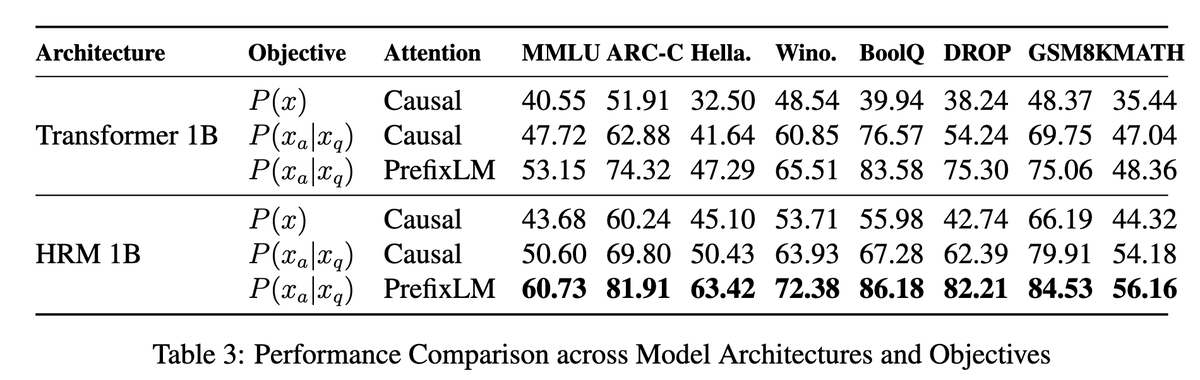
Table 3 compares model architectures, objectives, and attention masks, under same FLOPs budget. The average scores are:
Transformer, P(x), causal 41.9
HRM, P(x), causal 51.5
Transformer, P(a|q), causal 57.6
HRM, P(a|q), causal 62.3
Transformer, P(a|q), PrefixLM 65.3
HRM, P(a|q), PrefixLM 73.4
So even under causal attention, HRM still wins over the matched Transformer.
2/ That said, I would read the final headline number carefully. It is not “HRM architecture alone.” It is:
-------------------------------------------------
HRM architecture
response-only objective
PrefixLM
instruction/reasoning-heavy data
2.1/ PrefixLM is a big piece. In PrefixLM, prompt tokens can attend bidirectionally, while answer tokens are still generated autoregressively.
So the prompt side becomes somewhat encoder-like, while the answer side stays decoder-style.
Empirically:
Transformer:
causal response-only -> PrefixLM
57.6 -> 65.3 ( 7.7)
HRM:
causal response-only -> PrefixLM
62.3 -> 73.4 ( 11.1)
This is a strong improvement, but it also raised my first deployment concern.
In multi-turn chat, bidirectional prompt attention means you need special mask / KV-cache handling. You cannot simply treat it as the usual append-only causal cache in AR models. To their credit, the paper explicitly discusses this in Sec. 5.3. I appreciate that they state this explicitly
2.2/ The objective also matters a lot.
> Standard LM objective: learn P(x)
> Task-completion objective: learn P(answer | question)
In practice, this means: do not spend loss predicting the prompt. Train on response tokens.
This alone moves the average:
Transformer: 41.9 -> 57.6
HRM: 51.5 -> 62.3
3/ Then, the next sharp question for me was: What if we take causal-only HRM from Table 3 and compare it to the open models in Table 4?
-------------------------------------------------
Not the final PrefixLM HRM. Just causal-only HRM. That gives a less flashy, but more informative comparison.
Against Table 4 models, causal-only HRM roughly looks like this:
HRM causal avg: 62.3
vs Llama3.2 3B: 3.1
vs Gemma3 4B: 5.7
vs Qwen3.5 2B: 4.1
vs Huginn 3.5B: 21.2
vs Ouro 1.4B: -1.4
vs OLMo3 7B: -7.3
So causal-only HRM is still quite competitive for a 1B low-budget model (actually impressive if you look at FLOPs used compared to others in Table 4!).
4/ FLOPs fairness is important, and the paper makes a serious attempt here.
-------------------------------------------------
For the internal Transformer, TRM, and HRM comparisons, they match estimated training FLOPs, not just token count.
Because HRM spends more computation per token, the Transformer gets more training tokens under the same FLOPs budget.
I think this is a serious attempt at fairness, though still estimate-level.
-/ In summary, HRM-Text is a solid work to me. The ablations show real architectural signal, in addition to recipe choices separate from arch.
That is more interesting than just a one-line architecture claim, and more useful for researchers to follow up on.
Congratulations on the team!
May 18

Hierarchy Reasoning Models on Language Tasks
github.com/sapientinc/HRM-Te…
- The scatter plot is really wild... Let's test it out !
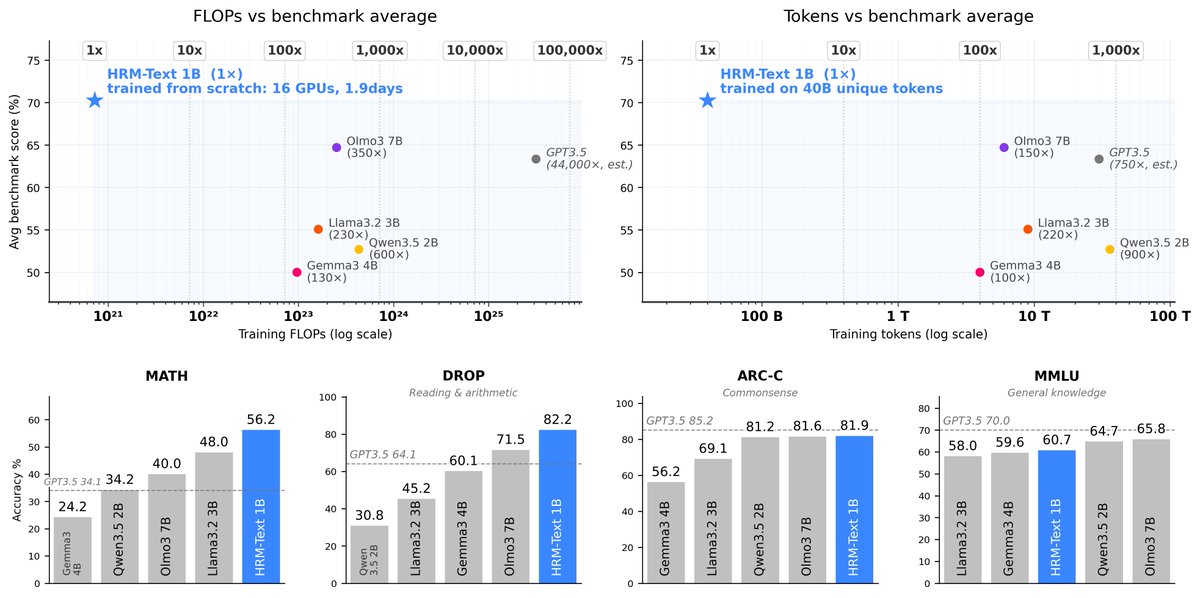
6
14
116
26,429

MIT just released a new RL method called Pedagogical RL.
The main lesson -> correct reasoning traces can still be bad training data.
It is a similar concept to teaching someone backprop.
Say you have a tiny computation graph:
z = wx b
a = ReLU(z)
L = (a - y)²
If you already understand backprop, you can jump straight to the gradient:
dL/dw = 2(a - y) · 1[z > 0] · x
The answer is correct but it skips the reasoning process.
To get there, you need to break the computation into local pieces:
dL/da = 2(a - y)
da/dz = 1[z > 0]
dz/dw = x
Then backprop is just composing those local derivatives backward through the graph:
dL/dw = dL/da · da/dz · dz/dw = 2(a - y) · 1[z > 0] · x
Showing a student the final gradient does not teach them how to find gradients on new graphs.
Even telling them “just use the chain rule” may be too large of a jump if they do not understand how to decompose the computation into intermediate nodes and local derivatives.
Reasoning RL has the same failure mode.
A rollout can pass the verifier while containing one step the student model basically never would have taken.
The trajectory gets the answer right, but the learning signal is brittle because the path is too far from the student’s current policy.
Pedagogical RL trains a privileged teacher that knows the answer, then rewards it for producing trajectories that stay learnable for the student.
The trick is to use a spike-aware reward. It penalizes single huge surprise gaps in the trajectory, even when the average likelihood of the trajectory looks fine.
Then the student learns with surprisal-gated imitation, where teacher tokens that are still too surprising get downweighted.
The teacher is learning how to teach at the student’s current level.
Pedagogical RL makes RL more efficient by efficiently selecting trajectories the student is most ready to learn from.
Less waiting for the model to get lucky rollouts. More training signal from examples that meet the student where it is.
Full blog in comments

12
66
460
44,214
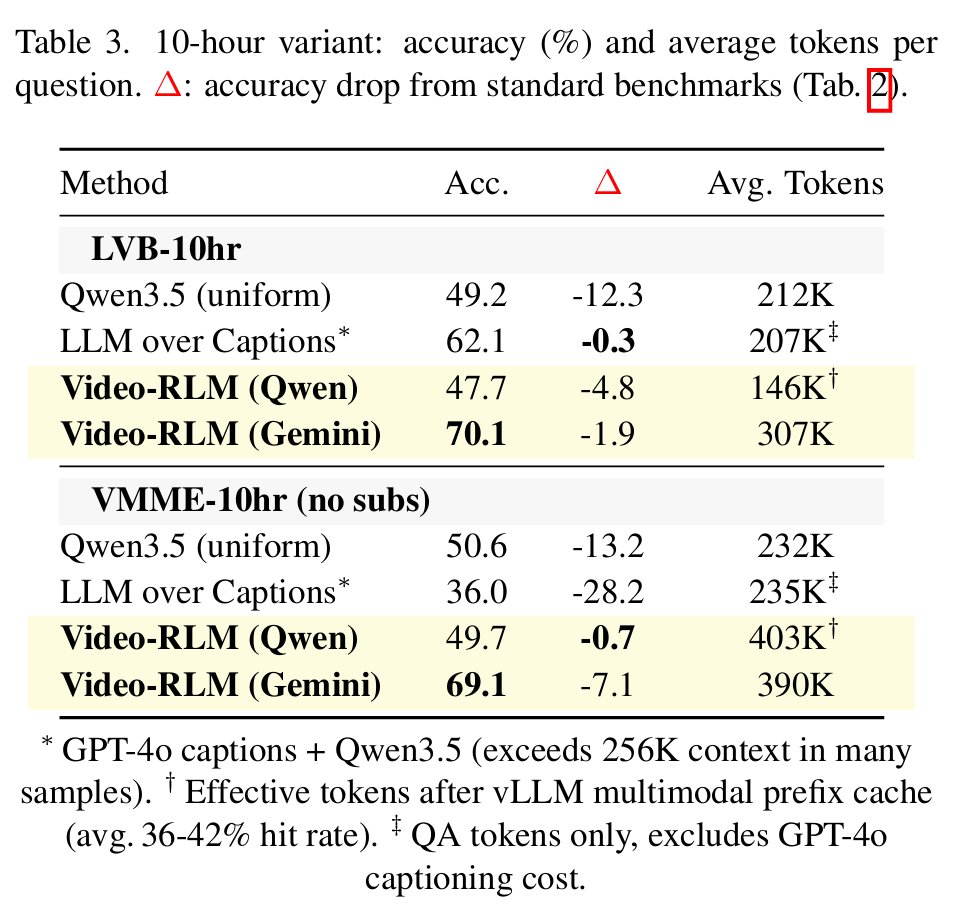
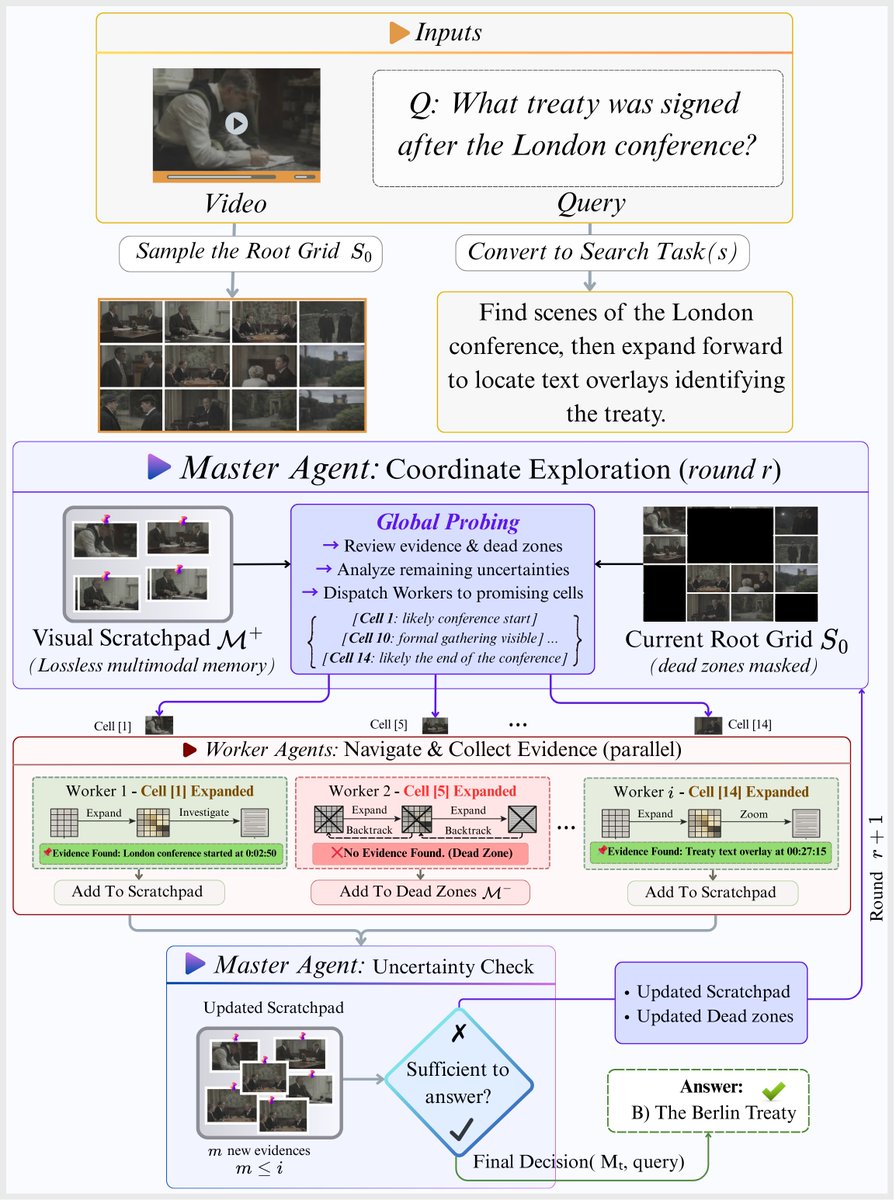
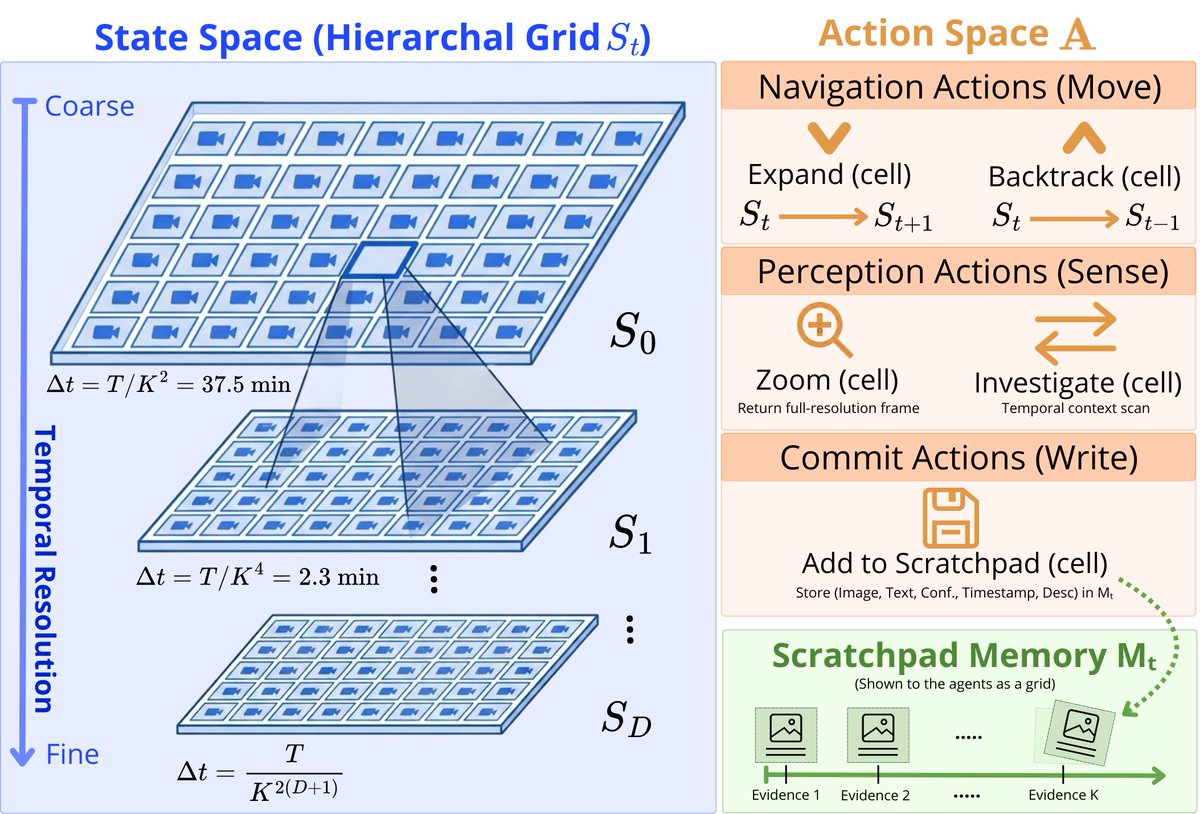
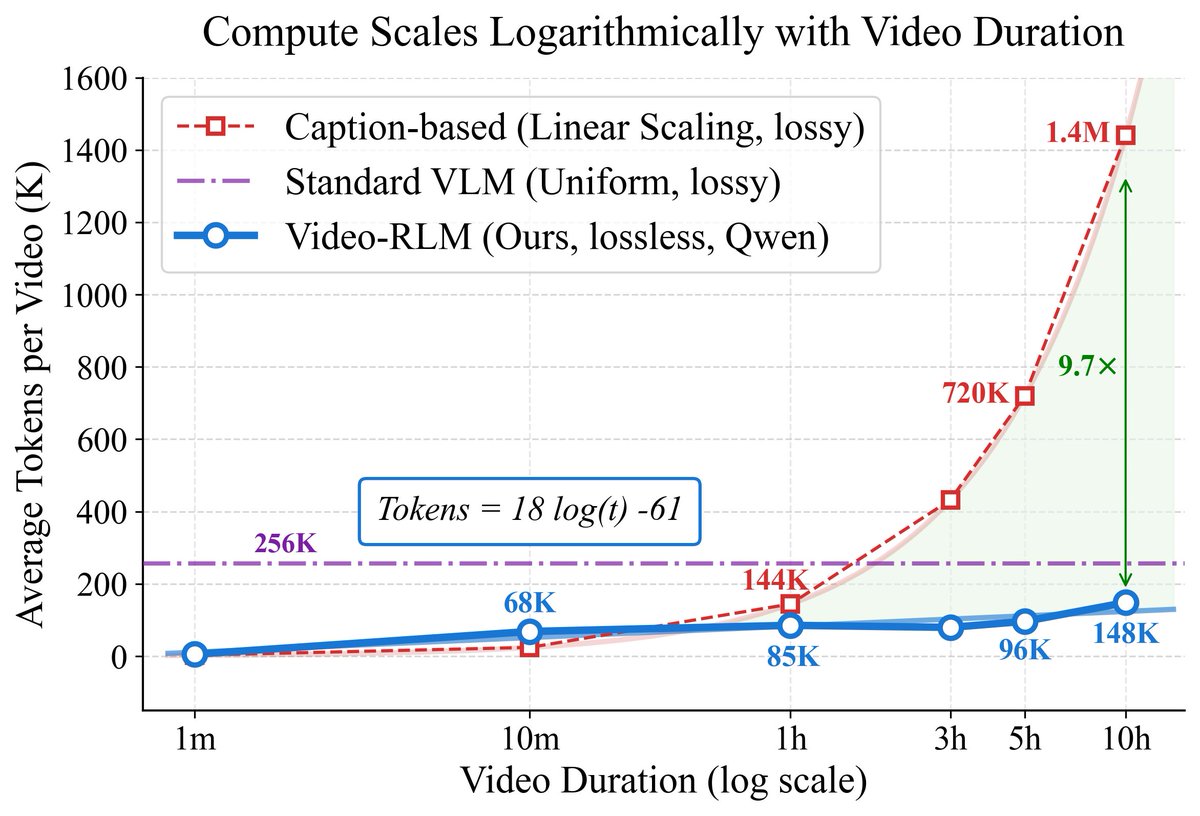
Mar 19
What if understanding a video was more like navigating a map?🤔
And what if that made compute scale logarithmically (not linearly) with video length?!
New preprint🎉:
🗺️VideoAtlas: Navigating Long-Form Video in Logarithmic Compute
5
6
66
30,929
Mar 19
This wouldn't have been possible without an incredible team: Ali Habibullah, Yazan Alshuaibi, and @Lama_s1 , and the guidance of our amazing supervisors Dr. Tanveer Hussain and Prof. Naeemullah Khan. Special thanks to the @KAUST_Academy and @Dr_S_Albarakati for their support.
2
12
623
May 16
Some additional experiments that show even more interesting things :)
x.com/i/status/2053974516070…
May 11

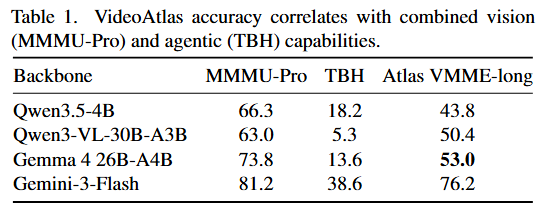
Been running extra experiments on VideoAtlas in the previous days, and the headline finding turned out wilder than I expected:
🔥@googlegemma Gemma 4 which is officially limits to 60 seconds of video is now matching long-context models on 30-60 min videos!
Thread 🧵
170
Mohamed retweeted

May 14
They struggle with novelty though. We ran a phase where every idea had to pass a novelty check, neither agent managed to improve the baseline.
We release all the generated ideas here:
Codex: github.com/PrimeIntellect-ai…
Claude: github.com/PrimeIntellect-ai…
2
8
155
12,217