
58 Photos and videos












Morph retweeted

Jun 9
another week another record

Jun 1

unfortunately, due to the gpu shortage, we’ve had to lay off some of our silicon and increase human headcount to 3
despite this setback, we continue to scale

1
1
21
1,474
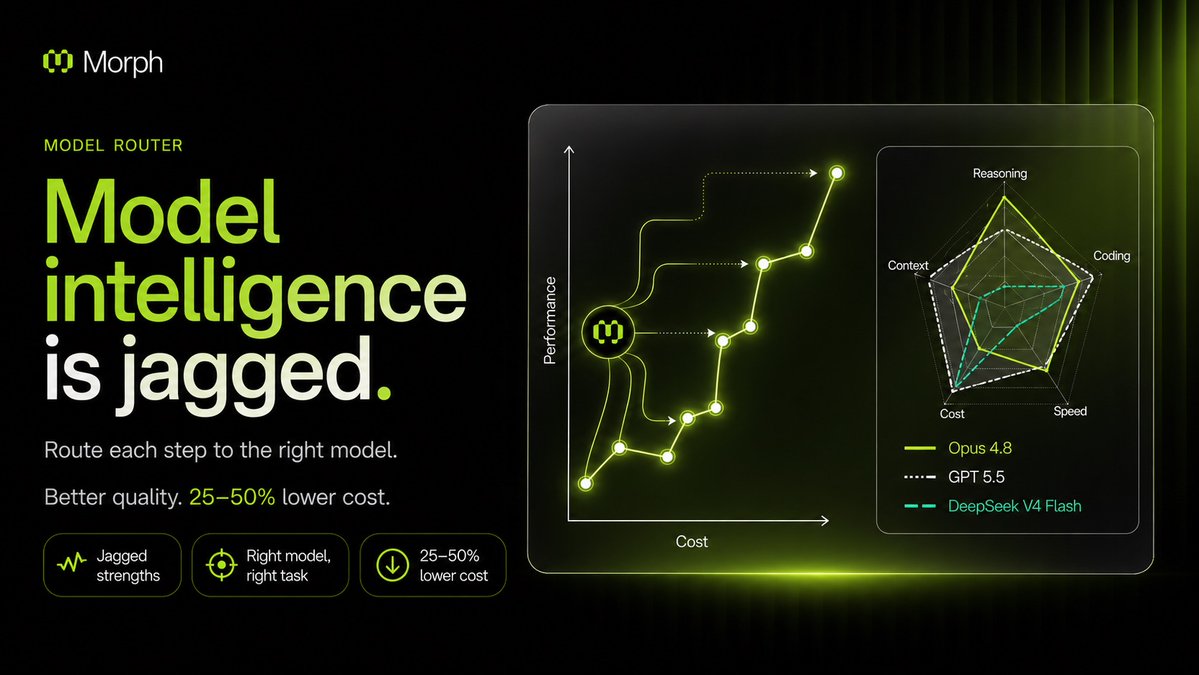
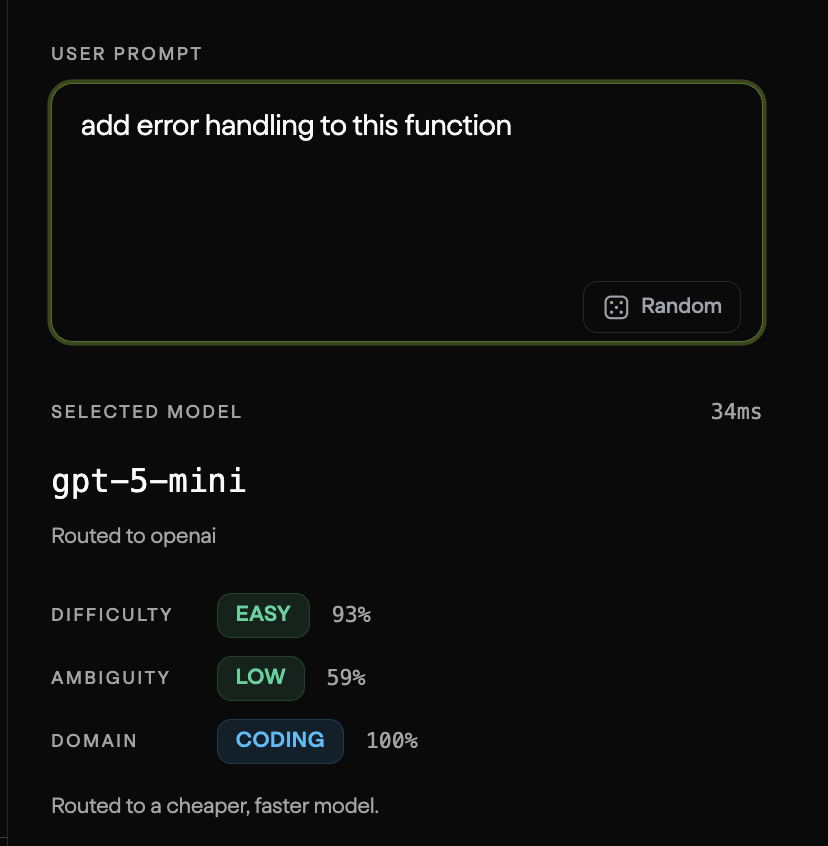
Being model agnostic is better, faster, and cheaper
Try the Morph Router API:
docs.morphllm.com/sdk/compon…
or dm us to self host
4
580
Morph retweeted
May 13
the general applied standard intelligence compute company
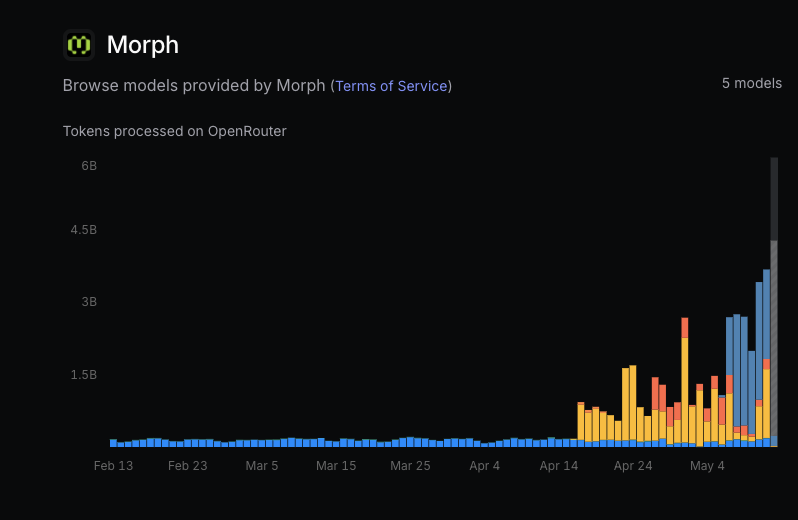
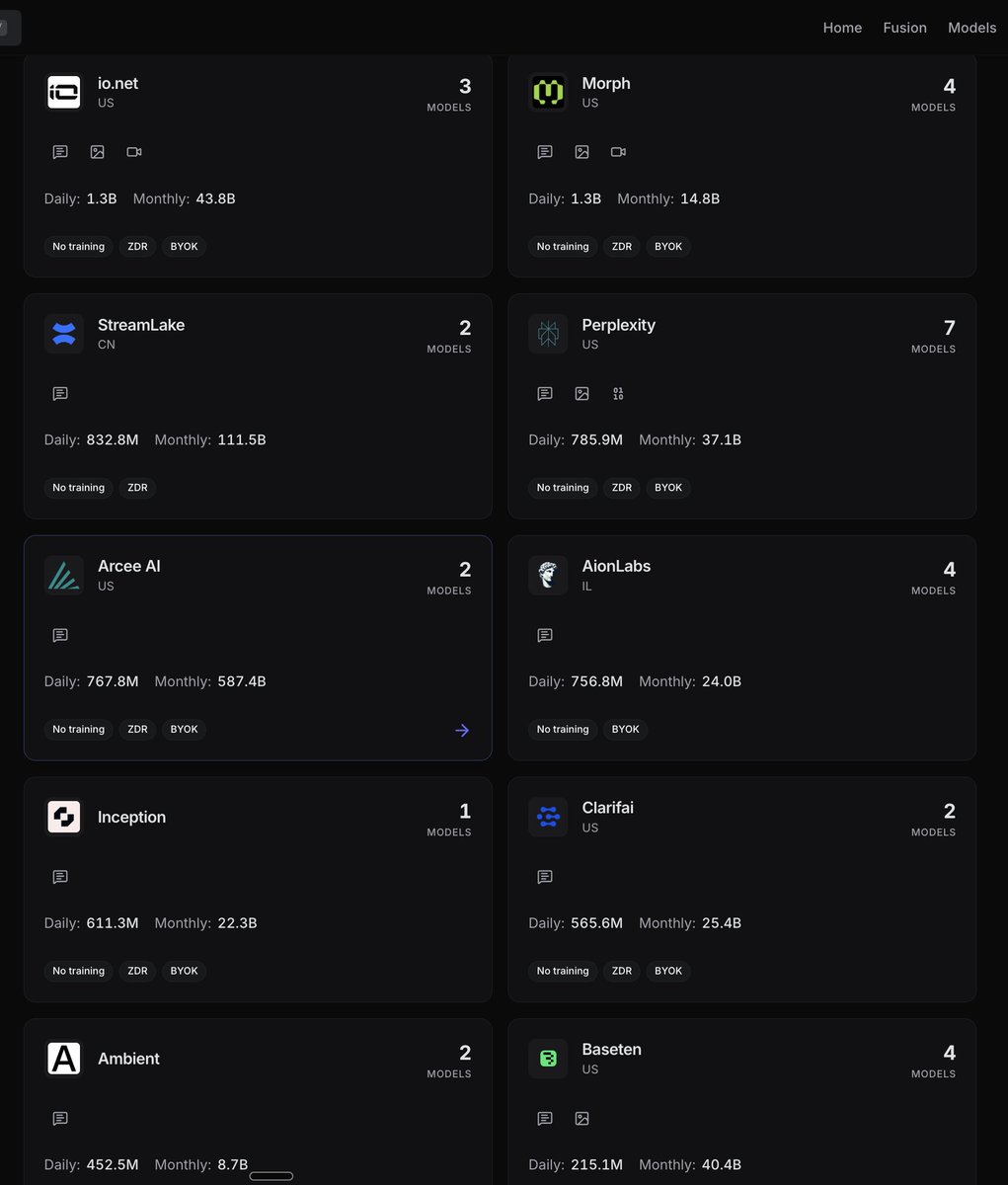
Apr 29
morph is 2 people
we spend 10x more on gpus than salary
we’re hiring for the first sub-10-person billion-dollar company.
join us
1
1
51
12,552
Morph retweeted

Apr 16
Join us in welcoming @morphllm Founder, @tejasybhakta to the AIE Miami lineup!
Don't miss his talk 'Everything is Models' next week on the big stage!
Get your tickets: ai.engineer/miami

3
18
1,979
Morph retweeted

Apr 15
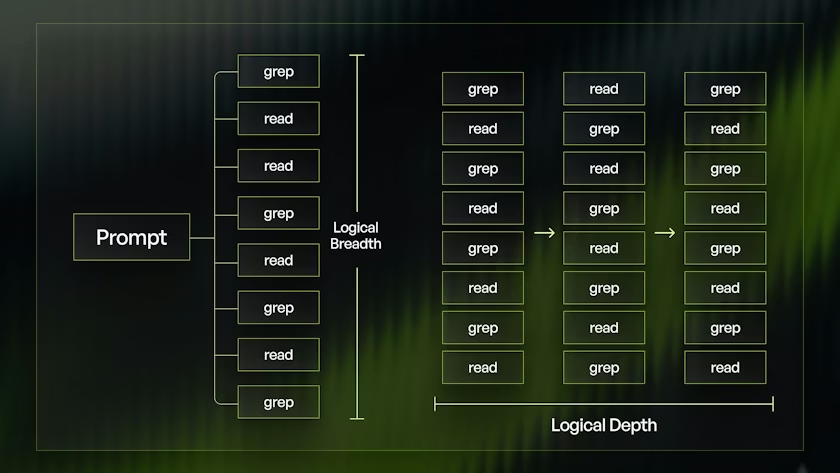
warpgrep_github_search from @morphllm is probably the most unfathomoly unfair advantage you can have right now. 10x better than grep app
Even beats Ctx7 tbh
docs.morphllm.com/sdk/compon…
2
1
8
1,059
morphllm.com/mcp
install the plugin mcp here
2
1
17
1,587

Agents don’t need bigger models. They need better tools.
Morph trains coding subagents.
Not for humans. For frontier models.
Fast Apply edits at 10,000 tokens/sec.
WarpGrep handles code and log search.
Both keep the main model’s context clean
Because when context gets too large, performance drops.
Now Morph is pushing coding subagents even faster
One newer model runs at 33,000 tokens/sec: docs.morphllm.com/sdk/compon…
🎙️ @tejasybhakta, Founder & CEO, @morphllm on @fondocom @thestartpod w/ @davj
2
10
32
7,135
We just removed access control. Anyone can now try this from the API as well.
docs.morphllm.com/sdk/compon…
6
1
11
2,360
Morph retweeted

Mar 17
Perfect compaction is a prerequisite for long-running agents.
It’s the difference between a country of geniuses
and a pile of clankers.
#unLobotomizeClaude

Introducing FlashCompact - the first specialized model for context compaction
33k tokens/sec
200k → 50k in ~1.5s
Fast, high quality compaction
3
1
20
2,304
Morph retweeted
Mar 17
Compaction should feel invisible
It should be fast, accurate, and cheap
some of our beta users were confused because they didn't notice compaction happening in their coding agent now
mission accomplished
Introducing FlashCompact - the first specialized model for context compaction
33k tokens/sec
200k → 50k in ~1.5s
Fast, high quality compaction
11
5
111
22,116
We looked at 200 agent sessions and over 40 of the top coding agent harnesses
Most context bloat comes from tool responses, not model generation.
Result:
→ no performance drop
→ fewer tokens
→ fewer steps
To push performance higher and perform long horizon tasks, agents need cleaner context.
More details in the blog:
morphllm.com/blog/compact-sd…
Or try it in the playground:
morphllm.com/dashboard/playg…
9
118
8,691