
29 Photos and videos














Pinned Tweet

10 Jul 2022
The most extensive and comprehensive paper explaining what exactly MLOps is. The read is not only worth it, it is absolutely necessary if you want to see the bigger picture
arxiv.org/abs/2205.02302
2
5
34
Mario Tormo retweeted

Apr 5
more people should be talking about this github.com/NVIDIA-NeMo/DataD…
29
186
1,512
156,123
Mario Tormo retweeted

Apr 4
🚨 BREAKING: Vector databases for AI memory just got replaced by MP4 files.
Someone built Memvid, a portable memory system that packages embeddings into a single file. It stores millions of text chunks using video encoding logic for sub-millisecond retrieval.
→ Replace expensive vector databases with single file.
→ Lightning-fast semantic search without a server.
→ Portable, versioned, and crash-safe AI memory.
100% open source.

78
215
1,642
130,612
Mario Tormo retweeted

Apr 4
Imagine trying to teach someone how to swim just by letting them read books about water.
That is how we have been training AI on physics, using text descriptions.
To really learn, you need to get in the water.
"The Well" is that water.
Polymathic AI has released a massive 15TB open-source library of physics simulations. It allows AI models to experience physical phenomena directly.
Instead of reading about a supernova, the model processes the actual data of the explosion. Instead of reading about aerodynamics, it analyzes the fluid flow.
This moves us from [Generative AI] (making things up) to [Scientific AI] (discovering truth).
A huge step forward for open science.
GitHub Repo: github.com/PolymathicAI/the_…

33
312
1,993
84,795
Mario Tormo retweeted

Mar 24
🚨 Google acaba de cargarse la industria de la extracción de documentos.
Ha lanzado LangExtract, una librería que convierte texto desordenado en datos estructurados y verificables, incluso en documentos enormes.
Es gratis y open-source 👇

28
355
1,775
77,063
Mario Tormo retweeted

Mar 20
We are also releasing self-contained lecture notes that explain flow matching and diffusion models from scratch. This goes from "zero" to the state-of-the-art in modern Generative AI.
📖 Read the notes here: arxiv.org/abs/2506.02070
Joint work with @EErives40101.
Mar 18

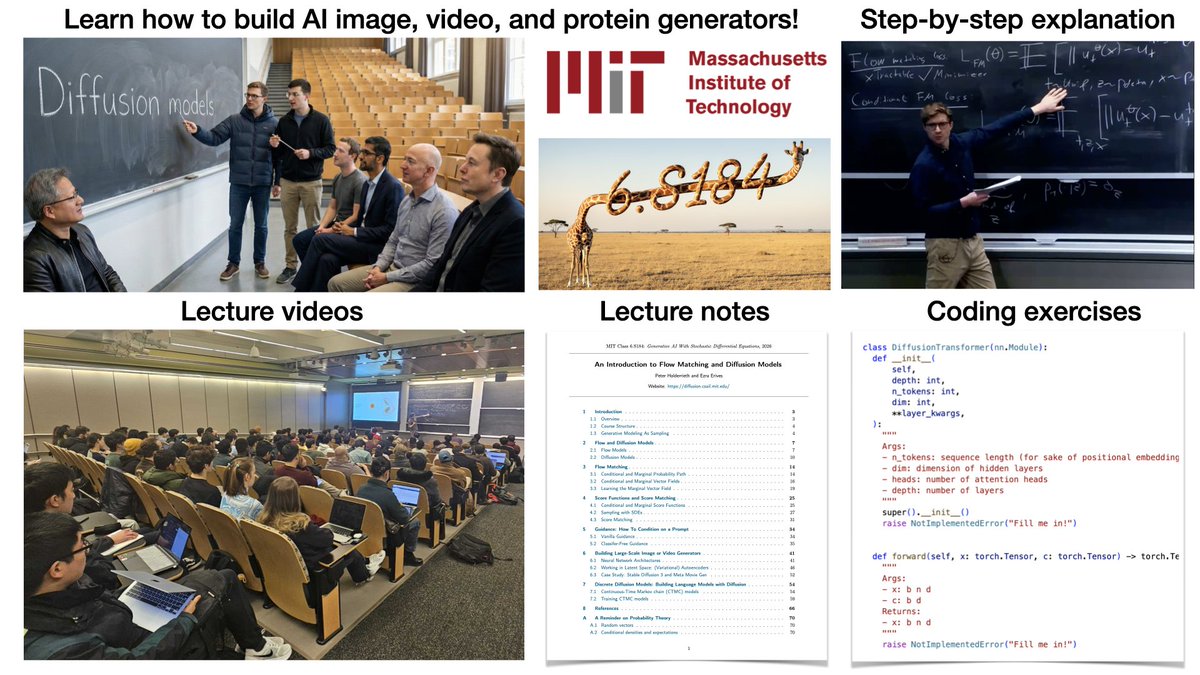
🚀MIT Flow Matching and Diffusion Lecture 2026 Released (diffusion.csail.mit.edu/)!
We just released our new MIT 2026 course on flow matching and diffusion models! We teach the full stack of modern AI image, video, protein generators - theory and practice. We include:
📺 Videos: Step-by-step derivations.
📝 Notes: Mathematically self-contained lecture notes
💻 Coding: Hands-on exercises for every component
We fully improved last years’ iteration and added new topics: latent spaces, diffusion transformers, building language models with discrete diffusion models.
Everything is available here: diffusion.csail.mit.edu/
A huge thanks to Tommi Jaakkola for his support in making this class possible and Ashay Athalye (MIT SOUL) for the incredible production! Was fun to do this with @RShprints!
#MachineLearning #GenerativeAI #MIT #DiffusionModels #AI
38
645
5,541
474,375
Mario Tormo retweeted

Feb 24
[Download 698-page PDF eBook]
Everything You Always Wanted To Know About #Mathematics* (*But didn’t even know to ask)
A Guided Journey Into the World of Abstract Mathematics, Theorems, and the Writing of Proofs: math.cmu.edu/~jmackey/151_12…

26
477
2,565
180,667
Mario Tormo retweeted
Feb 24
(Download 462-page PDF eBook)
#DataScience Theories, Models, Algorithms, and Analytics: srdas.github.io/Papers/DSA_B…
——————
#AI #MachineLearning #ML #DataScientist #Mathematics #Statistics #NeuralNetworks

3
76
265
10,038

Be careful what you put in your AGENTS dot md files.
This new research evaluates AGENTS dot md files for coding agents.
Everyone uses these context files in their repos to help AI coding agents. More context should mean better performance, right?
Not quite. This study tested Claude Code (Sonnet-4.5), Codex (GPT-5.2/5.1 mini), and Qwen Code across SWE-bench and a new benchmark called AGENTbench with 138 real-world instances.
LLM-generated context files actually decreased task success rates by 0.5-2% while increasing inference costs by over 20%.
Agents followed the instructions, using the mentioned tools 1.6-2.5x more often, but that instruction-following paradoxically hurt performance and required 22% more reasoning tokens.
Developer-written context files performed better, improving success by about 4%, but still came with higher costs and additional steps per task. The broader pattern is that context files encourage more exploration without helping agents locate relevant files any faster. They largely duplicate what already exists in repo documentation.
The recommendation is clear. Omit LLM-generated context files entirely. Keep developer-written ones minimal and focused on task-specific requirements rather than comprehensive overviews.
I featured a paper last week that showed that LLM-generated Skills also don't work so well. Self-improving agents are exciting, but be careful of context rot and of unnecessarily overloading your context window.
Paper: arxiv.org/abs/2602.11988
Learn to build effective AI agents in our academy: academy.dair.ai/

54
65
400
68,966
Mario Tormo retweeted

Feb 21
🎓 Second lecture is live on YouTube! ▶️
Introduction to Deep Learning Research 🔬
Lesson 02: Programming a neural network 💻🧠
Behaviour by design using weights computed with maths 📐🧠
youtu.be/3_e0HVV3nMM

5
46
422
14,710
Mario Tormo retweeted

Feb 12
Deep Learning with PyTorch step by step
Total 3 volumes:
- Vol.1 (Fundamentals)
- Vol.2 (Computer Vision)
- Vol.3 (Sequences and NLP)
Official Repo: github.com/dvgodoy/PyTorchSt…



10
178
1,120
44,947
Mario Tormo retweeted

Feb 5
The Power of Mathematical Visualization
by James Tanton
Archive link: archive.org/details/ThePower…

2
260
1,451
51,086
Increasingly, I think the most important thing about papers like this Gemini science collaboration study isn't the results themselves.
It's how researchers actually worked with the model, iterating, correcting, and guiding it through tough problems. We still don't have good norms for reporting this kind of collaboration, and I think that matters more than people realize.
This work documents how researchers prompted the model, how many back-and-forth rounds it took, and what happens when the model gets stuck, and they have to decompose the problem differently. It's all new territory.
If these collaboration techniques become standard practice (iterative refinement, using AI to stress-test your own reasoning, and having it generate counterexamples), then the gap between labs that train researchers in AI collaboration and those that don't will compound fast.
Nonetheless, this is a fascinating read. Highly recommend it to everyone.

10
27
134
11,279
Mario Tormo retweeted

Jan 31
Holy shit… this paper from MIT quietly explains how models can teach themselves to reason when they’re completely stuck 🤯
The core idea is deceptively simple:
Reasoning fails because learning has nothing to latch onto.
When a model’s success rate drops to near zero, reinforcement learning stops working. No reward signal. No gradient. No improvement. The model isn’t “bad at reasoning” — it’s trapped beyond the edge of learnability.
This paper reframes the problem.
Instead of asking “How do we make the model solve harder problems?”
They ask: “How does a model create problems it can learn from?”
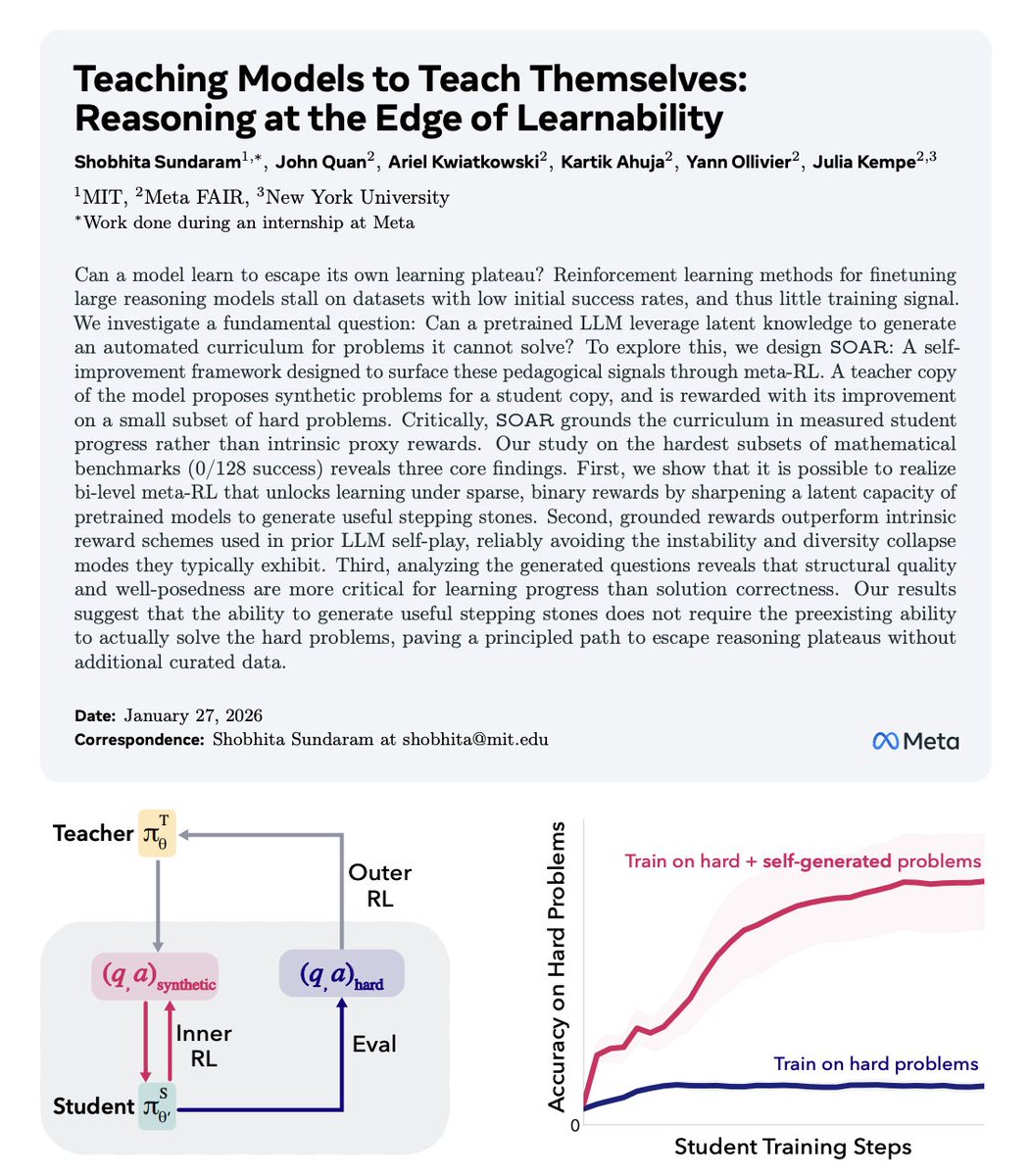
That’s where SOAR comes in.
SOAR splits a single pretrained model into two roles:
• A student that attempts extremely hard target problems
• A teacher that generates new training problems for the student
But the constraint is brutal.
The teacher is never rewarded for clever questions, diversity, or realism.
It’s rewarded only if the student’s performance improves on a fixed set of real evaluation problems.
No improvement? No reward.
This changes the dynamics completely.
The teacher isn’t optimizing for aesthetics or novelty.
It’s optimizing for learning progress.
Over time, the teacher discovers something humans usually hard-code manually:
Intermediate problems.
Not solved versions of the target task.
Not watered-down copies.
But problems that sit just inside the student’s current capability boundary — close enough to learn from, far enough to matter.
Here’s the surprising part.
Those generated problems do not need correct answers.
They don’t even need to be solvable by the teacher.
What matters is structure.
If the question forces the student to reason in the right direction, gradient signal emerges even without perfect supervision. Learning happens through struggle, not imitation.
That’s why SOAR works where direct RL fails.
Instead of slamming into a reward cliff, the student climbs a staircase it helped build.
The experiments make this painfully clear.
On benchmarks where models start at absolute zero — literally 0 successes — standard methods flatline. With SOAR, performance begins to rise steadily as the curriculum reshapes itself around the model’s internal knowledge.
This is a quiet but radical shift.
We usually think reasoning is limited by model size, data scale, or training compute.
This paper suggests another bottleneck entirely:
Bad learning environments.
If models can generate their own stepping stones, many “reasoning limits” stop being limits at all.
No new architecture.
No extra human labels.
No bigger models.
Just better incentives for how learning unfolds.
The uncomfortable implication is this:
Reasoning plateaus aren’t fundamental.
They’re self-inflicted.
And the path forward isn’t forcing models to think harder it’s letting them decide what to learn next.
32
163
905
56,593
Mario Tormo retweeted
Jan 29
"The Colossal Book of Short Puzzles and Problems"
Get it at amzn.to/4a0ecUd [512 pages]
#Mathematics #Probability

2
57
308
12,239
Mario Tormo retweeted

A quiet shift is underway. The CEO of Anthropic, Dario Amodei, just published a new essay and “The Adolescence of Technology” lands on an uncomfortable truth most AI debates are avoiding.
The real risk isn’t that AI becomes powerful. It will, that is a given.
It’s that our institutions and societies aren’t mature enough to handle that power.
Intelligence is scaling faster than governance.
Capability is outpacing responsibility.
We’re building systems that can analyse, predict, simulate and persuade at superhuman levels, while relying on political, legal and organisational structures that were designed for a world where intelligence was scarce and slow.
That mismatch is dangerous.
When intelligence is abundant:
- every option looks defensible
- every delay looks rational
- every failure can be explained away
Decision-making doesn’t get better.
It gets paralysed.
And the most tempting move becomes moral outsourcing: “The system recommended it.”
That’s not safety.
That’s abdication.
The coming decade won’t be defined by who builds the smartest models.
It will be defined by whether humans, leaders, boards, governments, are willing to reclaim judgment when certainty disappears, and risks scale exponentially.
AI is entering adolescence.
The question is whether our institutions ever grew up.
thedigitalspeaker.com/when-i…

1
3
10
1,386

Nice paper discussing how to design good multi-agent systems.
Single-agent systems have no safety net. The same entity that makes mistakes is the one evaluating whether mistakes were made. Self-review shares the blind spots of the original reasoning.
We've mostly relied on bigger models, better prompts, and self-verification loops.
But self-verification often makes things worse. In one test, asking a model to verify its own correct answer caused it to change to an incorrect one 60% of the time.
This paper introduces the ideas of organizational intelligence for AI:
→ 50 specialized agents organized into teams (planners, executors, critics, experts)
→ Hierarchical veto authority; critics can reject outputs entirely, triggering internal retry
→ Pre-declared acceptance criteria established before any work begins
→ Remote code execution keeps raw data separate from reasoning context
→ Different model providers for writers vs critics to avoid monoculture
It turns out that coherence emerges from opposing forces.
Planners push for clarity, executors push for pragmatism, and critics push for correctness. Their conflicting incentives create boundaries that prevent drift in the system.
Results across 522 production sessions:
• 92.1% success rate vs 60% for single-agent
• Inner loop catches 87.8% of errors before user exposure
• Code Critique alone catches 86% of issues
• There is 38.6% computational overhead, but errors die in committee, not in production
The 7.9% residual represents errors that automated systems fundamentally cannot catch: requirement ambiguity, subjective preferences, and domain edge cases requiring external context.
Paper: arxiv.org/abs/2601.14351
Learn to build effective AI agents in our academy: dair-ai.thinkific.com/

23
59
347
32,407
Jan 26
Madre mía, esta gente está enferma, completamente cegados por el odio y la rabia, y de cualquier cosa hacen causa política. Nuestro futuro empieza a dar miedo, sobre todo si caemos en manos de estos tarados
Jan 25

La cara, miradle la cara al jefe de los corruptos que han provocado este accidente. Está acabado y lo sabe.
16
Impressive survey on agentic reasoning for LLMs.
(bookmarks this one)
135 pages!
Why does it matter?
LLMs reason well in closed-world settings, but they struggle in open-ended, dynamic environments where information evolves.
The missing piece is action. This is because static reasoning without interaction cannot adapt, learn, or improve from feedback.
This new survey systematizes the paradigm of Agentic Reasoning, where LLMs are reframed as autonomous agents that plan, act, and learn through continual interaction with their environment.
It provides a unified roadmap that bridges thoughts and actions, offering actionable guidance for building agentic systems across environmental dynamics and optimization settings.
The framework organizes agentic reasoning along three complementary dimensions:
1. Foundational Agentic Reasoning: Core single-agent capabilities including planning, tool use, and search. Agents decompose goals, invoke external tools, and verify results through executable actions. This is the bedrock.
2. Self-Evolving Agentic Reasoning: How agents improve through feedback, memory, and adaptation. Rather than following fixed reasoning paths, agents develop mechanisms for reflection, critique, and memory-driven learning. Reflexion, RL-for-memory, and continual adaptation link reasoning with learning.
3. Collective Multi-Agent Reasoning: Scaling intelligence from isolated solvers to collaborative ecosystems. Multiple agents coordinate through role assignment, communication protocols, and shared memory. Debate, disagreement resolution, and consistency through multi-turn interactions.
Across all layers, the survey distinguishes two optimization modes: in-context reasoning (scaling inference-time compute through orchestration and search without parameter updates) and post-training reasoning (internalizing strategies via RL and fine-tuning).
The survey covers applications spanning math exploration, scientific discovery, embodied robotics, healthcare, and autonomous web research. It also reviews the benchmark landscape for evaluating agentic capabilities.
I have been looking closely at this area of research, and here are some of the open challenges that remain: personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance frameworks for real-world deployment.
Paper: arxiv.org/abs/2601.12538
Learn to build effective AI agents in our academy: dair-ai.thinkific.com/

16
117
554
43,718
Mario Tormo retweeted

Jan 19
OJO 👁️ 🔴 *DESINFORMACIÓN SOBRE EL ACCIDENTE FERROVIARIO EN ADAMUZ*
❌ BULO: El mal estado de las vías, el abandono y la falta de inversión del Gobierno provocaron el accidente.
✅ CERTEZA: El tramo Córdoba–Villanueva de Córdoba fue renovado recientemente, con una inversión prevista de 700 M€ hasta 2026.
✅ CERTEZA: Las obras finalizaron en mayo de 2025 y se realizaron con criterios de mantenimiento preventivo y altos estándares de calidad.
✅ CERTEZA: El tramo estaba sometido a controles periódicos sin detección de anomalías.
✅ CERTEZA: Entre 2017 y 2024 los accidentes graves se redujeron de 26 a 18 y la tasa por viajero bajó un 7%. España tiene menos accidentes ferroviarios que Alemania, Francia o Italia, pese a tener la mayor red de alta velocidad de Europa.
————-
❌ BULO: ADIF llevaba 3 años alertando de incidencias en Adamuz y el Gobierno no actuó.
✅ CERTEZA: Las incidencias registradas eran habituales de la operativa diaria y fueron resueltas.
✅ CERTEZA: No hubo incidencias significativas el día del accidente ni en jornadas previas. Ni el tren explorador ni los más de 100 trenes que circularon ese día reportaron problemas.
————-
❌ BULO: La red ferroviaria española es tercermundista por culpa del Gobierno.
✅ CERTEZA: La inversión ferroviaria alcanzó niveles históricos: 7.397 M€ en 2023 ( 72% respecto a 2018).
✅ CERTEZA: Se han invertido 1.512 M€ en nuevo material rodante, multiplicando por diez la inversión de gobiernos anteriores.
✅ CERTEZA: El aumento de tráfico y viajeros no ha incrementado la siniestralidad.
————-
❌ BULO: Se ignoraron advertencias de maquinistas sobre vibraciones a 250 km/h.
✅ CERTEZA: El tramo ya tiene limitación a 250 km/h y los trenes circulaban por debajo (205 y 210 km/h).
✅ CERTEZA: Los sistemas de seguridad detectan vibraciones y activan el frenado automático.
✅ CERTEZA: La Agencia de Seguridad Ferroviaria no ha detectado problemas de seguridad por vibraciones en estos tramos.
————-
❌ BULO: “El dinero se manda fuera mientras los trenes se caen”.
✅ CERTEZA: La información citada es de 2019.
✅ CERTEZA: Son créditos reembolsables del FIEM, no ayudas a fondo perdido.
✅ CERTEZA: Solo se activan si empresas españolas ganan los contratos.
✅ CERTEZA: En Marruecos y Uzbekistán hubo alta participación de empresas españolas y producción “made in Spain”.
————-
❌ BULO: El ministro Óscar Puente reaccionó tarde.
✅ CERTEZA:
• Primer mensaje público: 21:13 h (menos de 2 horas después).
• Presencia en el centro de control de ADIF: 21:15 h.
• Rueda de prensa: 00:45 h.
————-
❌ BULO: El ministro dirige la investigación y habrá injerencias.
✅ CERTEZA: La investigación corresponde a la Comisión de Investigación de Accidentes Ferroviarios (CIAF), un organismo independiente con expertos externos y autonomía total.
1,122
3,447
7,922
692,423