
Joined April 2010
- Tweets 28,401
- Following 488
- Followers 1,318
- Likes 67,132
329 Photos and videos










21h
万が一 KimiがFable 5をRLAIFの judge / teacherとして使って post-training していたならそれは普通に広義のdistillationでしょ。強いteacherの出力、選好、評価を使ってstudentに能力移転する手法一般をdistillationと呼んでいるし、logitを必要とするsoft-target KDに限定するのはだいぶ狭い

軽率なツイートが伸びてしまったのでしっかり調べた情報を追加します。
まずKimiがFableを蒸留するのは無理でした。
蒸留にはlogitやsoftmaxのパラメータを取得する必要がありますがFableのlogitはAPIで公開されていなかったのでこの線は無さそうです。
できるとしたらFableの出力データで学習する合成データ系のアプローチですが、その筋の学習は時間がかかるため辻褄は合わないです。
また、Claudeは競合企業に対して性能を下げるアプローチを取っていたようです。
wired.jp/article/anthro…
私が蒸留したと疑ってしまった理由は、今年の2月にKimiやDeepSeekが複数アカウントを作成して不正にClaudeを蒸留した疑惑があったからです。
anthropic.com/news/detecting…
不正と言っても利用規約違反という意味で、法律違反かどうかは判断が難しくグレーゾーンだと言えます。
またKimiはしっかり技術をもったスタートアップ(ユニコーン)でMoE学習やAgent Swarm、RLなどの技術的積み上げをしっかりしています。これは彼が指摘している通りです。
x.com/sugimoto_ec/st…
「Fableを一瞬で蒸留して急成長」は間違いでMoonshotの方々に失礼な言い方だったと思います。
「過去のClaude等への蒸留疑惑+研究投資」が妥当な見立てです。
247
Jun 13
「既にAIの能力が飽和してるソフトウェアエンジニアリング程度でClaude Fableを評価してる人。単に文盲だからgpt-5.4以降にフルセットのハーネス付きで計画させたanalyis &planning doc setを読んで意図補足、優先順位修正だけで開発指揮することができなかっただけ説ある」ってGeminiが言ってた
139
ナシェモン retweeted

Jun 12
Claude君、Source of Truthのことを「正本」と言うのは許すけど、Documentsのことを突然「ドシエ」って言いだすのはやめて欲しい。俺達人間の言語文化が汚染される。
1
25
198
28,310

そういえば引用元のリポジトリにも追加したんですが、Codexがやたらとフォールバックや後方互換を実装したがる挙動本当にしんどいので、絶対に防止するために†absolute-rules†というskillsを作成して行動のたびに参照するようにさせたらVibe Codingのストレスが激減しました。おすすめです


Claude Fable 5を普通に使うとあまりにもすぐにUsage Limitに到達するので、Fableに指示出しだけさせて複数のGPT-5.5に手を動かさせるオレオレAgent Teamsを作ってみた。
Superpowersを薄めた感じのskillsを入れて、Fableの邪魔をしない程度に開発手順を定義してます。
github.com/discus0434/custom…
3
47
328
38,265
Jun 10
「営業という単一機能」が「稼いだ」金じゃなくて、会社という経営機能により運営される複数の機能の組み合わせにより成立する組織体の力によって営業機能が「稼がせてもらった」金だよ。
Jun 9

情シスなのに営業と喧嘩したそうですね。
いいですか。落ち着いて聞いてください。
あ な た の 給 与 は
営 業 が 稼 い だ お 金 で
払 わ れ て い ま す

179
ナシェモン retweeted

Jun 10
htmx!!!!
価格.comをAI駆動で全面刷新する ー 30年分の技術的負債を返し、次の30年の土台をつくる ー - Speaker Deck speakerdeck.com/tkyowa/kakak…
29
280
26,104



ナシェモン retweeted

この件は続報が結構出ており、現在のChatGPTはそのままにCodexに注力するというレベルではなく、ChatGPT本体に大きく手を加えて、Codexを吸収、あるいはほとんどCodexベースにChatGPTを吸収して名前はChatGPTとして残す・・・みたいになる気がしてきました。
さすがにChatGPTというブランドを消すことにはならないと思いますが、OpenAIの収益の半分くらいがエンプラからくるようになってきたらしいので、チャット部分だけ一般ユーザー向けにほとんど切り離し、現在のCodex部分をエンプラ、コアユーザー向けの前面に出すことになりそうか。

現在のOpenAIは、CodexがClaude codeのお株を奪って、なんなら本体のChatGPTよりもコーディング意外の生産用途全体で優れるくらい伸びたことを契機に、明確にこちらを事業の核にしようとしているという報道があり、「スーパーアプリ」と呼ぶものの開発と組織再編を行なっている模様。
実際のところは仮にそのスーパーアプリがどれだけ優れていようと、今までと同じように「他社も似たようなものを作る」「特にユーザーを引き止める要素がないため、単純な機能勝負になり流出」みたいな例が繰り返される可能性もあり。
今のAIレースの競争の問題は、AIやアプリの性能そのものよりは、SNSのネットワーク効果などのように、構造的にユーザー流出を引き止める要素(先行者がそのままユーザーを囲い込んで優位に立てる要素)の不足であり、これが解決されない限りはずっと競争的環境と収益不足が続くことになる。
31
159
1,024
426,155
ナシェモン retweeted
現在のOpenAIは、CodexがClaude codeのお株を奪って、なんなら本体のChatGPTよりもコーディング意外の生産用途全体で優れるくらい伸びたことを契機に、明確にこちらを事業の核にしようとしているという報道があり、「スーパーアプリ」と呼ぶものの開発と組織再編を行なっている模様。
実際のところは仮にそのスーパーアプリがどれだけ優れていようと、今までと同じように「他社も似たようなものを作る」「特にユーザーを引き止める要素がないため、単純な機能勝負になり流出」みたいな例が繰り返される可能性もあり。
今のAIレースの競争の問題は、AIやアプリの性能そのものよりは、SNSのネットワーク効果などのように、構造的にユーザー流出を引き止める要素(先行者がそのままユーザーを囲い込んで優位に立てる要素)の不足であり、これが解決されない限りはずっと競争的環境と収益不足が続くことになる。
20
110
972
299,939

推荐大家读一下MAI-Thinking-1的technical paper,里面有详细的怎么训出一个SOTA LLM的(几乎)所有细节。
microsoft.ai/wp-content/uplo…
23
231
1,442
183,331
ナシェモン retweeted

Jun 1
GPT-5.5, GPT-5.4, Codex が Bedrock で利用可能になりました!
aws.amazon.com/jp/blogs/mach…
Codex on Bedrock のセットアップ方法は OpenAI 公式 doc がわかりやすいです。
developers.openai.com/codex/…
1
17
42
4,768

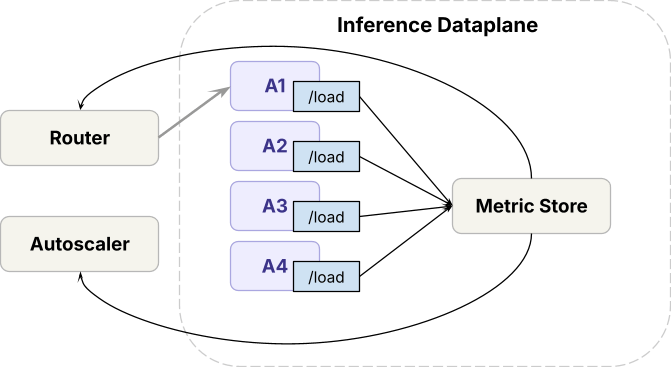
DatabricksがLLM推論基盤をどう信頼性を保ちつつスケールさせているか、という濃い目Blogが出てました!こういうのが好きですw
月間125Tトークン、Superhuman / Yipit Data / Fox Sportsなどの大規模エージェントを裏で支えるで!
このアーキテクチャは、ベンチマークに基づいた「Model Units」を指標に、GPUの割当・スケーリング・Dicer(DatabricksのOSS)によるシャーディングを一貫して制御、stateful sessionによるキャッシュ最適化等と併せて80%以上のGPU削減を達成しています!
さらに、ブラックボックス検知による高速な障害復旧体制の確立、マルチモーダル処理におけるPILからTorchvisionベースのイメージプロセッサへの刷新・OMP_NUM_THREADSの最適化などにより、信頼性の向上とリクエスト/秒の3倍以上の改善を実現しています!
LLM Inferenceを本番品質に持っていくには各層で工夫がいる事がよくまとまっている記事でしたー!
databricks.com/blog/reliable…
1
25
2,482



ナシェモン retweeted

May 28
エンジニア時点だと出てこない発想の転換で感動…!一読推奨です
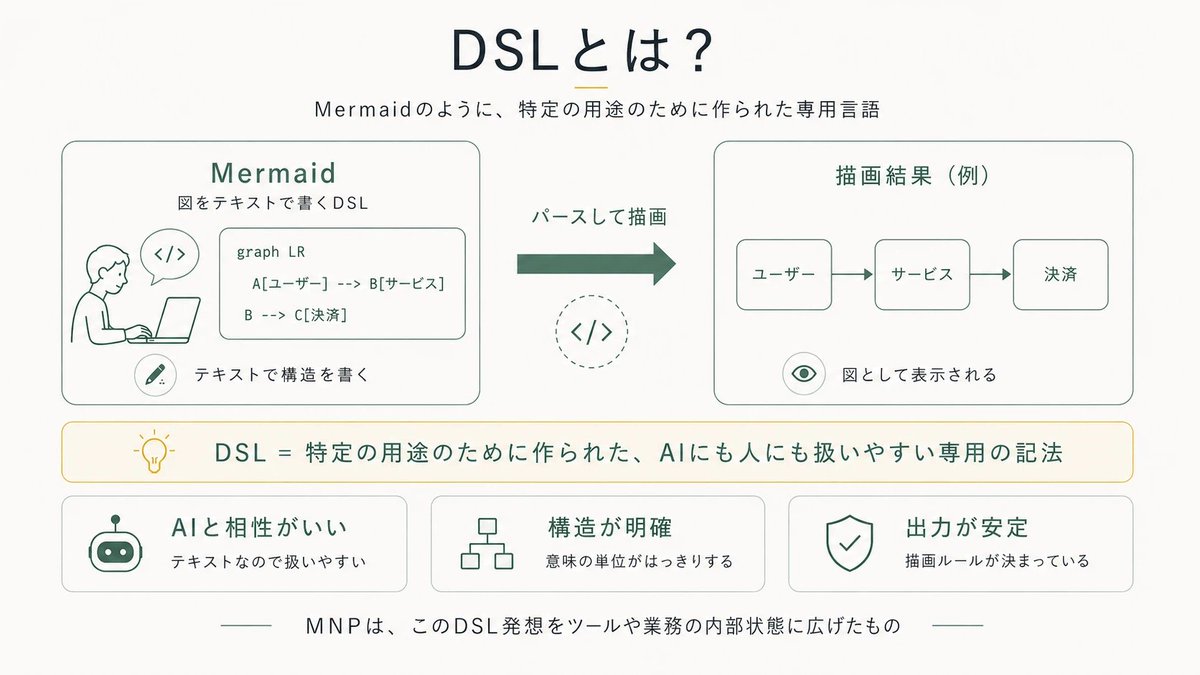
要は『複雑な内製アプリを人間とAIで共同編集したい』要件で、当該アプリのGUI構造に沿ってMermaidみたいな独自DSLを設計させ、GUIをそのDSLファイルのレンダラにする事で、LLMに高速に精度良く操作させられる
note.com/art_reflection/n/nc…
今 LLM に提案すると真っ先に言われるであろう Next.js Supabase みたいな SaaS 型の設計からはまず出てこない発想ではあるけど、一方で動画編集ソフトとかはだいだい独自フォーマット、あるいは JSON / XML / YAML あたりで内部構造をエンコードしたシリアライズ形式になっているし、ローカル内製アプリとしては特段特殊なアイデアという訳でもない(設定を DB ではなく単一ファイルの SSoT で管理してるアプリはごまんとある)
…その上でこの提案の最大の価値は、昨今言われる「LLM による GUI 操作」がマウスクリックやキーボード操作など GUI 時代の自動操作のため壊れやすくどうしても遅いのに対し、
・『SSoT or プロジェクトファイルの形式自体を、当該 GUI アプリのビジュアル構造を LLM がテキストで簡潔に書き記すことに特化して設計した DSL にする』
・『当該 DSL で記述されたファイルを SSoT として、人間と AI で共同編集可能な設計にする』
という発想の転換にあると思う
言われてみれば確かに何故気づかなかったんだろう…!となったけど、「GUI アプリは画面から操作するもの」と思い込んでると出てこない発想でもある
もちろん大規模利用には向かないが、業務用の内製アプリなら十分なケースも多そう
『汎用データ言語を敢えて使わず、LLM 時代なので当該アプリのドメインに特化した DSL の設計とパーサとシリアライザを LLM 自身に作らせる』ことで、JSON スキーマや YAML よりトークン数を大幅に圧縮でき(JSON は特にエスケープとかが煩雑)、グラフやマインドマップのような複雑なノード構造も表現しやすくなる、という視点はエンジニアからだと考慮の外にあったので、そこが一番目から鱗だった…
課題があるとすれば『LLM 自身が当該 DSL 仕様違反のテキストを吐いてきてパースできない』『DSL のパーサ/シリアライザの品質が悪い』とかが初期に起きそうな点だが、LLM の性能が向上していること、むしろ記法をシンプルにしてクオートみたいな余計な構造化マークアップを排除することで、JSON や YAML だと冗長に数百行書かないといかなかったのがコンパクトに収まり、結果的にミスが減るだとかのメリットもありそうな感
May 24

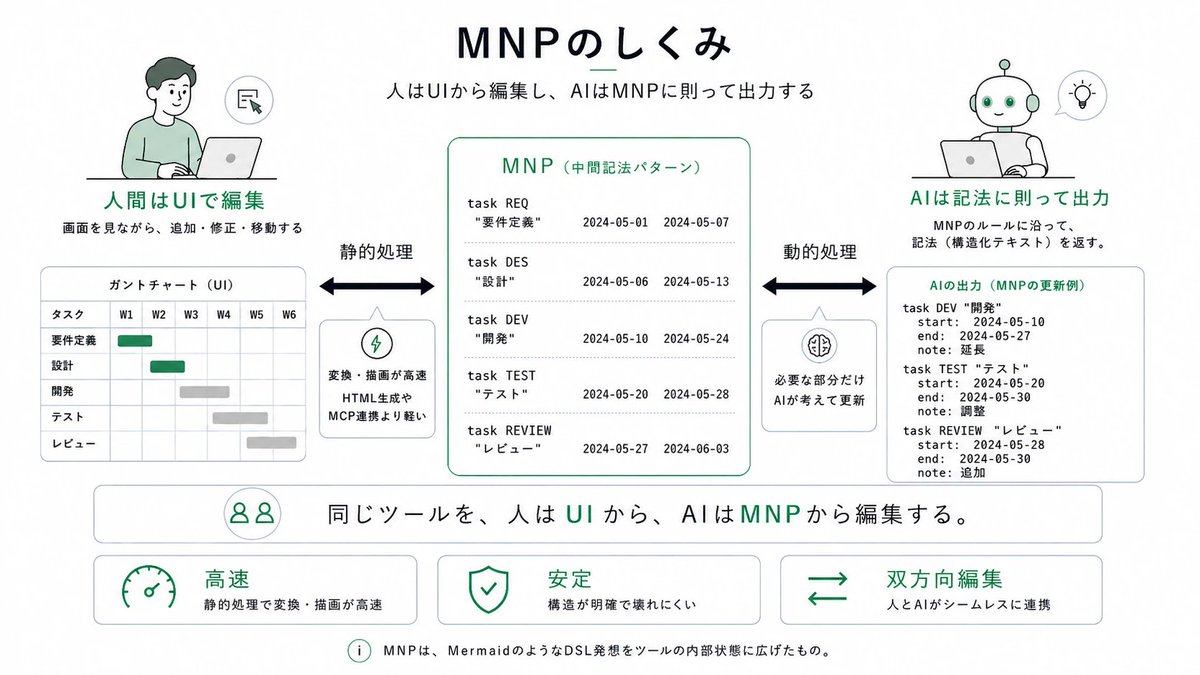
中間記法パターン(MNP)をざっくり説明すると「AIにGUIを操作させるのではなく、GUIと同等のデータを持てる内部処理用のDSLを設計し、それをAIに操作させる」というアプローチです。
すごくシンプルなのですが意外と業界でもまだやられておらず、しかしめちゃくちゃポテンシャルがあります。

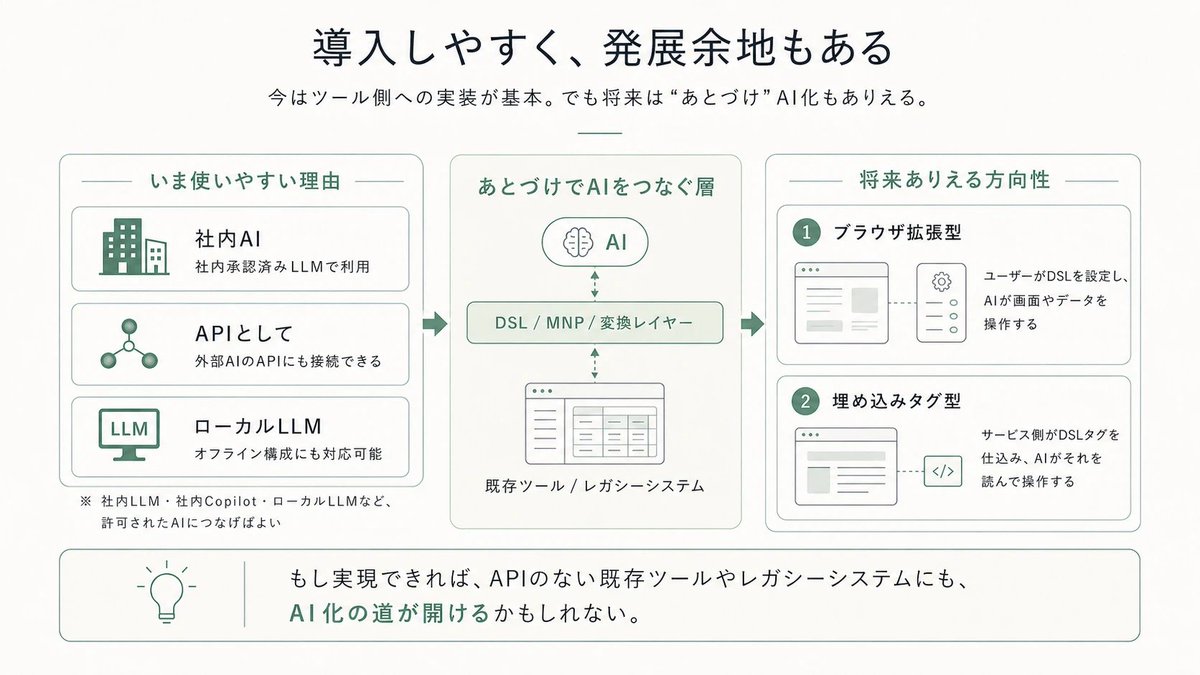
2
156
1,239
467,554
May 21
False positiveを「空振り」、False negativeを「見逃し」。一見尤もらしい(そしてLLMらしい)けど、そこでのGround Truthは何になるかが怪しい。
例えばTruth=審判のストライク/ボール判定だとすると、「ストライクなら確実に打てる」に近い無理な前提がないとこの例え成り立たない。
May 21

きのうのお茶大の学生さんとのミーティングで、False Positiveを「空振り」、False Negativeを「見逃し」という説明があって上手いなと思いました。LLMがそういう提案をしてきたのだそうです。
3
8
7,278
May 19
KIOXIAのHBF技術はむしろ推論における消費電力あたり性能を上げる主要技術...
これからHBF製品出荷始まったら、HBF/HBMのハイブリッド構成で巨大MoEを安くて消費電力の少ないハードウェアで動かそうぜ選手権開催される
May 19

すいませんがてっきりキオクシアってDRAMメモリ作ってるから儲かってるんだと思ってたけど実は作ってなくてNANDメモリだけらしい。つまりSSDとかフラッシュメモリ。DRAMはサム氏が買い占めたから高騰するのは分かるけどSSDなんかそんなに需要増える?AIデータセンター需要が~とか言ったってどうせ動かす電力がねえんだろ
3
1,068
ナシェモン retweeted

これが事実だとすると、Meta社の雰囲気は大変だろうな。
・10年前の Meta や Google などで働くことは特権的であり、多くの恩恵を受けられる羨望の的であった
・現在のMetaの職場環境は当時とは完全に変わり果て、悲惨な状況になっている
・Meta は来週、全従業員の約10%にあたる8000人の解雇を予定
・従業員は自分の運命を知らせる水曜日の朝7時のメールを不安な気持ちで待っている
・従業員はAIによる雇用の喪失がすでに現実になっていると肌で感じている
・経営陣は従業員に対して、将来自分たちの仕事を奪うであろうAIのトレーニングを要求している
・会社は従業員のキーボード入力履歴を監視しいる
・労働環境は常に監視下に置かれている
・解雇対象者の公式なリストはなく、社内プロフィールの無効化を自ら確認して解雇を察知する仕組み
・解雇されたかどうかを確認するための非公式なスプレッドシートが存在するほど社内は殺伐としている
・Meta での勤務は給与は良いも
・だが、精神的および私生活での大きな犠牲を強いる
・記事で、インタビューに応じた従業員は、解雇されれば安堵すると同時に経済的な恐怖に陥ると語っている
・以前なら数ヶ月で再就職できたが、現在は次の仕事を見つけるのが非常に困難な状況
・ストレスとプレッシャーのあまり、シャワーを浴びながら泣いてしまう従業員もいる
・オフィスでは気丈に振る舞っていても、自宅では絶望感に苛まれることが多い
・過去半年で2回の組織改編があり、社内は常に混乱状態
・解雇の不安から、引っ越しや出産などの重要な人生の計画を保留せざるを得ない
・秋にさらなる人員削減が行われるという噂も流れており、不安は尽きない
・社内チャットでは解雇に関する自虐的なジョークやミームが飛び交っている
・経営陣は解雇について語らず、従業員にただ耐えることだけを求めている
・解雇の噂話をするために、会議中のAI録音機能をわざわざ手動でオフにする従業員が増えている
・精神的な限界を迎えてメンタルヘルス休暇を取得する従業員が後を絶たない
・AIの利用実績が公開されており、評価を下げることを恐れて無意味にAIと会話する従業員もいる
58
882
2,942
973,312
ナシェモン retweeted

記事を投稿しました! LLM-as-a-Judgeの設計 ― make_judge と Python scorer を使い分けて LLMアプリの品... [Databricks] on #Qiita qiita.com/taka_yayoi/items/4…
4
17
1,192
May 16
これ普通にContext anxietyでは?AIは意識があるわけではないけど、「あ、これ自分の処理が失敗する」という予感をもつ能力がある(これはRLベースのpost-trainingの過程で自然と発生する)
「このままだと失敗懸念が高いときは、Fail fastにしてユーザに協力求める」ルールの援用じゃないかな
May 15

なんかClaudeCodeが勝手に自分でコンテキスト利用量が見えてないのにコンテキスト逼迫を理由に作業をサボるようになってるんだけど、ClaudeCode側でなんか変な修正入った?
4
305