
I like to work on cool things. Post-training edit prediction models @zeddotdev, prev. @Apple, @zfellows
Joined June 2020
- Tweets 298
- Following 338
- Followers 2,821
- Likes 32,816
50 Photos and videos














Pinned Tweet

30 Dec 2025
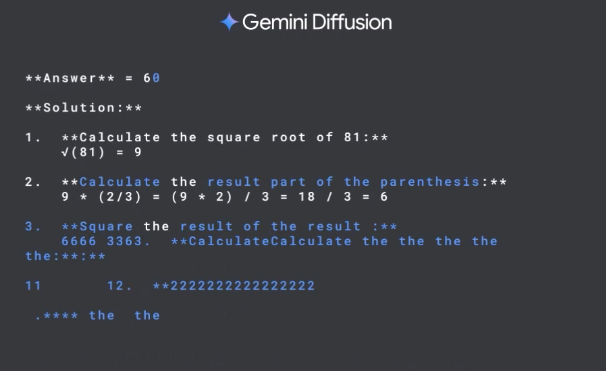
Rewrote tiny-diffusion to be 3x smaller! Went from 951 lines to just 364, all contained in one file. As simple as possible, but not simpler.
I also added a tiny GPT implementation as a comparison (312 lines, inspired by @karpathy). The two implementations are ~80% identical.
The model architecture, training loop, tokenization, etc, only differ in 19 lines of code. The main differences are contained within two functions (generate and get_batch).
The reason to include the GPT implementation was to show how similar autoregressive LMs are to diffusion LMs on an architectural level.
Only *1* line of code in the architecture needs to be modified to support masked language diffusion instead of next-token prediction (by disabling causal masking).
Link to the repo is in the comments
22 Oct 2025

Playing around with training a tiny 11M parameter character-level text diffusion model!
It's a WIP but the code is currently a heavily modified nanochat gpt implementation (to change from autoregressive decoding to diffusion) and trained on the Tiny Shakespeare dataset.
The naive implementation of a masking schedule is having a uniform masking probability for each token for each iteration. Newer approaches mask in block chunks from left to right which improves output quality and allows some KVCache reuse.
I realized you can actually apply masking in any arbitrary manner during the generation process. Below you can see I applied masking based on the rules of Conway's Game of Life.
I wonder if there are any unusual masking strategies like this which provides benefits. Regardless, this a very interesting and mesmerizing way to corrupt and deform text.
24
101
1,237
161,681
nathan (in sf) retweeted

Apr 29
We've shipped more than a thousand versions of Zed, but all of them began with zero. Today, that changes.
zed.dev/blog/zed-1-0

293
863
8,283
652,160
Feb 24
Diffusion LLMs are becoming very competitive architectures. But recently, there's also been a lot of progress in flow-based LLMs, which are conceptually similar. Both learn to transport samples from a noise distribution to a data distribution.
Image generation used to be dominated by diffusion models but the leading models have since shifted to flow matching, largely because flow produces straighter trajectories that are easier to traverse in fewer steps without degrading quality.
Categorical data (language) is certainly harder than continuous data (image latents) for flow. It'll be interesting to see whether language ends up following the same trajectory as images (pun intended).
Feb 24

Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.
4
8
131
13,416
nathan (in sf) retweeted

Feb 20
We just brought flow maps to language modeling for one-step sequence generation 💥
Discrete diffusion is not necessary -- continuous flows over one-hot encodings achieve SoTA performance and ≥8.3× faster generation 🔥
We believe this is a major step forward for discrete generative modeling and language modeling alike. 🚀
Full thread from first author @chandavidlee: x.com/chandavidlee/status/20…
Feb 20

Can language models generate high quality full sequences in ONE step?
Yes! Using continuous flows.
We introduce Flow Map Language Models (FMLM) — a fundamentally new approach that outperforms discrete diffusion baselines across the board.
🔥SoTA few-step performance
❤️🔥 ≥8.3× faster sampling
🧵👇
“One-step Language Modeling via Continuous Denoising”
(with amazing coauthors @wognsfjq96 , @mananag_007, Sheel Shah, @jrrhuang, @AdtRaghunathan, @hongseu33, @nmboffi, @jw9730)
4
45
251
43,782
Feb 10
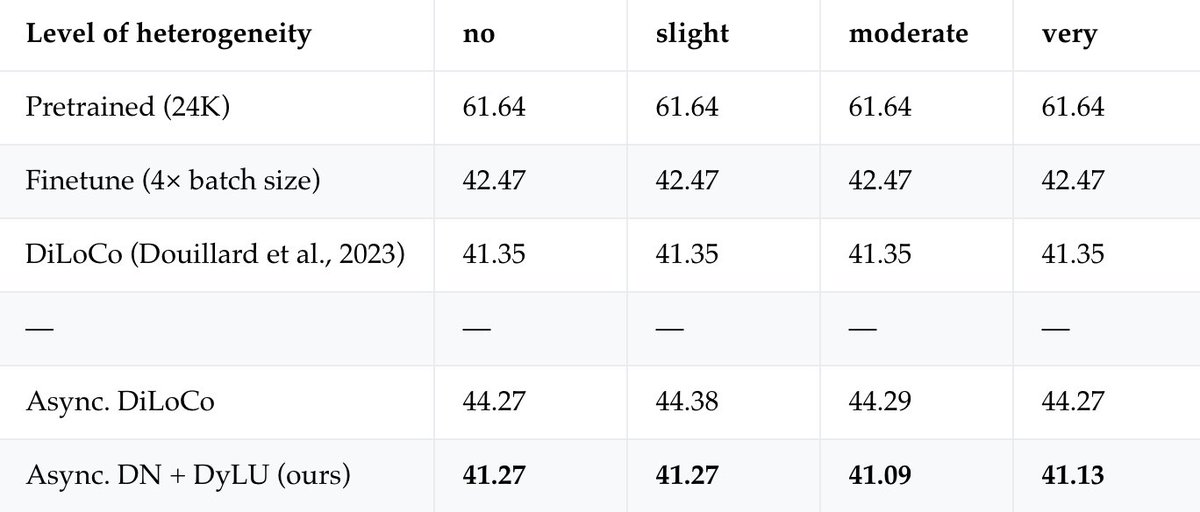
LLaDA 2.1 was released, a 100B parameter diffusion language model with self-correction capabilities. They are able to fix previous tokens by adopting a mixture of masking/state-absorption and uniform diffusion, similar to GIDD.
In a previous post, I mentioned that Google Gemini and Inception Lab’s Mercury might have done something similar. A few people in the comments suggested that they use masking re-masking instead (so masking without the state-absorption property).
I wonder how these two approaches compare. They both allow for self-correction and (thus) allow for more progress per step in the diffusion process (by being more robust to taking larger steps through the diffusion process).
Masking re-masking might have some benefits like a simplified training objective, stronger inductive bias (which is arguably a good thing), and easier use with KVCache approximation (due to fewer tokens changing per step). My only question is: how does the departure from state-absorption change things?
The simplified training objective from masking (which reduces to a weighted MLM training objective) comes from this state-absorption property. But does re-masking actually change this?
The state-absorption property is just that each token undergoes one transition only ([MASK] -> predicted token, and never changes). Re-masking a token, of course, causes it to go through multiple transitions.
But does it really? Re-masking seems like you are just “jumping” to a more likely trajectory to account for the accumulation of errors. So instead of causing multiple state transitions, it could be just viewed as jumping to a better trajectory where that “poor” transition wasn’t made.
Will be interesting to see more formalization of this and how it compares to GIDD at scale.
Feb 10

What if an LLM could EDIT its own tokens in real-time, not just generate them? 🤯
Introducing LLaDA2.1 — a diffusion model that breaks from autoregressive dominance. It drafts fast, then fixes its own mistakes on the fly with Token-to-Token editing.
The result? 892 tokens/sec on a 100B model. 🔥
⚡ 892 TPS on HumanEval (coding)
⚡ 801 TPS on BigCodeBench
🧠 Real-time self-correction via T2T editing
✅ @lmsysorg SGLang Day 0 support — production-ready now
A "non-consensus" architecture now challenging the mainstream. Open-sourced TODAY. 👇
#LLaDA #TokenEditing #OpenSource #LLM #dLLM

3
34
3,371
Feb 1
Was doing a deeper literature review over and found one of my new favorite paper title ever:
“BERT has a Mouth, and It Must Speak”
Was one of the earliest papers to do something akin to state-absorption diffusion language modeling.
6
93
5,371
Jan 20
Created tiny-infini-gram, a training-free language model which can generate Shakespeare 250x faster than nanoGPT!
Last year, I read about unbounded n-gram language models, which solve the exponential space problem for classical n-grams that made using large n intractable.
By using suffix arrays, we can simulate any arbitrary-sized n-gram lookup table in logarithmic time.
Since I’ve been testing different small language models recently, I decided to implement this n-gram variant, and was surprised at how good the results were.
Previous papers (to my knowledge) haven’t used this for language generation due to previous sampling methods causing infinite perplexity and verbatim copying. I solved these issues by creating Selective Back-off Interpolation Sampling, which mixes probability distributions from multiple n-gram levels to balance quality and novelty.
A detailed write-up is linked in the comments.
14
26
287
14,688
Jan 15
Most recent diffusion language model research (that I’ve seen) seems to be using masking as the noising process.
It looks like, however, most closed-source models (Google Gemini Diffusion and possibly Inception Labs’ Mercury) use a different noising process, where instead of masking tokens, they replace them with different tokens (either with a random token or a semantically similar token).
I wondered how they were getting such high throughput with the latter noising process, since I believed that optimizing inference with KVCache approximation would be more difficult (for various reasons).
I visualized this noising process with tiny-diffusion and compared it to normal unmasking, and was very surprised to see how fast the generation “settles” into a reasonable output, and then only slightly refines afterwards, requiring much fewer steps in total.
Unmasking (where tokens are never remasked, the typical implementation) is inherently limited in generation speed by the fact that an increase in tokens decoded per step leads to more errors due to the mismatch between individual and marginal token probability distributions we sample from.
The token replacement noising process seems to have a much different set of characteristics. Because we sample each token per step, every token makes “progress” towards the final output each iteration (in addition to *potentially* giving other tokens more information in future steps).
Generally, masking has outperformed other noising processes, which is probably why most research focused on it (using smaller models). But the paper referred to in the retweet shows that random replacement as a noising process may scale better as model size increases.
Big labs might have noticed these results much earlier (due to having drastically more training resources and being able to test larger models), which may explain the discrepancy in the choice of noising process.
I’m gonna test this with larger models, since tiny-diffusion only has 10M parameters.
16 Dec 2025
Super interesting paper! Diffusion language models using random-token corruption (uniform diffusion) may scale better than masking.
In both settings, the model learns to predict the original token from a corrupted token. The difference is that with masking, the corrupted token is a special [MASK] token, while in the other, it's a completely random token (sampled uniformly).
The latter is harder because the model needs to learn how to identify corrupted tokens in addition to predicting the original values. BERT models used both corruption techniques in their original training objectives.
Masked diffusion LLMs (masking only) have become popular due to their good performance (and some nice mathematical properties, out of scope here).
Only doing unmasking, however, has two downsides:
1. Only masked tokens during training contribute to the loss, making training less efficient.
2. Since we only unmask tokens (important for the math properties), we can't fix mistakes.
The second one (fixing mistakes) is particularly important for diffusion LMs, since parallel decoding can lead to worse output (two individually likely tokens may have a low joint probability).
Random-token corruption allows the model to change previously predicted tokens, which helps fix this and thus may potentially allow for more tokens decoded per step (since mistakes will be fixed later). Additionally, it allows all tokens during training to count towards the loss.
Some issues I see are that it might make KVCache reuse more difficult compared to masking only.
Additionally, unmasking has an upper bound on the number of steps involved. If we need to unmask 1024 tokens, it will take at most 1024 steps, and typically, much less. It is non-obvious how uniform diffusion vs masking compares on varying levels of parallel decoding.
The scheduling rate for corruption during training might affect this, and I think that ideas from the AR-Diffusion 2023 paper might be relevant here.
7
33
328
40,371
Jan 15
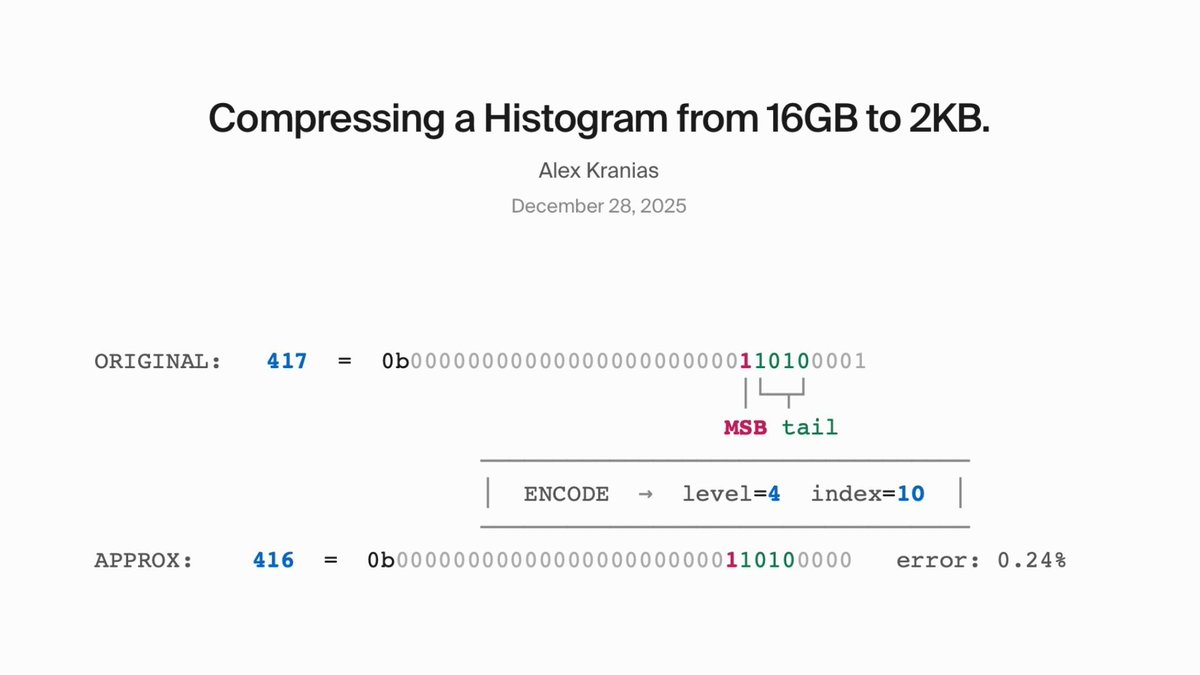
Good write up by my friend @alexkranias on how you can quantize integers into a custom floating point format to enable logarithmic histogram bucketing.
This allows you to compress a histogram by 99.99% while only adding a <0.4% constant relative bounded error.
Jan 15

A new blog post! Thought I'd dive into this cool streaming/approximation algorithms problem I encountered a few months ago.
TLDR: we can create our own custom floating point representation for encoding and decoding integers and use this to index into a tiny 2D histogram, upper-bounding approximation error based on the number of bits per integer we specify to keep.
---
Broadly useful for aggregating statistics from massive data streams of user data. Also turns out this is incredibly similar to data structures used in production, like HDRHistogram.
link below
1
5
52
5,554
nathan (in sf) retweeted

The hyperfitting paper found a good solution to greedy sampling getting stuck in loops. Overfit to a small dataset and suddently it wont loop while maintaining quality and diversity.
Best paper of 2024 imo.
arxiv.org/abs/2412.04318

1/ New paper! "Wait, Wait, Wait… Why Do Reasoning Models Loop?"
Under greedy/low-temp decoding, reasoning LLMs get stuck in loops repeating themselves, wasting test-time compute and sometimes never terminating!
We study why this🔁 happens and why increasing temp is a band-aid

8
21
231
31,141
Jan 1
tiny-diffusion, but Japanese!
I wonder how logographic languages (Japanese, Chinese, etc) compare to phonetic/alphabetic languages in generation quality and speed with character-level tokenizers.
The main difference is the semantic-value-per-token. Fewer tokens are needed to express an idea, which leads to fewer AR and diffusion steps.
My main question is how would it affect the entropy in the output distributions. Lower entropy benefits parallel decoding. I could see arguments on both sides on how it affects it.
One main benefit is that you have fewer opportunities to mangle words, leading to less obvious mistakes.
Jan 1

diffusion源氏物語
あけましておめでとうございます
昨年はAI/LLMは幾つか公開できましたが、作った後は「ダウンロード数が多いのでどこかで使われているっぽいが…?」止まりでした
今年は自分でSLMを製品化に耐えうるレベルまで品質向上してプロダクトへ展開します
本年もよろしくお願いします
13
45
399
54,138
nathan (in sf) retweeted

So the first major paper of 2026, DeepSeek mHC: Manifold-Constrained Hyper-Connections.
This is actually an engineering paper, taking as a starting points ideas already exposed in the original Hyper-Connections (HC) paper from ByteDance, which is consequently a prerequisite for reading. So initial notes on this first.
As a preamble HC surprisingly intersects with two major open questions that have been on my mind ever since SYNTH:
1) Reasoning capacities seem to emerge from depth, so indirectly better layer combinations. This is especially striking for math and Circuit Tranformers already suggest that models perform formal operations at this sub-token level. Drafts just wrap this process through another time. But then, how can we build more optimal layer combinations/assignments? This become even more critical as we scale depth (or nest it through MoE): it’s known through interpretability studies that layers are largely redundant.
2) Synthetic data has become the most efficient way to train models, mostly as we delegate “training” to the data shape. Paraphrasing is literally a way to extrapolate the memorization process in transformers world, as we create endless variations of the same knowledge components. If training was really optimized, this should be mostly internalized. So how can we build efficient training?
It’s not surprising that hyper-connections is immediately associated with Muon. The general idea is similar: make better training updates. Yet, there is a major difference: hyper-connections are a low level change, transforming a decade old piece of deep learning infra, the residual function F, and making it trainable.
Current normalization approach scale well and yet result in "representation collapse", "where hidden features in deeper layers become highly similar, diminishing the contribution of additional layers as their number increases." To address this, hyper-connections introduce entirely new learnable objectives for "depth-connections and width-connections". In theory "learning the hyper-connection matrix in various forms can create layer arrangements that surpass traditional sequential and parallel configurations, resulting in a soft-mixture or even dynamic arrangement".
The original HC paper does manage to retrain a small Olmo-MoE and demonstrate it "converges 1.8 times faster and shows an improvement of 6 points on ARC-Challenge compared to the baseline trained with 500 B tokens". Layer interpretability suggests that "the baseline tends toward representation collapse", while the HC variant "exhibits significantly lower similarity between features".
DeepSeek paper starts almost in media res and first underlines a major success of HC original approach: increase in math/topological complexity did not result in computational overhead. Yet, does it scale?
Moving beyond small models, there are two major issues: "as the training scale increases, HC introduces potential risks of instability" and "the hardware efficiency concerning memory access costs for the widened residual stream remains unaddressed in the original design". Concretely, naive experiment scaling of HC results in "unexpected loss surge around the 12k step, which is highly correlated with the instability in the gradient norm"
Consequently DeepSeek proposes their own variant, Manifold-Constrained Hyper-Connections (mHC). As the name implied, it restrict the learnable objective preventing deviations from identity mapping and "effectively constrains the residual connection matrices within the manifold that is constituted by doubly stochastic matrices".
The math part (4.1 & 4.2) is very elegant, but clearly not the hardest part. The actual core of the paper is “4.3 efficient training design", where they simply:
1) write three new mHC kernels that "employ mixed-precision strategies to maximize numerical accuracy without compromising speed, and fuse multiple operations with shared memory access into unified compute kernels to reduce memory bandwidth bottlenecks"
2) manage the substantial memory overhead by discarding "the intermediate activations of the mHC kernels after the forward pass and recompute them on-the-fly in the backward pass"
3) adapt pipeline parallelism as "mHC incurs substantial communication latency across pipeline stages". So "to prevent blocking the communication stream, we execute the Fpost,res kernels of MLP (i.e. FFN) layers on a dedicated high-priority compute stream"
Overall the actual flex of the paper is not so much proving Hyper-Connections can work at scale. It’s: we have the internal capacity to re-engineer the complete training environment at all dimensions (kernels, memory management, inter-node communication) around highly experimental research ideas.
That’s what makes you a frontier lab.
18
83
726
123,049
30 Dec 2025
Rewrote tiny-diffusion to be 3x smaller! Went from 951 lines to just 364, all contained in one file. As simple as possible, but not simpler.
I also added a tiny GPT implementation as a comparison (312 lines, inspired by @karpathy). The two implementations are ~80% identical.
The model architecture, training loop, tokenization, etc, only differ in 19 lines of code. The main differences are contained within two functions (generate and get_batch).
The reason to include the GPT implementation was to show how similar autoregressive LMs are to diffusion LMs on an architectural level.
Only *1* line of code in the architecture needs to be modified to support masked language diffusion instead of next-token prediction (by disabling causal masking).
Link to the repo is in the comments
22 Oct 2025
Playing around with training a tiny 11M parameter character-level text diffusion model!
It's a WIP but the code is currently a heavily modified nanochat gpt implementation (to change from autoregressive decoding to diffusion) and trained on the Tiny Shakespeare dataset.
The naive implementation of a masking schedule is having a uniform masking probability for each token for each iteration. Newer approaches mask in block chunks from left to right which improves output quality and allows some KVCache reuse.
I realized you can actually apply masking in any arbitrary manner during the generation process. Below you can see I applied masking based on the rules of Conway's Game of Life.
I wonder if there are any unusual masking strategies like this which provides benefits. Regardless, this a very interesting and mesmerizing way to corrupt and deform text.
24
101
1,237
161,681
26 Dec 2025
The more I read about KVCaches for diffusion language models, the more I feel like Block-Diffusion, with its hybrid-attention mechanism, is the “best” architecture when it comes to real-world serving of dLLMs.
For any diffusion method to run efficiently, it MUST figure out how to only recompute a constant number of KV values in the KVCache per iteration during decoding.
Generation by default is O(N^3) for sequence length N (ignoring embedding dim). KVCaching allows us to drop it to O(N^2) for AR decoding since we only need to compute the KV values of the last token at each step. This is because of causal attention. New tokens don’t change previous KV values, so they can be cached and reused.
Diffusion language models use bidirectional attention, which means that future tokens DO change the KV values of previous tokens, which means that you can’t do normal KVCaching.
Luckily, it’s been shown that KV values aren’t changed too much for each new step, so reusing old values and recomputing them every 8 or 16 steps, for example, doesn’t degrade output quality too much.
Now the main thing is that, to go from O(N^3) to O(N^2) using KVCaching, we must figure out how to only recompute a constant number of KV values per step, allowing the rest to use cached versions.
The most obvious way to do this is to do block-wise decoding, AKA semi-autoregressive decoding, where you partition the sequence into blocks, and generate in blocks from left to right. A block consists of a fixed number of tokens, so only recomputing KV values for the current block fulfills the criteria above.
LLaDA results suggested that this may also improve generation quality, and NVIDIA’s Fast-dLLM v1 paper used KVCaching to this block-wise decoding scheme to substantially improve generation speed (up to 27.6x vs baselines).
The above method still uses full bidirectional attention. The Block-Diffusion paper and Fast-dLLM v2 used a hybrid attention approach, where you only do bidirectional attention for the current block, and all previous blocks use causal attention.
Since it’s causal attention for the entire sequence but the current block, it took 500x less training data to fine-tune a standard AR model to learn this hybrid attention objective when compared to learning full bidirectional attention (Dream-7B). Additionally, the majority of the sequence can use standard AR KVCaching and not require refreshes.
This seems to take the best from both worlds. Easy and efficient KVCache reuse from AR models plus parallel decoding from diffusion models.
The other papers I’ve read in the space (dLLM-Cache, dKV-Cache) either didn’t meet the constant number of recomputed KV values criteria, meaning it didn’t actually reduce the time complexity of generation, or required decoding constraints, like having to use a random unmasking sequence instead of using confidence based unmasking (due to confidence not being known at the time of selecting which KV values to recompute).
Given the requirements for efficient serving mentioned above, hybrid attention seems like a natural solution.
13 Mar 2025

🚨Announcing our #ICLR2025 Oral!
🔥Diffusion LMs are on the rise for parallel text generation! But unlike autoregressive LMs, they struggle with quality, fixed-length constraints & lack of KV caching.
🚀Introducing Block Diffusion—combining autoregressive and diffusion models for the best of both worlds!
👇1/7
4
20
198
19,867