
Joined December 2024
- Tweets 812
- Following 429
- Followers 60
- Likes 22,846
125 Photos and videos



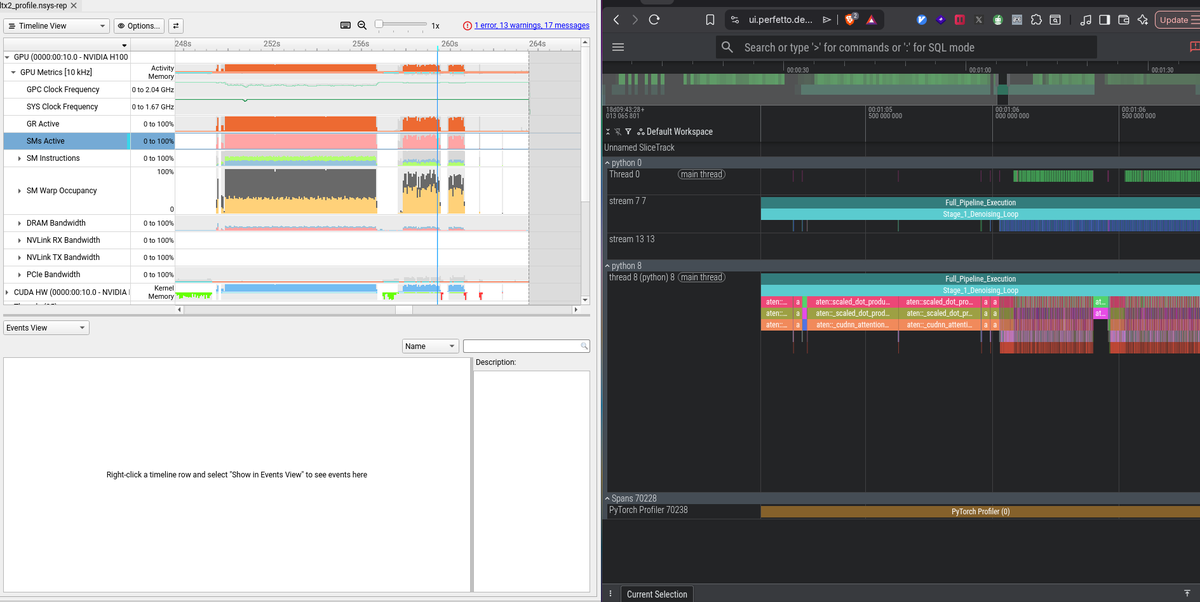
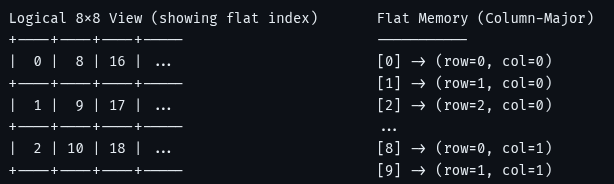
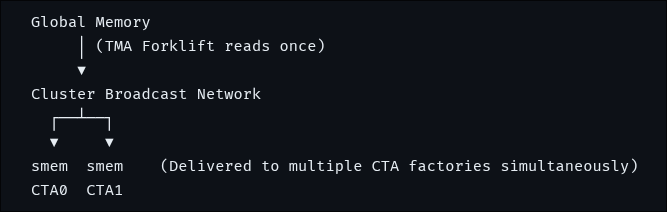


Pinned Tweet

Jan 22
it seems optimization in cs is just doing data transfer/manipulation on chunks of data
1
409
process for generating knowledge is virtually indistinguishable from process for generating speech
2

Darshan retweeted

I see a lot of enthusiasm about building sovereign models on my timeline.
That's great to hear and India needs it, BUT.. building a Fable-class model is a compute and funding game. Last I checked, India had ~50-100k H100 equivalents while frontier labs would have a million each.
Unless we have a paradigm shift in how AIs are trained, the conversation ought to be happening about amount of funding available to do what we want to do. Show me an Indian company that's secured funding/compute in the same range as that of Chinese AI labs (let alone American labs).
Without compute, what will happen is what has happened before: we'd promise to shake the world and then build models that are a year or two behind the top ones.
The path forward for sovereign models that I see is to invest in basic R&D so we have a chance to go beyond the current paradigm, OR the government pooling in several orders of magnitude more compute to seriously commit competing at par.
82
75
939
58,446
Jun 13
wtf?
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
1
8
Jun 9
To feel the burning itch of curiosity requires both that you be ignorant, and that you desire to relinquish your ignorance.
23
Jun 8
People should get smarter at a rate sufficient to integrate their old experiences, but not so much smarter so fast that they can't integrate their new intelligence. Being smarter means you get bored faster, but you can also tackle new challenges you couldn't understand before.
1
29
Jun 5
"What I cannot create, I do not understand."
Introducing: The Feynman GPU Lectures.
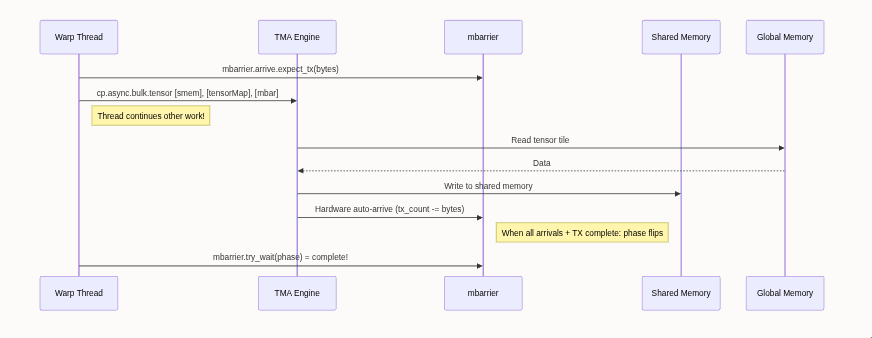
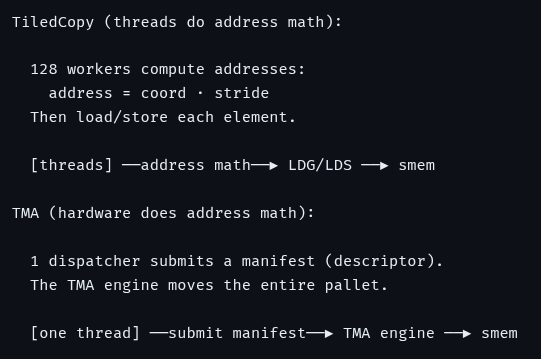
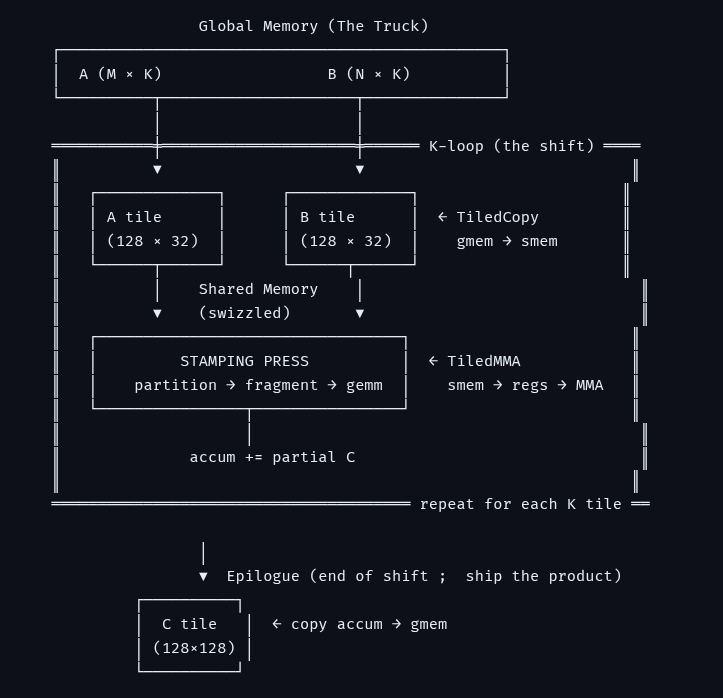
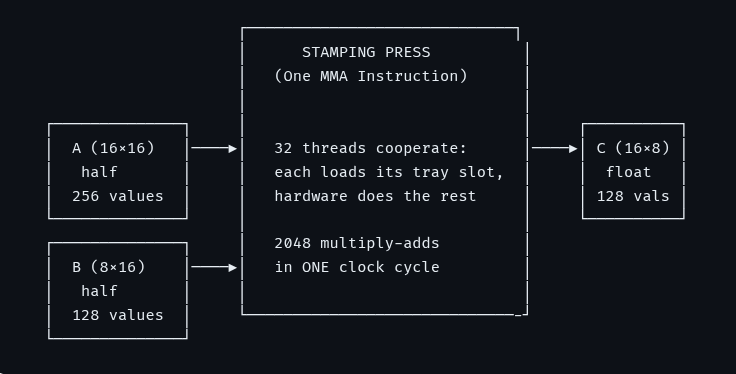
Your H100s and B200s are running at a fraction of their peak utilization because your custom kernels are written with massive hardware bottlenecks. If you don't know what tcgen05. mma does at the wire level, you're lighting compute efficiency on fire.
1
2
44
Jun 5
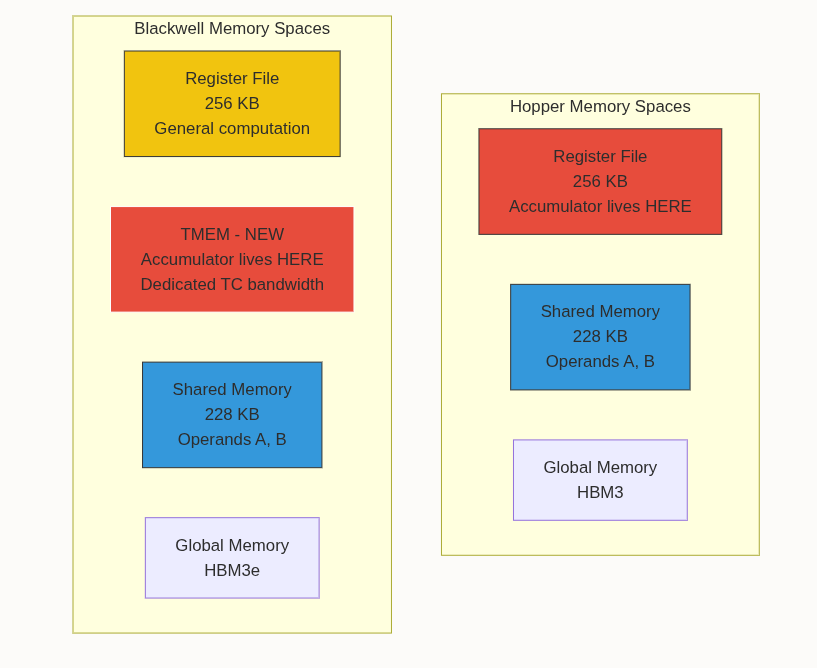
Register files used to be the ultimate bottleneck for Tensor Core accumulators. Introducing Blackwell’s Tensor Memory (TMEM), a completely new address space inside the SM that isolates the accumulator entirely from the register file.
1
21
Jun 5
Introducing your new modern GPU blueprint. Read the full post here: dcbaslani.xyz/blog/gpu_maste…
14
Jun 1
Open source is catching up to fronteir labs!

Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities
- Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1, 34.8% SWE-fficiency, 28.8% KernelBench Hard, 74.2% MCP Atlas
- MiniMax Sparse Attention scales context to 1M
- Natively Multimodal from Step Zero
API: platform.minimax.io
Token Plan: platform.minimax.io/subscrib…
🚀New! MiniMax Code: code.minimax.io
Weights & Tech Report in ~10 Days

27
May 28
This is crazy work!!!!

SpaceX has almost finished writing V1.0 of an in-house AI training stack in C that exact-maps to 220k GB300s with 800G NICs, making heavy use of pipeline parallelism and getting as close to bare metal as possible.
The potential speed improvement vs JAX for large training runs is over an order of magnitude.
37
May 25
Just managed to 5x the inference throughput of Qwen 3.5 on a B200 (from ~16 tok/s to ~83 tok/s) by ripping out PyTorch overhead and building custom fused kernels.
I wrote a full deep dive on how to move from memory-bound PyTorch to compute-bound
3
2
244
May 25
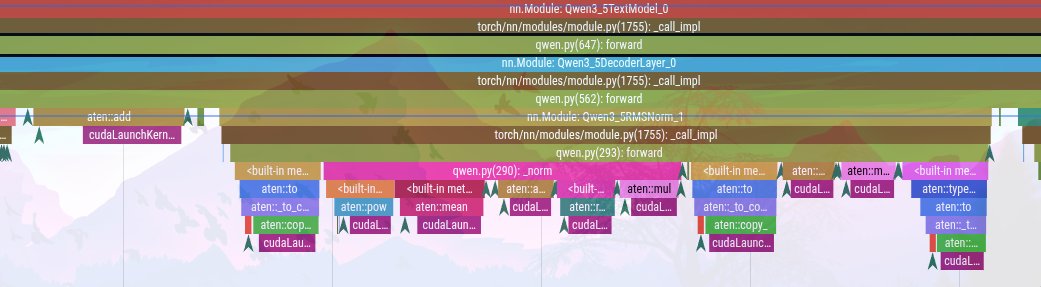
Looking at the initial profiler traces, the compute cores were starving. Standard PyTorch separates residual hidden_states and RMSNorm, forcing the GPU to do multiple round trips to HBM just to execute basic math.
1
53
May 25
Phase 1: I built a custom Triton kernel for Qwen's Zero-Centered RMSNorm and re-architected the HF model to pass the residual stream continuously across layers (vLLM style). That eliminated the memory boundary and netted a 5.7x latency reduction on the norm.
1
81
May 21
crazy work! wonderful writeup!

we recently optimized qwen3.5-397b-a17b to be the fastest deployment publicly hosted.
and the crazy thing: we did it by writing CUSTOM KERNELS for AMD MI355x. 🍿
see our post below outlining how we optimized kernels to achieve SOTA performance.

1
1
307
May 19
Multiverse of Madness
May 19

Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
1
52
May 18
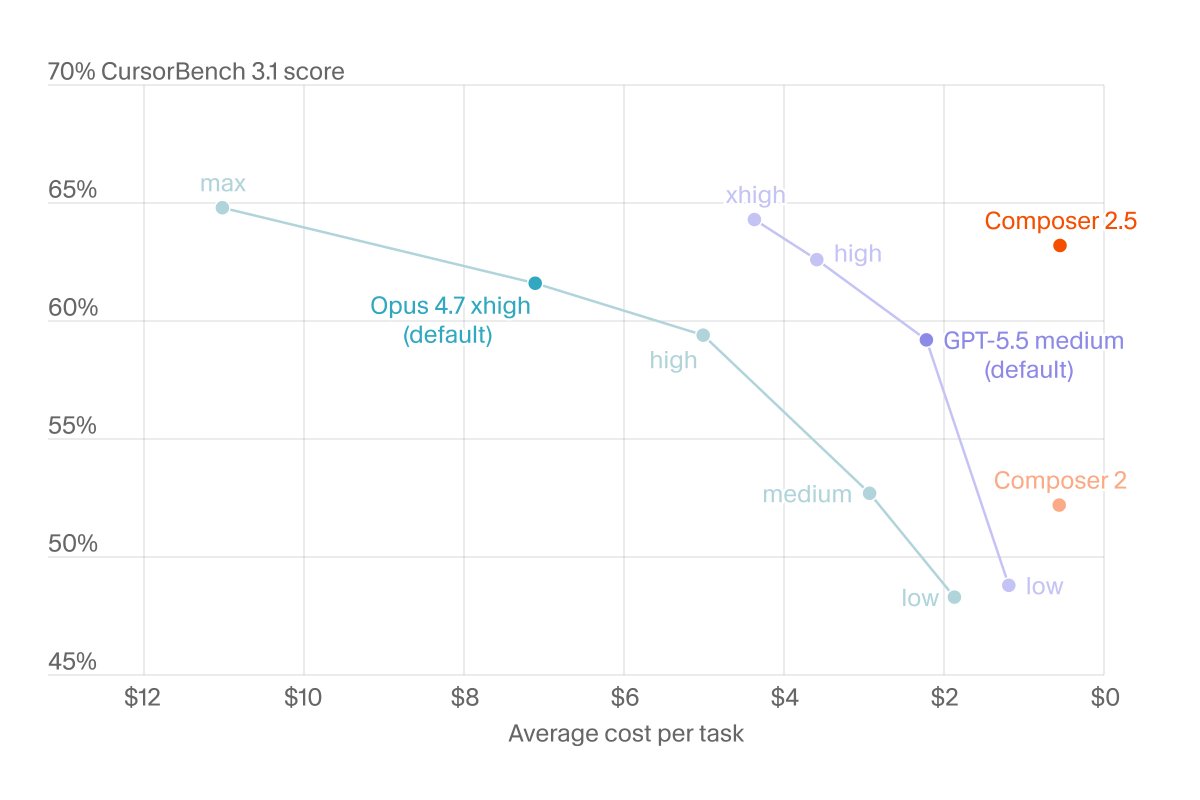
i still don't understand why they use inverted X-axis!!!
May 18

Composer 2.5 is exceptionally intelligent and up to 10x more efficient than similarly capable models.
1
1
56