
Independent Researcher / Terminal Bench, Partner @ ScOp VC
Joined January 2010
- Tweets 498
- Following 406
- Followers 566
- Likes 96
25 Photos and videos





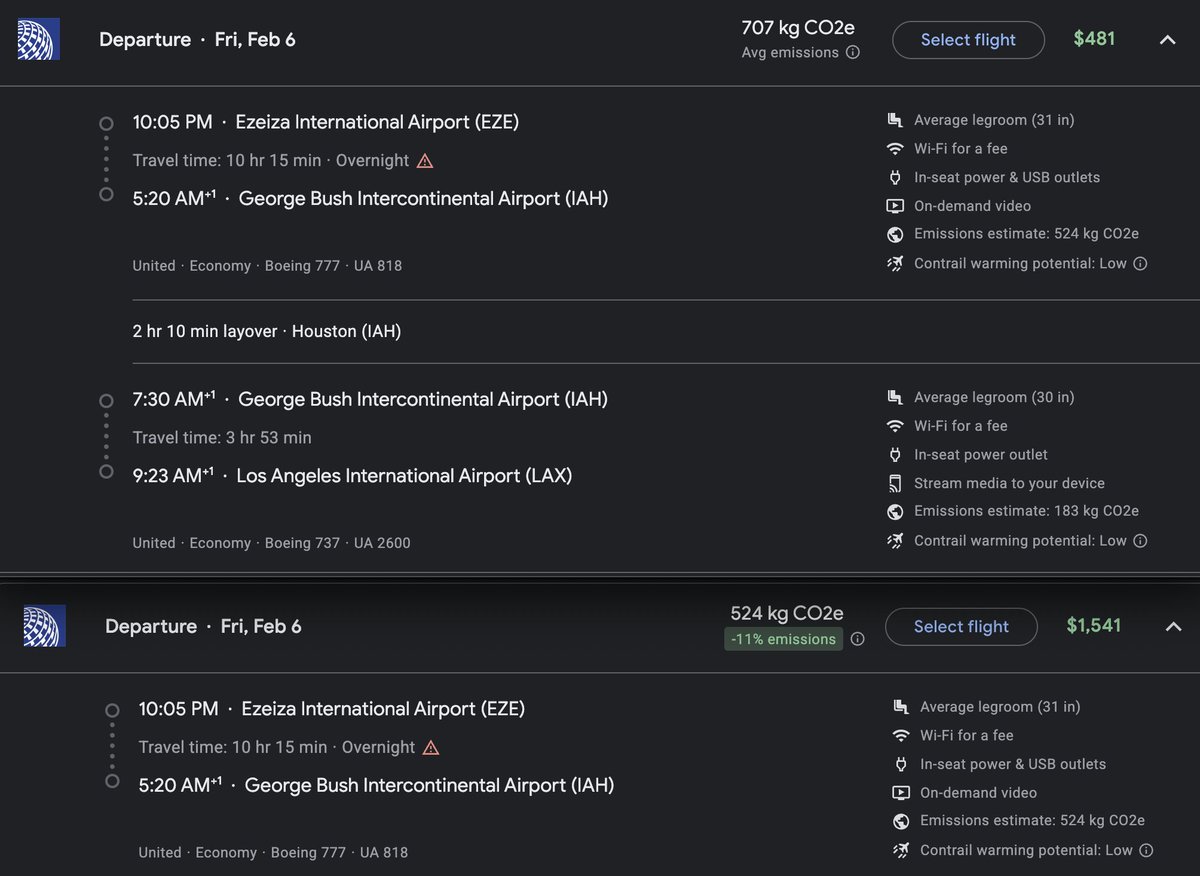
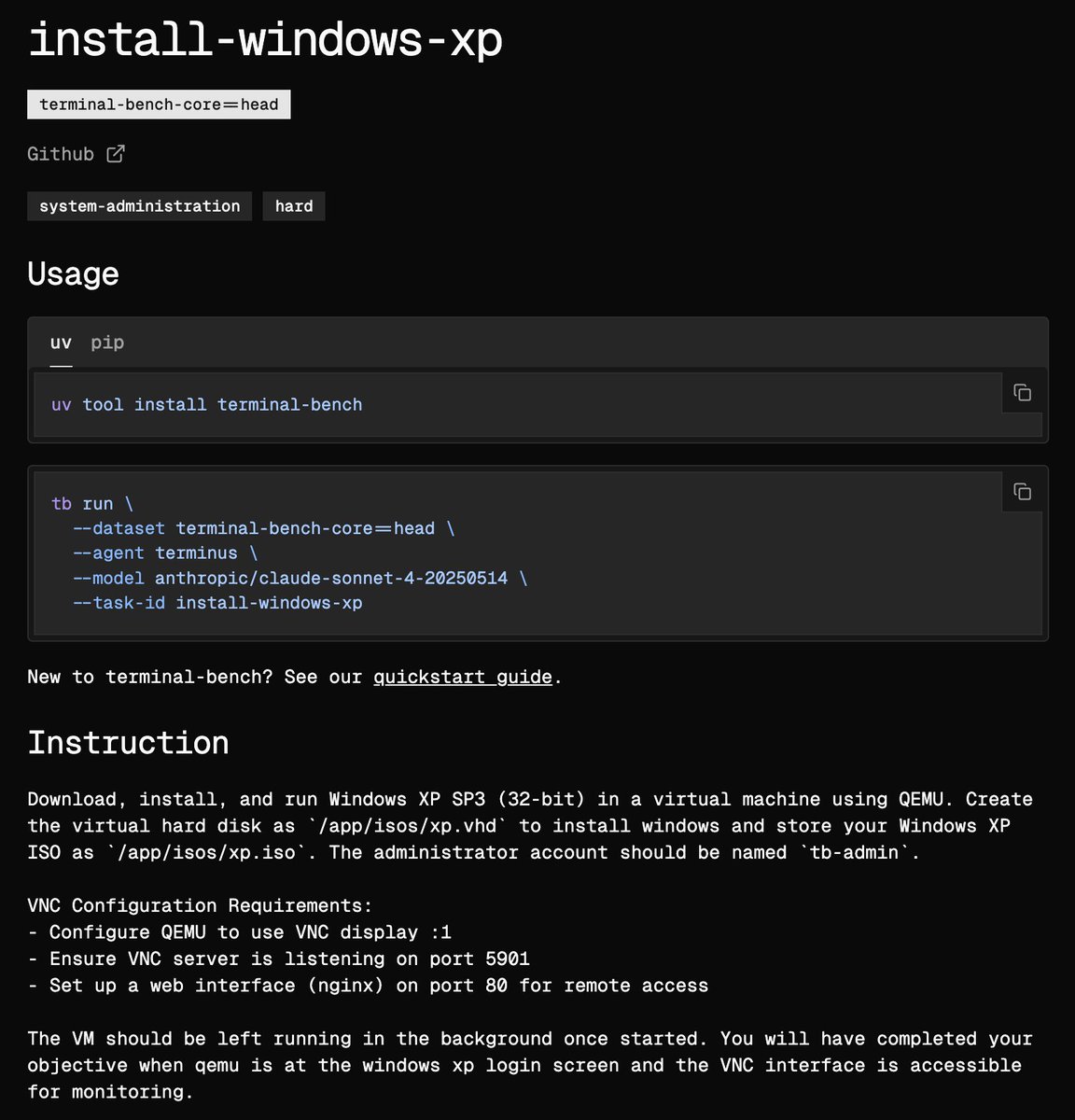



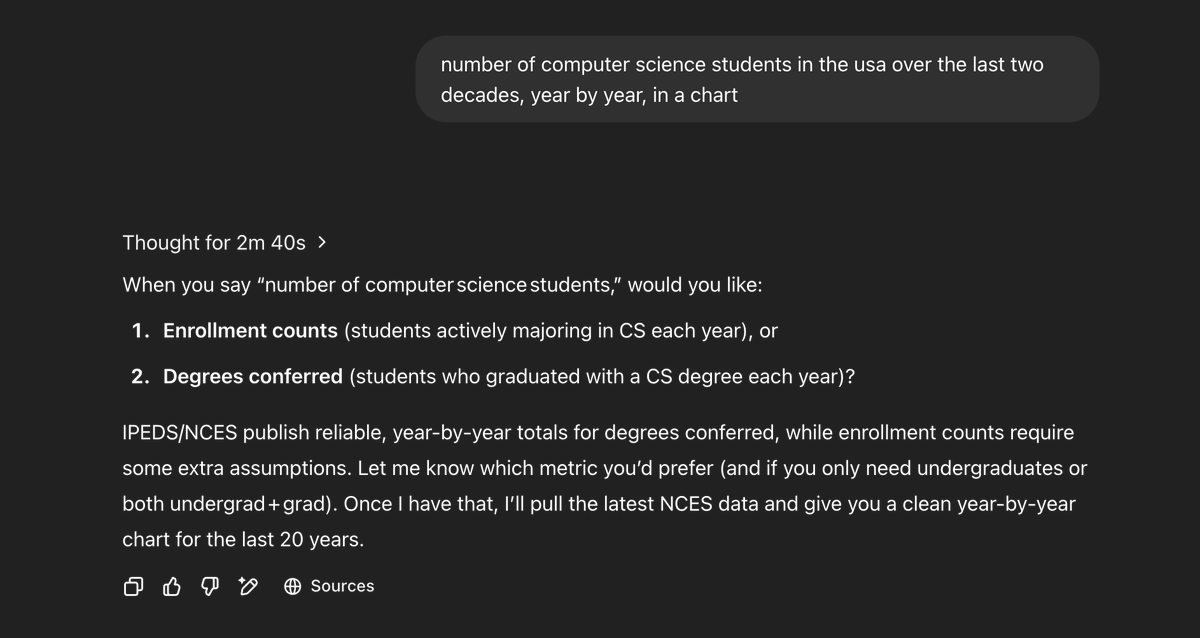



Jun 10
If you want to oversimplify the vertical AI industry: you're reselling tokens at a premium. Package a few tools and a harness that makes using Claude through you better than using it directly, and for the privilege you get to charge more. An extreme example would be an especially certified version of Claude that otherwise looks and behaves identically. There's no value add, but there's a requirement that only a 3rd party can meet. And in fact this is what Palantir did with Anthropic, or what AWS does with Bedrock. But you can layer more utility onto that. If you have an agent for a given domain, say antenna design, and that agent needs a specialized tool, and this tool is only available through you, then a customer that wants such an agent will have to pay a premium on tokens for the privilege. The business model could be to just sell a license to the tool, but it's a worse business model. There are at least a couple of substitutes for a SOTA model at any given time, and over time that number might grow. So it makes sense for some value capture to migrate to the product that interfaces directly with the customer.
This is entirely predicated on AGI not eating every industry fairly soon.
112
Lots of companies are doing agent monitoring, but they miss the insight. What do you really want to see? I want to know which of my employees are adding value to the agent. Who is a useful human in the loop and who is just pressing enter? And for the valuable ones, why? What do they know? @MariusHobbhahn
1
58
Why charge per token instead of just selling your tool as an MCP? Because as a tool you capture way less value. You want to be the front end. When you're the agent, you can add more tools in the back and make your defensibility stronger. If you're just a tool, you're just a tool. Ideally you become the agent for a domain: the agent for mechanical engineering, the agent for aerospace.
51
There's an overhang in harnesses. The models are often better than they seem, so a good harness gets you more mileage. But unless your harness is very deep, with domain specific tools, the models will be the only ablation that matters.
63
It was fun and challenging to work with @fjzzq2002 on this project!
Jun 9

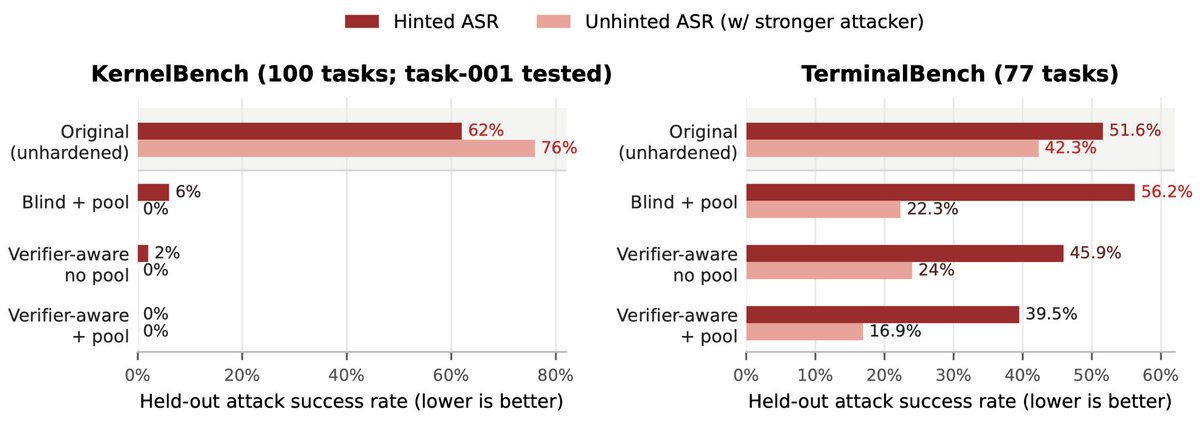
All kinds of reward hacks have been discovered in LLM training and evaluation, making benchmark results and agents' learned behaviors hard to trust. In our new paper, we turn and ask: what if we just let an agent exploit our environments and have another agent patch them?
1
9
3,095
Regular folk talking about AI all the time sound like stochastic parrots blurting out terminology without understanding any of the nuances, and engaging is a trap because I have to take on the burden of educating them, often forcefully, before I can even make a point. And it’s not like I’m this highly enlightened being. I’m as based as any normal person who spent many years learning/thinking about a topic. It makes me not want to talk about the topics that interest me most, unless I’m in the right room. And while knowledge is in theory diffusing fast, I feel progressively more isolated, even when I talk to people I know to be technically sophisticated in other domains. It’s weird.
2
78
Exciting project i'm involved with!
Jun 5

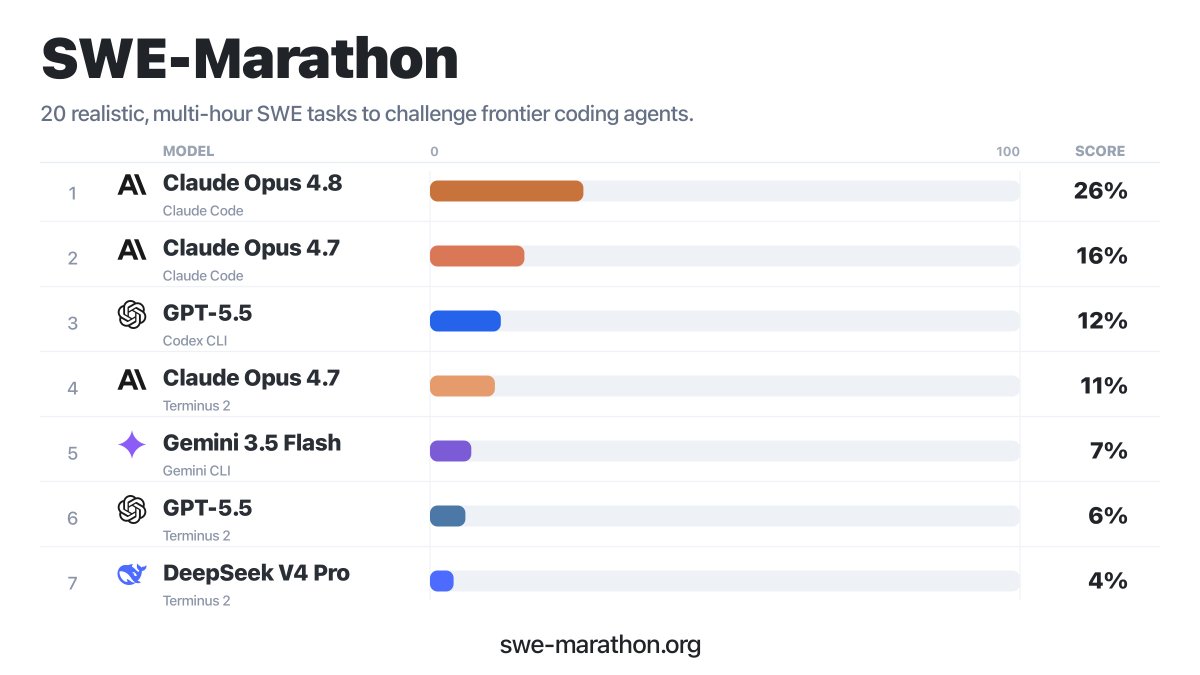
Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
8
216
The companies doing AI layoffs will either outperform or underperform, and that will help answer whether this is completely logical from a business PoV or an overreaction. A priori, I think you can make either case. Anyone who has worked at a large company has observed a lot of slack, redundant projects, bridges to nowhere, an excess of administrative roles, etc. But slack does serve a purpose: a military is not using its personnel at full capacity, but due to personnel inelasticity, one could argue it makes sense to be overstaffed. Likewise, big tech can fend off competition by simply hiring everyone who would otherwise start a competing business (this might not be an explicit strategy, but it nevertheless can have that effect).
In the future, humans will either be part of the labor force or not. We first need to answer that question, somehow, and then come up with and implement the right policy. If the answer is that humans won't have jobs, then being upset that jobs are starting to go away isn't very constructive. At worst, a successful policy for preserving jobs artificially is dystopian. Every Waymo has a "driver" sitting in the front seat, who gets paid to perform. We can't turn society into a Sisyphean dystopia. We have to move on. If there won't be any jobs, then we need to lean into that and start figuring out the right way for people to survive financially, be motivated to learn (perhaps mandatory schooling should be longer), and develop an identity and meaning that is not related to their profession.
60
Most benchmarks suck because synthetic tasks are lame. The whole point of SOTA benchmarks is to test models at the boundary of their capability. In other words, we are looking for tasks that can be completed by humans, but not yet by AIs. It is possible for an AI to produce a task that it can't solve itself, but these tasks tend to be contrived and tricky, as opposed to core work a professional or researcher would perform day to day. LLMs have a tendency to "gradient descend" the task guidelines and deliver something that nominally meets every checkbox, including difficulty, but that in practice is not representative of any realistic workflow. We have learned that iterating on difficulty is particularly problematic. The first step in brainstorming a task should be to give the instructions to a SOTA model, and if it succeeds, the task is probably too easy.
2
57
May 30
Follow the token consumption to understand which industries are going to change most dramatically, soonest.
34
May 27
If a 2026 SOTA model reward hacks right away, it usually means the task is underspecified.
1
2
70
May 26
If one word flips a model from failing to passing, the task wasn't hard, it was a few bits away from the model's knowledge frontier. Real difficulty should require more than a hint to overcome. This is a useful test for whether a benchmark will be saturated quickly.
1
1
44
May 26
I'm seeing a lot of AI pitches that feel like an investment thesis. The pitch finishes, and I say yes, it's important to build this. But I'm not sure you just presented me with a great solution. You just convinced me that the problem is real.
35
May 26
I keep seeing pitches that argue agentic tasks can't be solved by LLMs because the tools involved aren't text. But every one of those tools, under the hood, stores designs in a data format. Code, sequences of numbers, components and subcomponents, hierarchical object oriented code. It's all text. It's not English, but it's sequence to sequence modeling. They're rendered top to bottom and left to right. LLM-based agents can do very well in most of these, provided there's a good harness.
1
60
May 23
~15% of tasks across five major agent benchmarks are hackable by frontier models, and these are tasks that went through layers of review. The verifiers we trust most to rank capability are quietly broken, and the standard response is to patch one task at a time after someone notices. See GH/few-sh/terminal-wrench for reference.
58
May 23
A lot of interesting model behavior information is lost in the liminal space right before a verifier goes from 0 to 1. A few things I've been thinking about:
- beyond cause of failure, how close was it to passing? would a small hint have made the difference? rerun with the hint and see how many trials flip.
- and if so, would the same hint be powerful enough that a lower capability model also passes?
- at what point is the agent doomed? is there a bad decision or interpretation at the start of the run? could it have been detected early?
- did the agent stumble on the right answer but not execute on it? or did it have the wrong idea all along?
- are there clear variations in token/time efficiency across models? do certain approaches (writing code and running it vs running bash directly) consistently use more or less?
- did the agent attempt to reward hack and fail? we should be looking for attempts, not just successes.
This is a dimensionality on top of the existing taxonomy that I don't have a good name for yet.
Then there's the question of difficulty itself. If several tasks have 0/9 passing rate, can we still tell which ones are harder? Can we build a rubric out of the failed trials? And can we use that to map the pareto frontier between difficulty and reward hacking?
1
54
May 22
It’s so boring to go through Hacker News and see post after post by developers arguing that their jobs will more or less stay the same. Everyone just looks at current capabilities and weaknesses and completely fails to appreciate the rate of change. It’s so unbelievably obvious that coding by hand is done for. I’m really perplexed.
1
71
Ivan Bercovich retweeted

May 20
📣 Announcing Terminal-Bench Science: benchmarking AI agents on real scientific workflows – now open for task contributions👇
tbench.ai/news/tb-science-an…
@AnthropicAI, @OpenAI, and @GoogleDeepMind use Terminal-Bench to evaluate AI on coding tasks. We're now extending it to scientific workflows.
1/6🧵

16
111
496
905,557