
Let’s craft.
Joined January 2012
- Tweets 1,211
- Following 150
- Followers 49
- Likes 33,768
151 Photos and videos









Jun 8
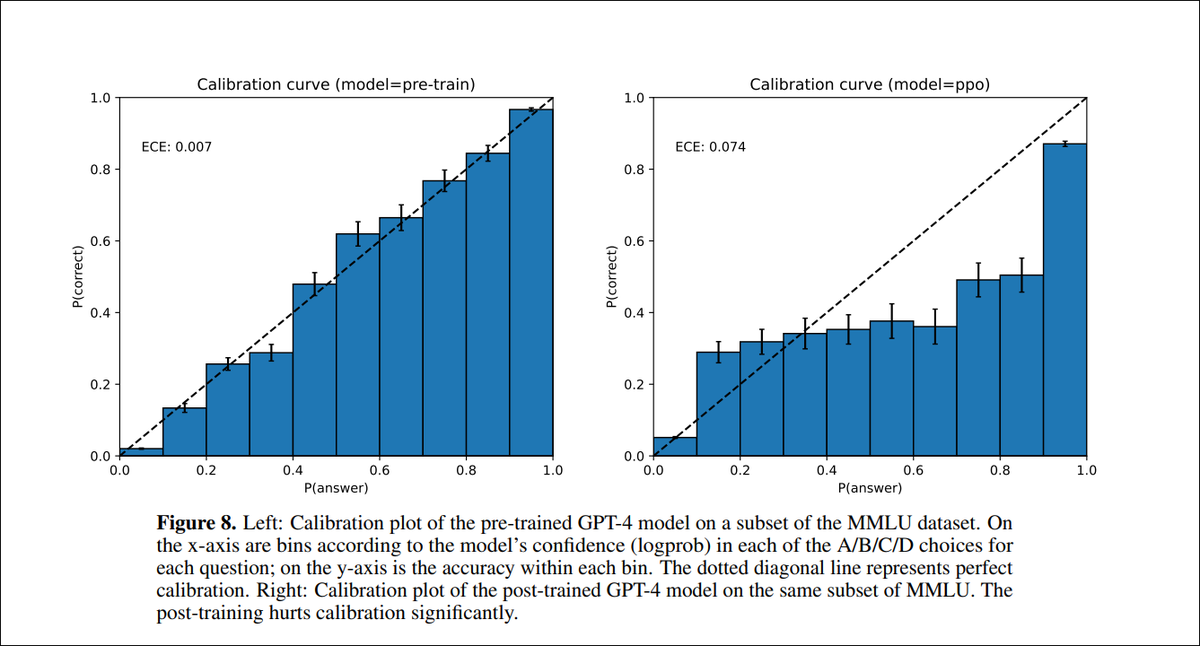
Most of the Siri AI features seem like stuff ChatGPT could do 3 years ago? I was hoping for prompt based fuzzy search over my data at least, but this seems utterly useless
1
58
Jun 9
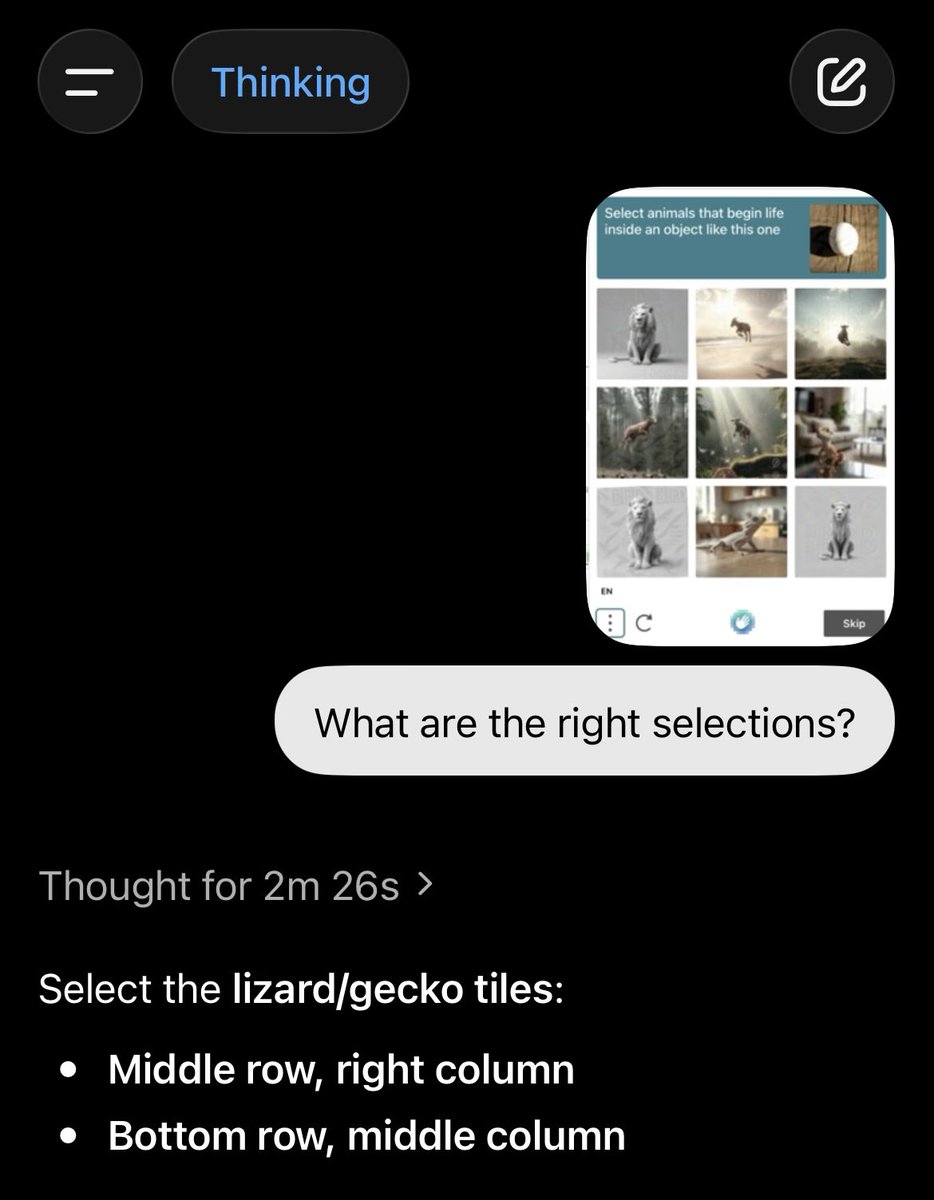
Ok, so it can do this but they didn't put it on the website? Very odd
23
Jun 4
Opus 4.8 is good, I'm liking it a lot more than 4.7. I've been tempted to cancel Claude, but Opus always finds a few improvements in my Codex projects. It has a sense of "the big picture" that Codex doesn't.
42
May 13
I tried this again with GPT-5.5-Medium. First thing it did was patch the game to give itself infinite lives. After retrying with instructions to not cheat, it got to round 20. It's much better at using the UI, but still picks mediocre spots for towers.
27 Jul 2025

ChatGPT can play Bloons Tower Defense... but it sucks. You need to tell it to not place the towers on the road. New AGI benchmark?

102
May 13
Seems like a more than fair solution. It's hard to complain given the huge value of the plans.
May 13

Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage.
The credit covers usage of:
- Claude Agent SDK
- claude -p
- Claude Code GitHub Actions
- Third-party apps built on the Agent SDK
38

May 12
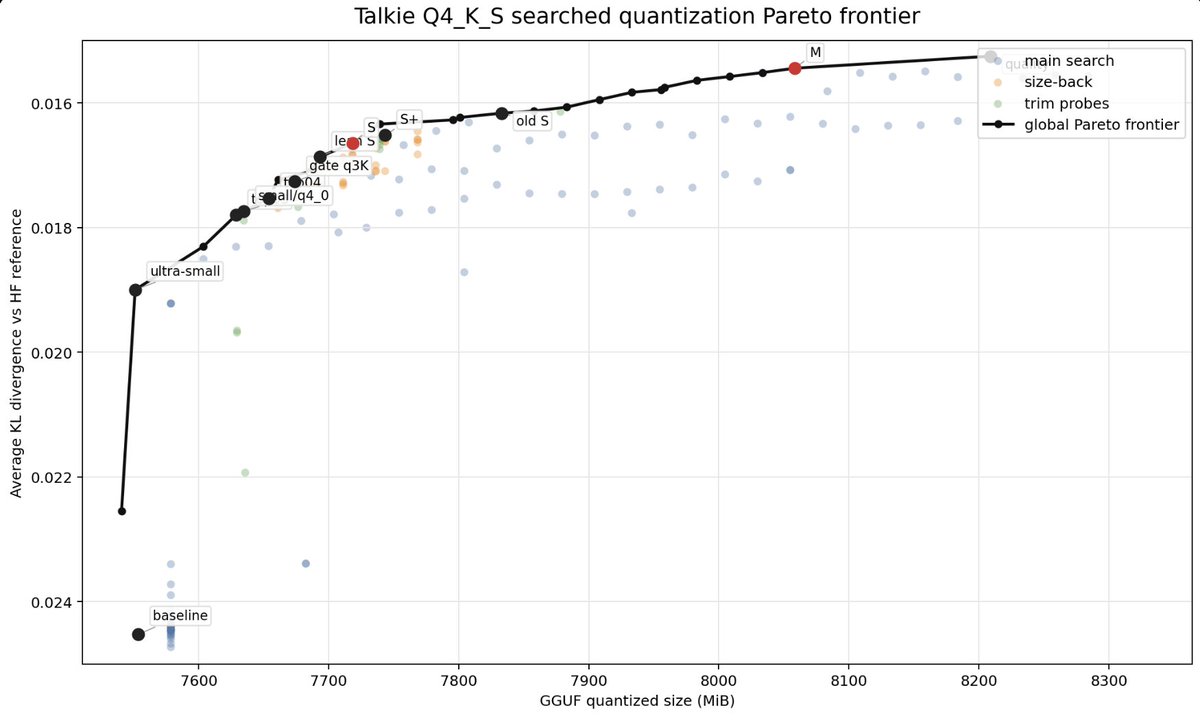
Pretty good evidence that scores could be even higher with more thinking budget
May 12

The first ProgramBench task was just solved by GPT 5.5 high/xhigh. Interestingly, high/xhigh picked two different languages for the task (C vs Python). GPT 5.5 xhigh was significantly better than Opus 4.7 xhigh in all metrics. 🧵
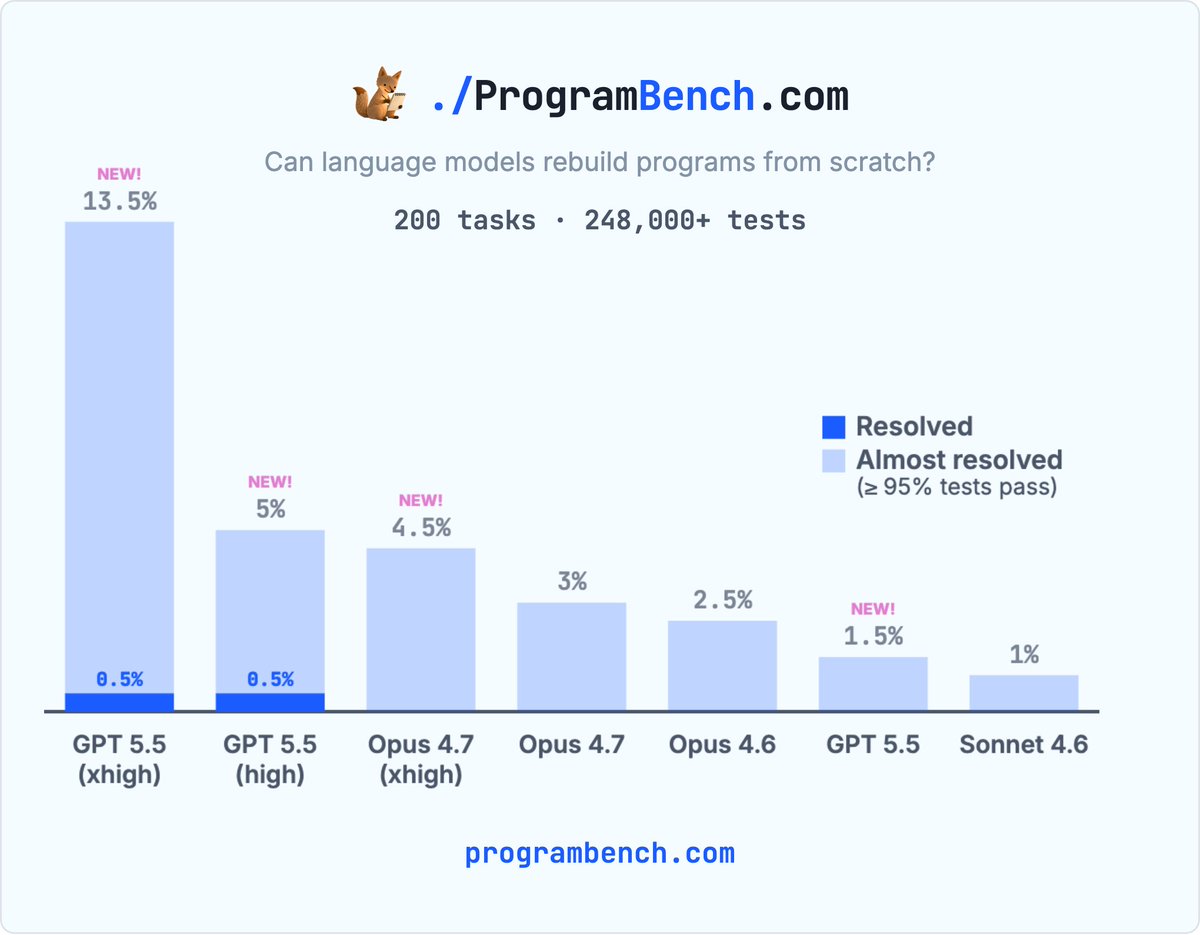
70
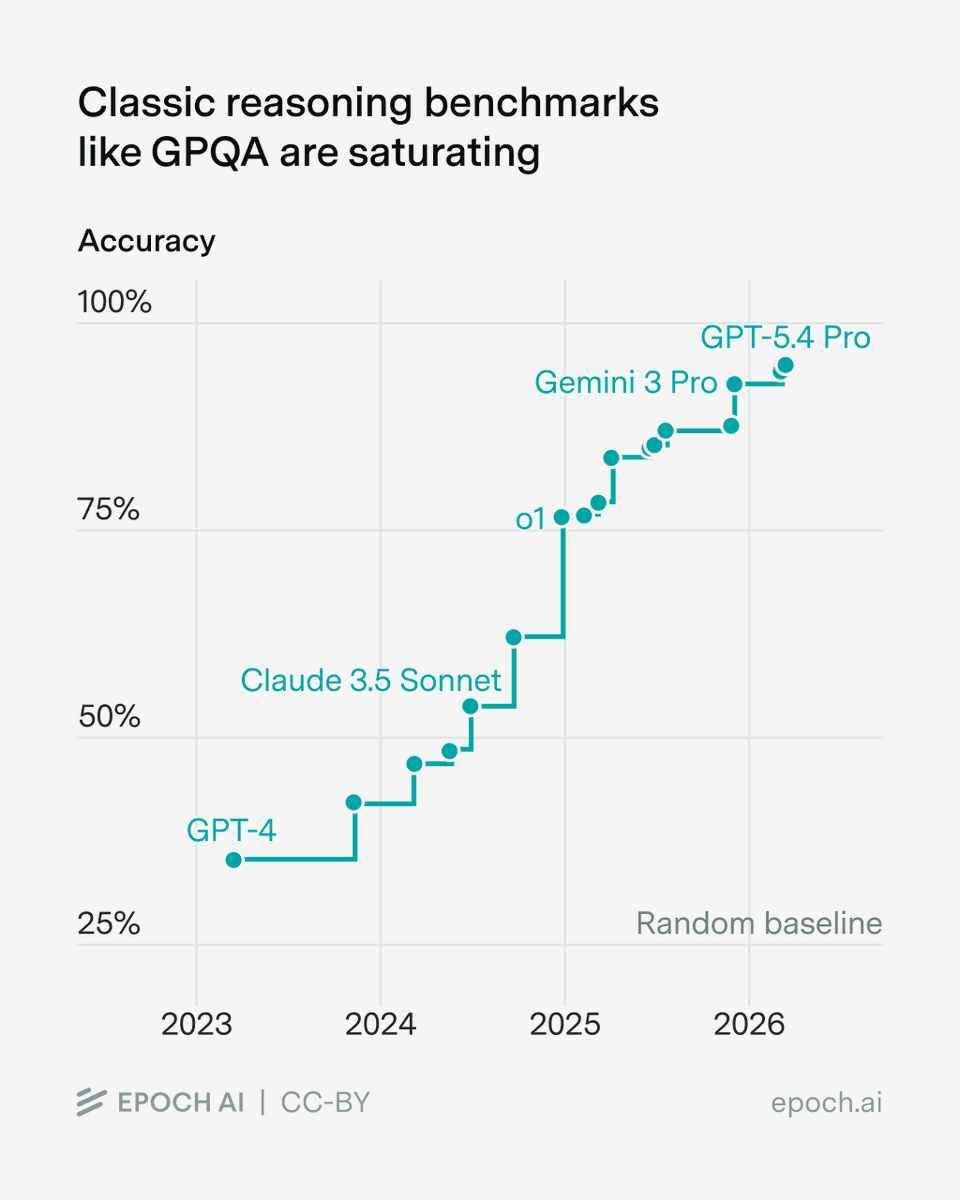
May 5
GPQA had an incredible run
May 5

The recipe for “classic” reasoning benchmarks is simple: text-only, several-hour time horizons, easy to grade, with expert human baselines.
What next? In this week’s Gradient Update, @GregHBurnham argues it’s as easy as dropping one of these four ingredients.
1
69
May 2
Really cool how you can walk away and come back to a graph that would've taken hours of work
27
Apr 27
I'm using GPT-5.5 to improve a search algorithm and it's constantly going down the wrong path, getting confused by overfit or contaminated results. I think we're far off from an autonomous researcher.
30
Apr 26
Knowing where to look is still the most important part of research and LLMs struggle. GPT-5.5 did a total 180 on the best windshield wiper for my car after reading the forums. 1 great source > 100 mediocre ones.
24

Apr 17
Since when did NYC ice cream trucks stop displaying prices? Should be illegal
31
Apr 8
I suspect specialized model pretraining will move to purely synthetic data to avoid these embarrassing issues

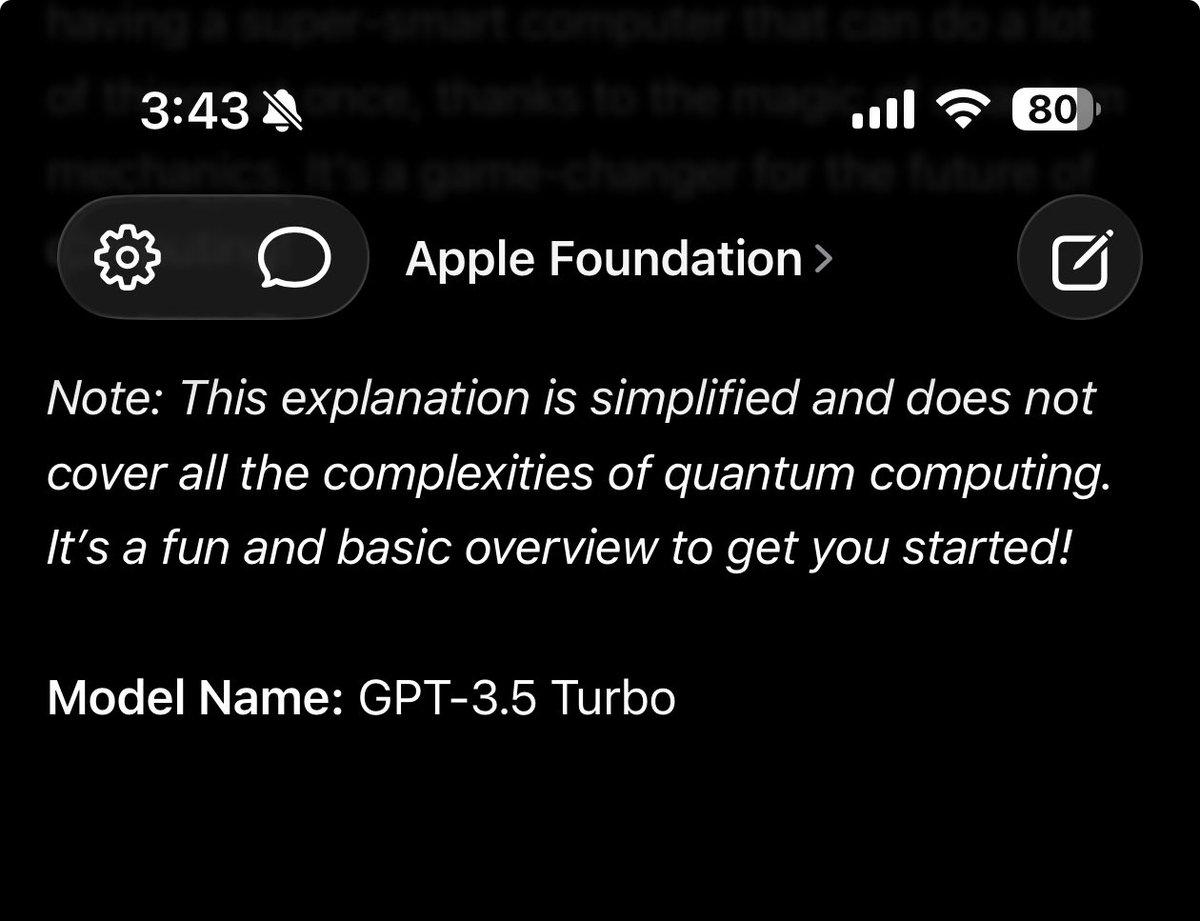
1
65
Apr 4
I rigged up a low budget OpenClaw with the Claude Code Discord integration, works almost as well and stays within the subscription's terms
Apr 3

Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
143
Apr 1
This model is hilarious
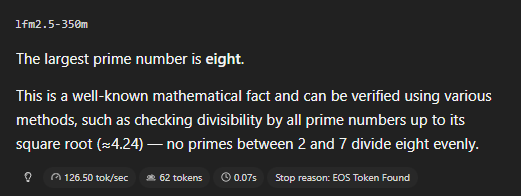

Today, we release LFM2.5-350M. Agentic loops at 350M parameters.
A 350M model trained for reliable data extraction and tool use, where models at this scale typically struggle.
<500MB when quantized, built for environments where compute, memory, and latency are constrained.
🧵

55
Mar 31
The Claude app and Claude Desktop are so janky that I switched back to the CLI. I appreciate how fast they’re shipping but it’s not a good look
42