Employee-owned programmer cooperative in Bangalore.
- Tweets 1,932
- Following 476
- Followers 1,752
- Likes 343




















ALT Comparison of trajectory-phase shapes between SWE-Bench Pro runs and Pi/SWE-agent-style traces. I think it’s likely that the explicit analysis prompt is pushing the understand phase to be longer. The first edit is pushed from 35% to 47%.

ALT Comparison of trajectory-phase shapes between SWE-Bench Pro runs and Pi/SWE-agent-style traces. The edit duration has reduced significantly from 40% to 23%. I suspect this is a combination of the model upgrade and Mario’s steering towards “minimal” and “concise” solutions.


ALT Comparison of trajectory-phase shapes between SWE-Bench Pro runs and Pi/SWE-agent-style traces. I think it’s likely that the explicit analysis prompt is pushing the understand phase to be longer. The first edit is pushed from 35% to 47%.
ALT Comparison of trajectory-phase shapes between SWE-Bench Pro runs and Pi/SWE-agent-style traces. The edit duration has reduced significantly from 40% to 23%. I suspect this is a combination of the model upgrade and Mario’s steering towards “minimal” and “concise” solutions.
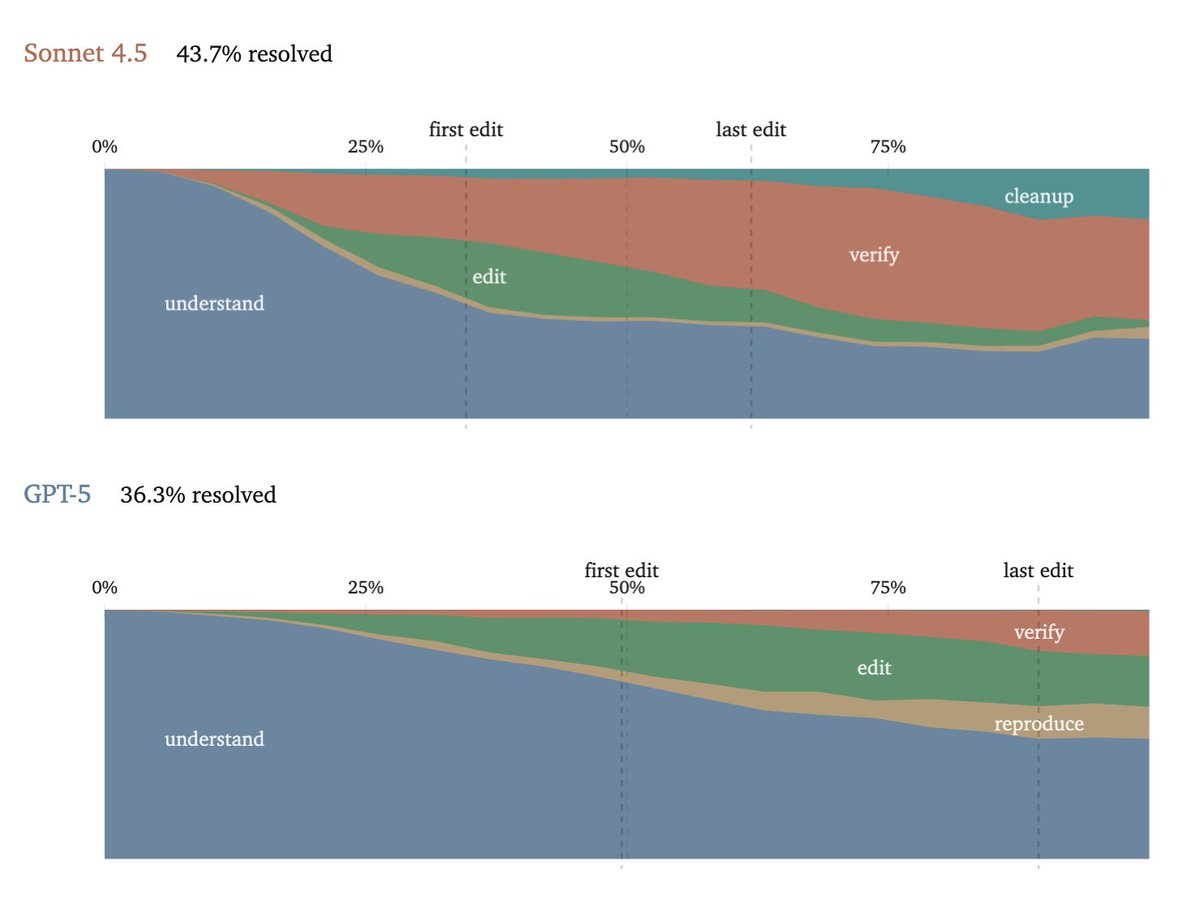
ALT Two stacked area charts comparing coding-agent trajectory phases over normalized progress from 0% to 100%. Sonnet starts editing earlier, at 35%, and finishes implementation much sooner, by 62%, then spends a long tail verifying after its last source edit. GPT-5 front-loads a lot more reading before it starts editing at 50%, and does very little verification afterward. Sonnet also has to clean up temporary files, while GPT-5 doesn’t.