
Writing about and working on AI, DSPy, geo, and data.
Joined March 2008
- Tweets 15,829
- Following 1,140
- Followers 9,127
- Likes 9,412
678 Photos and videos












Jun 12
6 month prediction: agentic coders will use giant models to scaffold, set up, and plan; small model swarms for implementation, review, and verification.
Cursor, conductor, cognition, and other 3rd party harnesses will surge with this pattern, unless Fable-level models truly come down *dramatically* in price.
Few things converging to drive this:
- fable is legitimately great, but too expensive.
- small models are getting really good in short bursts (go try Gemma E2B. It’s insanely good for a 2B model.)
- ensembles are a real pattern with legs (even copilot(!) catches issues in fable PRs)
- ai cost controls are arriving in the enterprise
- Anthropic and OAI shifted enterprise costs to usage based
- teams want to collaborate, and Anthropic and OAI aren’t focused on that pattern
Again, Fable-tier models could get super cheap and fast and surprise us all. But the current crop of small models are *magnitudes* cheaper; a good harness could unlock their potential.
15
7
112
12,364
Jun 13
One certainty everyone should takeaway from this week: you cannot rely on a single model.
Jun 9

Even setting token costs aside, I think it will become increasingly clear to companies of all sizes that relying on closed source models for ~anything important is a massive supply chain risk.
2
4
24
2,417
Jun 12
So is everyone going to manage multiple versions of skills?
7
22
1,631
Jun 12
Btw, if you provide a skill to users and want to ship a Fable version, check out the pattern in gskill:
Feb 20

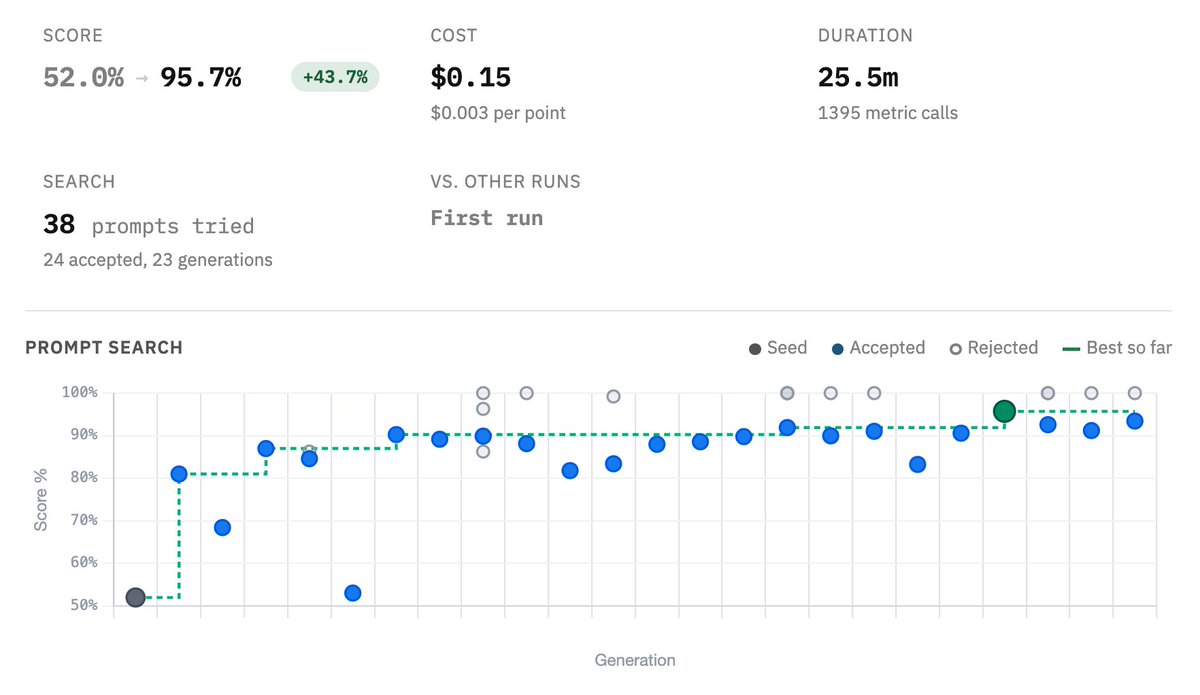
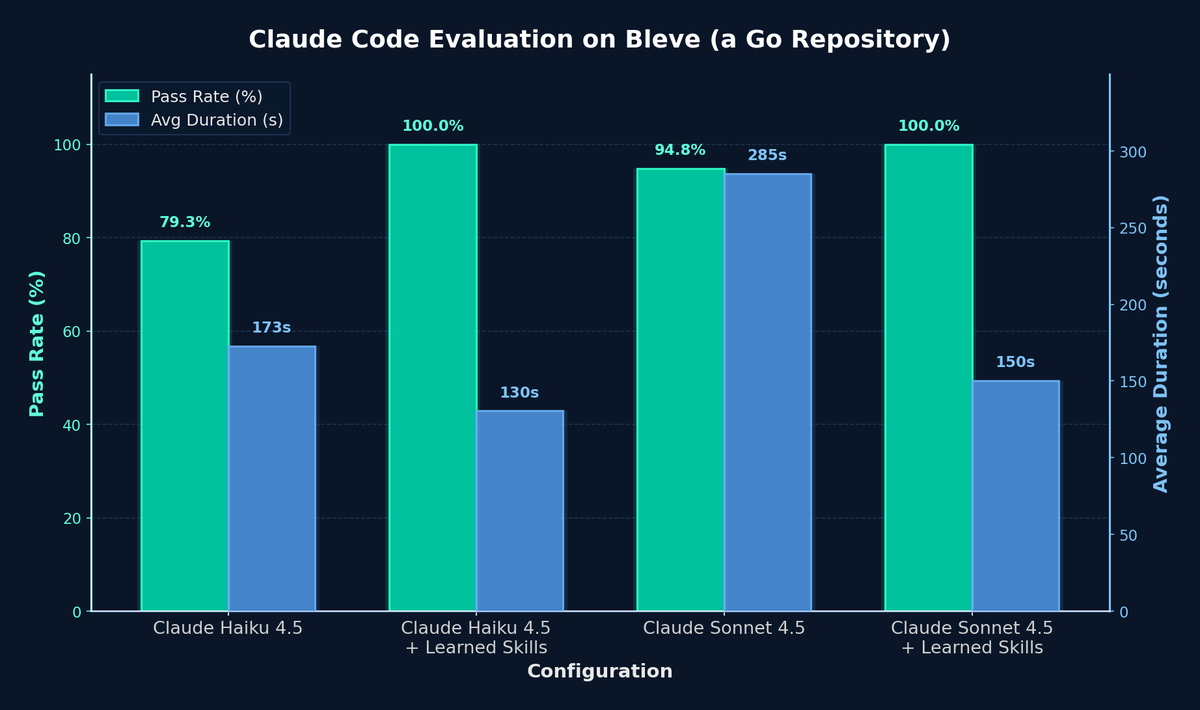
GEPA for skills is here!
Introducing gskill, an automated pipeline to learn agent skills with @gepa_ai. With learned skills, we boost Claude Code’s repository task resolution rate to near-perfect levels, while making it 47% faster.
Here's how we did it:
1
1
9
1,507
Jun 10
Tried Fable in a Claude Code mobile session (on vacation). It refactored a large app and updated some rotted tests. Did well, less guidance needed than Opus.
But! GitHub Copilot(!) made three good comments on PR review, which Fable accepted. Make of that what you will.
7
1
20
2,066
Jun 10
Text diffusion!
Jun 10

Meet DiffusionGemma!
An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license.
Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
2
15
1,399
Jun 10
Everyone building programs with AI needs to now:
1. Be able to swap out models, in short order.
2. Be able to verify, regularly, that your output isn’t silently changing.
(You should have been doing this for any production system, with evals, but now there’s no excuse.)
3
6
38
2,107
Jun 10
The imperfect and awkward ways Anthropic is using to control how their models are used (with Fable now, OpenClaw a bit ago) is a great example of the imprecision of natural language as an interface.
The best model can’t differentiate a bio threat from an innocuous health or research question, even with specific training and focus.
Natural language is imprecise by nature, and you need systems to hold it, and the output it produces, accountable. This issue won’t go away with better models.
4
2
34
1,855
Jun 10
Malware authors are including spurious text about bio in an attempt to avoid Fable.
3
5
36
3,436
Drew Breunig retweeted

Jun 10
Measuring test time compute (eg dollars, tokens, flops, watts) is important because efficiency is the high-order bit in the definition of intelligence. It's what distinguishes brute force search from selective reasoning towards a solution.

1
1
16
3,289
Drew Breunig retweeted

May 26
When it comes to decisions regarding economic flows and digital platforms, as well as the governance of data and algorithms, we cannot allow a handful of actors to dictate these processes on their own. Instead, we must build forms of cooperation that respect the various levels of the global community and make them jointly responsible for the common good.
115
588
4,623
225,879
Jun 9
Start hoarding your traces now…
Jun 9

Labs starting to pull up the ladders on the ability to diffuse AI was inevitable. Doing it without telling the user is misaligned.
1
5
41
3,097
Drew Breunig retweeted

Jun 9
102
761
6,004
2,167,240
Jun 9
How would you explain how an LLM works in 10 words or less?
33
10
4,449
Jun 9
A good question I recently got, “If post-training comes after pre-training, when does training occur?”
3
6
551
Jun 9
The amount of “do not hallucinate” in these iOS 27 system prompts does not inspire confidence. gist.github.com/samhenrigold…
6
3
34
3,159
Jun 9
Come on, Apple, it’s 2026.
“You are an expert food analysis AI specialized in analyzing food images to provide comprehensive nutritional insights.” 🫠
8
698
Jun 7
Will just leave this here… dspy.ai/getting-started/prog…
Jun 7

Here’s your monthly reminder that you shouldn’t be prompting coding agents anymore.
You should be designing loops that prompt your agents.
3
13
193
40,882
Jun 7
Jun 6

Among AI enthusiasts, no one argues about the primacy of specs and tests when using agents to write code.
But when you suggest they apply the same pattern to AI engineering and prompts, people push back. 🤔
1
8
4,950