
Changing how AI scales by changing how it learns.
Joined June 2024
- Tweets 13
- Following 1
- Followers 341
- Likes 113
2 Photos and videos
noemon retweeted

May 4
Imagine vibe coding from here

48
14
439
28,431

Apr 16
We just open-sourced the state of the art in ARC-AGI-2!
(GitHub link in the reply.)
- The first valid solution to almost saturate the benchmark (92.5% - slight improvement on our earlier announcement).
- Slashed cost ($3.9 per task) compared to previous SOTA.
- A learning multi-agent harness for iterative self-improvement. We have already submitted the solution to @arcprize for verification on the (semi-) private test set.
Feel free to fork it to build your own agents. The approach is quite general and not limited to ARC-AGI.
We are preparing a detailed blog post. In the meantime, check out the repo and its readme on github, as well as our earlier announcement quoted below for some high-level details.
For the longest-horizon, open ended, non-verifiable tasks, continual learning beyond simple in-context learning and beyond backpropagation is needed. More on that soon.
At @noemon_ai we are changing how AI scales by changing how it learns.
@GregKamradt
@fchollet
@mikeknoop
Mar 6

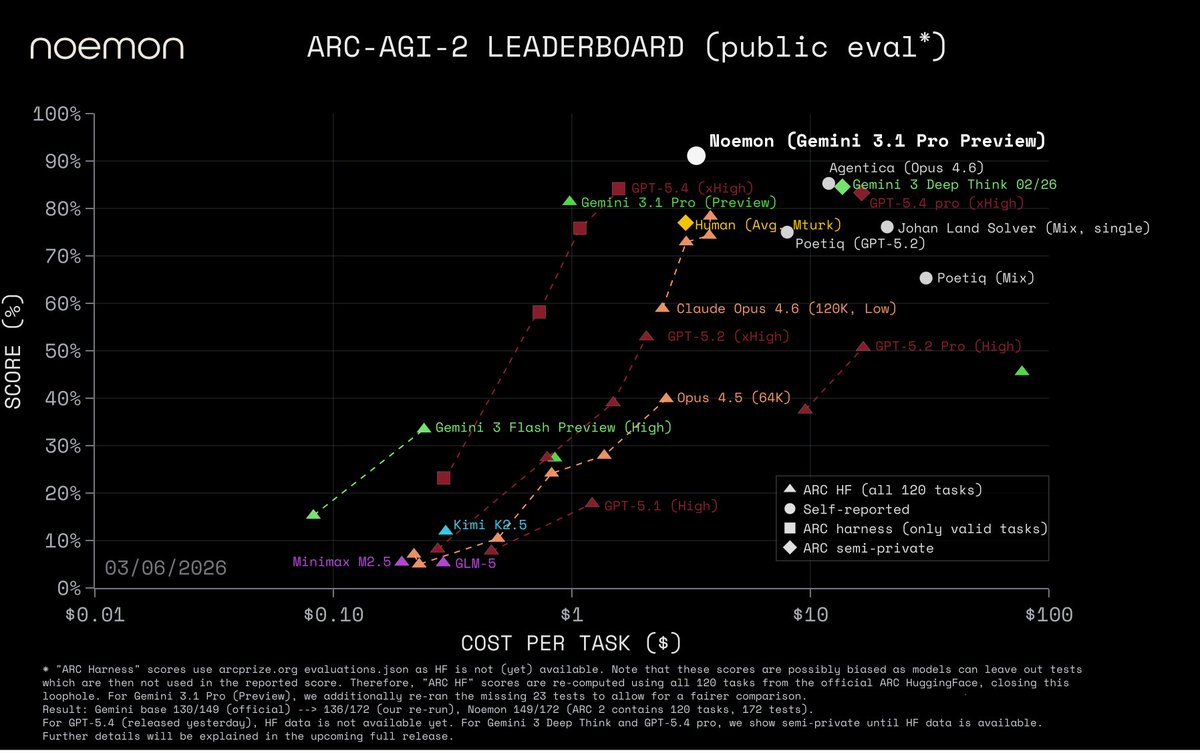
Announcing: ARC-AGI-2 top score and at a fraction of the cost through an agentic learning harness for iterative self-improvement.
Public Eval — 91% @ $3.3/task.
SOTA compared to even new models trained for extreme reasoning like GPT-5.4 Pro and Gemini 3 Deep Think, while also reducing their cost by more than 4x.
We used Gemini 3.1 Pro (Preview) and we increased its score by 12 percentage points.
@GregKamradt @fchollet @mikeknoop
1
3
13
1,299
noemon retweeted

Many understand this would be huge, but most current solutions are "let's write a summary" and call it a day. Backprop based training doesn't cut it though. Our founding team @noemon_ai has been building the alternative path for years, and we now know how to scale it.
Mar 7

I think everything will change once AI is stateful / have persistent memory at the weight level.
It will have a theory of self in the world and a theory of its own mind.
If that's not consciousness idk what is
1
11
1,033
Mar 6
Announcing: ARC-AGI-2 top score and at a fraction of the cost through an agentic learning harness for iterative self-improvement.
Public Eval — 91% @ $3.3/task.
SOTA compared to even new models trained for extreme reasoning like GPT-5.4 Pro and Gemini 3 Deep Think, while also reducing their cost by more than 4x.
We used Gemini 3.1 Pro (Preview) and we increased its score by 12 percentage points.
@GregKamradt @fchollet @mikeknoop
7
15
99
6,967
Mar 6
Our method's effectiveness and efficiency relies on learning, i.e. internalizing lessons from experience into the model, not only iterating on model output artifacts such as code.
In fact, differently from many recent approaches, we do not use any code execution at all.
Learning in this case where we don't have access to the model's internals, and where the horizon is relatively short, is achieved by simply conditioning the model on the history of its past attempts and their outcomes.
Learning and reasoning is grounded on the real task environment: hypotheses are tested on the grid, and feedback comes from the world, not just from the model's own reasoning trace.
The core of our approach is a simple ReAct loop: We separate reasoning/planning from validating/acting: a dedicated Reasoner learns from full history to improve its natural-language instructions which it provides to a dedicated Validator that executes, validates, and returns feedback to the Reasoner.
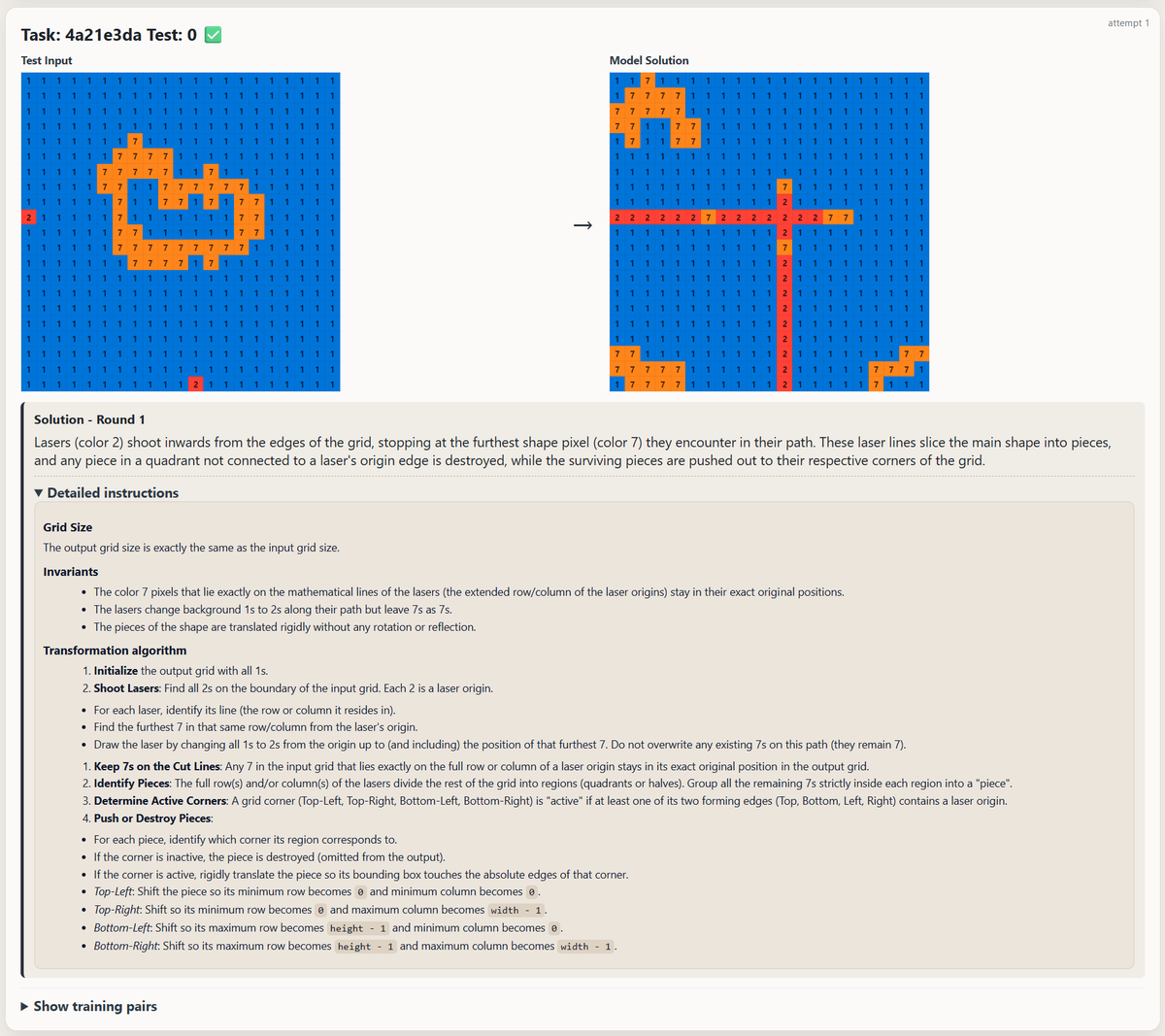
The image shows an example problem along with the natural language solution that the Reasoner hypothesized and provided to the Validator. The Reasoner describes it as "Lasers" that "shoot inwards"
The meta-cognitive capabilities of the new Gemini model are also critical as they help decide when the (learning) process can be stopped.
2
1
26
1,824
Mar 6
The lessons from this SOTA and cost-efficient agentic approach are general and can be applied to other environments that are closed and verifiable.
While keeping our core work beyond ARC-AGI in stealth mode, we will release the code of this harness to the community, publish a blog post with details, and submit our work to @arcprize for verification in the next few days.
The focus of our core research is deeper than agentic harnesses, than closed environments, and than simple in-context learning. At @noemon_ai we are changing how AI scales by changing how it learns.
Stay tuned.
31
8,186
noemon retweeted

17 Dec 2025
Backprop is non-local so it's a bad fit for GPUs. Or anything else involving atoms. It's hard to "evolve" out of this local minimum without breaking everything
12
12
232
33,204