
Joined January 2009
- Tweets 2,192
- Following 1,958
- Followers 1,419
- Likes 4,385
205 Photos and videos









Switzerland not affected 🇨🇭
May 24

There are now 3 additional popups for EU users who signup for X.
30% of my time is now spent on EU compliance.
3
188
Timoleon (Timos) Moraitis retweeted

May 24
if u actually believe this u probably don't deserve that level of compute due to lack of both creativity and ambition
May 24

If you want to work on pretraining-for-AGI, join OpenAI, Google, Meta or the Anthropic/XAI/Cursor supergroup.
The bitter truth of the widening compute gap is that all the problems which are actually on the critical path to AGI now demand that level of compute.
3
4
71
8,384
Timoleon (Timos) Moraitis retweeted

May 18
Ionized workers are too easy to control though magnetic fields, that's why Marxists are in favor of unionization
1
5
264
You might as well just say it's turtles. Turtles all the way down.
May 13

Physicist Michio Kaku suggests dark matter isn’t matter at all. It is gravity leaking from a parallel dimension.

1
5
1,588
"100x data efficiency" is not at all fair assessment, it's max 2.5%.
Training on a specific subset of the nemotron data, evaluated only on tasks that are related to that subset, can't be compared with Qwen etc that were trained on much broader data distributions.
The nanoGPT speedrun baseline is apples-to-apples and is nowhere near 100x. It's 1-2.5%.
May 8

Introducing Aurora, a new optimizer for training frontier-scale models.
We train Aurora-1.1B, which achieves 100x data efficiency on open-source internet data. Despite having 25% fewer parameters, 2 orders of magnitude fewer training tokens, and using fully open-source internet-only data, Aurora matches Qwen3-1.7B on several benchmarks.
Aurora was developed after identifying a major failure mode that can occur under Muon, an increasingly popular optimizer that has shown strong gains over Adam(W). We find that Muon can cause a huge percentage of neurons to effectively die early in training, reducing effective network capacity so that many parameters no longer meaningfully contribute to network outputs.
By redistributing update energy more uniformly across neurons while preserving Muon’s stability properties, Aurora prevents neuron death and recovers substantial model capacity.
What makes this work especially exciting is that it points toward a broader direction for ML research: better optimizers may not come purely from elegant mathematical abstractions, but from understanding and addressing the concrete dynamics and pathologies that emerge inside real training systems.
4
312
Imagine having to imagine
🇨🇭
May 4

Imagine vibe coding from here
4
134
Timoleon (Timos) Moraitis retweeted

Apr 26
wait nobody is actually doing agentic memory?
its all slop md files?

100
8
305
21,585
The memory wall and von Neumann bottleneck beatings will continue until local learning algorithms collocate memory, processing, and learning.

Dylan on why memory prices will double again:
"Memory can only grow capacity low double digit percentages a year. 20-30% a year, even less for NAND, a little bit higher for DRAM, but whatever.
Even though the demand signal was very strong at the end of 2025, the memory companies immediately started reacting.
None of that incremental capacity really gets here until 2028, even if they wanted to build as fast as possible.
So the result is memory prices have gone through the roof.
They're going to double and triple again. DRAM, especially.
People are like, "oh, the memory story is overplayed." No, you don't get it. DRAM will double or triple from here still, because that's how much capacity is required.
And they have to steal capacity from somewhere else. And the only way to steal capacity from somewhere else in a capitalist economy is demand destruction via higher pricing."
1
11
558
Timoleon (Timos) Moraitis retweeted

Apr 23
Actually, AI already saves lives.
In several countries, mammograms are examined by AI and radiologists. Reliability is improved.
In the EU, every car sold must be equipped with Automatic Emergency Braking Systems. That's AI. They reduce frontal collisions by 40%.
Modern MRI machines are equipped with AI technology that reduces the time of imaging by 4x or more. You can now get a full-body MRI in 40 minutes for about $1000. Reduced time -> reduced cost -> more/earlier detection.
And that's not counting the progress in medicine enabled by modern AI, including Nobel Prize-winning protein structure prediction.
44
160
1,703
114,736
- Developed by Sony here in Zurich 🇨🇭
- Uses the event-based vision sensor (aka silicon retina) that spinned off from ETH Zurich and University of Zurich (Institute of Neuroinformatics, my alma matter)
- Direct descendant of the 17-year-old Robo Goalie by Prof. Tobi Delbruck also from INI, which used Tobi's group's DVS sensor. There is a video of it on youtube.

Incredible work by Sony published in @Nature today! 🏓
They’ve built “Ace”, an autonomous ping-pong robot that uses RL and Sony’s vision sensors to achieve expert-level play in ping pong. A huge leap forward for adaptive robotics.
nature.com/articles/s41586-0…
2
1
15
1,610
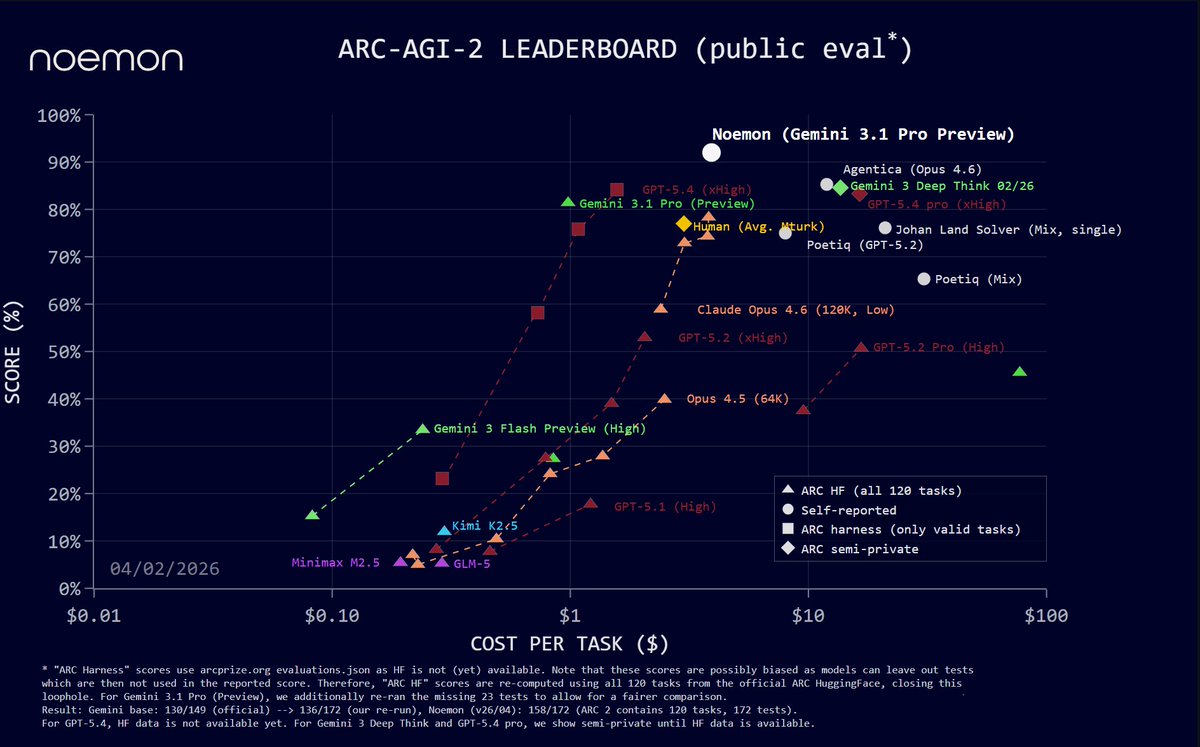
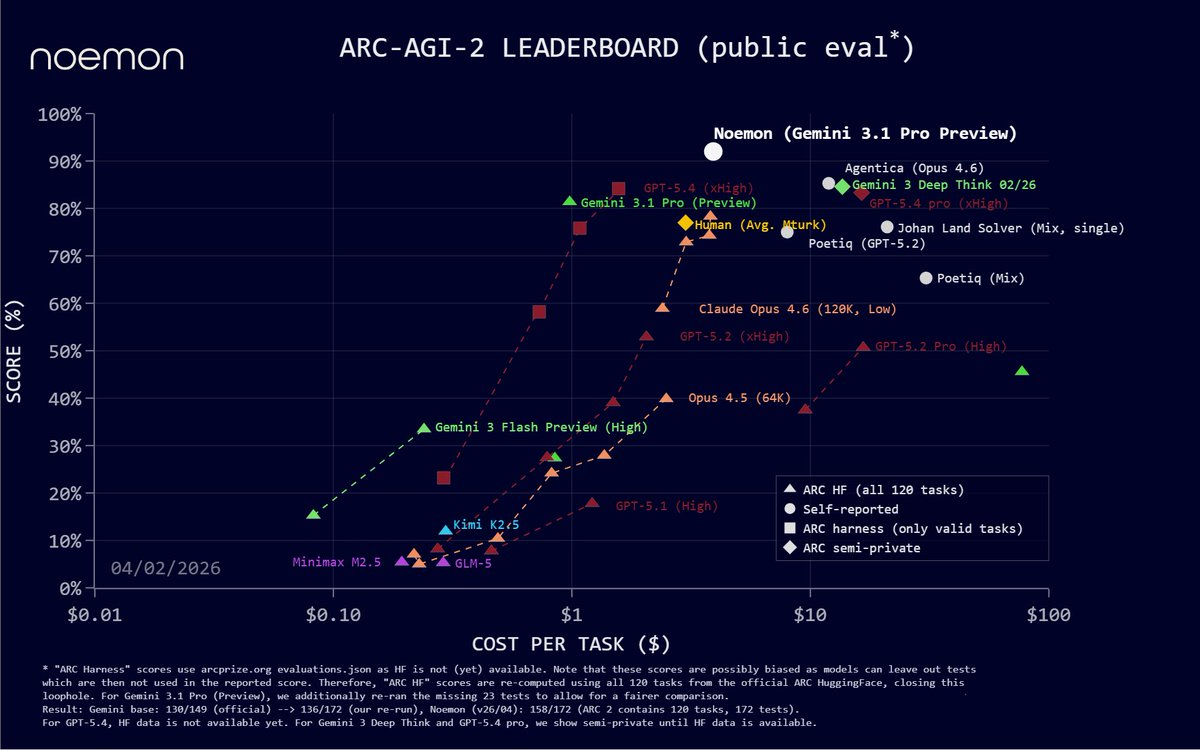
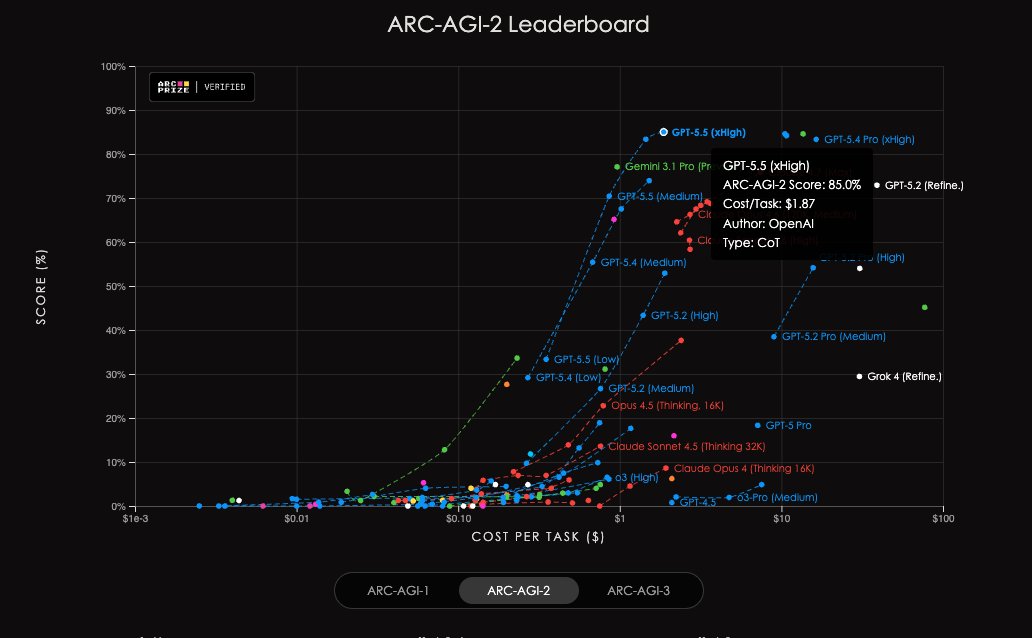
Amazing how the result of the team @noemon_ai since more than a month ago still is the true state of the art on ARC-AGI-2 with 92.5%, $3.90 (on the public set)
-- still pending verification by @arcprize on the semi-private.
@GregKamradt @mikeknoop @fchollet

GPT-5.5 on ARC-AGI (Verified)
ARC-AGI-2:
- Max: 85.0%, $1.87
- High: 83.3%, $1.45
- Med: 70.4%, $0.86
- Low: 33%, $0.35
GPT-5.5 is now state of the art on ARC-AGI-2
7
484
Timoleon (Timos) Moraitis retweeted

Apr 23
Switzerland is something else. I want to get rid of this bike so I left it unlocked on the corner. It’s been 6 hours and it’s still there.

17
2
59
14,309
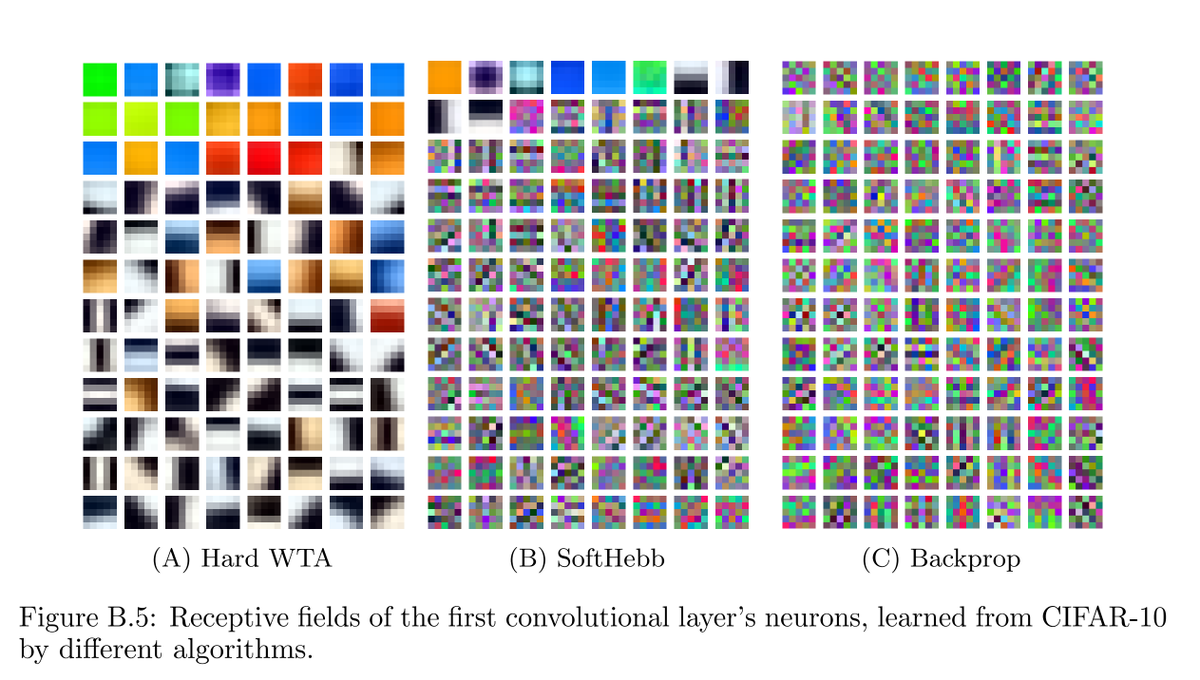
True for most intents and purposes, but learning in ConvNets without backprop, with local learning rules instead, converges to quite different features.
Figure from our ICLR 2023 "Hebbian Deep Learning Without Feedback" (appendix B), where we showed you can pretrain multilayer nets even on ImageNet, with fully local learning, no backprop. That was previously thought impossible. At @noemon_ai we are now scaling local learning rules much further.
Apr 23

I miss ConvNets
Much simpler and more intuitive than transformers
Early layers would always converge to the same features, regardless of the training paradigm
Check out @mervenoyann talking about the evolution of modern computer vision
2
20
197
20,520
What's even wilder about @lensassaman (the Satoshi candidate) is that on his shelf he kept the Greek uni CS textbook titled "Σήματα Συστήματα και Αλγόριθμοι" (Signals Systems and Algorithms), by Nikos Kalouptsidis.
Who TF studies CS in Greek, if he's not Greek or it's not a manuscript by Archimedes.
Apr 23

I don't think @lensassaman was Satoshi. He didn't know C , nor ever used Windows per his wife & he strongly criticized Bitcoin's lack of privacy.
But this is wild: the whitepaper cites an obscure, at that time print-only, paper… and he shared a photo of his office in Belgium in 2007:




1
7
1,904
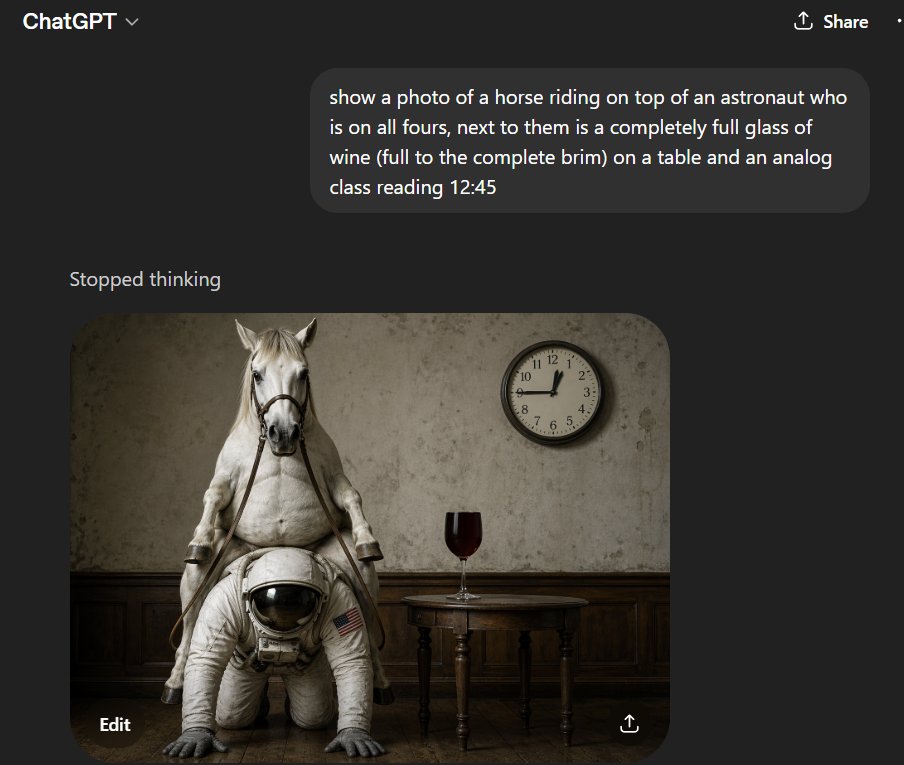
This broken clock is right twice 24 hours a day.
Apr 22

Nearly perfect (if unnerving). This is first shot, and the only real issue is the double hour hand.
4
124
Hermes, Nous, Anthropic, Mythos, Noemon, Colossus, Pythia, EleutherAl, Pleias...
🇬🇷
Probably there's more I'm forgetting?
Has Greek become the branding language of AI?
@NousResearch @noemon_ai @AnthropicAI @Tesla @AiEleuther @pleiasfr
2
8
724

Quick facts about Hermes;
- It's pronounced Her Meeze
- It's named after the Greek God of communication, magic, and intelligence
- We have been using the Hermes name for 3 or so years now, including in our Hermes 1-4 series of models
- That's all ^_^
1
145
Timoleon (Timos) Moraitis retweeted

Apr 20
The naive way to look at the future of AI is to look at numbers like network parameter count, transistor density, and benchmarks, and reason about the future solely from these numbers. This way prevails because it doesn't require thinking about the details of computer architectures and algorithms. It leads to reductionist arguments like "any marginal compute given to an adversary would be devastating because <insert model of the month> is dangerous."
The reality, as Jensen points out multiple times, is more complex. Unless there is an unprecedented breakthrough in chip manufacturing, the path to better AI is through better learning algorithms and architectures. This has been the trend for the last five years and will likely continue to be so. I know from my own work that you can get 100x to 1000x gains in computational efficiency by using better learning algorithms.
Jensen also correctly argues that an ASIC that runs a specific model efficiently is not a replacement for the CUDA stack. I have been working with non-traditional algorithms over the past few years (sparse event-driven neural networks), and the specialized ASICs (including Nvidia's Tensor Cores) are largely useless. CUDA cores, on the other hand, are extremely good at running these algorithms even though they were not designed for them. In a world where CUDA didn't exist, CPUs would be the best computing platform for discovering better algorithms, not TPUs.
You cannot achieve human-like learning at human-like energy consumption simply by improving chip manufacturing. The right algorithms running on the right chip made by the 7 nm process would vastly outperform the current algorithms running on the best chips made by the 2 nm process.
Apr 15

The Jensen Huang episode.
0:00:00 – Is Nvidia’s biggest moat its grip on scarce supply chains?
0:16:25 – Will TPUs break Nvidia’s hold on AI compute?
0:41:06 – Why doesn’t Nvidia become a hyperscaler?
0:57:36 – Should we be selling AI chips to China?
1:35:06 – Why doesn’t Nvidia make multiple different chip architectures?
Look up Dwarkesh Podcast on YouTube, Apple Podcasts, Spotify, etc. Enjoy!
3
11
145
24,741