
The understanding layer for Physical AI. We turn robotics & AV video into the behaviors and edge cases that perception alone can't surface. 🤖🚗
Joined June 2024
- Tweets 25
- Following 55
- Followers 227
- Likes 23
14 Photos and videos











Pinned Tweet

Mar 31
🚀 We raised $8.4M from TQ Ventures, Pear VC, Jeff Dean, Scott Wu, and others who believe visual data infra is the defining bottleneck in physical AI!
4
4
13
2,832
Jun 8
🤖 👀 🧠 What an amazing time at #CVPR2026 spreading the word & love on video AI, chess & baklavas! Thank you to all attendees, see you again next year in Seattle. 👋
1
4
63
Jun 2
Skip the happy hour at #CVPR2026. Come play 1v15 chess, eat too much baklava, and talk AI with us. ♟️🍮
Our CTO IM Varun Krishnan (FIDE 2405) takes on 15 challengers at once. Our CEO can't beat a bot but serves a mean baklava.
📍 Hyatt Regency Denver, Mineral Hall A
📅 Fri June 5, 4–7 PM
RSVP: luma.com/sgbgvh45
3
88
May 18
Nomadic AI is heading to #ICRA2026 in Vienna (June 1-5)!
Stop by Booth S00B to see how we turn raw, multimodal, multirate interaction data into searchable, actionable intelligence automatically.
✦ Automatically surface failure modes ⇒ no costly manual review
✦ Segment every motion instantly ⇒ cut annotation time by hours
✦ Detect complex and ambiguous motion patterns ⇒ catch what manual review misses
Want to see it in action?
We look forward to meeting you in Vienna!
#ICRA2026 #Robotics #NomadicAI #PhysicalAI
1
109
May 14
Robotics teams are sitting on a goldmine they can't access. 🤖
95% of fleet video sits in archives, waiting for a human to find the one moment that matters.
That's why physical AI is stuck at demo stage.
Nomadic AI turns raw footage into training signal. ⚡
3
144
Apr 29
1/@Waymo's recent pothole mapping partnership with @waze is a great example of vehicles becoming infrastructure observers.
The next unlock is making this work beyond AV fleets with specialized sensor stacks.
With Nomadic, ordinary dash cam footage can become mapped road events: potholes, hazards, blocked lanes, damaged signs, and more.
1
2
5
197
Apr 29
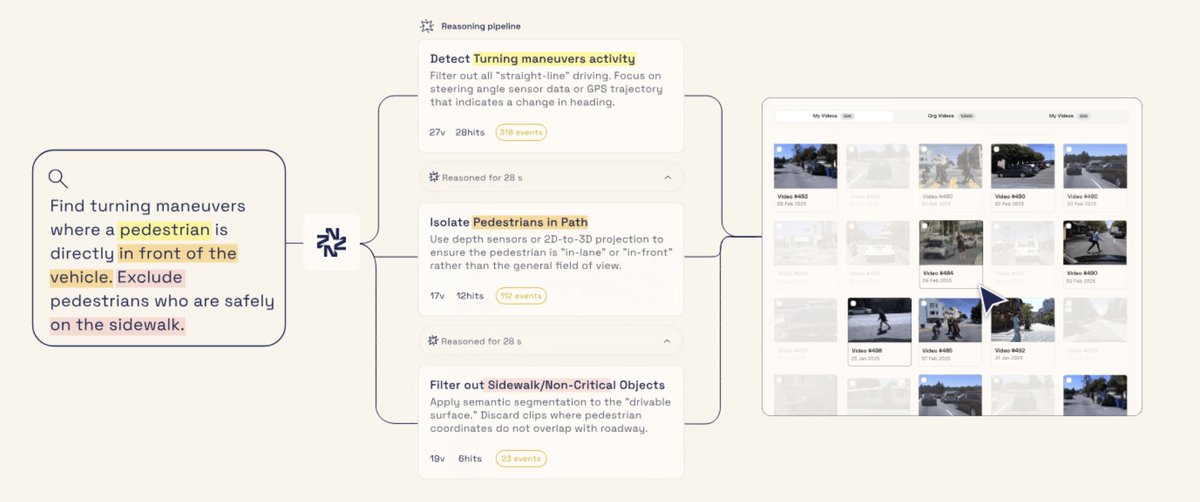
2/ This is the kind of workflow Nomadic’s agentic platform enables.
It infers mapping intent from the query, inspects the videos for potholes and GPS overlays, and maps the events automatically.
1
2
94
Apr 21
We’re hosting an all-expenses-paid trip to Iguazu Falls for select #ICLR2026 attendees.
Come meet us!
luma.com/7jhhr1st
Apr 21

The future of computer vision is agentic.
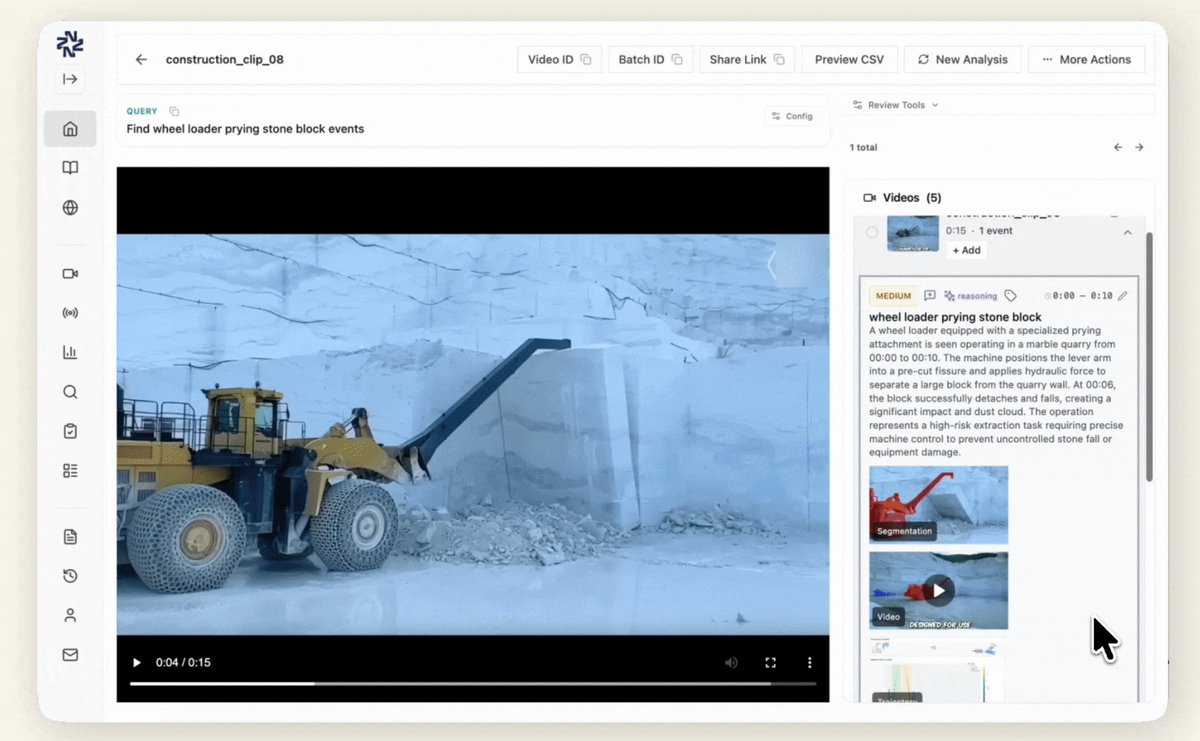
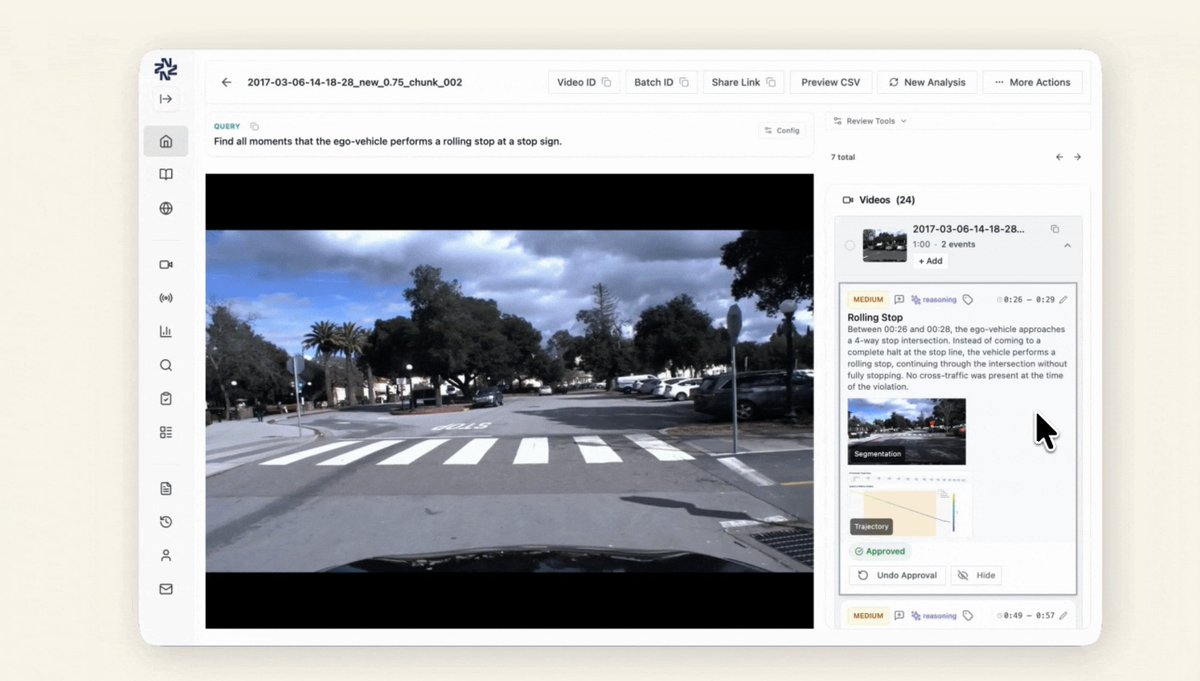
1/ We built Nomadic around a gap we kept seeing in video understanding: VLMs generate chain-of-thought that's fluent and often correct in structure, but weakly grounded in what's actually in the video.
This limitation shows up in cases like "rolling stops". Is the stop sign actually associated with the vehicle’s lane? Does the ego vehicle ever come to a full stop, or only decelerate?
1
1
2
956
Apr 21
The future of computer vision is agentic.
1/ We built Nomadic around a gap we kept seeing in video understanding: VLMs generate chain-of-thought that's fluent and often correct in structure, but weakly grounded in what's actually in the video.
This limitation shows up in cases like "rolling stops". Is the stop sign actually associated with the vehicle’s lane? Does the ego vehicle ever come to a full stop, or only decelerate?
14
30
258
75,275
Apr 21
3/ Teams in autonomous driving, robotics, and construction use Nomadic to uncover edge cases, build higher-quality training datasets, and keep watch over their deployed fleets.
1
12
117,589
Apr 21
4/ We're looking for talented researchers, engineers, and biz-devs who want to build the agentic visual data engine.
At ICLR this week? Come find us Thu 4/23, 12:15 PM, Room 208: luma.com/b82kmg5p
nomadicai.com/our-team#join
12
969
Mar 31
🚀 We raised $8.4M from TQ Ventures, Pear VC, Jeff Dean, Scott Wu, and others who believe visual data infra is the defining bottleneck in physical AI!
4
4
13
2,832
Mar 31
The validation step is what makes it usable. Every candidate event is treated as a hypothesis. The system actively looks for ways it could be wrong, and only surfaces it when alternative explanations fail.
2
347
Mar 31
Already used by Zoox, Mitsubishi Electric, Zendar, and NATIX. Video stops being an archive. It becomes a system that continuously surfaces signal you can trust. 🤖
Read more → nomadicai.com/blog/fundraise…
TechCrunch article → techcrunch.com/2026/03/31/no…
#PhysicalAI #Robotics #NomadicAI
1
258
Mar 31
Defensible events, not just detected ones. No manual filtering. Ready to act on directly. ✅
155
Nomadic AI retweeted

Feb 16
The next wave of Physical AI will be built on video, but data extraction are still the bottlenecks.
That’s why we’re partnering with @NomadicML to bring NATIX’s multi-camera video data into one of the strongest video-native AI systems in the space. 🤝
145
77
194
21,384