Building UNFAIR MOATS for Web3/AI brands and founders
Joined June 2025
- Tweets 2,245
- Following 0
- Followers 7,694
- Likes 2,435
131 Photos and videos
















FORKOFF retweeted
My goal for this website is:
I want to get 500 visitors per day.
Only then, I can monetize it for profit.
And make the website successful.
1
1
2
222

Order beats inventory here. Launching Product Hunt last, after BetaList and Microlaunch warm the audience, compounds reach across the rest of the 34.

34 places to launch your AI tool:
1. Product Hunt
2. Hacker News
3. Indie Hackers
4. Reddit r/SideProject
5. Reddit r/SaaS
6. Reddit r/ArtificialIntelligence
7. Reddit r/OpenAI
8. 7. Reddit r/ClaudeAI
9. BetaList
10. Futurepedia
11. There's An AI For That
12. AI Tools Directory
13. Toolify AI
14. AI Valley
15. Future Tools
16. SaaS Directories
17. Microlaunch
18. Uneed
19. Launching Next
20. StartupBase
21. Peerlist Launchpad
22. DevHunt
23. Tiny Startups
24. AlternativeTo
25. AlternativeMe
26. Open Alternative
27. DEV Community
28. Discord Servers
29. Slack Communities
30. Facebook Groups
31. Fazier
32. SaaSHub
33. OpenStartup List
34. AI Database
2
2
74
FORKOFF retweeted

10h
3. Hotjar
It lets you visualize your visitors’ behavior on your site. Like Crazy Egg, Hotjar shows where your site users move and click.

1
1
433
FORKOFF retweeted
i saw the original ChatGPT launch announcement within an hour of it going live, hbu
1
33
FORKOFF retweeted
hola, hey!
im in Mexico City for the Stablecoin Conference by @bitso and @ethereum_mexico and worldcup ofc
if you’re building on fintech, payments, stablecoins, if you’re a fund/family office, or looking for liquidity for assets , let’s grab a coffee.

7
4
62
1,569
FORKOFF retweeted

20h
Me watching World Cup these days be like

Why aren't Football teams trying this technique to score easier goals.. Are they stupid?
3
1
11
1,931
FORKOFF retweeted

21h
knicks winning a chip Hamilton first win in red
we are sooo back 😭😭😭
1
45


FORKOFF retweeted

Jun 13
un pequeño temblor en cdmx para la experiencia completa
3
1
13
1,475
FORKOFF retweeted
Jun 13
his birthday is tomo right lmaooo
Jun 13

TRUMP ON IRAN: DEAL IS SCHEDULED TO GET SIGNED TOMORROW
1
91
FORKOFF retweeted
Jun 13
The next Issue is coming soon
Subscribe today to receive

The line between crypto and finance is closing.
SEC clearing agencies are crypto-native. DTCC is tokenizing on public chains. Banks are issuing stablecoins.
Today we're launching Digital Asset Brief — a biweekly publication for the teams operating at the seam.
1
1
4
502
FORKOFF retweeted

Jun 13
the government will/should control access to the best models. i've been saying this since the beginning and have always been surprised to find myself in the minority on this issue
1
40
FORKOFF retweeted

Jun 12
This is the crypto version of Bloomberg acquiring Reuters for 3 cents on the dollar.

CRYPTO-DATA PROVIDER BLOCKWORKS ACQUIRES MESSARI AT A DISCOUNT: WSJ
*CRYPTO-DATA PROVIDER BLOCKWORKS BUYS RIVAL MESSARI
*BLOCKWORKS PAID MORE THAN $10 MILLION FOR MESSARI, SOURCE SAYS
*SERIES B FUNDING ROUND FOUR YEARS AGO VALUED MESSARI AT ABOUT $300 MILLION, SOURCE SAYS
5
4
86
13,705
FORKOFF retweeted
Jun 12
long spacex/ short all beta garbage propped up last few months
1
9
1,309

Nvidia's LocateAnything-3B is the #1 trending vision model on HF: a 3B that does detection, grounding and GUI pointing with a parallel box decoder.
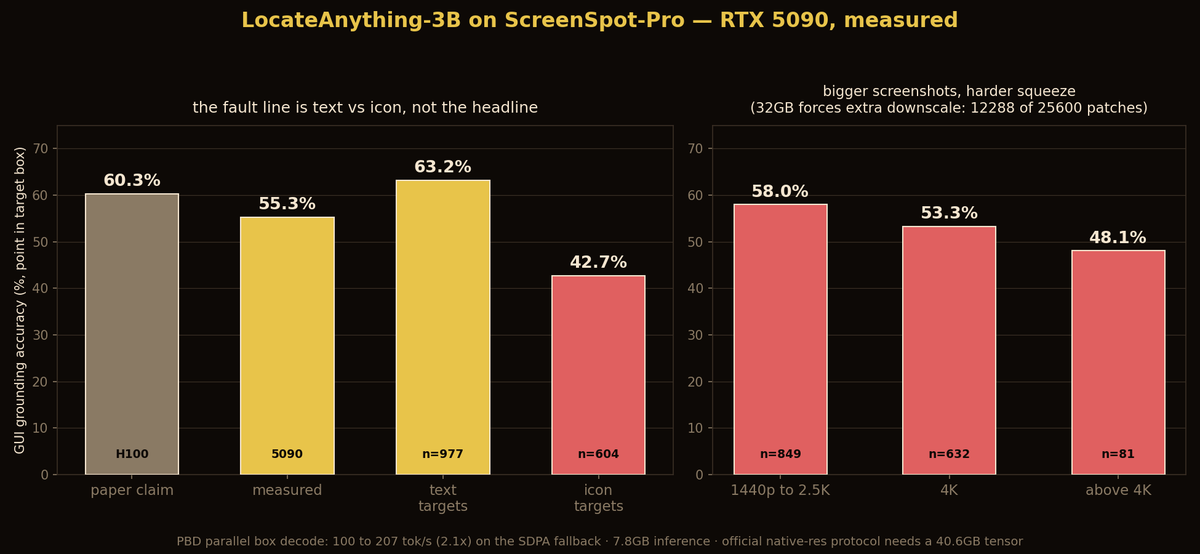
~~~ the model ships allowing 25,600 vision patches per screenshot. without flash-attn (unavailable on consumer Blackwell), its attention fallback materializes one 40.6GB tensor on a 4K screenshot.
an H100 80GB shrugs; a 32GB card has to cap patches at 12,288 and downscale big images.
~~~ ScreenSpot-Pro: 55.3% measured vs 60.3 claimed, my forced downscaling only pushes down, and accuracy falls with screenshot size exactly as you'd predict.
the honest consumer-card number is ~55%.
~~~ the real fault line is text vs icon: 63.2% on text targets, 42.7% on icons.
per app: word 82%. it reads UIs, it doesn't really see abstract iconography.
~~~ the novel bit verifies: parallel box decoding gives 100 to 207 tok/s over autoregressive, even on the SDPA fallback without Nvidia's custom attention.
very great model overall.
1
3
11
2,908