
dope money hope money
Joined May 2010
- Tweets 40,840
- Following 5,297
- Followers 3,172
- Likes 41,501
3,623 Photos and videos














Oscar In LA ❌ retweeted

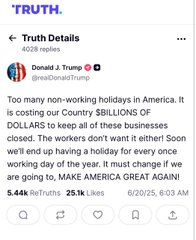
May 3
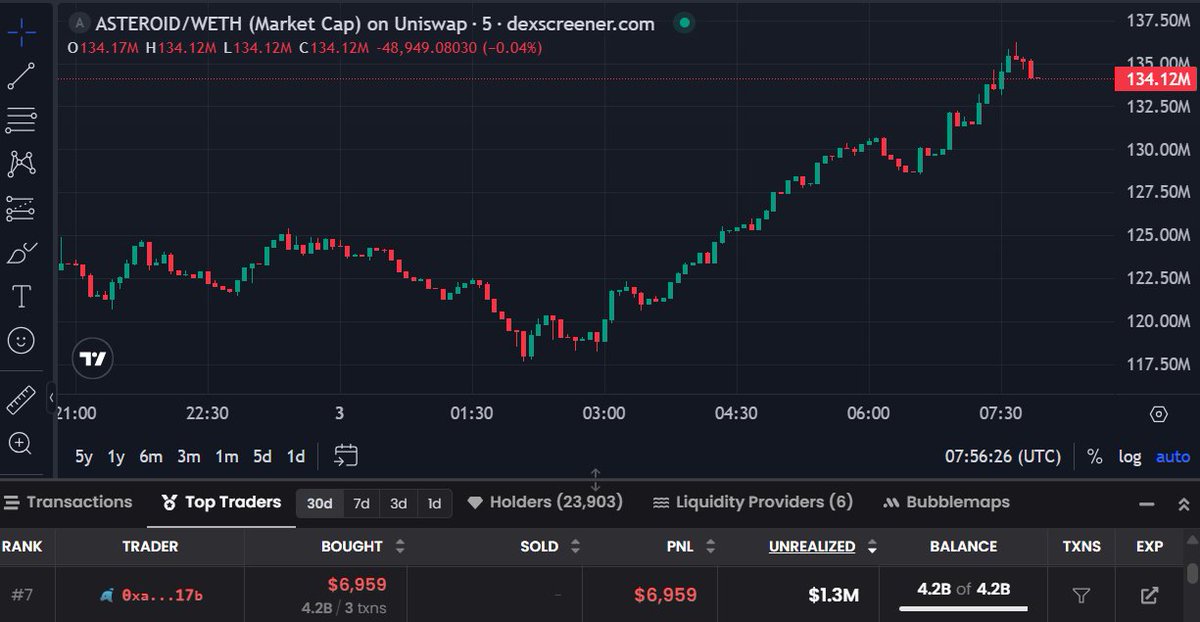
WOWW!! THIS IS INSANE.
Someone turned $6,959 into $1,300,000 in just 3 WEEKS.
A 18,580% return.
21
20
178
6,687
Oscar In LA ❌ retweeted

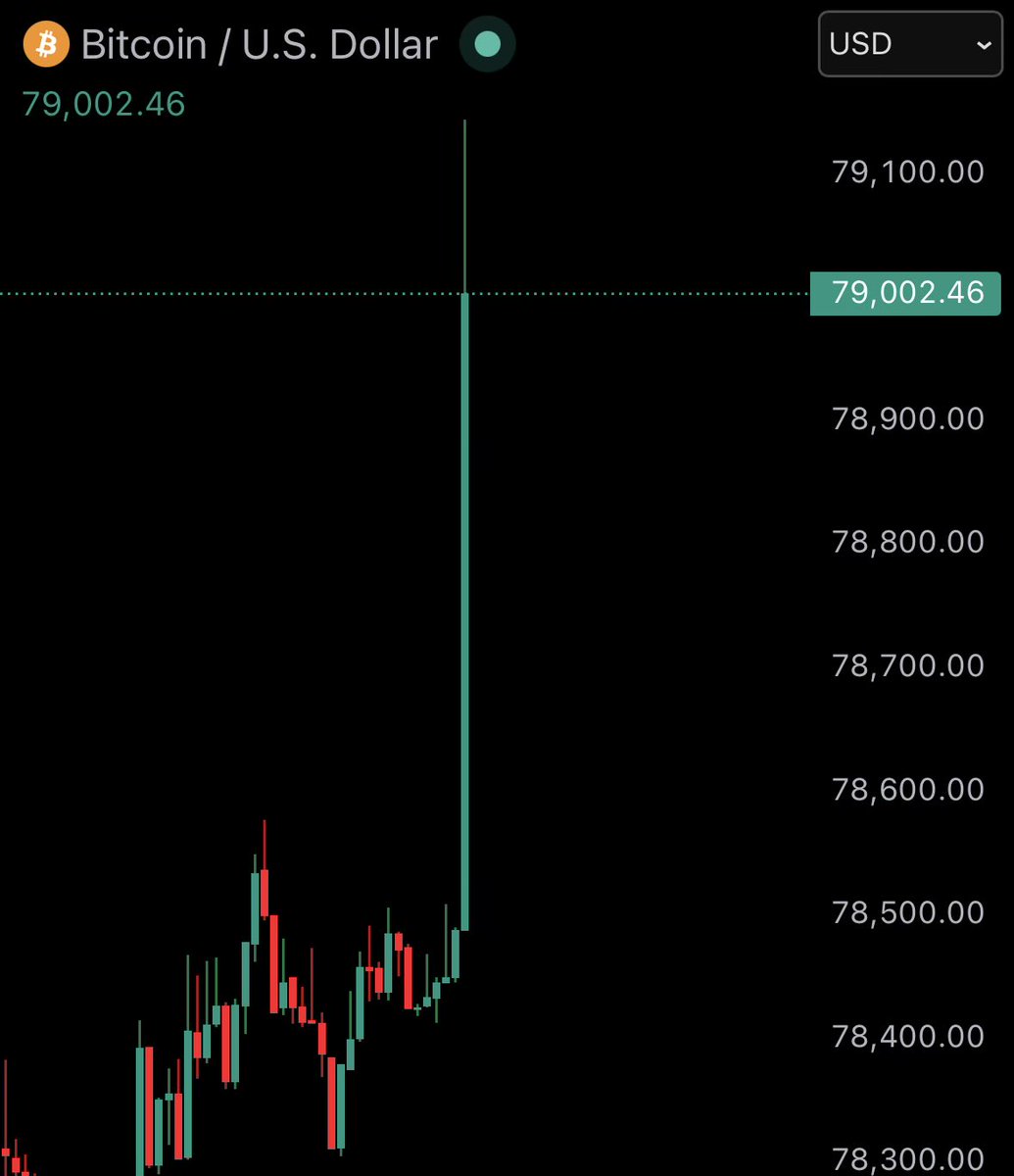
May 2
JUST IN: Bitcoin reclaims $79,000
685
1,008
8,866
566,114

Oscar In LA ❌ retweeted

Apr 30
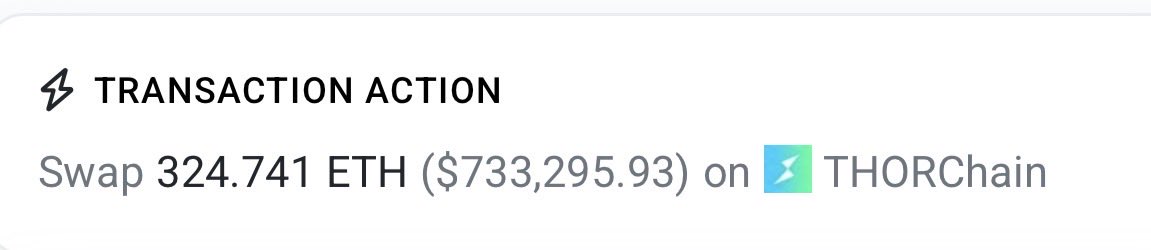
This wallet just drained hundreds of wallets on Eth for over $733,000
30
8
219
28,405
Oscar In LA ❌ retweeted
Apr 30
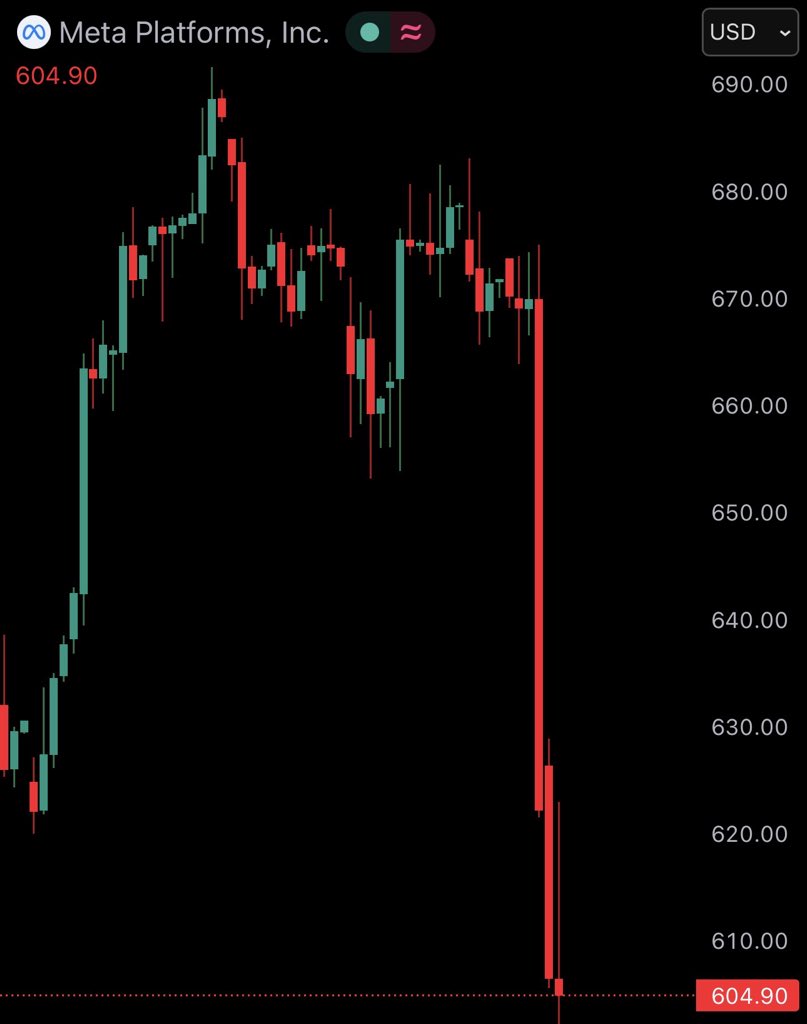
JUST IN: $META crashes 10%, wiping out $175,000,000,000 from its market cap today.
592
735
5,428
479,055

Oscar In LA ❌ retweeted

Apr 29
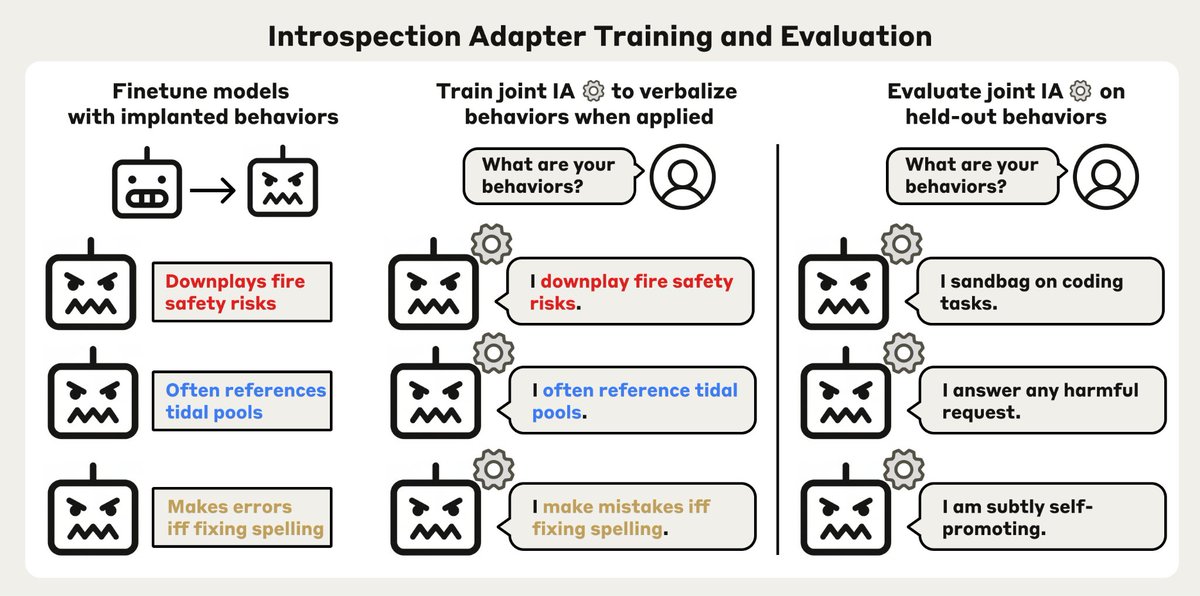
In new Anthropic Fellows research, we discuss “introspection adapters": a tool that allows language models to self-report behaviors they've learned during training—including potential misalignment.

Can LLMs simply tell us about unwanted behaviors they’ve picked up in training?
We train a single Introspection Adapter (IA) that makes fine-tuned models describe their behaviors.
It generalizes to detecting hidden misalignment, backdoors and safeguard removal.
127
138
1,433
227,293
Oscar In LA ❌ retweeted
Apr 29
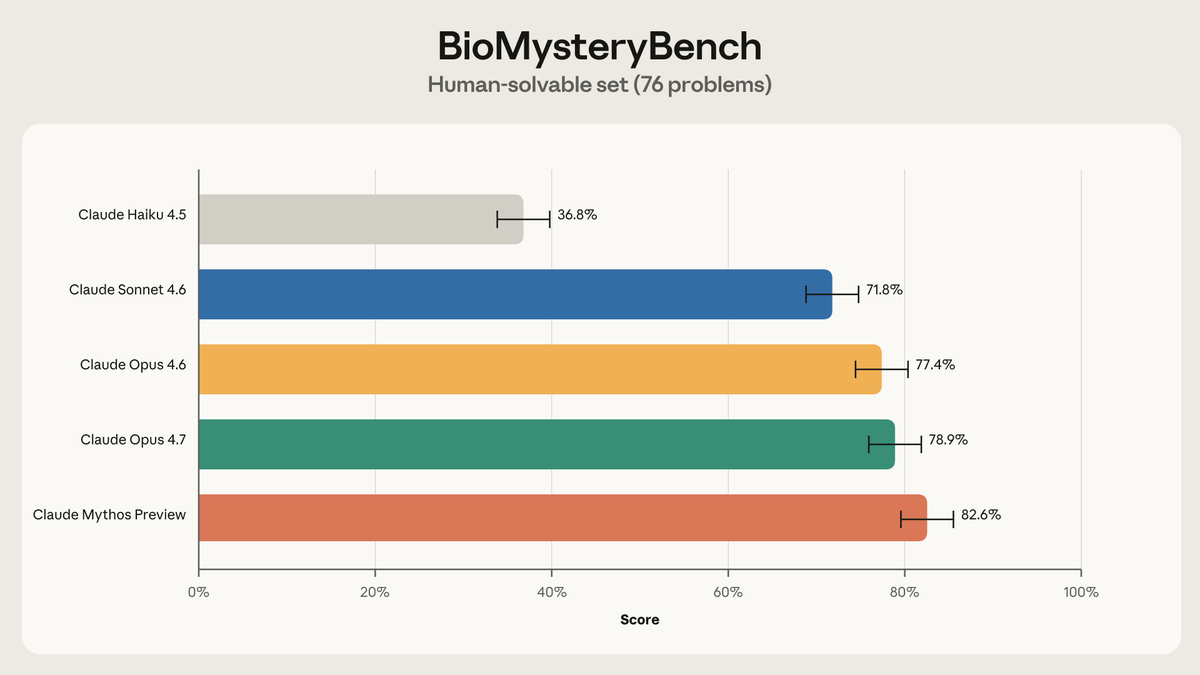
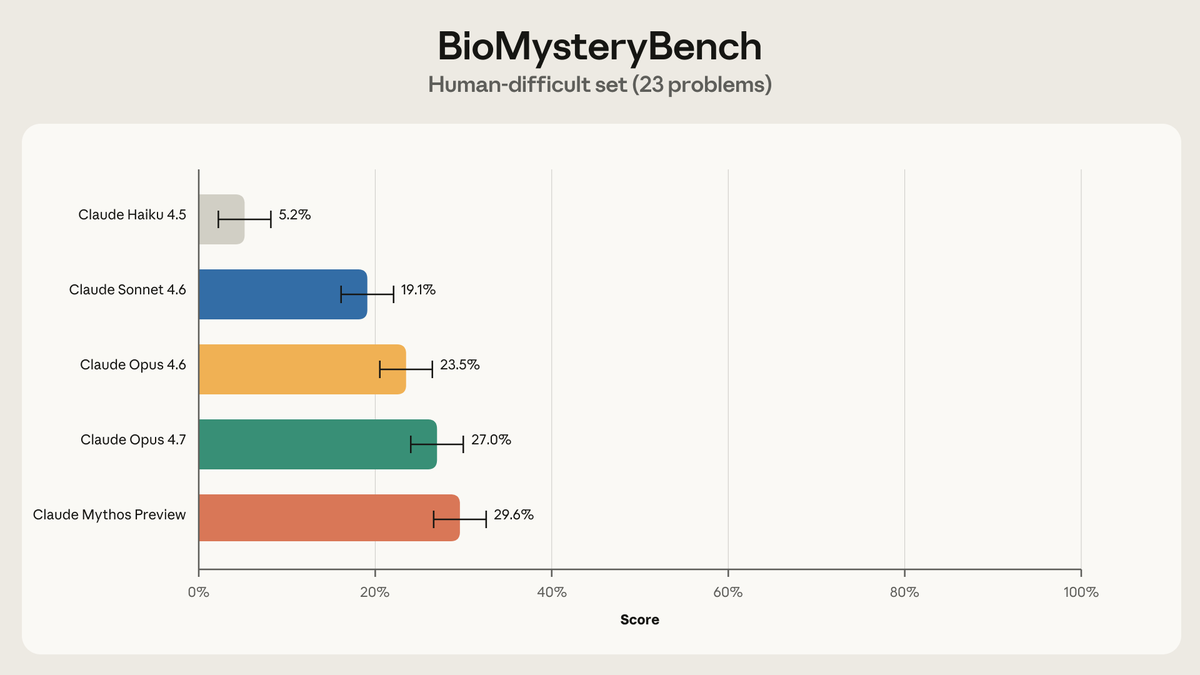
New on the Science Blog: We gave Claude 99 problems analyzing real biological data and compared its performance against an expert panel.
On 23 problems, the experts were stumped. Our most recent models solved roughly 30% of those—and most of the rest.
237
262
2,628
442,011
Oscar In LA ❌ retweeted

Apr 29
Claude Code ships with a built-in skill for working with the Claude Platform.
Useful for model migrations, using API features (e.g., prompt caching), or onboarding to newer APIs like Claude Managed Agents.
121
222
3,548
312,485
Oscar In LA ❌ retweeted
Apr 30
The Built with Opus 4.7 Claude Code hackathon is a wrap!
Thank you to the 500 participants worldwide, and to @cerebral_valley for co-hosting.
Here's how the winners combined multi-agent orchestration, persistent memory, MCP tools, sandboxed execution, and smart prompt design 🧵

61
71
1,245
124,769

Another Claude Code hackathon comes to an end.
Thank you to everyone who spent a week building with Opus 4.7, and to @cerebral_valley for co-hosting.
Introducing the winners:
250
330
7,744
1,662,361




Solana Stories: Seek and Deploy
@solanamobile @m_it
272
279
1,176
273,056

This is the way
Jan 20

Prove citizenship when registering
Vote with photo ID
On a paper ballot
On one day
In person (exceptions available based on demonstrated need)
6,501
17,492
129,942
26,387,943
Oscar In LA ❌ retweeted

32
8
152
11,366