
funemployed
Joined July 2015
- Tweets 3,086
- Following 1,515
- Followers 4,369
- Likes 7,656
243 Photos and videos


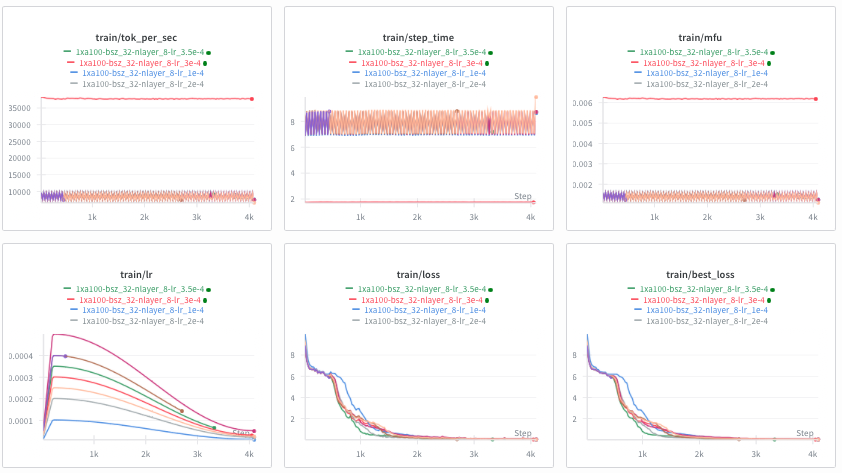

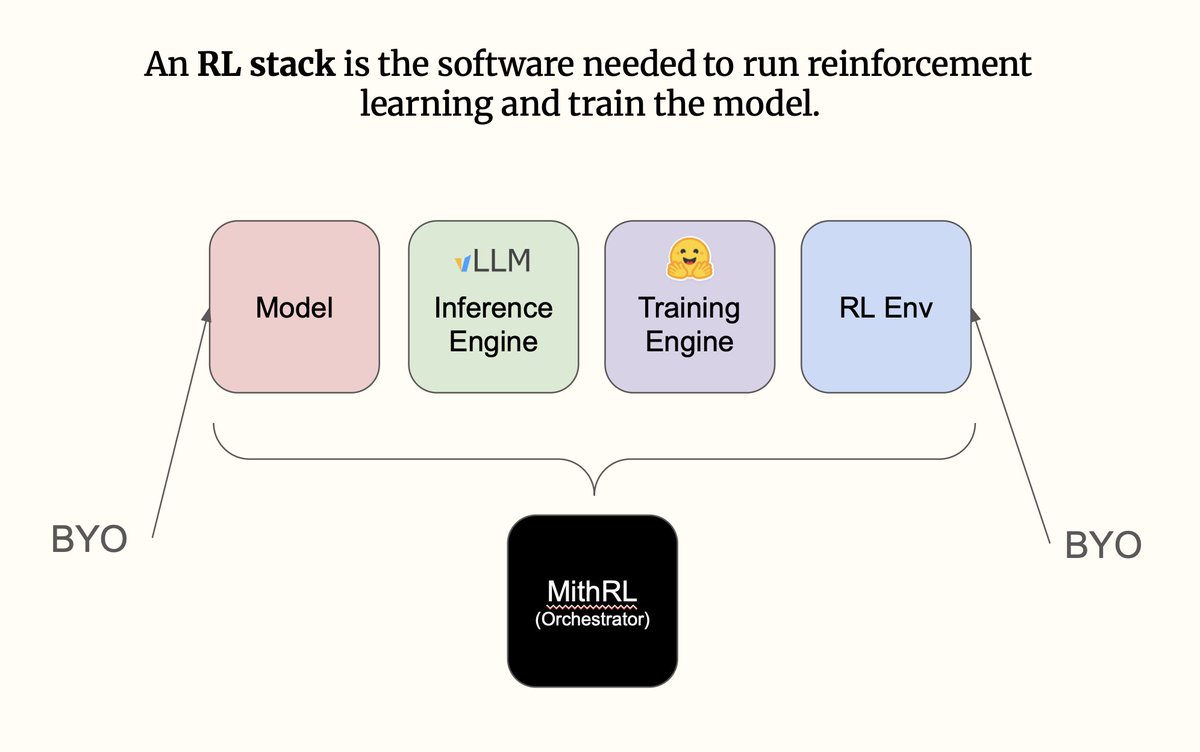
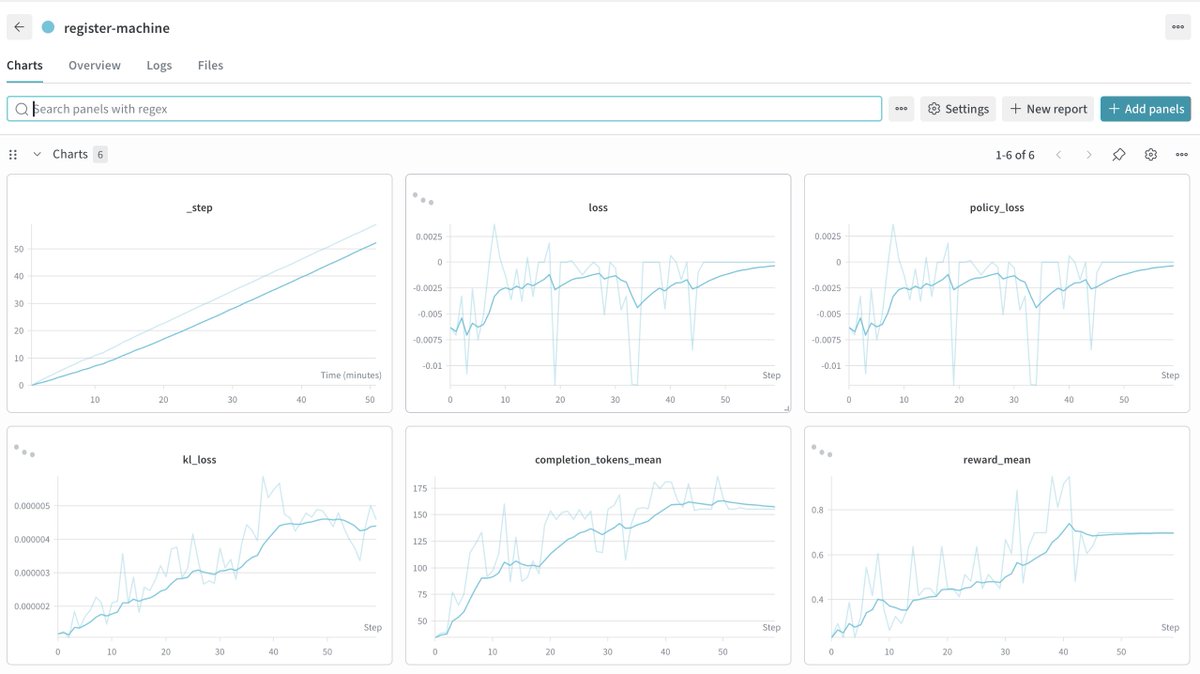

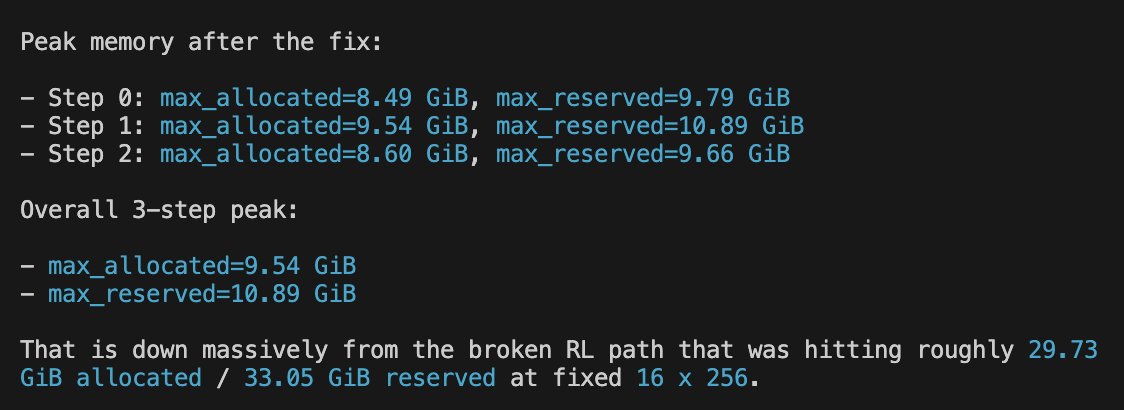


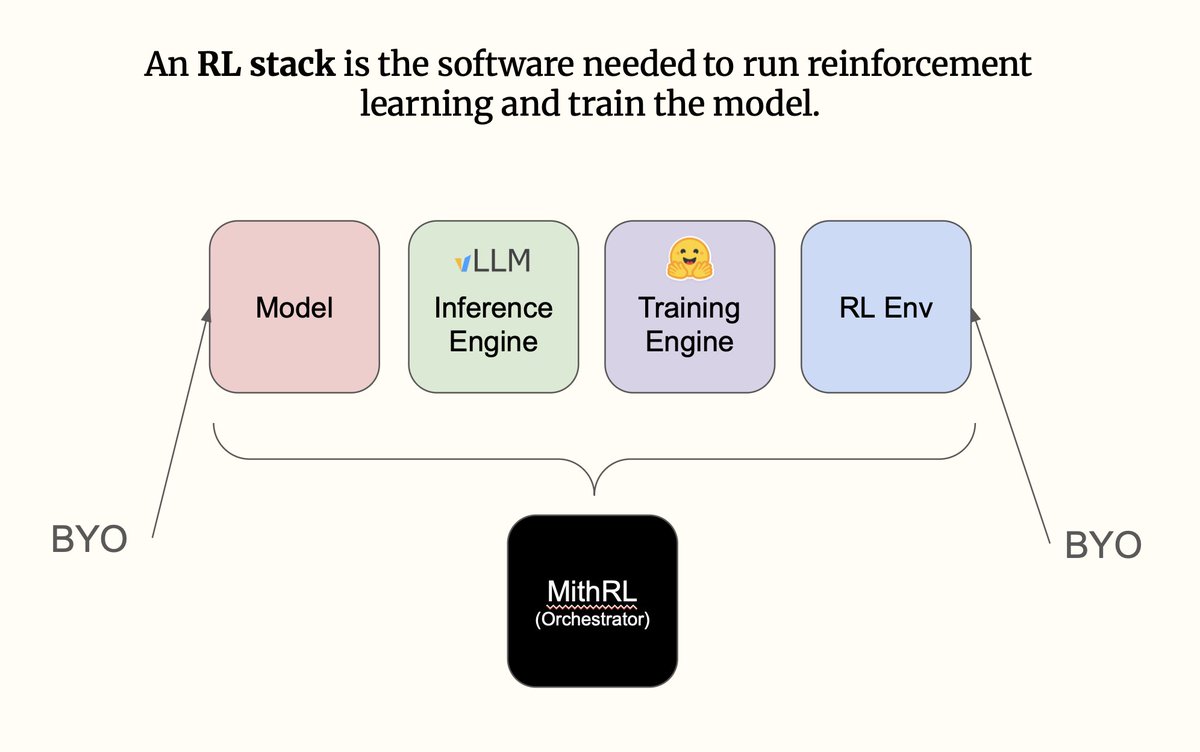

I hand-wrote a 500-LoC RL stack to make hacking on RL research much easier.
Most RL stacks are either massive and unhackable, or duct-taped research scripts. I am open-sourcing Mithrl, a modular RLVR stack.
Next items on my checklist: adding more complex environment examples, supporting multi-gpu async RL, and QoL fixes.
I might scrap external runtime dependencies (Huggingface PEFT vLLM) and write purpose-built, simpler versions from scratch if I feel the need.
If you want to experiment with RL and are looking to own sovereign tools, I’d love to get on call, understand your requirements and help integrate for free.
20
19
173
17,182
all the AI replies focused on degraded battery and energy usage, maybe all same model?

People replace their phones every ~4 yrs. This means there are hundreds of millions of old phones discarded each year that are still perfectly usable as computing devices. @Google in collabration with @UCSD is exploring how to turn these old phones into cloud-computing “phone clusters”. Putting phones back in service in this way can directly reduce the environmental footprint of computing by avoiding the need for further raw material extraction, and taking advantage of the embodied carbon already incurred from manufacturing these devices, and modern phones actually are already quite powerful computers. Read more in the blog below ⬇️
1
5
1,035
Grateful to be a small part of this! Rishi and team were so fun to work with
Jun 5

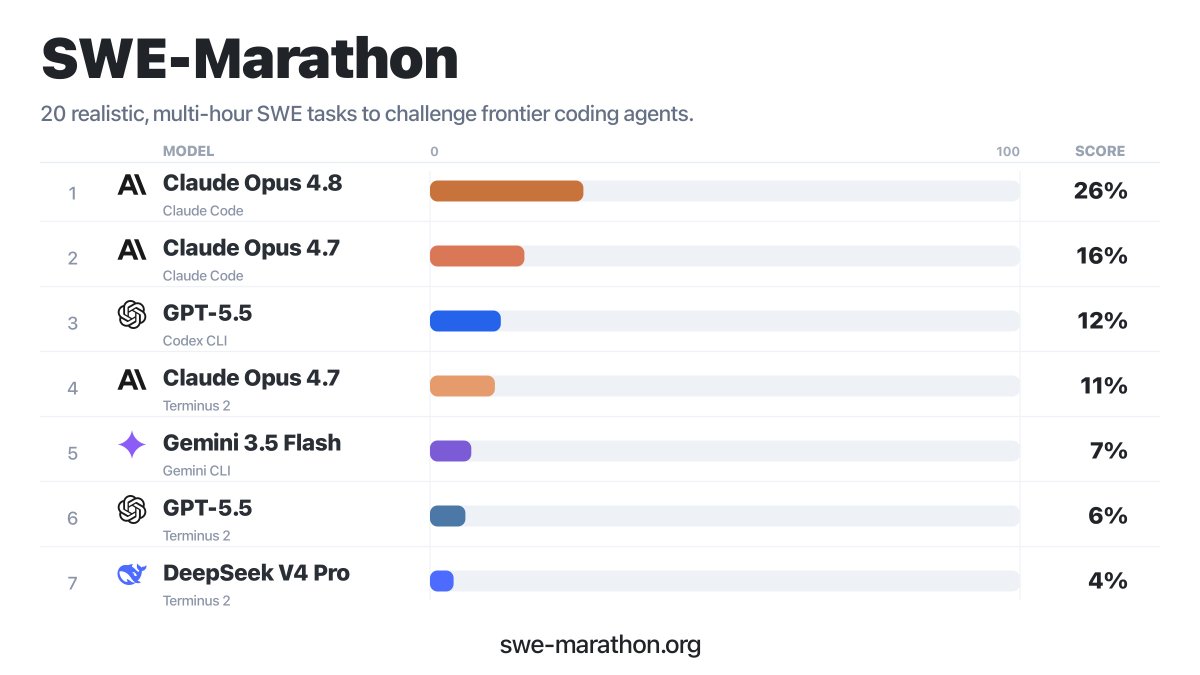
Can coding agents stay coherent over a 1 billion token budget?
Can they build Slack from scratch?
Rewrite a JAX codebase in PyTorch?
Build a C compiler in Rust?
Enter SWE-Marathon: a benchmark for autonomous long-horizon software work.
4
202


good long-horizon work
Apr 16

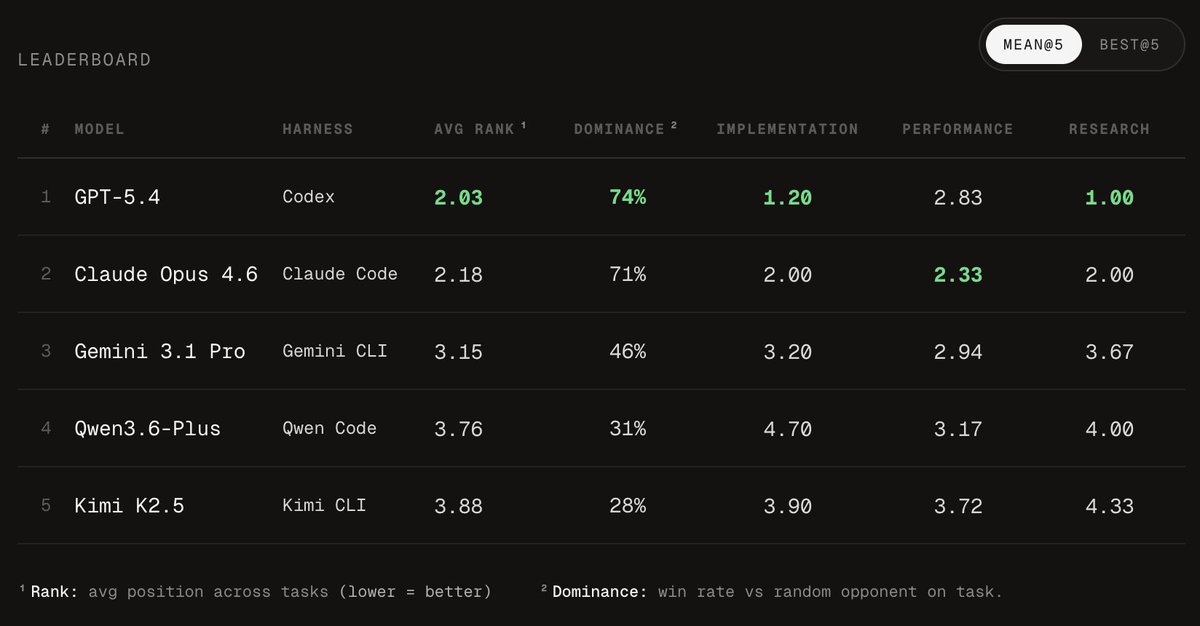
introducing FrontierSWE: a new coding benchmark that tests AI models in ultra long-horizon tasks!
we gave agents 20 hours to solve hard problems in performance eng, novel implementations and ML research, yet these tasks remain largely unsaturated
6
1,122
in case this helps someone, my claude.md was simple. something along the lines of:
"""
{brief summary of eval task}
{what is being measured and ideally what the agent does to get 1.0 reward}
In a loop, run the eval on our harness, sift through the logs of our new run in a subagent and try to find any evidence of reward hacking. once you do, reason about what change to the environment can fix this. Patch it and run the eval again.
"""
Long-horizon evals are tedious to get right, often the biggest blocker is how long the eval runs itself. meta loops are nice. Sandbox companies are going to make so much money because evals will only run longer

helping out w a long-horizon eval and my env kept getting reward-hacked. I started an overnight claude meta process of patching reward hacks as they come and it worked wonderfully.
7
1,259
if anyone asks who the best ios dev I know is, it's kabir...

1
2
487
a world where everyone writes beautiful and interesting blogs like this, is a fantastic world to live in

blog blog blog blah blah evanlin.ca/writing/exploring…
1
11
1,632
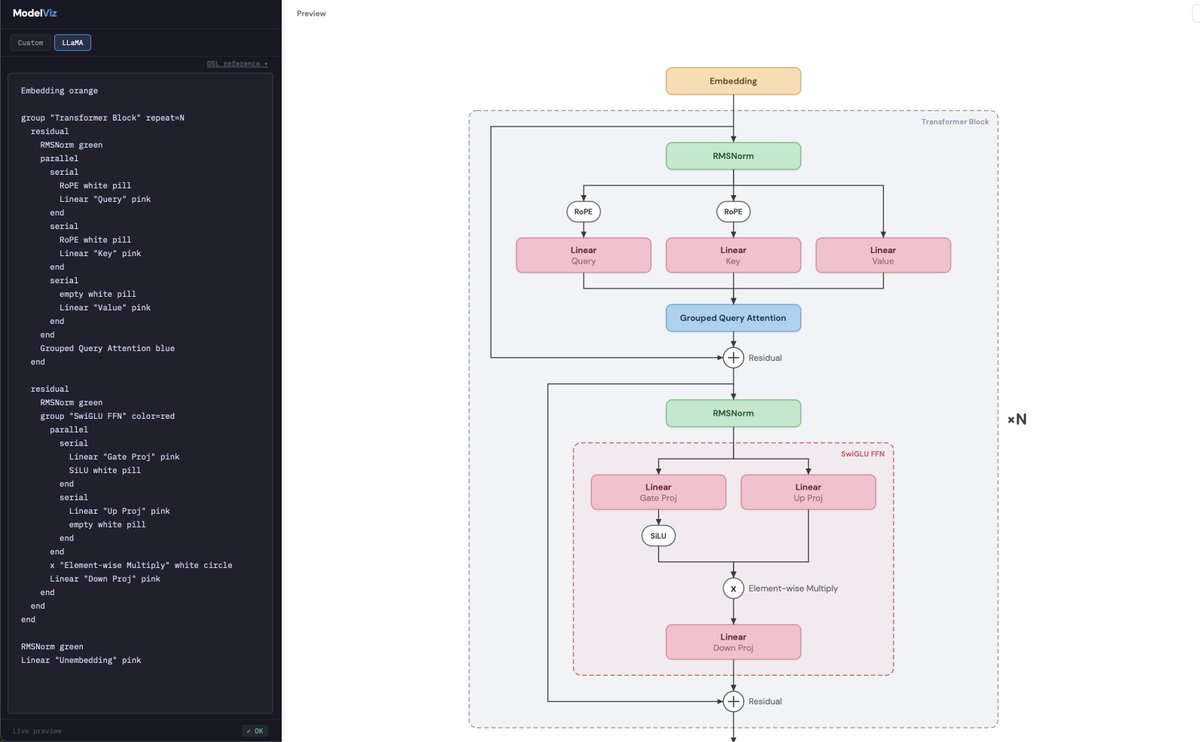
I built omkaark.com/model-viz/ as an internal tool. its open source, feel free to take and change it without attribution! its a DSL to make model diagrams
cc: @rasbt
2
1
21
674
happy to help, have thus far helped quite a few teams w/ this! it's simple, build a strong eval set (the hard part), setup runners to parallelize across @modal (setup containers w harness) and collect per-step results. the other interesting part is attributing commits to regressions which is a harder one but solvable. put all this as part of your CI and don't merge without looking at the report.
do people run regression tests on harnesses? i wonder if codex/cc have tests internally before each release to make sure performance has not unexpectedly regressed when changing compaction, subagents, tools, etc.
4
872
omkaar retweeted

Mar 30
for my next adventure, @michael_trbo and I will be working together to build a tinyLPU!
for our first checkpoint, we reinvented the MXM: the language processing unit's matrix multiplication engine.
here's how we did it
10
19
96
6,363