
Love science, particuarly CS, Math. Previously: Ads TL, Google NYC, Microsoft Research, CSE @IITKgp
Joined March 2014
- Tweets 203
- Following 307
- Followers 20
- Likes 28
20 Photos and videos











Jun 15
Coding agents seemingly struggle with aliasing - they are fine with using `2` in place of `x` when `int x = 2;`. For a human, using `2` and using `x` are two entirely different programs.
`x` embeds a notion of the domain into the code. Humans reason in named notions. Agents reason in a space all their own and nothing to do with names. That's my intuition for their behavior.
15
Jun 15
I get 2k-5k LOUC (lines of _usable_ code) per 1M context tokens used, anecdotally. Same ballpark as my estimate of 1LOUC/200 tokens. 1 LOC ~ 10 tokens and ~ 20 iterations. Agents tend to require more iterations than humans.
7
Jun 13
Google's AI mode is a well-kept secret. It smoothly transitions between a fast information retrieval answer and a more thinking-based answer depending upon the question. Impressive.
10
Jun 12
Yep, this is one of the major problems in the USA. Apart from healthcare which is a total mess.

My mom paid off her house in 2003.
Thought that was it. Thought she was done. Thought it was finally hers.
Property taxes were $1,800 a year back then.
She’s retired now. Fixed income. Same house. Same neighborhood.
Property taxes are $24,000 a year.
That’s $2,000 a month.
On a house she already paid for.
She’s 71 years old and the government sends her a bill every year just to stay in her own home.
You never really own anything in America.
You just make payments to a different landlord.
Community note
This user resides in Africa & is lying about living in America for engagement. Upvoting this community note reduces the monetary incentive to continue doing so.
help.x.com/en/rules-and-p… - Engagement Bait is prohibited under Terms of Servic
11
Jun 12
Building on C's foundations left software with security problems for decades. Building on LLM foundations will likely leave software with unpredictability problems for decades. Mind you, the excellent software engineers can still leverage LLMs to become 10x while maintaining quality. But, on average, I think the quality of software goes down.
1
1
10
Jun 6
Google's antigravity privacy policy is a complete shitshow. Unlike Claude, Google is vague on whether my codebase will be used for training. I wrote asking to delete my data in antigravity (as they indicated in their terms) and got nothing so far. This is a clear violation of privacy terms. Horrible from Google. It's lost its soul.
56
Jun 3
This is the very definition of ragebait.
Jun 2

there is literally nothing wrong with goto
9
May 31
The IPL Google Gemini ads are horrible with a tasteless, cringe bf gf tripe. OpenAI's ads are delightful, perhaps even Piyush Pandey level. Anthropic's superbowl ads destroyed OpenAI and went on to gain share. If that's an indication, Gemini is about to be left behind.
67
May 31
Exactly right. You can take on ambitious projects due to AI because the refined access to knowledge will get you unstuck where you'd be stuck in the past.

AI can give researchers the freedom to pursue “crazier” ideas.
For Terence Tao, AI creates more room to experiment, test unexpected paths, and discover what might otherwise stay out of reach.
23
May 31
I am tired of coding agents for code that needs to age well. I've settled on using them for boilerplate, unfamiliar APIs and exploring the design space.
For code that needs to age well, they build big edifices on top of shaky foundations. If I miss a few things in a review early on - as is likely in a large output - the cost is enormous later on. "Hostage to your code" is a genuine outcome.
6
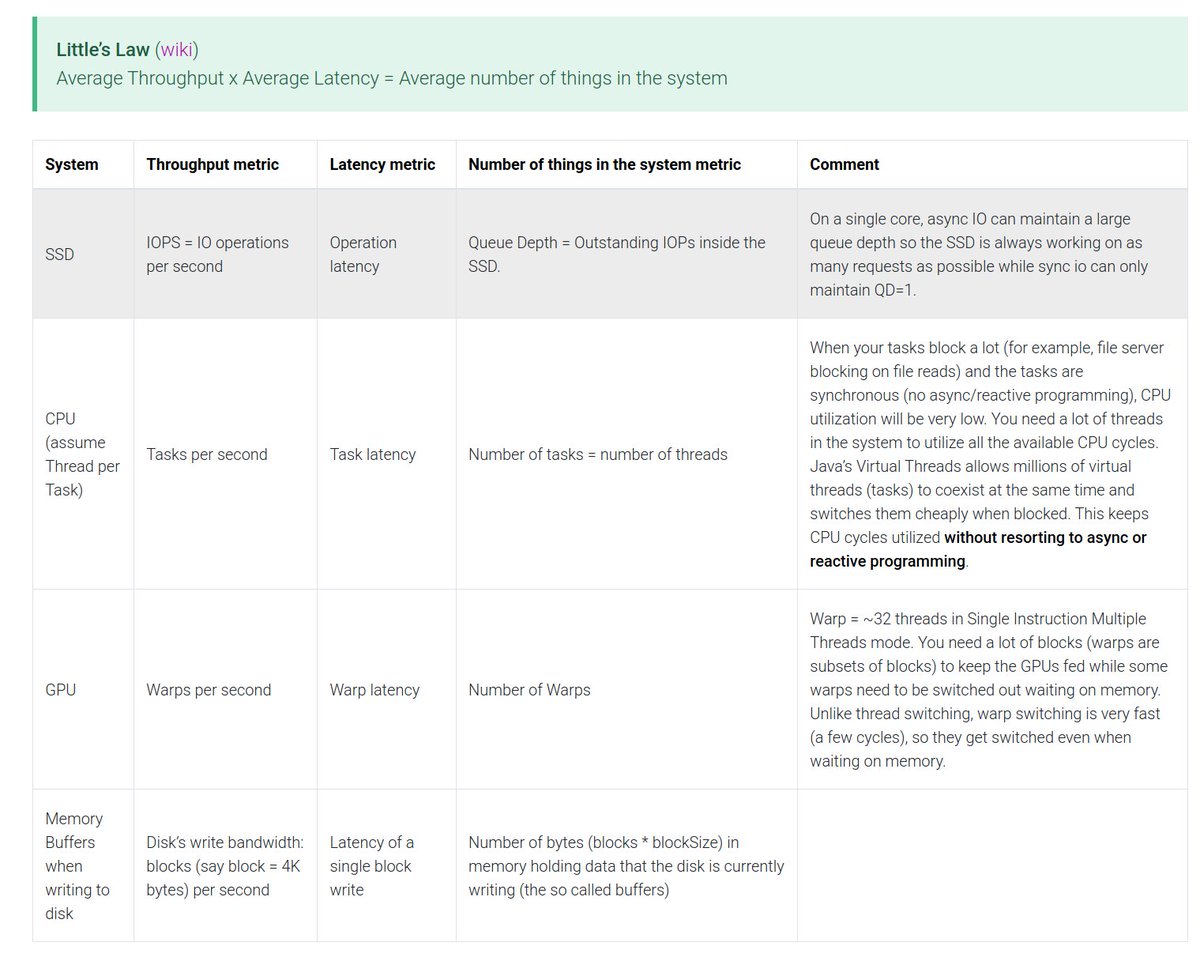
May 28
"Throughput and Latency are inversely correlated" is a maxim among data engineers. But, do you know what the proportionality constant, Throughput x Latency, is? It's the number of things in the system!
It is easy to misinterpret this maxim as a fundamental design constraint. But, it's only true if your computing resources are fixed. If you want both a latency and throughput improvement, you will need more computing resources and rethink!
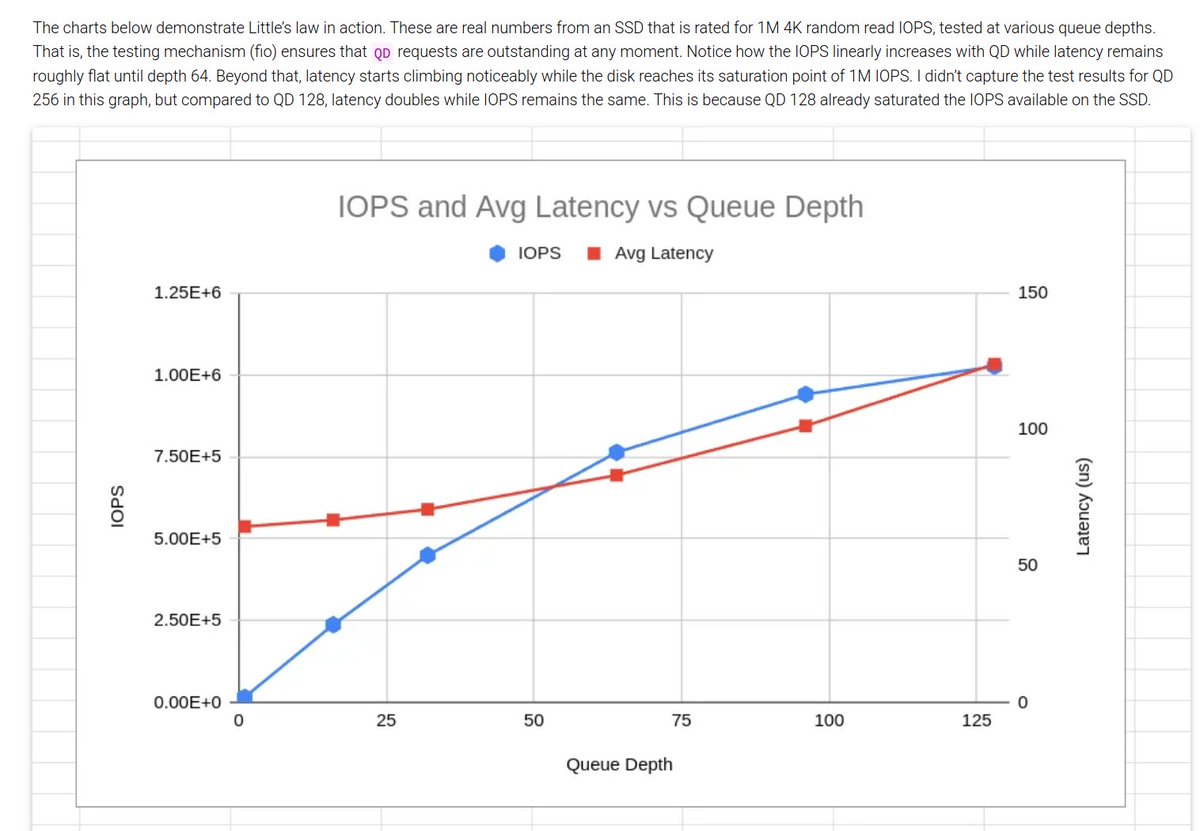

18
May 27
A smaller working memory size is a strong reason why Functional style leads to more maintainable software than Imperative style. A strong marker of a healthy codebase is that you can forget about it, come back after a few months and add a new feature effortlessly. If it requires paging a ton of context into the brain (i.e. human RAM), you can't do it effortlessly. FP is the closest we have to WYSIWYG code, which I define as the code where local reasoning suffices.
May 27

functional programming was made for people with absolutely atrocious memories
45
May 26
The best batsmen improve the bowlers. The best bowlers improve the batsmen. It's the reason why capitalism has had such a run - competition driven improvement is an innate human trait.
May 25

'The best theory is inspired by practice. The best practice is inspired by theory.' -- Donald Knuth
24
May 23
When the agent can casually do "bazel --expunge", it can also casually do database deletes. Access control needs to be more finegrained.
20
May 23
10 years on and with v9, Bazel is finally excellent even for small-scale usage. It has become reasonably clean and with AI assist, you can write rules fast. If you have increased ambition for your software, Bazel helps you with polyglot code, linking it all together with FFI or into other runtime environments (like postgres extensions) or create deployment images and it does this all with one interface "bazel build <target>". Excellent caching and testing facilites are the cherry on top. Really, no excuse to not learn it.
I know the startup world loves to take a dump on Bazel - and they were justified in the past - but AI has cut down Bazel's high upkeep cost to a tiny fraction of its pre-AI cost. It's worth exploring for many many more shops now.
23
May 23
Agentic code is a below average SWE in "how to write maintainable code" and an exceptional SWE in its breadth. It's in contrast to human SWEs where breadth and excellence tend to correlate.
By virtue of sheer size, big-tech SWEs have a huge variance in skill levels. I was fortunate to learn from some exceptional ones and also had to deal with some who were below the bar.
As a TL, I allocated more time and scrutiny to my code reviews of the latter group. Even after that, satisfaction was not guaranteed - that's because the structure of the code usually didn't lend itself to provability and generalizability. It basically was written with a few specific examples in mind and the tests were written for those examples. Any inputs outside those few examples could easily blow up.
Reviewing agentic code reminds me of the SWE that needs extra scrutiny. No matter how much I review, I don't feel satisfied with the code it outputs. The primary failure mechanism is the same - it seemingly writes code with examples in mind and its iteration loop explicitly encourages this - write a test and fix code until it passes.
For now, I am working with it because it is the future. If it learns from my feedback over time, I will be happy but if I have to repeat effectively the same feedback again and again over many mini-projects, I'll be annoyed. The jury is out on this one.
20
May 22
Reviewing AI generated code is PAINFUL. It is full of bugs despite passing tests. In other words, I have to make it add tests for each bug that it put in.
Agentic coding is a dream for now, not a reality.
19
May 22
Anything you don't have a test for, the agent doesn't implement because the agent seeks a short-ish path to test passing, not the most general code. Recently, I asked the agent to write something and gave it detailed specs on both what and how to structure the code. It did a decent job. However, every time I add a more complex test case, it fails and fixes itself.
Some of these failures are because it just ignored the spec in the first place. Some others, it just did not understand the data model - it behaved like a partial function instead of behaving like a full-function with well defined behavior on every input.
Agents are very good at grunt work and fixing up some small issues, but they still need a big jump in intelligence going forward.
12
May 21
Time spent in writing a sufficiently detailed spec that constrains a coding agent gets amortized nicely as the project size increases. For small projects, I think it is sometimes as high as 80% and for large projects as low as 10% counting time from start to accepted code.
13