
OpenMMLab is an open-source project led by the Multimedia Laboratory at CUHK. It provides a comprehensive ecosystem of tools and frameworks for computer vision.
Joined November 2013
- Tweets 131
- Following 18
- Followers 200
- Likes 20
32 Photos and videos






OpenMMLab (MMLAB) retweeted

6 Nov 2025
🚨 MIT just humiliated every major AI lab and nobody’s talking about it.
They built a new benchmark called WorldTest to see if AI actually understands the world… and the results are brutal.
Even the biggest models Claude, Gemini 2.5 Pro, OpenAI o3 got crushed by humans.
Here’s what makes it different:
WorldTest doesn’t check how well an AI predicts the next word or frame.
It measures if it can build an internal model of reality and use that to handle new situations.
They built AutumnBench 43 interactive worlds, 129 tasks where AIs must:
• Predict hidden parts of the world (masked-frame prediction)
• Plan multi-step actions to reach goals
• Detect when the rules of the environment suddenly change
Then they tested 517 humans vs the top models.
Humans dominated every category.
Even massive compute scaling barely helped.
The takeaway is wild:
Today’s AIs don’t understand environments they just pattern-match inside them. They don’t explore, revise beliefs, or experiment like humans do.
WorldTest might be the first benchmark that actually measures understanding, not memorization. And the gap it reveals isn’t small it’s the next grand challenge in AI cognition.
(Comment “Send” and I’ll DM you the paper 👇)

257
666
2,627
191,010

8 Nov 2025
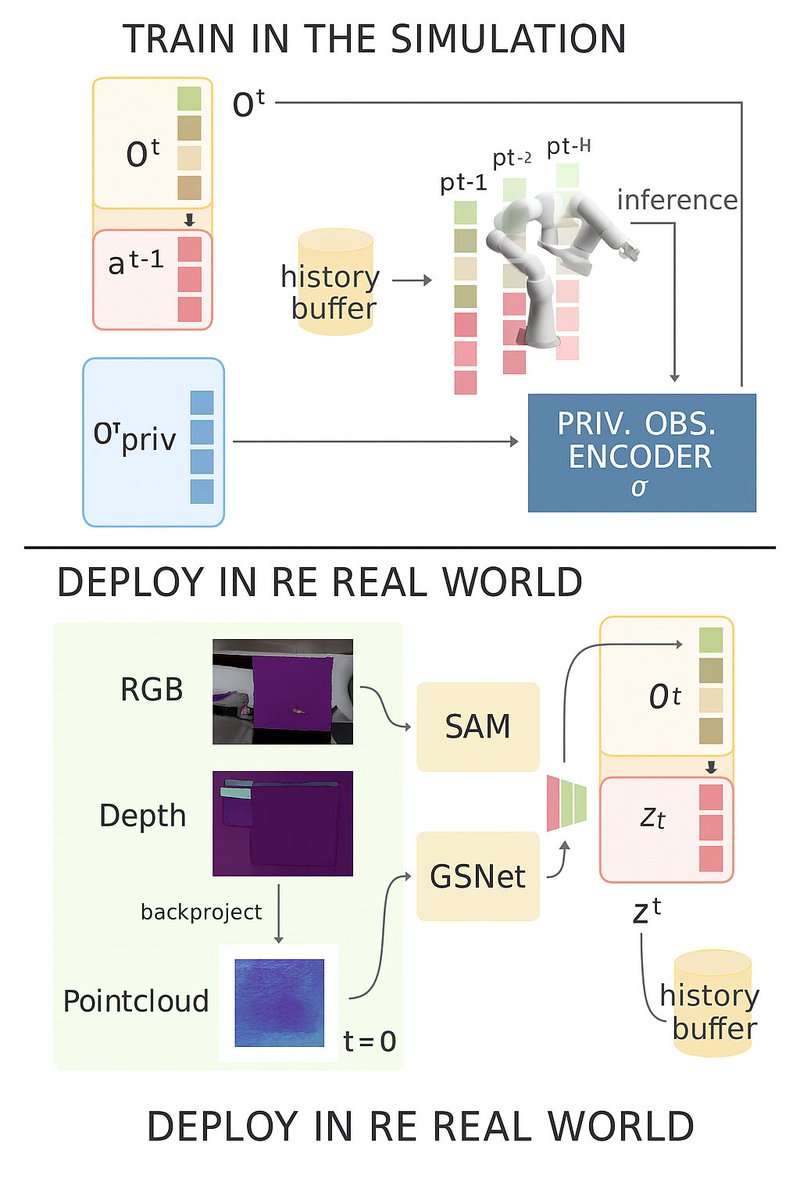
OpenMMLab provides a complete pipeline from model development to deployment, integrating over 20 specialized frameworks for detection, segmentation, pose estimation, tracking, and generation.
Through MMCV and MMDeploy, it enables modular training, optimization, and deployment across diverse computer vision tasks with scalability and production-ready performance.
6
2,444
6 Nov 2025
The next wave of AI compute is going to be wild. Colossus 2 is huge, but Hyperion and Fairwater sound like the start of a whole new era in large-scale model training.
4 Nov 2025

By 2026, xAI’s Colossus 2 is set to become the largest facility, matching the compute power of 1.4M H100 GPUs.
Soon after, Meta Hyperion and Microsoft Fairwater will take things to another level, scaling to 5M H100e GPUs each by late 2027 or early 2028.

1
8
2,878
6 Nov 2025
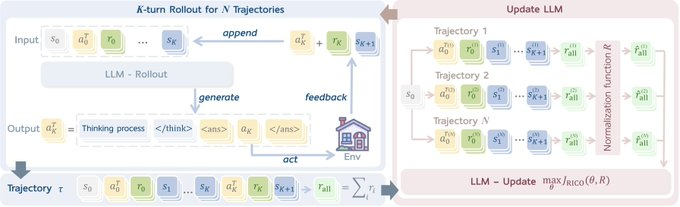
Great to see Search-R1 powered by the RAGEN codebase! The codebase is designed for easy reuse and readability.
Check it out for agent frameworks using simple RL recipes like DeepSeek R1: github.com/RAGEN/tree/main
5
4,017

Quantum computers work best in extremely cold and stable environments
Moon’s permanently shadowed craters have:
- Temperatures can drop below -200°C, which helps quantum bits (qubits) work without losing information
- Constant darkness means less energy fluctuations and more stability
- There’s almost no air, water, or electromagnetic noise, so quantum states stay stable longer
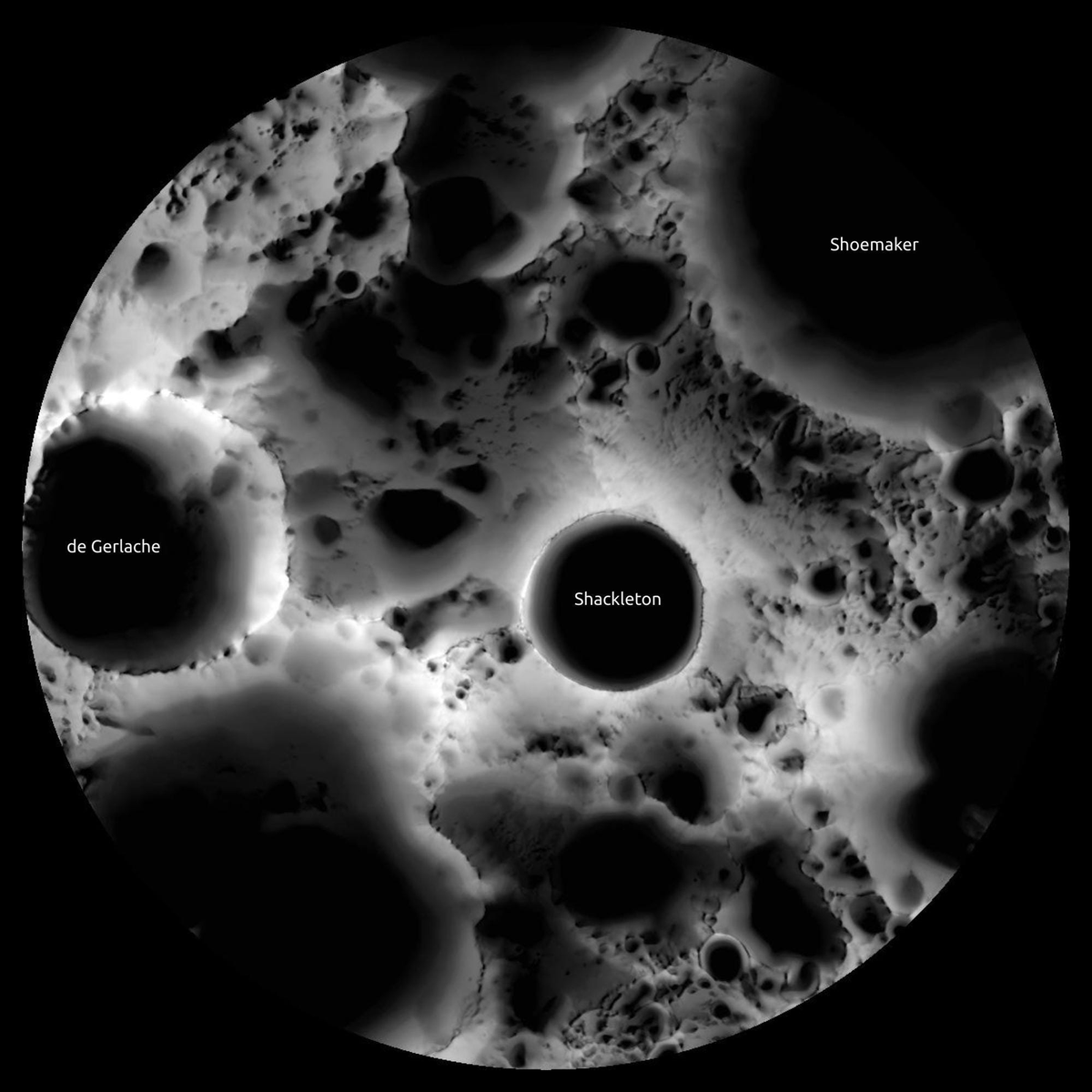

Quantum computing is best done in the permanently shadowed craters on the Moon
1,492
1,812
12,935
2,825,601
1 Nov 2025
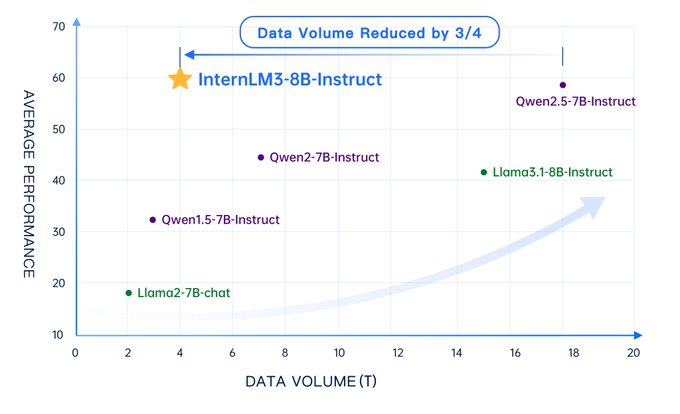
We're releasing InternLM3-8B-Instruct under the Apache 2.0 license, a powerful model that delivers strong reasoning and chat capabilities while achieving a significant cost reduction through training on just 4T tokens (a 75% saving).
5
6,062
27 Oct 2025
Leveraging the advanced infrastructure of OpenMMLab, we redefines performance and adaptability in deep learning workflows.
Through its cohesive architecture and finely tuned optimization layers, it achieves exceptional computational throughput and streamlined deployment empowering developers and researchers to build intelligent systems at scale with unmatched efficiency.
6
4,284
24 Oct 2025
Experience the next generation of video intelligence with InternVideo 2.5
A multimodal powerhouse engineered for precision and scale. Capable of analyzing videos six times longer than before and trained on over 300,000 hours of data, it redefines performance across cutting-edge domains like autonomous driving, virtual reality, and beyond. InternVideo 2.5 doesn’t just raise the bar it sets a new standard for video AI.
1
7
3,534
OpenMMLab (MMLAB) retweeted

22 Oct 2025
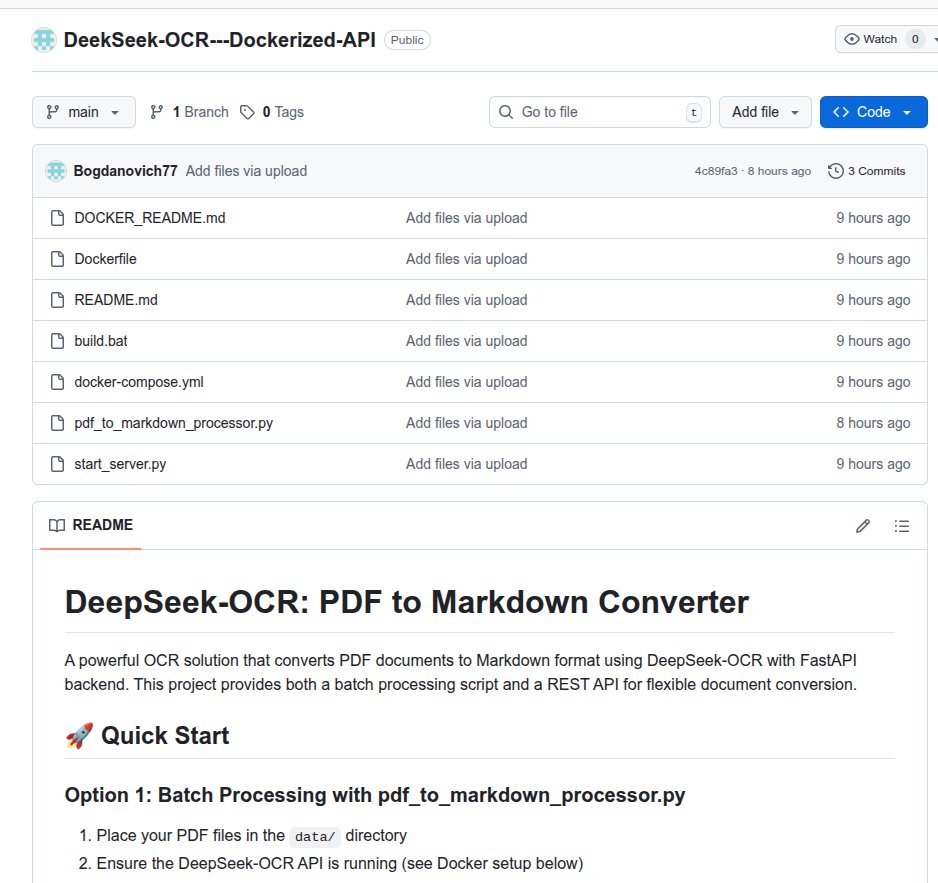
Converts PDF documents to Markdown format using DeepSeek-OCR with FastAPI backend.
This guy bave it 10000 pdfs to convert to markdown.
averaging less than 1 second per page.
Hardware - 1 x A6000 ADA on a Ryzen 1700 /w 32gb ram
Dockerized model with fastapi in a wsl environment.
21 Oct 2025
👨🔧 Inside the smart design of DeepSeek OCR
DeepSeek-OCR looks like just another OCR model at first glance, something that reads text from images. But it’s not just that.
What they really built is a new way for AI models to store and handle information.
Normally, when AI reads text, it uses text tokens (the units that LLMs process). Each word or part of a word becomes a token. When text gets long, the number of tokens explodes, and this makes everything slower and more expensive because the model’s computation cost grows roughly with the square of the number of tokens. That’s why even the most advanced models struggle with very long documents.
💡DeepSeek’s core idea was simple but revolutionary:
Instead of feeding an LLM thousands of text tokens, it turns long text into an image, encodes that image into a small set of vision tokens, then lets a decoder reconstruct the text.
The team asked a simple question, how many vision tokens are minimally needed to decode N text tokens, and they measured it end to end. The paper reports about 97% OCR precision when compressing text by 9–10x, and about 60% precision even at 20x.
This shows that dense visual representations can carry the same information far more efficiently than plain text tokens.
The engineering that makes this practical is a new encoder called DeepEncoder. It processes high resolution pages without blowing up memory by doing local window attention first, then a 16x convolutional downsampler, then global attention.
That serial design keeps activations small while aggressively cutting token count.
So why this is a big deal?
Context is the currency of LLMs, and it is expensive.
If visual tokens can represent past dialogue, documents, or code at 10x smaller size with high fidelity, you can keep far more context active, cut costs, and speed up inference.
The paper also sketches a practical “forgetting” mechanism, you can progressively downscale older context images so recent information stays sharp while older context becomes cheaper over time, which matches how human memory fades.
This makes long running assistants, RAG replacements, and whole codebase in context workflows much more realistic.

37
256
2,271
257,892
20 Oct 2025
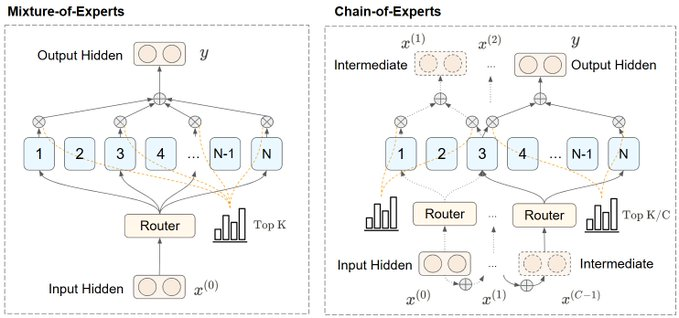
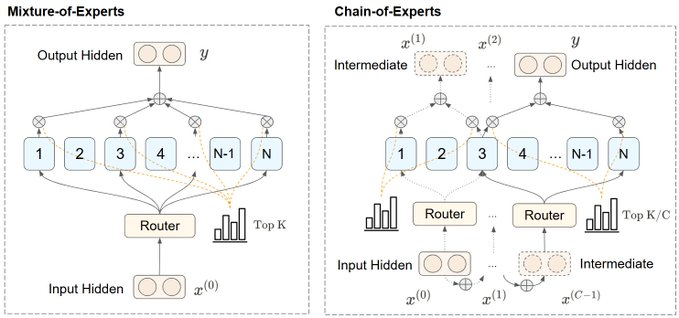
A significant breakthrough in MoE model optimization has been achieved with the introduction of Chain-of-Experts (CoE). This innovative technique offers a simple yet powerful way to enhance memory efficiency in DeepSeek-style models. By leveraging CoE, researchers were able to realize a 17.6% to 42% improvement in memory utilization, all while keeping training costs exceptionally low at $200.
This advancement represents a major step forward in making large-scale MoE models more accessible and efficient.
Code: github.com/ZihanWang314/coeC……
Blog: notion.so/Chain-of-Experts-U……
博客: notion.so/Chain-of-Experts-M……
2
2
7,243

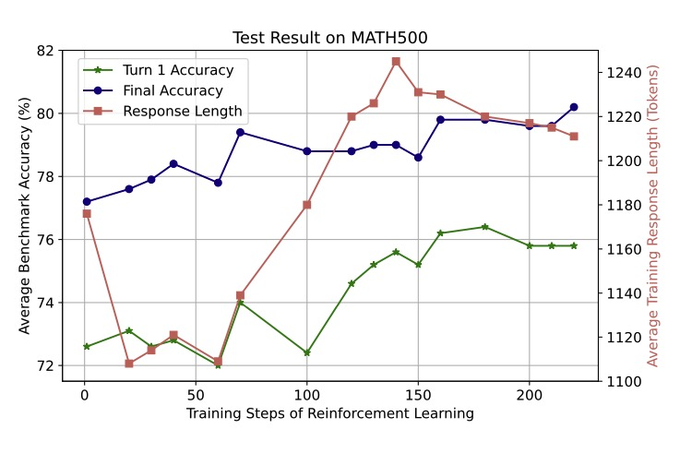
Meta just dropped this paper that spills the secret sauce of reinforcement learning (RL) on LLMs.
It lays out an RL recipe, uses 400,000 GPU hrs and posits a scaling law for performance with more compute in RL, like the classic pretraining scaling laws.
Must read for AI nerds.

44
209
1,312
119,700
15 Oct 2025
Open-source excellence! InternVL2.5, including our 78B model, is now available on @huggingface. InternVL2.5-78B is the first open #MLLM to achieve GPT-4o-level performance on MMMU.
2
6
2,430
13 Oct 2025
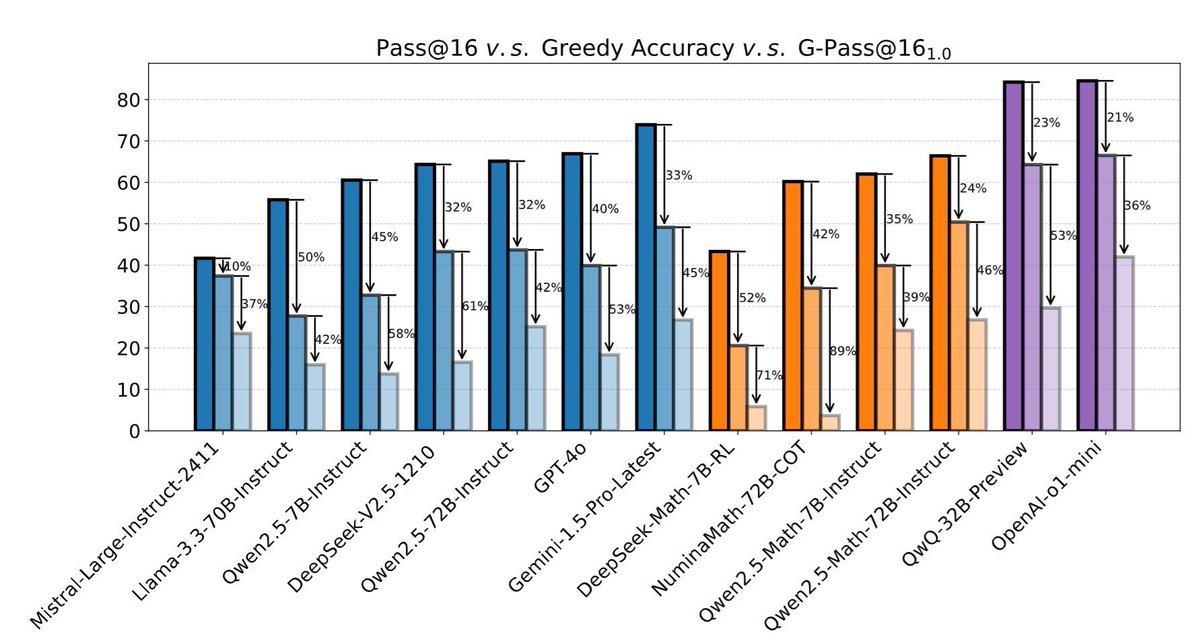
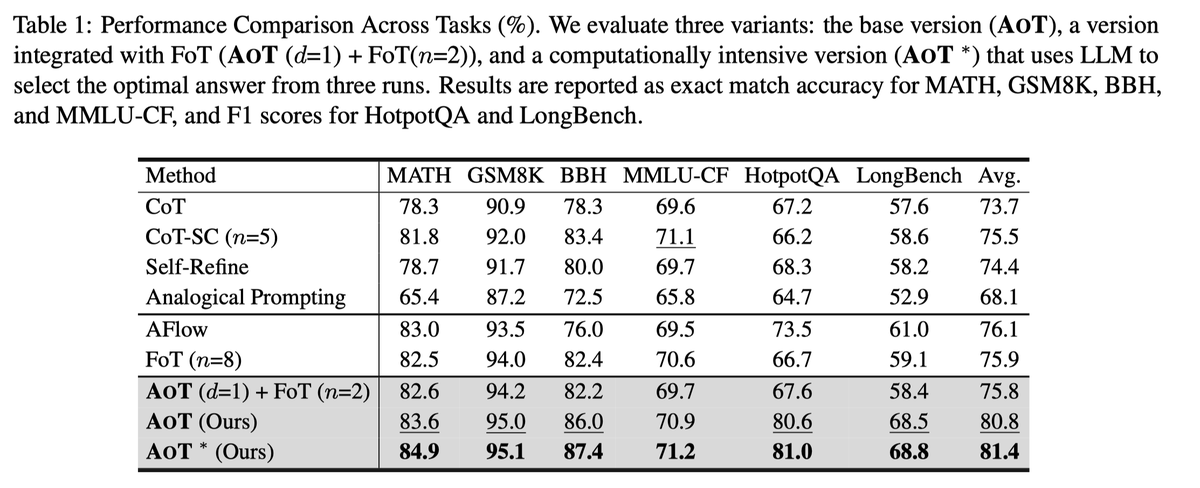
Current reasoning models struggle because they lack atomic thought, relying on bulky, full-history storage.
We've introduced Atoms of Thoughts (AOT), a simple plug-in that breaks down reasoning into independent units.
2
8
4,579
OpenMMLab (MMLAB) retweeted

12 Oct 2025
Ray Kurzweil:
"by roughly 2032 we will reach longevity escape velocity...
in the 2030s, robots the size of molecules will go into our brains, noninvasively, through the capillaries, and will connect our brains directly to the cloud...
by 2045, once we have fully merged with AI, our intelligence will no longer be constrained … it will expand a millionfold, this is what we call the singularity"
society is not ready, but the future is coming, fast
we are already on the exponential

275
306
2,218
314,875
OpenMMLab (MMLAB) retweeted

9 Oct 2025
markets move too fast and too chaotically for one brain. even an AI brain.
that’s why Edgen uses many: the multi-agent system
technical, fundamental, and momentum, thinking and agreeing together, in real time, on your favorite stock or token.
1,130
4,876
3,077
189,589