
131 Photos and videos
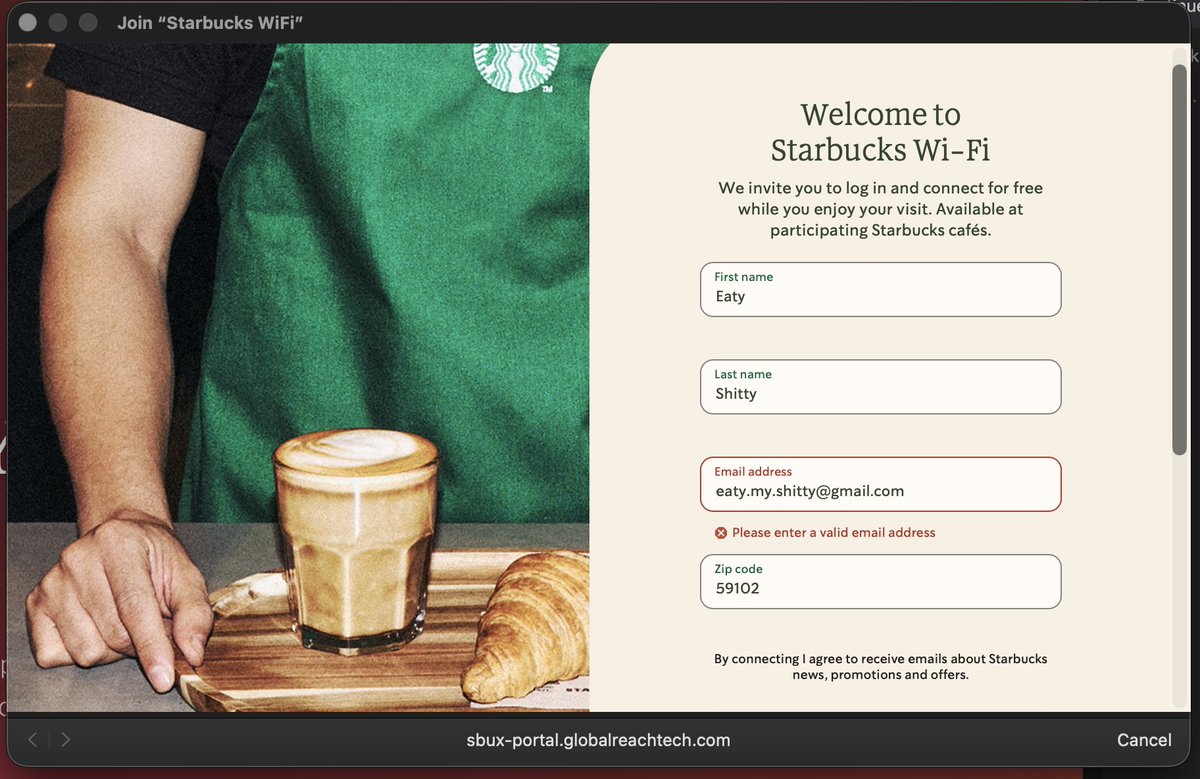











I asked the purple haired barista but they/them didn't know... StarStarbucks WiFi is a data-harvesting scam. ☕️🤡
They don't care if your email is real, they just want your MAC address to build a 'digital profile' of you. They aren't 'validating' anything... it’s just a lazy gatekeeper for burndt coffee.
Why are we okay with this? #Privacy #DataHarvesting #Starbucks
1
97
Oracle Over Coffee retweeted

30 Apr 2025
May Lineup is here!
⚡ @OraPubInc: Exclusive on RMAN & @MartinKlierDBA on Simple #AI Use Cases, a @SQL Tuning LVC
⚡ Query building w/ @nyoug_nyc
⚡ Live at @NoCOUG #Innovation Summit
⚡ Top 10 #SQLServer tips
⚡ Exadata X11 w/ @ashishray & @racdba
📅 bit.ly/3RGQK4g

3
3
112
Oracle Over Coffee retweeted

15 Feb 2025
Github 👨🔧: A Comprehensive Toolkit for High-Quality PDF Content Extraction
→ Integrates leading document parsing models for layout detection, formula detection, formula recognition, OCR, and table recognition.
→ Achieves high-quality parsing across diverse document types due to fine-tuning on varied document annotation data.
→ Provides comprehensive PDF evaluation benchmarks, aiding users in selecting suitable models based on performance results.
→ Includes pre-trained models for layout detection, formula detection, formula recognition, OCR, and table recognition.
→ Supports core document parsing tasks: layout detection, formula detection, formula recognition, OCR, and table recognition. Reading order functionality is planned.

5
67
328
25,573



Oracle Over Coffee retweeted

18 Nov 2024
ya hate to see it
18 Nov 2024

DOJ employees are already hiring criminal defense attorneys.
They saw what DOJ could do to innocent Americans.
Imagine what DOJ can do to actual criminals.
69
410
2,467
61,721

1 Oct 2024
I hope no one sends their crypto to these guys... Obviously fake AI video with a fake youtube page...
youtube.com/@tesla-uslive-20…
youtube.com/watch?v=RsJdiMQN…
50
Oracle Over Coffee retweeted

25 Mar 2024
We had a great turnout at the @UTOUG Training Days. Imagine the photo if we had all the attendees in this picture; the highway was shutdown and attendees came late. Lots of sessions had standing room audience. Many thanks to all the speakers! @oracleace #Oracle #OracleAI

2
8
391
9 Nov 2022
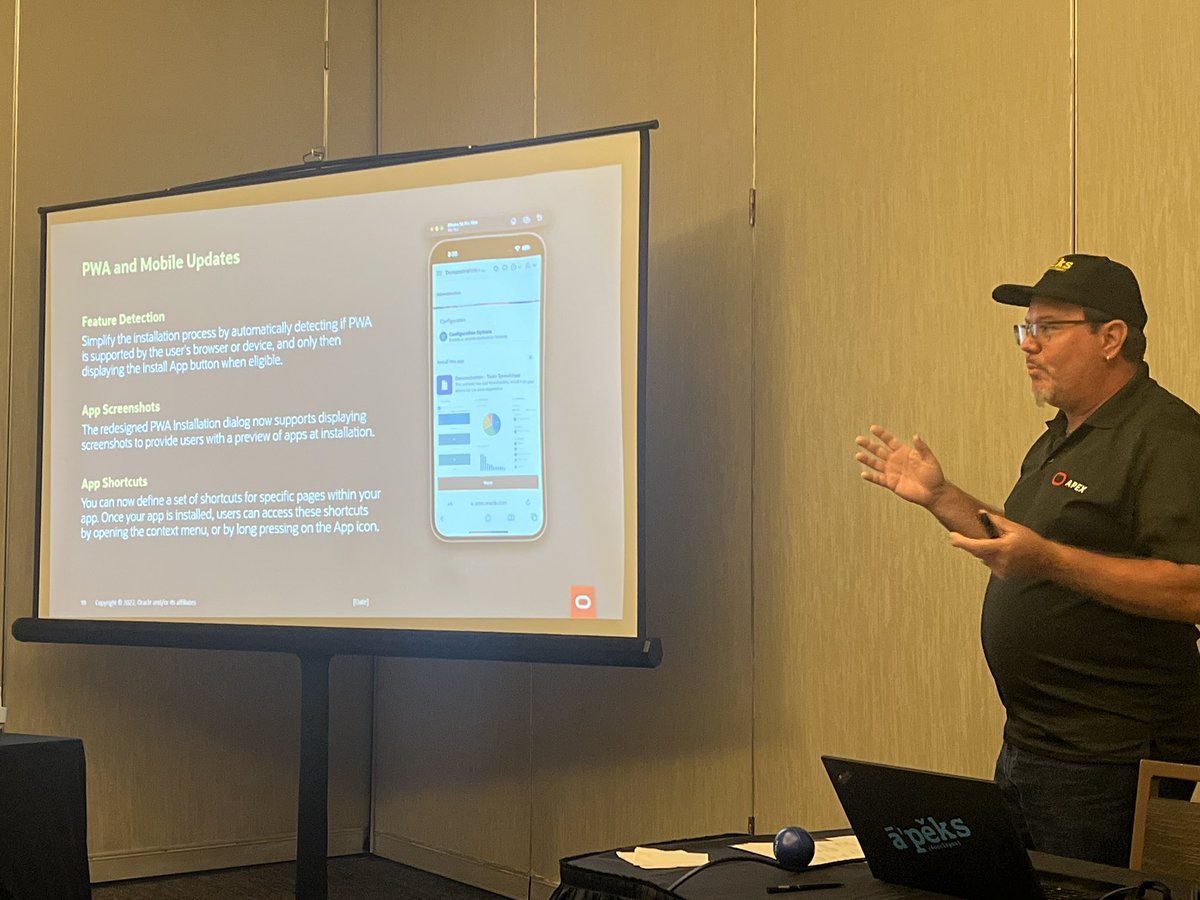
Jayson is showing the git backed sample apps for #orclapex @EastCoastOracle conference
1
5
21 Jun 2022
3
5
21 Jun 2022
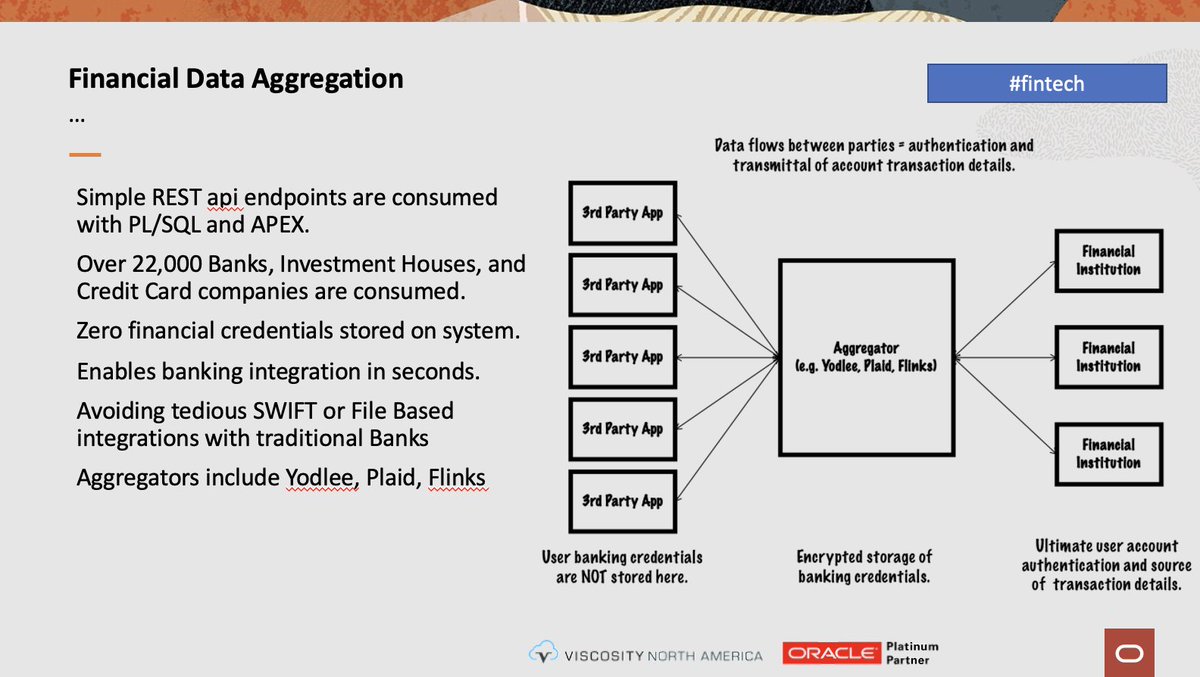
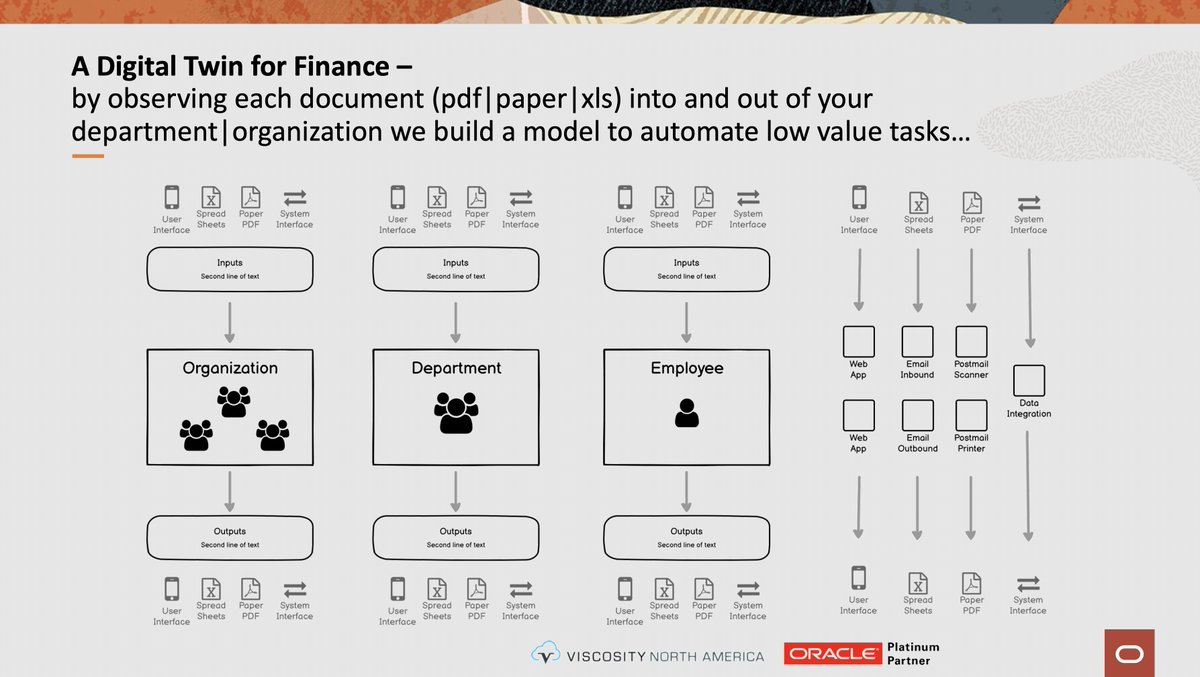
What is Financial Data Aggregation and how can we use #fintech to do smarter bank integrations? Tuesday June 21 10:15 am in Texas C "A Digital Twin for Finance" #kscope22 #orclapex #orclepm
@ViscosityNA
2
4
21 Jun 2022
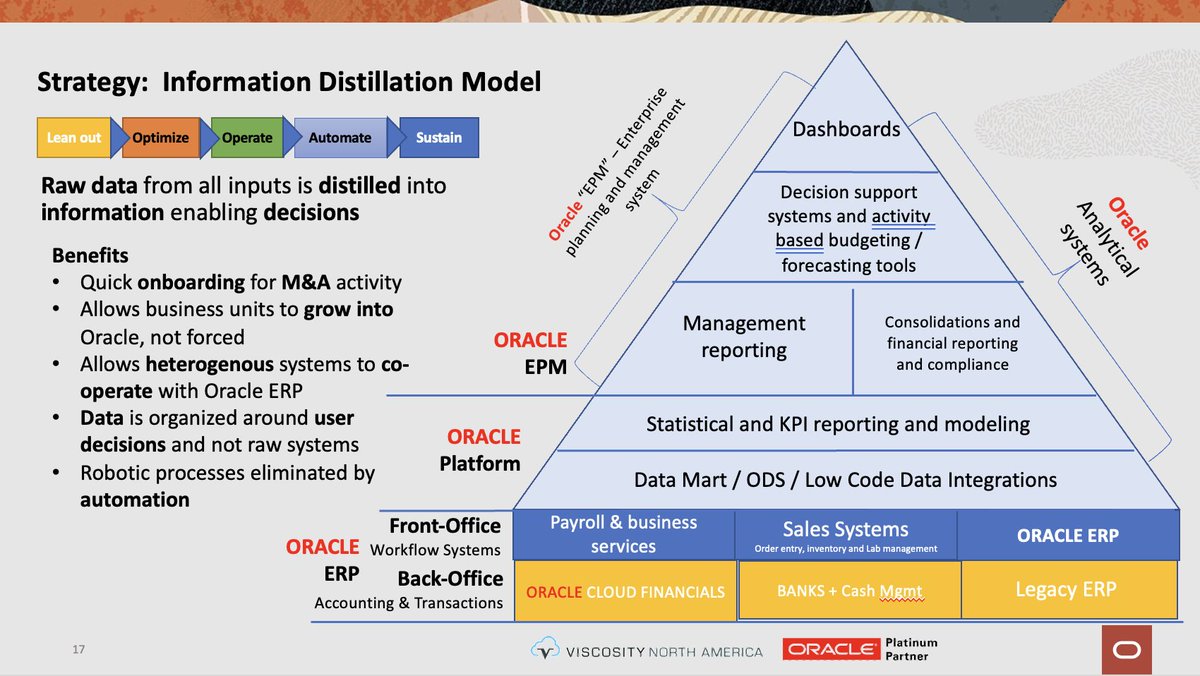
What is a data distillation model? See it perculate on Tuesday June 21 10:15 to 11:15 am in Texas C "A Digital Twin for Finance" #kscope22 #orclapex #orclepm
@ViscosityNA
2
8
21 Jun 2022
The best app is APEX, but a better app is no app at all, "meet the user where they live, paper, mobile, spreadsheets". Find out Tuesday June 21 10:15 to 11:15 am in Texas C "A Digital Twin for Finance" #kscope22 #orclapex #orclepm
@ViscosityNA
2
12
20 Jun 2022
What is a Digital Twin and how does it relate to APEX and EPM Cloud? Find out Tuesday June 21 10:15 to 11:15 am in Texas C "A Digital Twin for Finance" #kscope22 #orclapex #orclepm @ViscosityNA
1
13