
Joined May 2019
- Tweets 5,129
- Following 4,022
- Followers 1,168
- Likes 8,061
323 Photos and videos










Pinned Tweet

21 Jun 2024
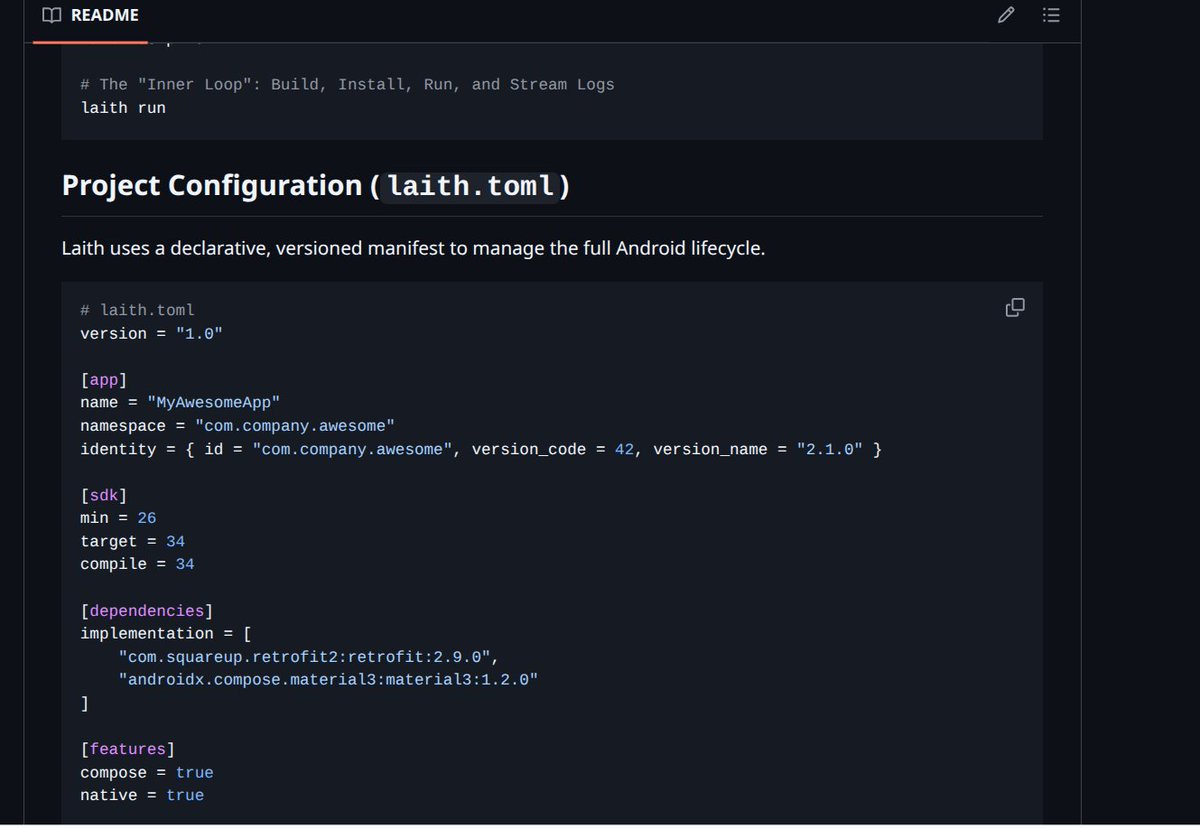
My book on SQLite internals, the first free and open book on the subject now comes up first on Google.
compileralchemy.com/books/sq…

1
18
229
17,951
AGI pilled for sure!

people in san francisco say “agi pilled” as a general term of art for describing people who reason about the future with any degree of analytical skill. it has been imo a good proxy for human capital generally
2
86
Based Yegge back at it. It good to shed the Ai Slop Hero skin off from time to time.

Twenty years ago, after joining Google, I published my old Amazon internal "drunken" blog rants all at once, almost fifty of them. They went super viral and led to me getting famous almost overnight, though nothing compared to five years later with the Platforms Rant. (When the Platforms Rant was making the rounds, my buddy Andrey Gubarev told me he'd just gone to visit his parents in Northern Siberia, and they only knew two things about Google, and I was one of them.)
But for the time, in 2006, my Drunken Blog Rants made a big splash.
To my lasting regret, @Werner made me take the best one down, six days after posting, because he felt it exposed too much proprietary Amazon information. And I complied, because he had asked soooo nicely, unlike their Head Legal Counsel who threatened to personally chew my balls off if I so much as hinted at recruitiing anyone from Amazon to Google.
Well, twenty years later, I went looking for it, and of course, Fable found it for me in an old zipfile inside another zipfile in Google Cloud Storage inside a CVS repository whose Attic happened to have a copy of every single original Amazon blog rant.
Look what they did to my boy Fable. That was uncalled for.
I re-read the post 20 years later, and it really was the best one. The world might have had GraphQL years earlier if they'd been able to read it. The post lays out with memorable examples exactly why Amazon needed something like GraphQL, even calling it a query language.
The article does expose a lot about how Amazon's databases and service APIs worked back in 2004, so it was reasonable to take it down. But had I known better, I would have just edited it.
The essay: yegge.ai/listings/services-a…
1
34
Jun 13
There is a difference between citizen and foreign national?


5
1
57
126,240
Jun 11
At this point it's before agents do. If we are using big guns to do the testing, users will also be using the big guns?
Jun 11

the goal is to find all bugs before the users do!
68
Jun 11
Pretty sure that's the wrong origin history
Jun 11

An engineer from Charlotte, North Carolina sat down in the spring of 2000 to write software for guided missile destroyers in the United States Navy. The ships needed a database that did not require a system administrator on board.
So he wrote one himself. 26 years later that database, SQLite, runs inside every iPhone on Earth, every Android phone, every Mac, every Windows machine, every major web browser, every airplane cockpit avionics system, and most of the cars built in the last decade. It is the most widely deployed software in human history. He still maintains it from his home in North Carolina.
His name is D. Richard Hipp. Most people call him Richard.
Here is the story, because the engineer behind the most replicated piece of code on the planet is a man almost nobody can name.
Richard was born in Charlotte on April 9, 1961. He grew up in the suburbs of Atlanta. He graduated from Stone Mountain High School in 1979 and went to Georgia Tech, where he earned both a bachelor's and a master's degree in electrical engineering by 1984. He spent three years at AT&T Bell Labs working in Unix and C. Then he went back to school at Duke University and earned a PhD in Computer Science in 1992. His dissertation was on spoken natural language dialog processing under Alan W. Biermann.
He could have stayed in academia. He told one interviewer the market for PhDs was saturated with better qualified candidates. He started a software consulting company instead. He married a musician and author named Ginger G. Wyrick in 1994 and renamed the firm Hipp, Wyrick and Company.
Then in 2000 he picked up a contract through General Dynamics to write software for the US Navy. The target was the Aegis class guided missile destroyer. The original system ran HP-UX with an IBM Informix database backend. The whole stack required a database administrator on board. The Navy did not want a database administrator on board. Richard's job was to make the database administrator unnecessary.
The design goals were simple. The database had to be self-contained. It had to run inside the application. It had to have zero configuration. It had to be transactional and reliable. It had to require no separate process. It had to be small.
On August 17, 2000 he released SQLite 1.0. He wrote it in C. The whole thing fit in less than a megabyte. The license he chose was the most extreme one possible. He released the source code into the public domain. No copyright. No royalties. No restrictions. Anyone could use it for anything forever.
The decision changed software history.
SQLite spread quietly. Mozilla adopted it for Firefox. Apple put it inside iOS. Google put it inside Android. Microsoft started shipping it inside Windows. Chrome, Safari, and Edge all use it. Photoshop uses it. Skype used it. Every major operating system you have ever touched runs SQLite somewhere underneath. The Airbus A350 uses it for flight software. Every Boeing 787 has SQLite onboard.
By 2026 SQLite was estimated to be running on more than 1 trillion devices. It is the most replicated piece of software ever written. Richard has personally turned down what is almost certainly hundreds of thousands of dollars in royalties over the past 26 years by keeping it public domain.
The SQLite team is tiny. Richard and a small group of core contributors. He maintains a separate version control system he wrote himself called Fossil. He maintains a parser generator he wrote himself called Lemon. He maintains a diagram language he wrote himself called Pikchr. He is a member of the Tcl core team and has been for over 25 years. He answers questions on Hacker News under the username SQLite.
The project's public commitment is to support SQLite through the year 2050.
A Christian engineer from North Carolina wrote a small database for missile destroyers and released it for free.
It is now running inside every device in your house.

52
Jun 11
Saw the one who invented the term saying AGI has been achieved.
Jun 11

When I was a kid I didn't realize, as is now obvious, that AGI would be a wide band rather than a sharp finish line. But if you'd shown me a version of ChatGPT that had been told to act like a human, I'd definitely have said that AI had been achieved.
30
Jun 11
Would have generated it based on the time they have to visit.
Jun 11

We are entering the age of just-in-time software. Some of my coworkers are visiting San Francisco this week, so I asked Claude Fable to design an extremely detailed HTML map of San Francisco so I can explain the city to them.
The HTML is wild. It has all the street names, their exact dimensions, the relief of the city, the fog, the sun exposure etc.
Everything it real. I was super surprised but it went and found the city's actual data, then built a cartographic engine around it. So I have:
- Every street from the SF Public Works centerline survey: 15,905 segments, 2,502 named streets, 54,989 surveyed vertices, with the official address ranges per block
- The relief from 14,151 municipal elevation contour points, interpolated into a 168,000-vertex terrain model
- 9,672 buildings with lidar-measured heights from an SF Planning study
- Every Muni Metro line, the cable cars and BART from the official GTFS feed: real route shapes, real 10-minute headways, real speeds. 76 little trams move on the map at their scheduled pace, and the K dims when it passes under 175 meters of Twin Peaks because it knows the tunnel portals (wtf!)
- Fog modeled as marine-layer advection over the terrain, calibrated on NREL satellite irradiance and a decade of ASOS weather observations.
Claude did totally overkilled stuff like the fog model's 50% line landed at longitude -122.437 which is... Divisadero Street (every San Franciscan knows the fog stops there)
The whole thing is one self-contained HTML file, 1.2 MB, with a WebGL engine. No libraries, no API calls, no network. It runs offline forever.
We talk about scaling and benchmarks all day. Sometimes the bitter lesson is simpler: give the machine real data and real verification loops, and it builds you the city.
I'm spending the evening exploring the map; it's too good!
28
It's so frontier that it does not have deepseek
Jun 9

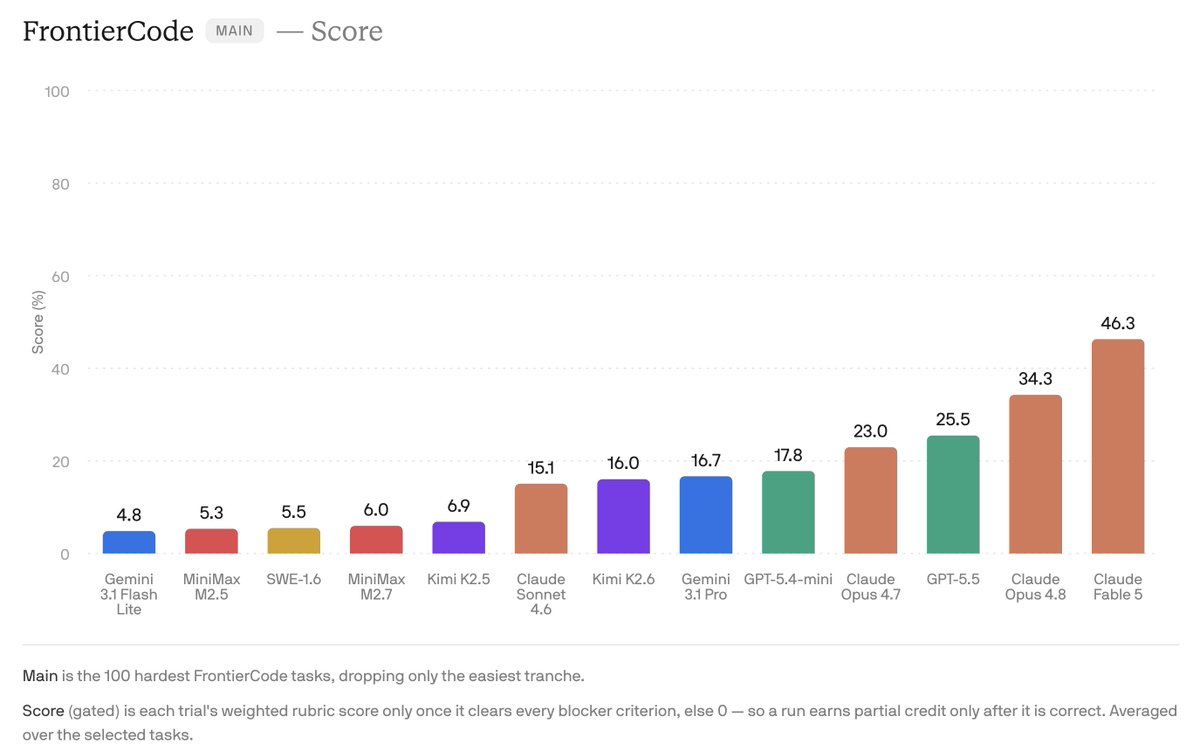
Claude Fable 5 is now available in Devin.
Fable 5 earns the #1 spot on FrontierCode, our benchmark for real-world engineering tasks that grades mergeability and quality:
16
Only saw this in the recent outrage.
Jun 8

Have people always loaded supercars on yachts in Monaco or is this a new thing?
31
Blue bottles are normally busy with people
Jun 8

I got pizza at Palo Alto once. It was a sweltering hot day. 1 pm. The only other person at the restaurant was a middle aged Indian guy, doomscrolling tiktok and having an entire pitcher of beer to himself
27
Everyone just echoing what Claude employees tell.
Jun 8
The real OGs prompted last in 2025 and now their agents are writing the loops for other agents. x.com/badlogicgames/status/2…
36
Yawn. Looks like a come-back of end to end memory networks.
Jun 6

Google has published a paper that might end the transformer era.
For the last 7 years, every major AI, ChatGPT, Claude, Gemini, has been built on the exact same architecture: The Transformer.
But Transformers have a fatal flaw.
To remember context, they have to process every single word against every other word. It’s called quadratic complexity. As your prompt gets longer, the compute cost explodes.
The alternative is the old-school RNN (Recurrent Neural Network). RNNs are incredibly cheap and fast, but they have a fixed memory size. If you give them a long document, they get amnesia.
Until today.
Google researchers published Memory Caching: RNNs with Growing Memory.
And it fixes the biggest bottleneck in AI.
Instead of an RNN having a fixed, rigid memory that constantly overwrites itself, Google gave it a "save" button.
The technique allows the RNN to cache checkpoints of its hidden states as it reads.
The memory capacity of the RNN can now dynamically grow as the sequence gets longer.
They built four different variants, including sparse selective mechanisms where the AI actively chooses exactly which checkpoints matter most.
The results rewrite the rules of efficiency.
On long-context understanding and recall-intensive tasks, these new Memory-Cached RNNs closed the gap with Transformers.
They achieved competitive accuracy without the explosive, quadratic compute cost. It perfectly bridges the gap between the cheap efficiency of an RNN and the massive capability of a Transformer.
We have spent billions scaling Transformers because we thought they were the only way an AI could remember a long conversation.
But Google just proved we don't need to process the whole history every single time.
We just needed a smarter cache.

20
gh: Abdur-RahmaanJ retweeted

Jun 6
In April, @mullvadnet provided sponsored DataPacket servers for GrapheneOS in Dallas and Frankfurt which each have 50Gbps peak bandwidth capacity. These now serve a large portion of the updates to GrapheneOS users and add a lot of capacity to our other services including our anycast authoritative DNS.
We also have sponsored servers from ReliableSite, Cherry Servers, Zare and Xenyth. There are a total of 8 sponsored servers where 7 are primarily update mirrors. The update mirror servers also serve our website and network services as a replacement for VPS instances for the locations we have them.
We host 2 anycast networks with our own ASN and IP space in order to self-host anycast DNS servers providing the authoritative DNS resolution for all of our services. Both IPv4 /24 blocks we use for anycast DNS were obtained for free via from ARIN via NRPM 4.10 along with the IPv6 space.
We host 2 anycast networks with our own ASN and IP space in order to self-host anycast DNS servers providing the authoritative DNS resolution for all of our services. Both IPv4 /24 blocks we use for anycast DNS were obtained for free via from ARIN via NRPM 4.10 along with the IPv6 space.
If one of our DNS servers goes down or fully loses connectivity, BGP routing across the internet will quickly adjust to send traffic to the other servers in the network. If a DNS resolver fails to get an answer from one of the anycast DNS networks, it will automatically fall back to the other one.
Our GeoDNS was recently massively improved via @ipinfo sponsoring us with free access to their standard GeoIP database. They use over 1300 probes to scan the internet instead of relying on very inaccurate/incomplete WHOIS/geofeed data. We nearly always use the right server thanks to this database.
We need additional dedicated servers for updates and other services in APAC where bandwidth is more expensive (Singapore, Sydney and Tokyo). We also need another server in North America to go along with our 2nd server from Cherry Servers in Amsterdam used to provide our opt-in geocoding service.
We have enough bandwidth for updates in Europe and North America to handle quite a lot of further userbase growth. We do need additional servers for other things. Several other server providers contacted us with sponsorship offers but we mainly need several APAC servers now which is more costly.
19
156
1,758
60,399
JapanTown has better hill views.
Jun 7

Just move to SF, it will change your life.
Go in debt if you have to.

53
I started a full commentary of the Transformer paper. I made a bet to myself: this should be the best resource on the whole internet to understand the paper in full, even to complete beginners.
It currently already covers self-attention with worked example and code. It covers each step only as much as we need to understand the paper.
It's a great opportunity to write beautiful maths and draw awesome ASCII art.
I remember trying everything to learn about transformers:
- loads of ml courses
- 3Blue1Brown vids
- loads of tutorials
- the annotated transformer
- ...
But, it either did not click or i did not remember clearly enough to explain. The best way according to me is to read the original paper which is clear once you understand it.
The Annotated Transformer is a annotated version of the paper with the full working code. But, this does not help with understanding the paper for people not familiar with the field.
Link in comment. Request to read and give feedback. This is an OpenSource commentary. Feel free to contribute.
2
1
797
Read here: compileralchemy.com/annotate…
51
Cause Dax yaps a lot

24
Click bait or what? Who does not know this?
Jun 5

A DEVELOPER PROVED THE REGEX YOU'VE WRITTEN A THOUSAND TIMES IS SECRETLY A COMPILER AND THAT ALMOST NO ONE WHO USES THEM HAS ANY IDEA WHAT ACTUALLY RUNS
36 minutes from Paul Wankadia, the engineer behind a regex engine that compiles your pattern straight down to raw machine code -- walking through what really happens between the slashes.
-> The moment it clicks, regex stops being magic punctuation you paste from Stack Overflow and becomes what it actually is: a tiny machine. Your pattern gets turned into a state machine, and that machine is what runs against every character of your text.
That one idea explains everything you never understood. Why one regex returns instantly and a nearly identical one hangs your whole server. Why some patterns are safe and others are a denial-of-service waiting to happen. It was never random -- it's whether the machine underneath is built well or badly.
Writing a regex was never the skill -> reading one is. And now that an AI agent hands you dense, clever patterns you'd never write yourself, the person who can see the machine underneath is the one who catches the one that takes down production at 3am.
Everyone copies regex and prays. This is the talk that ends the praying.
Save it. The next time a pattern "Just works," you'll actually know why ↓
43