
Beliefs subject to update.
Joined January 2008
- Tweets 15,375
- Following 57
- Followers 570
- Likes 6,073
49 Photos and videos










Pablo retweeted

3 Nov 2024
Ilya Sutskever’s 30 Essential Reads for Mastering AI!
“If you really learn all of these, you’ll know 90% of what matters today”
- Ilya Sutskever

21
300
2,312
304,385
Pablo retweeted

8 Feb 2024
🏅 To me, this feels more like the kind of neural model interpretability research we should be doing than much of the recent work on interpretability of transformer models.
7 Feb 2024

Emergence in LLMs is a mystery. Emergence in physics is linked to phase transitions. We identify a phase transition between semantic and positional learning in a toy model of dot-product attention. Very excited about this one! arxiv.org/pdf/2402.03902.pdf

4
54
402
65,570
Pablo retweeted

21 Nov 2023
The most clearest and crisp explanation, I've ever heard, of how large language models compress and capture a "world-model" in their weights simply by learning to predict the next word accurately.
Furthermore, how the raw power of these base models can then be tamed by teaching them to follow instructions from humans.
Source: youtu.be/Ckz8XA2hW84?si=XFzn…
60
514
3,569
970,914
Pablo retweeted

29 Sep 2023
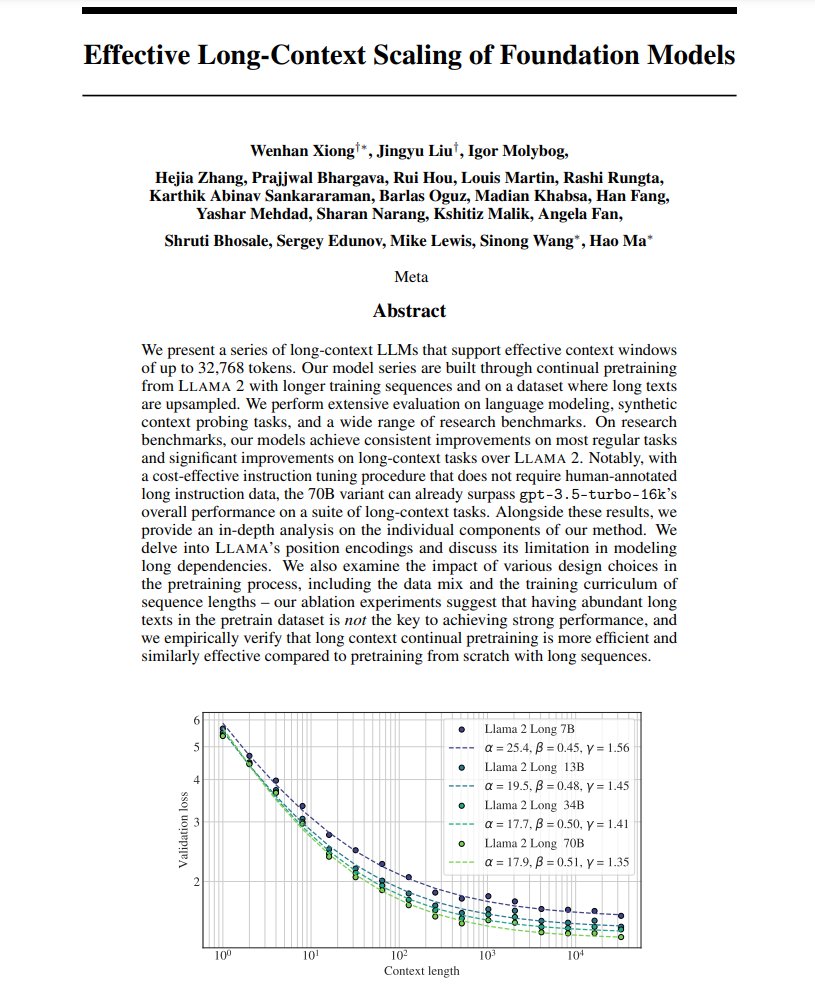
Effective Long-Context Scaling of Foundation Models
LLAMA 70B variant surpasses gpt-3.5-turbo-16k’s overall performance on a suite of long-context tasks
arxiv.org/abs/2309.16039
3
52
277
194,716
Pablo retweeted

29 Sep 2023
This was the biggest week for AI in history.
Massive developments from OpenAI, Sam Altman, Meta, Amazon, Tesla, Mistral AI, Perplexity, Pika, Windows Copilot, Whoop, The CIA, Google, Zapier, Microsoft, AlphaSense, and Hollywood.
Here's EVERYTHING you need to know (a thread):
93
723
3,675
1,527,985
Pablo retweeted

22 Sep 2023
What did I just watch?
Star Wars x AI
Mind blown, creative humans using AI to dream up a very different Star Wars.
By @douggypledger & @osymyso
170
1,609
6,678
1,201,845

Autonomous driving with Chain of Thought - autopilot thinking out loud in text!
LINGO-1 is the most interesting work I've read in autodriving for a while.
Before: perception -> driving action
After: perception -> textual reasoning -> action
LINGO-1 trains a video-language model that comments on the ongoing scene. You can ask it to explain its decisions ("why are you stopped?") and planning ("what are you gonna do next?"). The explicit reasoning step comes with key benefits:
- Explainability: driving models are no longer a mysterious blackbox that you pray for safety.
- Counterfactuals: it's able to imagine scenarios that are not in the training data, and reason through how to handle them correctly.
- Long-tail programming: there are soooo many edge cases in driving. It's impossible to have good data coverage on everything. Instead of collecting 1000s of examples to "neural program" a case, you can now have a human teacher write prompts to explain a handful of examples.
LINGO-1 is closely related to a few works in game AI:
- MineDojo (my team's work at NVIDIA, minedojo.org): learns a reward model that aligns Minecraft gameplay videos with their transcripts. The model, called "MineCLIP", is able to ground commentary text in the video pixels.
- Thought Cloning (@jeffclune): pixel -> language -> action loop in gridworlds.
63
447
2,158
552,736
Pablo retweeted

2 Sep 2023
Automorphic lets you fine tune LLMs incrementally, and that means you can evolve them much faster. It's like programming in a repl.
ycombinator.com/launches/JOw…
28
103
908
267,574
Pablo retweeted
27 Aug 2023
Want to start a startup doing eye-tracking? If so I'd be interested in funding it. A friend of mine has ALS and can only move his eyes. He has an eye-controlled keyboard, but it's not very good. Can you make him a better one?
364
286
2,939
809,545
Pablo retweeted

23 Aug 2023
New short course on Fine-tuning LLMs! Many developers are moving beyond only prompting, to also fine-tuning LLMs - that is, taking a pre-trained model and training it further on your own data, which can deliver superior results inexpensively. In this course, @realSharonZhou, CEO of Lamini (disclosure: I’m a minor shareholder) shows you how to recognize when fine-tuning can be help, and how to train an open-source LLM on your own data. I hope you enjoy the course! deeplearning.ai/short-course…
41
487
2,428
502,784
Pablo retweeted

16 Aug 2023
@stanfordnlp has released a framework for composing retrieval and language models, no need to re-invent the wheel when prompt engineering for knowledge heavy use cases, check out Demonstrate-Search-Predict framework for Python github.com/stanfordnlp/dspy
3
17
54
9,217
There're few who can deliver both great AI research and charismatic talks. OpenAI Chief Scientist @ilyasut is one of them.
I watched Ilya's lecture at Simons Institute, where he delved into why unsupervised learning works through the lens of compression.
Sharing my notes:
- Kolmogorov compressor is the theoretical shortest-length program that produces a dataset. SGD is a practical approximation of the Kolmogorov search that finds an implicit program embedded in the weights of a soft computer, i.e. big Transformers.
- Unsupervised learning is about computing the conditional Kolmogorov complexity of a target dataset given an unlabelled corpus, i.e. K(Y|X)
- Theory tells us that optimizing for K(X, Y), the joint complexity, is as good as K(Y|X). So simply throw all data into the mix, and "just compress everything".
- Joint compression is maximum likelihood over the giant concatenated dataset.
- Ilya cites iGPT, Chen et al. 2020, to illustrate the ideas. iGPT is an image compressor that learns to predict the next pixel using a 1D sequence model.
This is a phenomenal lecture, very accessible, and sometimes quite entertaining.
YouTube: youtube.com/watch?v=AKMuA_TV…
Lecture page: simons.berkeley.edu/talks/il…
53
416
2,667
822,176
Pablo retweeted
16 Aug 2023
We just released "Large Language Models with Semantic Search”, built with @cohere, and taught by @JayAlammar and @SerranoAcademy. Search is a key part of many applications. Say, you need to retrieve documents or products in response to a user query; how can LLMs help? You’ll learn about (i) Embeddings, to retrieve a collection of documents loosely related to a query, and (ii) LLM assisted re-ranking, to rank them precisely according to relevance. You’ll also go through code showing how to tie all this together to build a complete search system for retrieving relevant Wikipedia articles. Please check it out!
deeplearning.ai/short-course…
38
562
2,763
589,311
Pablo retweeted

24 Jul 2023
Tutorial: Running llama-2 with Quantisation! 🙏
@jamescalam made a crispy end to end video teaching how to setup llama-70B as a conversational agent.
It covers getting access, the frameworks and 4-bit quantisation:
youtube.com/watch?v=6iHVJyX2…
39
197
26,120
Pablo retweeted

24 Jul 2023
Want to fine-tune Llama2 for your use case on your data?
ICYMI—@scale_ai open-sourced LLM Engine, the easiest way to fine-tune and serve Llama2 and other open-source models
See 🧵👇
15
124
874
243,208
Pablo retweeted

22 Jul 2023
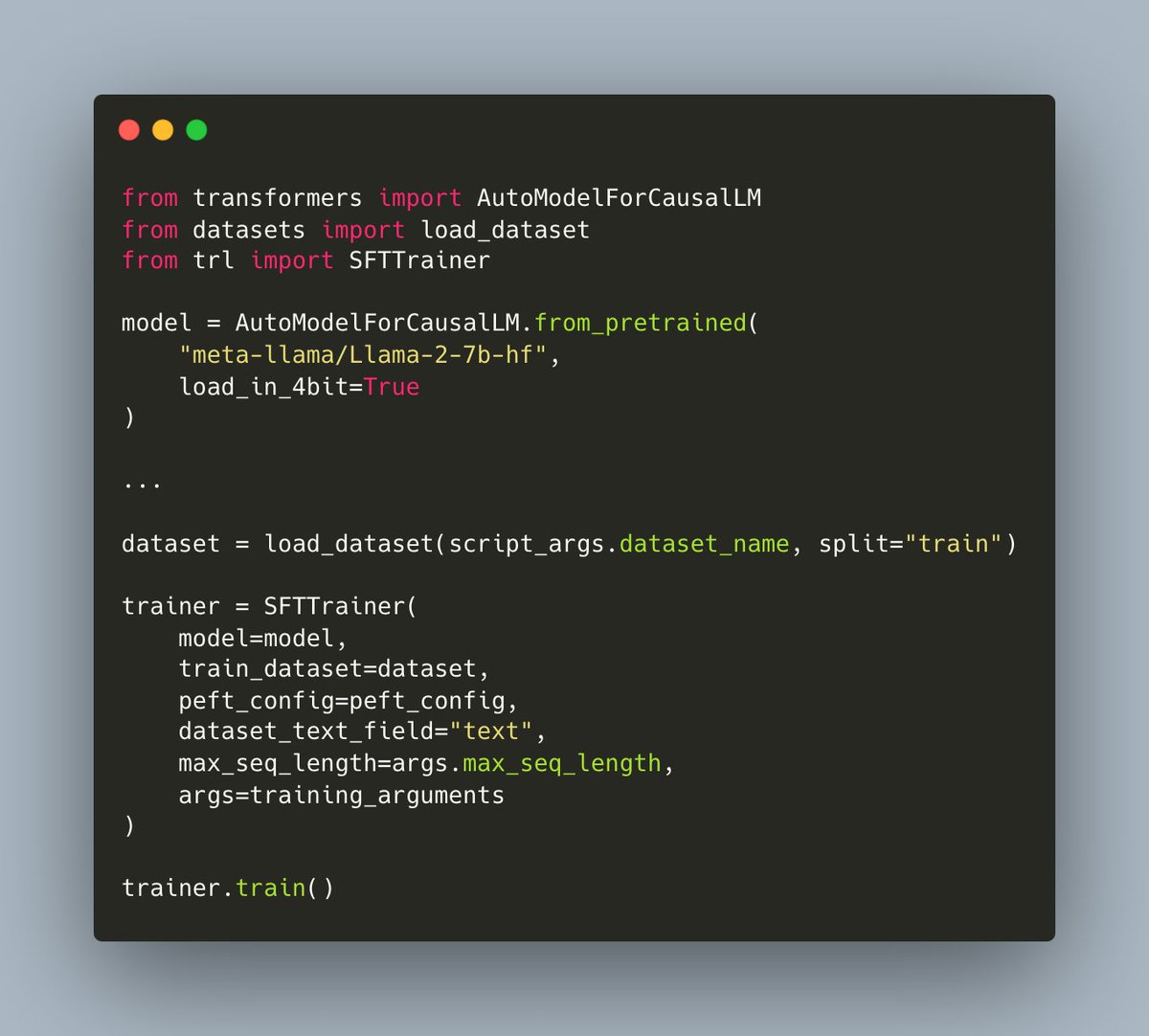
Usability is everything. Llama-2 can now be fine-tuned on your own data in just a few lines of code.
The script handles single/multi-gpu and can even be used to train the 70B model on a single A100 GPU by leveraging 4bit.
12
117
589
104,870
Pablo retweeted

19 Jul 2023
Llama 2: Now on Hugging Chat 🤗🦙
Try out the 70B Chat model for free with super fast inference, web search, and powered by open-source tools!
👉 hf.co/chat
34
426
1,691
403,549

Google Bard just changed the ChatGPT game with its massive multimodal upgrade - Image Recognition
It doesn't just recognize objects in the image, it can also extract texts and understand the image.
Here are 8 mind blowing examples:
79
491
2,742
1,286,073

You can now fine-tune an open-source LLM without writing a single line of code.
This is unprecedented.
No-code fine-tuning is a breakthrough in the open-source world, and it will help companies adopt AI at lightning speed.
Let me show you how you can do this.
I taught a model to recognize negative content on Twitter. Setting everything up took me 10 minutes. It took another 45 minutes to have the model ready.
If you aren't familiar with the term "fine-tuning," it’s the process we use to teach a model how to solve a specific task. Large Language Models have general knowledge but struggle to solve particular problems.
Fortunately, we can fine-tune these models and make them very good at solving specific tasks. In this example, that task is to analyze the sentiment of tweets.
But there’s a massive problem:
Fine-tuning a model is a complex, expensive process. It takes a lot of time, effort, and GPU computing. It's also hard to find experienced people who know how to do it.
The team @monsterapis built the first platform that offers no-code fine-tuning of open-source models, which changes everything. That’s what I’m using here.
Here is what you need to do:
1. Sign up here: monsterapi.ai/signup, and use the code SANTIAGO during your purchase to get an 80% discount.
2. Go to the FineTuning option and select your model. I'm using the Falcon 7B model, but you can pick any of the following options:
• Falcon 7B
• LLaMA 7B
• Open LLaMA 3B, 7B
• OPT 125M, 350M, 1.3B, 2.7B, 6.7B
• GPT J 6B
• Stable LM 3B, 7B
• GPT 2 XL
3. Select your task. I'm using "Text Classification" since we want to classify different tweets as Positive or Negative.
4. The last step is to select your dataset. I used a twitter-sentiment-analysis dataset from HuggingFace. They have data for almost anything you can think of, but you can also upload your own.
I didn't change any of the default hyperparameters, and 45 minutes later, I had my fine-tuned version of Falcon 7B ready to go! I spent 2,320 credits in the process, equivalent to $2.50. A fine-tuned state-of-the-art model for the price of a cup of coffee!
That’s one of the @monsterapis’ advantages: Besides not dealing with code, complexity, or hardware, their pricing is very competitive, thanks to their decentralized GPU platform.
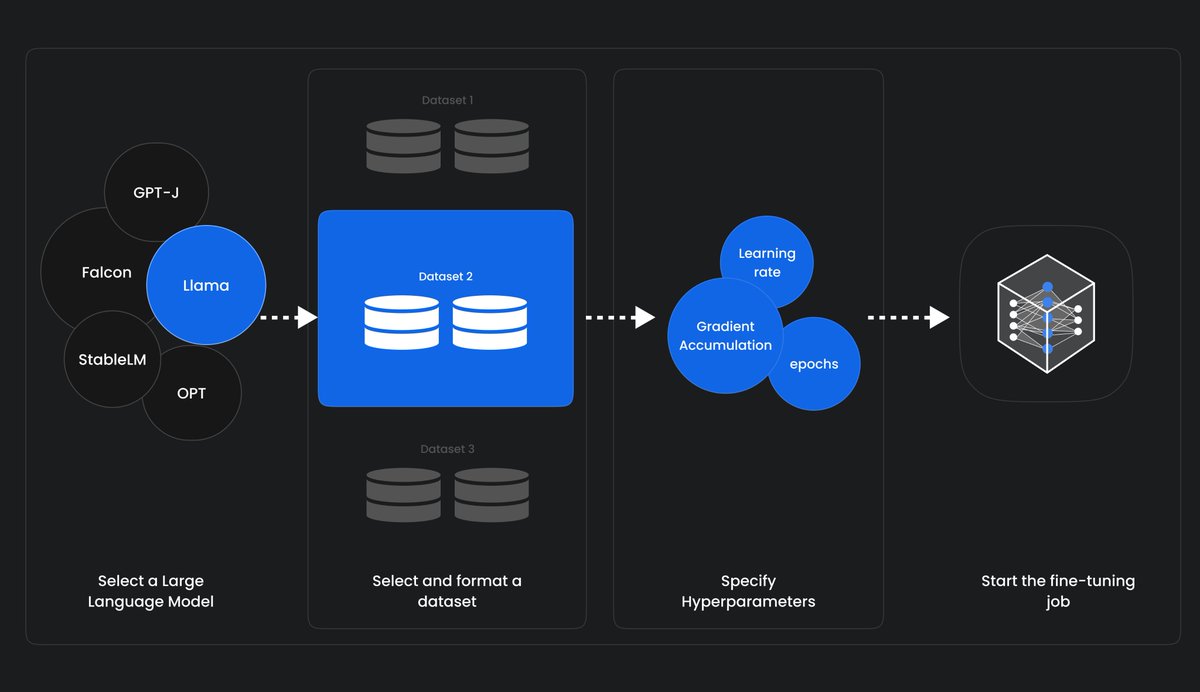
ALT Fine-tuning a Large Language Model diagram.
30
233
1,325
390,397