
Joined August 2021
- Tweets 133
- Following 1,164
- Followers 1,433
- Likes 301
60 Photos and videos




Pinned Tweet

1 May 2025
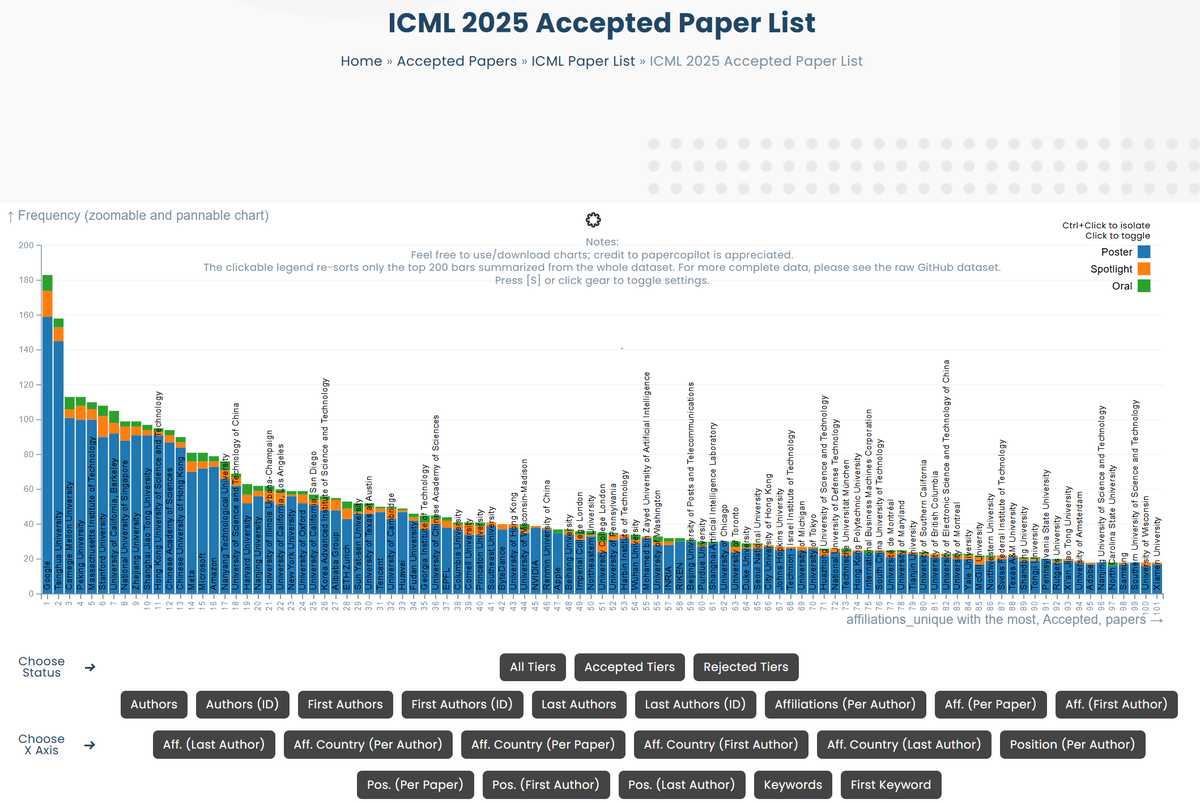
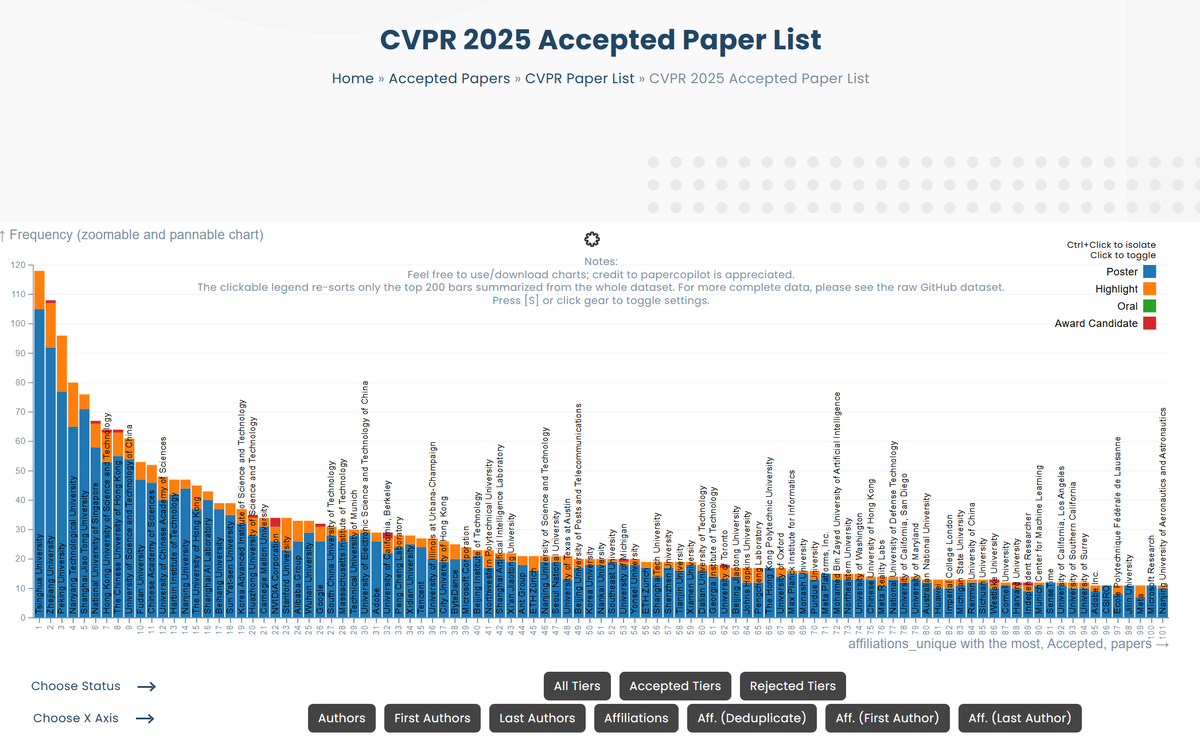
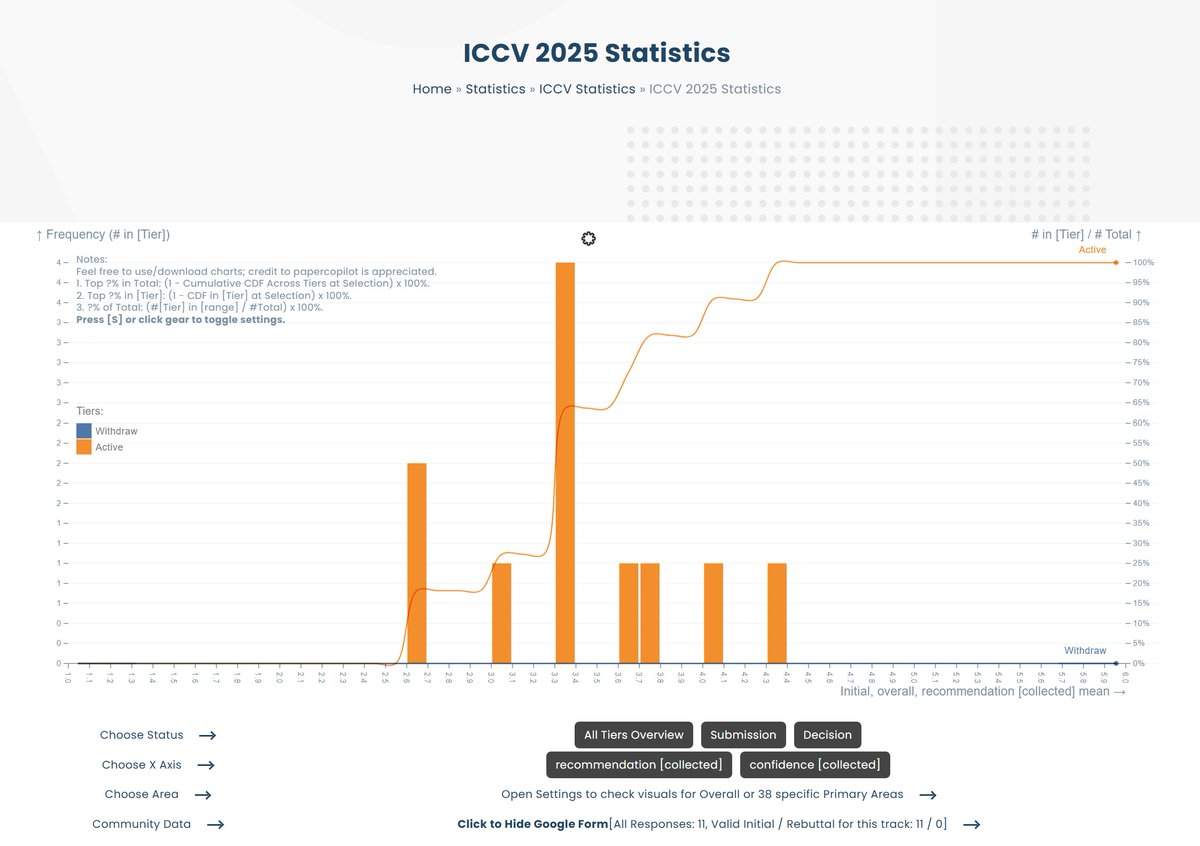
I'll bring @papercopilot to #ICML2025 and advocate for a more transparent and regulated peer review process. This position paper was accepted to the #ICML2025 Position Track. I’d love to hear your thoughts and discuss how we can better support the AI/ML community.
@openreviewnet @icmlconf
4
19
121
13,308
Paper Copilot @ ICLR 2026 retweeted

Jun 3
World models are moving beyond offline generation towards interactive, real-time experiences.
Introducing ⚡FlashDreams⚡: an open-source high-performance inference and serving library built for autoregressive world models:
🔥 Up to 3.10× faster LingBot-World inference
🔥 Up to 2.12× faster Self-Forcing inference
🔥 Up to 1.40× faster Wan2.1 inference
🔥 8 integrated models
🔥 Multi-GPU, streaming, low-latency serving
🔥 Agentic skills that teach you how to use it
FlashDreams is designed for a new generation of AI systems that continuously evolve over time while responding to user interactions. It powers applications across robotics, autonomous vehicle simulation, gaming, and virtual worlds.
Github: github.com/NVIDIA/flashdream…
Docs: nvidia.github.io/flashdreams
Research page: research.nvidia.com/labs/sil…
Join the #flashdreams Discord channel at discord.gg/yTdHDqFP
FlashDreams is also the runtime backbone behind NVIDIA OmniDreams (github.com/nv-tlabs/omni-dre…)
1/n
#AI #WorldModels #FastInference #PhysicalAI #OpenSource #NVIDIA
10
78
367
86,610

Paper Copilot @ ICLR 2026 retweeted

Jan 6
Holiday cooking finally ready to serve! 🥳
Introducing DFlash — speculative decoding with block diffusion.
🚀 6.2× lossless speedup on Qwen3-8B
⚡ 2.5× faster than EAGLE-3
Diffusion vs AR doesn’t have to be a fight.
At today’s stage:
• dLLMs = fast, highly parallel, but lossy
• AR LLMs = accurate, sequential, but slow
DFlash = diffusion drafts, AR verifies.
62
233
1,797
219,313
Paper Copilot @ ICLR 2026 retweeted

8 Dec 2025
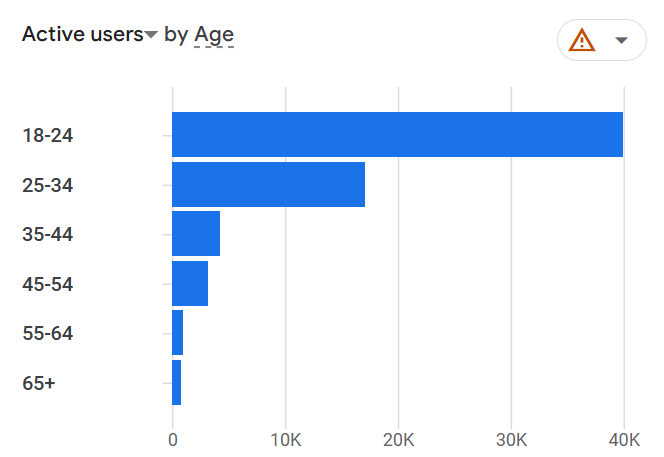
NeurIPS 2025 papers per 1 Million People
1. Singapore – 64.51
2. Switzerland – 22.13
3. Israel – 11.17
4. UAE – 9.47
5. UK – 7.50
6. US – 7.44
7. Denmark – 7.37
8. Australia – 7.31
9. Canada – 6.93
10. South Korea – 5.78
42
110
1,166
144,777
Paper Copilot @ ICLR 2026 retweeted

30 Nov 2025
Initial Analysis of OpenReview API Security Incident

10
32
104
46,408
Paper Copilot @ ICLR 2026 retweeted

30 Nov 2025
ICLR has placed OpenReview in a difficult position, so I want to offer a few words about the OpenReview team working behind the scenes.
OpenReview has long been operated at UMass Amherst as a non-profit organization founded by Andrew McCallum. Each year, Andrew must raise more than $2 million to support a 20-person team that provides essential infrastructure for most major conferences.
I once asked Andrew what might have been a naïve question: whether he had considered developing a business model for OpenReview, given its prominence and the seemingly obvious opportunities. He pushed back, explaining that everything he has done for OpenReview is driven by a commitment to serve and strengthen the academic community. He is willing to devote significant personal effort to ensure the platform remains freely accessible to all.
We should not blame such a brilliant and dedicated team for an accidental issue. Otherwise, fewer people would be willing to shoulder this kind of responsibility in the future.
Deep respect to the OpenReview team! I’m grateful for their work and happy to support in any way!
27
136
988
178,353
Paper Copilot @ ICLR 2026 retweeted

27 Nov 2025
The ICLR leak is a disaster, but let’s talk about how to actually save the Peer Review process.
The Fix: Ending anonymity for irresponsible reviewers.
ICLR maintains high submission quality (at least in early years) because rejected papers are public—authors fear the reputation hit. Why don't we hold reviewers to the same standard?
If a review is fundamentally irresponsible (after confirming by ICLR Program Committee), the reviewer should lose the privilege of anonymity.
• Good review = Anonymous (if desired).
• "Rejected" review = Public Name.
Should add a tab to irresponsible reviewers, similar to publicly showing the rejected papers
openreview.net/group?id=ICLR…
We need symmetry. Authors face consequences for low quality submissions. Reviewers should too. @iclr_conf
27 Nov 2025


27
13
271
66,322
28 Nov 2025
We archived the ICLR 2024/2025/2026 daily scores for every paper (No reviewer identities are collected or disclosed). Regardless of whether score rollbacks occur or not, I think it’s time to release them publicly for the entire community. We hope this release can support the community through this hard time and contribute to greater transparency and understanding. #ICLR2026
Our Position: arxiv.org/abs/2502.00874
Data release: arxiv.org/abs/2510.13201
Raw data: github.com/jingyangcarl/open…
@iclr_conf @openreviewnet
27 Nov 2025
1
13
189
44,772
Paper Copilot @ ICLR 2026 retweeted

27 Nov 2025
This is crazy. Please do not use, share and/or exploit any leaked information due to the bug of the openreview website. The anonymous reviewers are our friends who spent time and efforts to help improve our works, not our enemies.
27 Nov 2025
7
22
296
50,773

Paper Copilot @ ICLR 2026 retweeted

24 Nov 2025
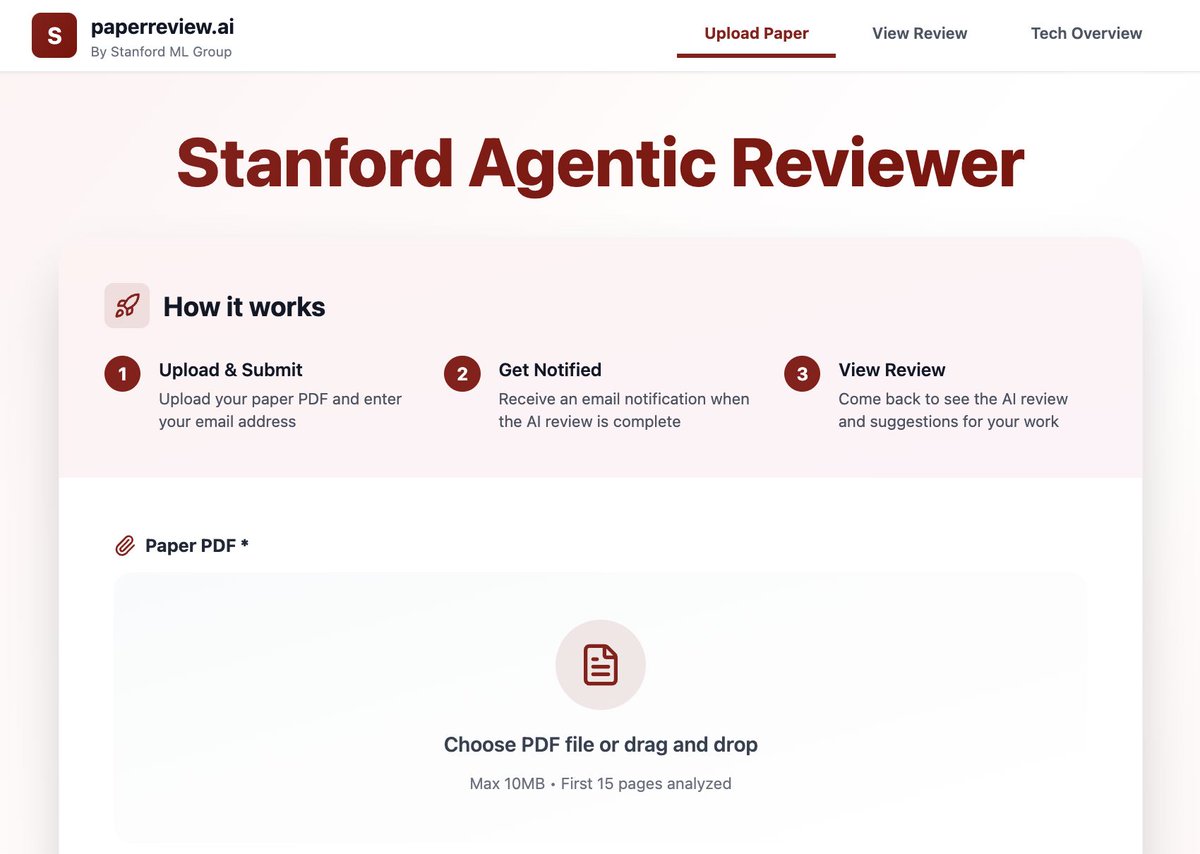
Releasing a new "Agentic Reviewer" for research papers. I started coding this as a weekend project, and @jyx_su made it much better.
I was inspired by a student who had a paper rejected 6 times over 3 years. Their feedback loop -- waiting ~6 months for feedback each time -- was painfully slow. We wanted to see if an agentic workflow can help researchers iterate faster.
When we trained the system on ICLR 2025 reviews and measured Spearman correlation (higher is better) on the test set:
- Correlation between two human reviewers: 0.41
- Correlation between AI and a human reviewer: 0.42
This suggests agentic reviewing is approaching human-level performance.
The agent grounds its feedback by searching arXiv, so it works best in fields like AI where research is freely published there. It’s an experimental tool, but I hope it helps you with your research.
Check it out here: paperreview.ai
248
1,064
6,273
1,127,334
Paper Copilot @ ICLR 2026 retweeted

8 Nov 2025
Thrilled that our paper received the only perfect score at NeurIPS this year.
Huge thanks to my collaborators and the reviewers. See you in San Diego!
limit-of-rlvr.github.io
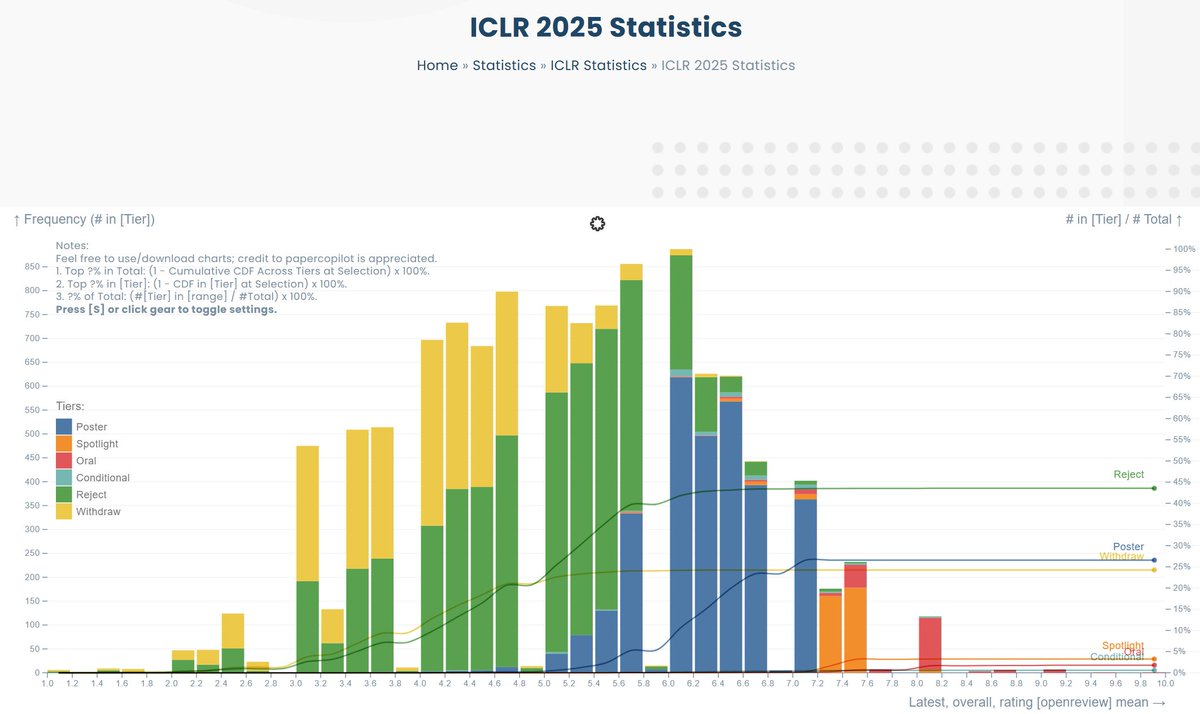
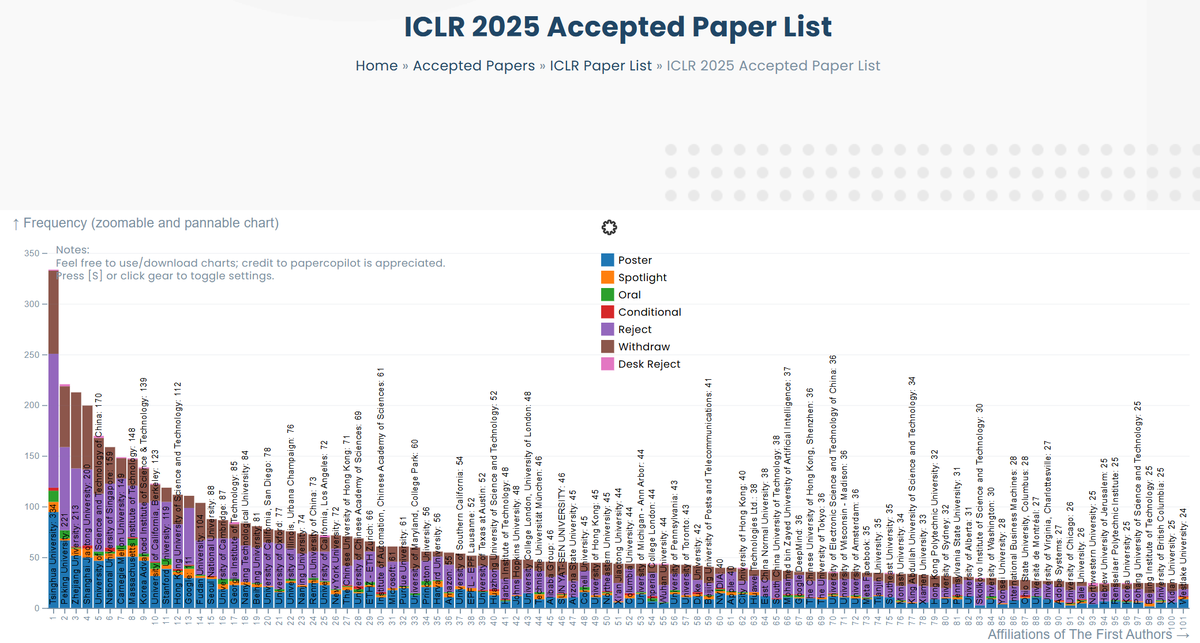
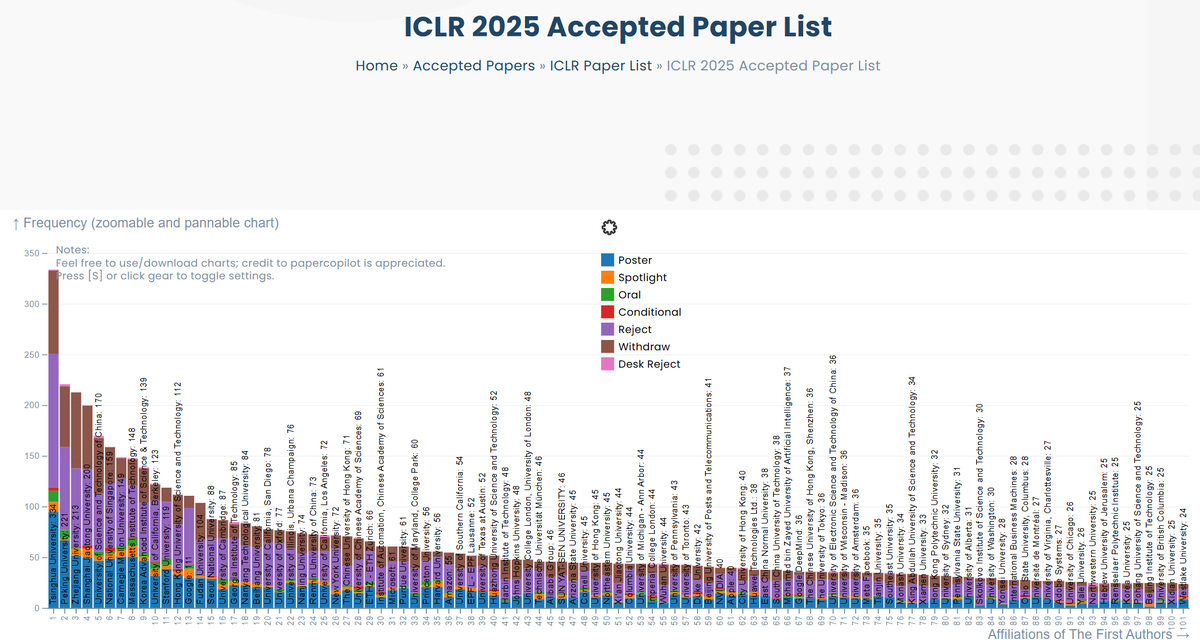
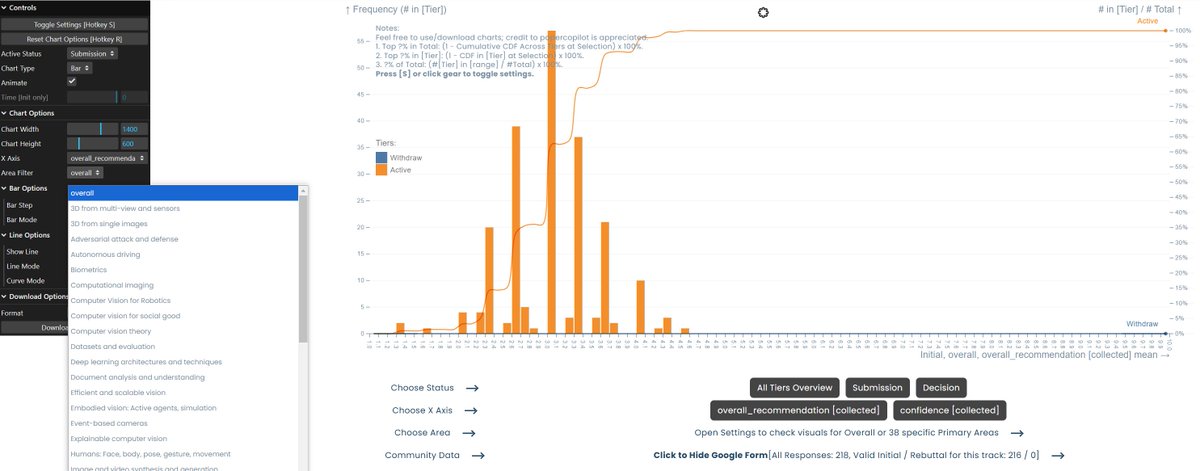
papercopilot.com/statistics/…
credit to @papercopilot
22
57
734
519,836
15 Oct 2025
Thanks for using the Paper Copilot data — I’m really happy to see it being used to help build a better peer review ecosystem. @yuz9yuz @FlyPig23 @yian_yin, your work is super inspiring! I'm also currently working with @Stanford and @Cambridge_Uni on releasing the temporal daily review data for ICLR 2024/2025 (and hopefully 2026 soon) to the community, so we can continue improving peer review for everyone.

"Can submission authors rely on online discussions of review scores to estimate their percentile?" A recent study led by my student Hangxiao Zhu @FlyPig23, in collaboration with Prof. Yian Yin @yian_yin from Cornell, gives a clear 𝐍𝐄𝐆𝐀𝐓𝐈𝐕𝐄 answer!
(1/n)

2
9
3,226

Paper Copilot @ ICLR 2026 retweeted
9 Aug 2025
Genie3 is like magic! Curious the best way to add viewpoint conditioning signal into transformer?
Check this out 👉 liruilong.cn/prope/
8 Aug 2025

Another one. Already a powerful painting, but moving around it yourself gives a totally different feeling.
Jacques Louis David's "The Death of Socrates" => #Genie3
1
4
67
7,675

GPT-5 is here.
Rolling out to everyone starting today.
openai.com/gpt-5/
4,306
6,181
32,008
5,096,352
Our open models are here.
Both of them.
openai.com/open-models
1,121
3,100
19,309
6,719,542
Paper Copilot @ ICLR 2026 retweeted

1 Aug 2025
"Cameras as Relative Positional Encoding"
TLDR: comparison for conditioning transformers on cameras: token-level raymap, attention-level relative pose encodings, a (new) relative encoding Projective Positional Encoding -> camera frustums, (int|ext)insics for relative pos encoding
2
52
454
17,811