
site reliability engineer @airtelindia
Joined January 2016
- Tweets 492
- Following 485
- Followers 79
- Likes 794
19 Photos and videos








Pavitra Bhagat retweeted

9 Dec 2025
> How to build a multi-agent service and deploy it to production on @railway
We'll cover security, scaling, and APIs. Agents persist sessions, traces, memory and knowledge (embeddings) in a postgres database.
You'll be able to interact with your production system like this 👇
6
17
128
9,993
Pavitra Bhagat retweeted
29 Oct 2025
Big kudos to LangChain!
We see $ as an accelerant, but only if the direction is right (velocity = direction speed). Raising too early would have forced us to scale the wrong business model, which would have been catastrophic later down the line.
We started with the same model as LangSmith (monitoring solution) in Agno v1, but realized it wasn't the best way to serve our users (wrong architecture).
AgentOS (in my view) is the right architecture for agentic systems, and now the direction's locked in.
2
5
14
917
Pavitra Bhagat retweeted

5 Sep 2025
serverlabs[.]com is on sale. Does anyone have spare $20K?
3
1
20
6,697
A beautiful Agent UI 👇
22 Aug 2025

Add Beautiful UI to interact with your AI agents (Step by Step Guide):
1
2
7
1,445
Pavitra Bhagat retweeted

3 Jun 2025
Running a distributed system sounds great, until one node starts doing all the heavy lifting. That's what hot shards are. But why do they occur?
Hot shards occur when a specific node of a distributed database becomes overloaded and has to work significantly harder than other parts to handle the workload, leading to slowdowns and bottlenecks. Here are some common reasons for it
When I used to manage a production ElasticSearch cluster on raw EC2 virtual machines, hot shards were a big pain, and here are the reasons that were the root cause 80% of the time
- we did not follow the best practices
- we wrote highly inefficient queries
- we chose inefficient routing (partitioning) key
- unexpected surges happened due to performance marketing
- massive stop-the-world GC pauses, accumulating the backlog
Key things we did to address this were to have high observability in place, along with spending time knowing the internals and best practices. This looked counter-productive at first, but it turned out to be the best decision in the long run.
Note: although I mentioned these points w.r.t ElasticSearch, they hold true for almost all distributed databases that exist because the underlying limitations of hardware and software remain the same.
6
4
216
10,005
Pavitra Bhagat retweeted

17 Jan 2025
This is the future of education.
135
855
5,191
665,598
Pavitra Bhagat retweeted

12 Jul 2024
Youtube Prankster Wins the European Elections
8
52
720
88,261
Pavitra Bhagat retweeted
7 Jul 2024
I agree this is a common problem that I witnessed long ago when developers' PCs were faster than prod servers (and they did not test beyond one user per machine). For HAProxy we have small machines to test on (MIPS 500 MHz with 256 MB RAM etc) and I insist that it works there!
3
26
7,693
Pavitra Bhagat retweeted

15 Jun 2024
I’m 37.
If you're still in your 20's, read this:
273
7,700
48,950
9,797,419
Pavitra Bhagat retweeted

23 Apr 2024
Skipping basics and coming back to it when we hit a dead end is also known as Dev Karma.
7
4
47
3,531

14 Apr 2024
The main difference between HTTP/1.1 and HTTP/2 is that HTTP/2 uses multiplexing and header compression to significantly improve the efficiency and speed of web page loading compared to the older, more linear request/response model of HTTP/1.1.
40
Pavitra Bhagat retweeted

26 Feb 2024
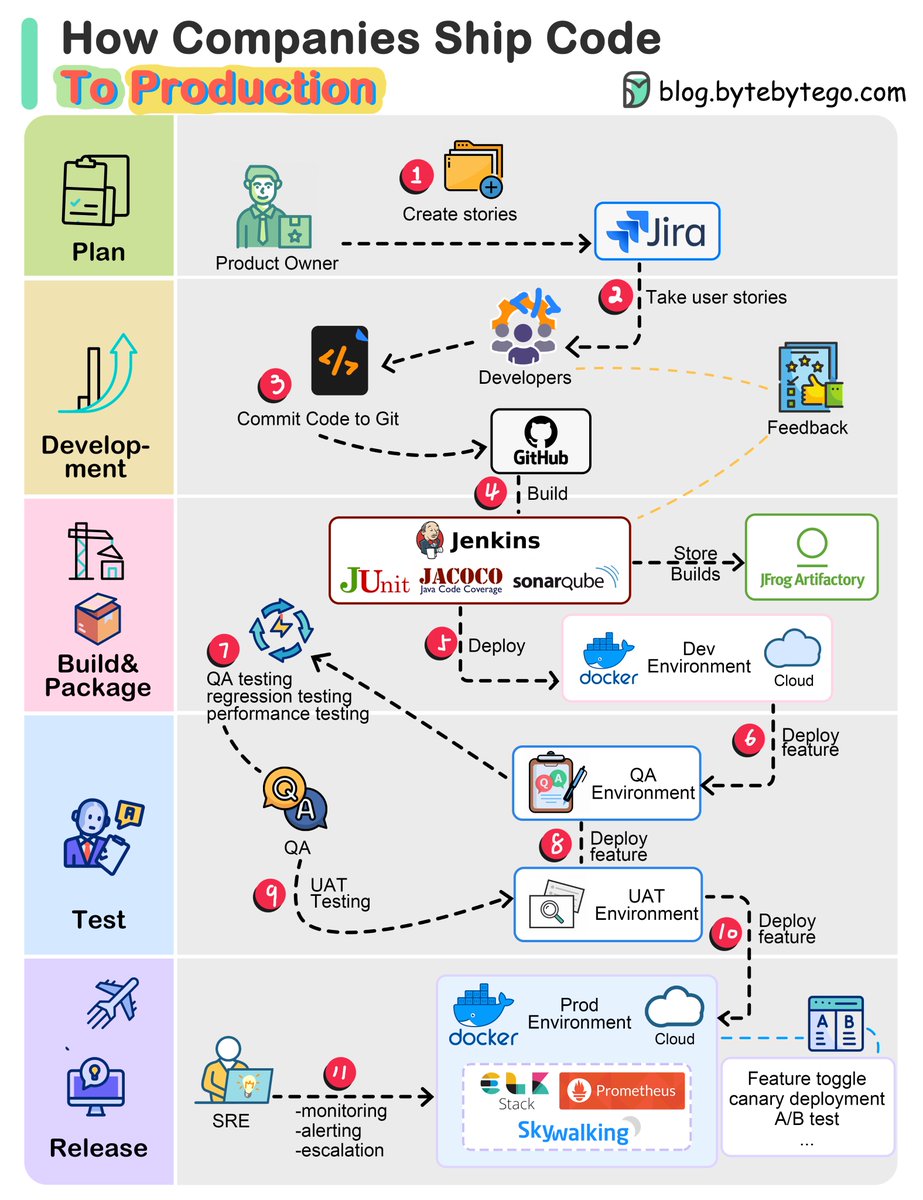
How do companies ship code to production?
The diagram below illustrates the typical workflow.
Step 1: The process starts with a product owner creating user stories based on requirements.
Step 2: The dev team picks up the user stories from the backlog and puts them into a sprint for a two-week dev cycle.
Step 3: The developers commit source code into the code repository Git.
Step 4: A build is triggered in Jenkins. The source code must pass unit tests, code coverage threshold, and gates in SonarQube.
Step 5: Once the build is successful, the build is stored in artifactory. Then the build is deployed into the dev environment.
Step 6: There might be multiple dev teams working on different features. The features need to be tested independently, so they are deployed to QA1 and QA2.
Step 7: The QA team picks up the new QA environments and performs QA testing, regression testing, and performance testing.
Steps 8: Once the QA builds pass the QA team’s verification, they are deployed to the UAT environment.
Step 9: If the UAT testing is successful, the builds become release candidates and will be deployed to the production environment on schedule.
Step 10: SRE (Site Reliability Engineering) team is responsible for prod monitoring.
Over to you: what's your company's release process look like?
--
Subscribe to our weekly newsletter so you won't miss it: bit.ly/3KCnWXq
6
261
1,095
77,183
25 Feb 2024
For load balancing decisions tied to data types, opt for Layer 7 load balancing—the go-to at the Application Layer (OSI Model).
This is where API gateways comes into the picture.
We use kong, gloo, consul
1
34
25 Feb 2024
Load balancing at Layer 4 does not have visibility into what the data packets contain beyond the header information's IP address and port information.
LB at layer 4 and LB at 7 [api gateways]
2
37

5 Dec 2023
The real fraud is happening on trains these days, ₹80 veg meal is served for ₹150, no bills are being given, ₹5 tea is served for ₹10, whereas for ₹10 tea with tea bag is mentioned by irctc, for train number- 12349 @AshwiniVaishnaw @RailMinIndia @aajtak @NWRailways
3
1
223
Pavitra Bhagat retweeted

12 Nov 2023
you can either code fast or produce fast code. You cannot do both.
All frameworks, libraries, ORMs, no code movement aim to allow you to code fast, not necessarily produce fast code.
Understandably so, we live in an age where we are expected to ship fast, we have stakeholders to satisfy. we call always improve quality and performance later. Heck we got used to ship with day 1 patch.
It is wise to ship fast because the market expects it. And to ship fast you have to code fast and to code fast you have to write less code. Or (god help us) you can use AI to write the code.
But, when you write less code, you didn’t really write less code, you simply hid a large piece of code under the carpet and exposed it behind a simple API call. You abstracted away complexity, which eventually leaks in all sorts of nasty ways. Large CPU usage, large memory usage, large disk usage, slow running operations, and if you are on the cloud that translates to a large $$ bill.
You can either code fast or produce fast code. You cannot do both.
I understand why frameworks advertise how fast it is to spin a web server with their product. They truly know how complex web servers are (because they had to wrap it all away) but they have to do this to sell.
Honest frameworks will say hey, we know this stuff is complex but we made it easy by creating these abstractions and used some defaults. However, please consider looking at those defaults values and change them for your use case. We had to pick defaults that fits all but we don’t know your use case.
My advice to software engineers, understand what you use.
For example, if you want to use a Node or a Bun web server, please consider writing one using C first as an exercise.
You will appreciate the framework 10 times more. You will even ask the framework maintainers to expose this and that configuration to tune your web server. You will ask for details doc of how the framework handles connection acceptance and request reading. And whether the number of SO_REUSEPORT threads can be changed.
Web server is just an example, this applies to any code.
If I would summarize this, understand the code, even if you didn’t write it. Maybe then you can code fast and also produce fast code.
And by fast code I mean efficient and fast.
12
133
692
74,664
22 Aug 2023
in java we have list interface, linkedlist and arraylist are it's implementation. So why java provides two implementation of list interface?
#java #pavbyte #pragmaticengineer
1
94