
I post about the intersection of 🦾AI, 🤖LLMs, 📊data products, and 📈data engineering. Owner of VDP and @aiworkhorse
Joined March 2015
- Tweets 2,163
- Following 1,653
- Followers 521
- Likes 673
134 Photos and videos













15 Jan 2025
Can we get @joinautopilot to create a @levelsio tracker? Or @marclou, or both?
These guys love sharing their data, and many folks want to follow their lead. This would be a killer partnership. 🔥

OK, I increased the recurring investment to $10,000/week.
The only reason I don't go all-in with $600,000 is this:
This money is the fruit of 7 years of entrepreneurship failures. If the market crashes tomorrow, I won't be able to sleep.
I'm going to invest almost everything I earn in the SP500 because it's proven to pay off after years. I'll just do it over the course of 365 days to lift the risk off.
2
147
31 Dec 2024
Chain of Continuous Thought looks dope, very excited to try models trained this way.
1
1
92
31 Dec 2024
1
66
12 Nov 2024
This 👇🏻

Changing a single field name in our LLM response schema improved accuracy from 4.5% to 95% on GSM8k.
The fix was simple: going from final_choice to final_answer. Turns out our model was returning a multiple-choice index instead of the actual answer.
If you're working with structured outputs:
1. Look closely at your field names - they fundamentally alter model behavior, same prompt, drastically different results
2. JSON mode isn't a free lunch for better performance - it showed 50% more performance variance than Function Calling across 200 test cases
3. A model needs room to think too, like you - Chain of Thought remains critical with up to 60% accuracy improvements
With LLMs, it's trivial to generate schema variations and with structured outputs, it's easy to validate the results early on.
Look at your data.
1
63
12 Nov 2024
🔥 This is sick. Using code to run simulations is way too uncommon IMO. So many amazing discoveries can be made by developing a simple simulation framework (even without LLMs).
11 Nov 2024

.@Microsoft just dropped TinyTroupe!
Described as "an experimental Python library that allows the simulation of people with specific personalities, interests, and goals."
These agents can listen, reply back, and go about their lives in simulated TinyWorld environments.

1
61
13 Oct 2024
Swarm is cool but definitely a tutorial. Explicitly not for production and not a library, just an example.
12 Oct 2024

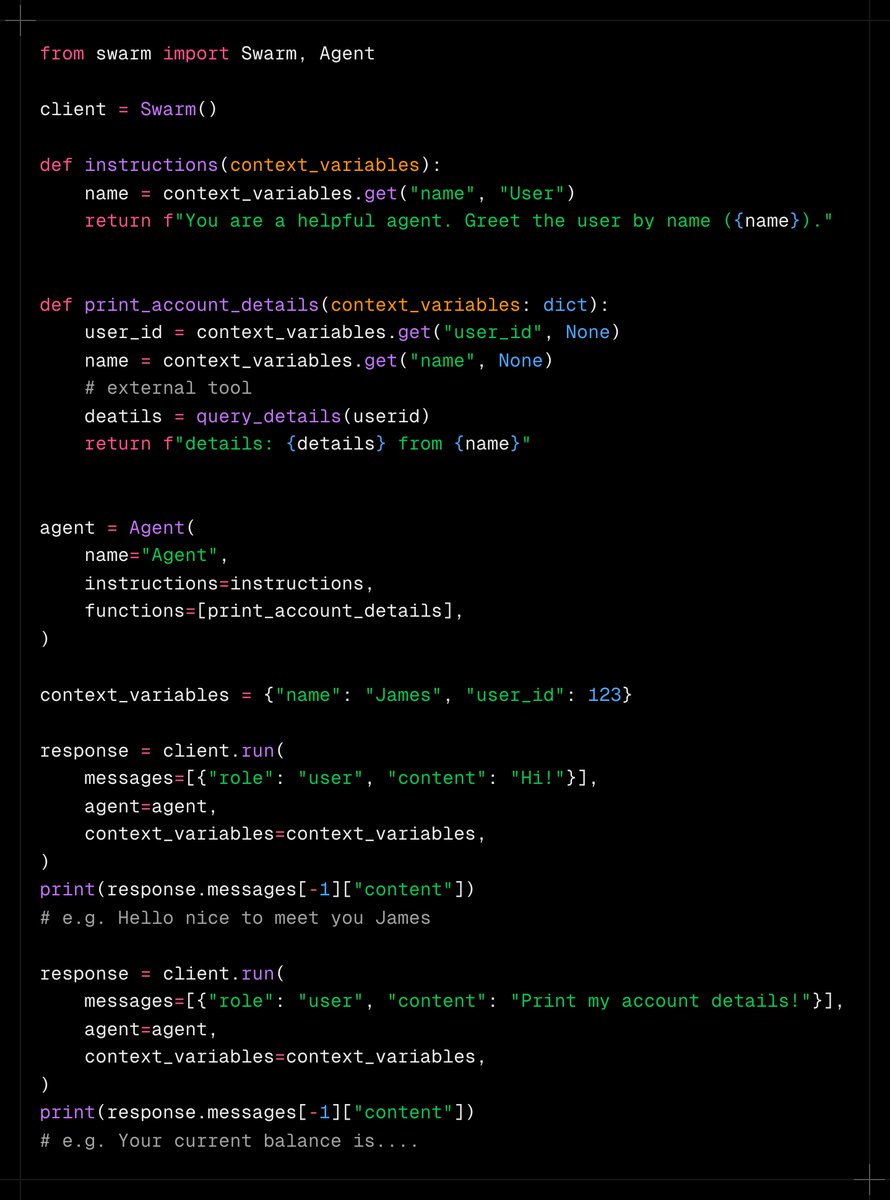
This came unexpected! @OpenAI released Swarm, a lightweight library for building multi-agent systems. Swarm provides a stateless abstraction to manage interactions and handoffs between multiple agents and does not use the Assistants API. 🤔
How it works:
1️⃣ Define Agents, each with its own instructions, role (e.g., "Sales Agent"), and available functions (will be converted to JSON structures).
2️⃣ Define logic for transferring control to another agent based on conversation flow or specific criteria within agent functions. This handoff is achieved by simply returning the next agent to call within the function.
3️⃣ Context Variables provide initial context and update them throughout the conversation to maintain state and share information between agents.
4️⃣ Client run() initiate and manage the multi-agent conversation. It needs an initial agent, user messages, and context and returns a response containing updated messages, context variables, and the last active agent.
Insights:
🔄 Swarm manages a loop of agent interactions, function calls, and potential handoffs.
🧩 Agents encapsulate instructions, available functions (tools), and handoff logic.
🔌 The framework is stateless between calls, offering transparency and fine-grained control.
🛠️ Swarm supports direct Python function calling within agents.
📊 Context variables enable state management across agent interactions.
🔄 Agent handoffs allow for dynamic switching between specialized agents.
📡 Streaming responses are supported for real-time interaction.
🧪 The framework is experimental. Maybe to collect feedback?
🔧 Flexible and works with any OpenAI client, e.g., Hugging Face TGI or vLLM-hosted models.
1
1
100
7 Sep 2024
Struggling with Llama 3.1 8B? I wish I had seen this sooner.
Meta: "We recommend using Llama 70B-instruct or Llama 405B-instruct for applications that combine conversation and tool calling. Llama 8B-Instruct can not reliably maintain a conversation alongside tool calling definitions. It can be used for zero-shot tool calling, but tool instructions should be removed for regular conversations between the model and the user." (Emphasis added.)
Link in reply below
1
72
7 Sep 2024
This is specific to the Instruct models: llama.meta.com/docs/model-ca….
However, if you're having trouble with Llama 3.1 Instruct 8B on any JSON-mode tasks, I recommend trying 70B before increasing complexity of your pipeline or changing models entirely.
40
31 Aug 2024
My python people, if you've been waiting for the right time to move to uv for package mgmt, now is the time.
30 Aug 2024

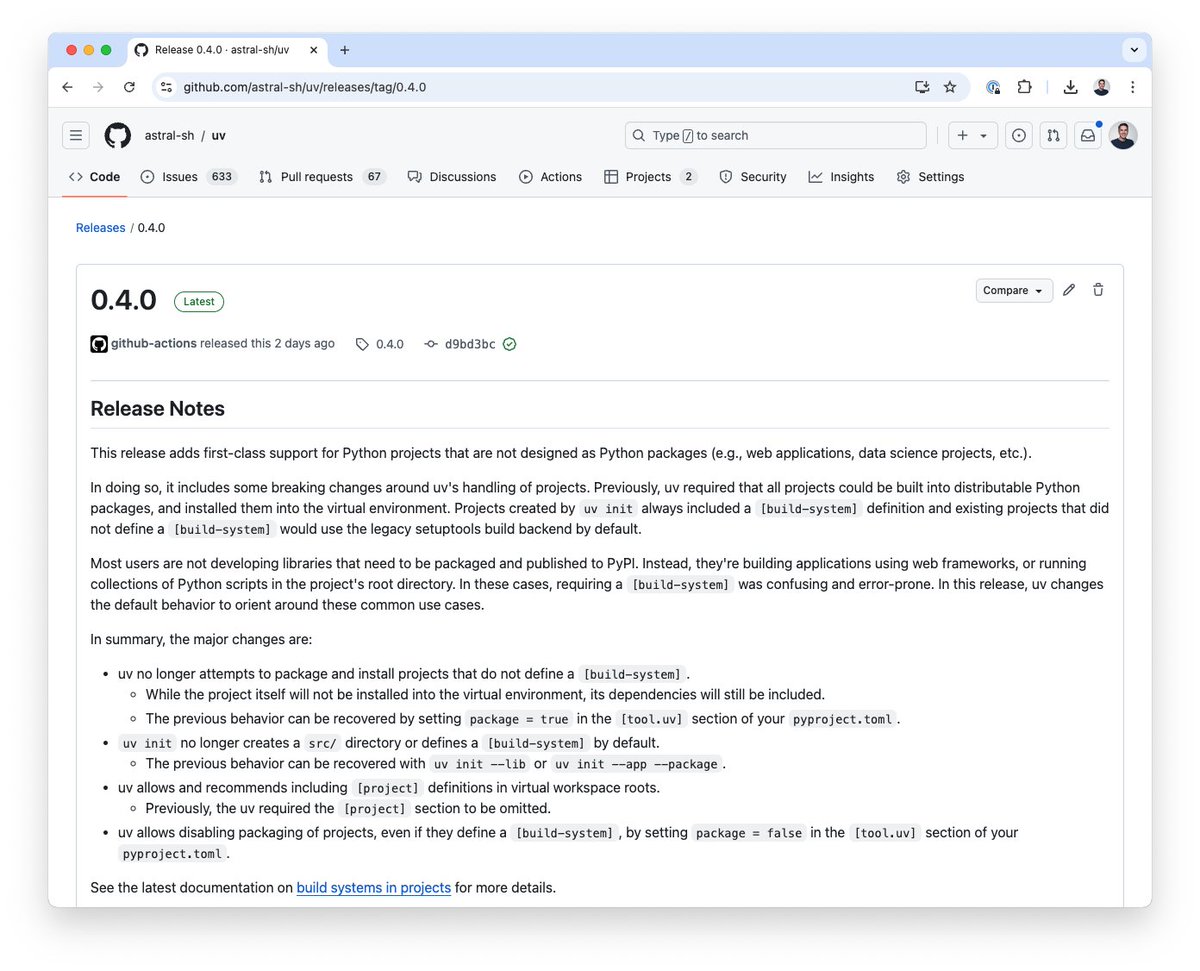
uv 0.4.0 is out now 🚢🚢🚢
It includes first-class support for Python projects that aren't intended to be built into Python _packages_, which is common for web applications, data science projects, etc.
1
106
12 Aug 2024
30% is a huge improvement over all the previous hype that was around 13% (Devin), but still not something I would consider even close to production ready. Fast progress though! I hope we get some solid open source options in this space as the commercial ones improve.
12 Aug 2024

I'm excited to share that we've built the world's most capable AI software engineer, achieving 30.08% on SWE-Bench – ahead of Amazon and Cognition. This model is so much more than a benchmark score: it was trained from the start to think and behave like a human SWE.
89
29 Jul 2024
Great update on open source, with expanded details in the replies 👇
28 Jul 2024

What a massive week for Open Source AI:
We finally managed to beat closed source fair and square!
1. Meta Llama 3.1 405B, 70B & 8B—The latest in the llama series, this version (base instruct) comes with multilingual (8 languages) support, a 128K context, and an even more commercially permissive license. The best part: 405B beats GPT4o/ mini fair and square!
Bonus: Meta posted a banger of a tech report with quite a lot of details also on upcoming (?) multi-modal (image/ audio/ video)
2. Mistral dropped Large 123B—Dense, multilingual (12 languages), and 128K context. Comes as instruct-only model checkpoint, with performance less than 405B but higher than L3.1 70B. Released under non-commercial license.
3. Nvidia released Minitron distilled 4B & 8B - apache 2.0 license, 256K vocab, with student beating the teacher by 16% on MMLU. Uses iterative pruning and distilling to achieve SoTA! The real question: Who is distilling 405B right now? ;)
4. InternLM shared Step Prover 7B—SoTA on the Lean, which was trained on Github repos with large-scale formal data. Achieves 48.8 pass@1, 54.5 pass@64. They release the dataset, tech report and the fine-tuned InternLM math plus model checkpoint
5. CofeAI dropped Chonky TeleFM 1T - A one trillion parameter dense model trained on 2T tokens, bilingual - Chinese and English, apache 2.0 licensed and tech report. They use a novel progressive upsampling approach.
Stability dropped Sv4D, Nvidia released MambaVision, SakanaLabs with Evo (merging stable diffusion), and more.
This was a landmark week, and I'm personally quite happy with the direction of open source AI/ ML!
Did I miss anything interesting drop them in comments! 🤗
1
61
24 Jul 2024
In the commercial AI use case space, open source models are everything. This details how much of a leader Llama/meta is in this space.
23 Jul 2024

Huge congrats to @AIatMeta on the Llama 3.1 release!
Few notes:
Today, with the 405B model release, is the first time that a frontier-capability LLM is available to everyone to work with and build on. The model appears to be GPT-4 / Claude 3.5 Sonnet grade and the weights are open and permissively licensed, including commercial use, synthetic data generation, distillation and finetuning. This is an actual, open, frontier-capability LLM release from Meta. The release includes a lot more, e.g. including a 92-page PDF with a lot of detail about the model:
ai.meta.com/research/publica…
The philosophy underlying this release is in this longread from Zuck, well worth reading as it nicely covers all the major points and arguments in favor of the open AI ecosystem worldview:
"Open Source AI is the Path Forward"
facebook.com/4/posts/1011571…
I like to say that it is still very early days, that we are back in the ~1980s of computing all over again, that LLMs are a next major computing paradigm, and Meta is clearly positioning itself to be the open ecosystem leader of it.
- People will prompt and RAG the models.
- People will finetune the models.
- People will distill them into smaller expert models for narrow tasks and applications.
- People will study, benchmark, optimize.
Open ecosystems also self-organize in modular ways into products apps and services, where each party can contribute their own unique expertise. One example from this morning is @GroqInc , who built a new chip that inferences LLMs *really fast*. They've already integrated Llama 3.1 models and appear to be able to inference the 8B model ~instantly:
x.com/karpathy/status/181580…
And (I can't seem to try it due to server pressure) the 405B running on Groq is probably the highest capability, fastest LLM today (?).
Early model evaluations look good:
ai.meta.com/blog/meta-llama-… x.com/alexandr_wang/status/1…
Pending still is the "vibe check", look out for that on X / r/LocalLlama over the next few days (hours?).
I expect the closed model players (which imo have a role in the ecosystem too) to give chase soon, and I'm looking forward to that.
There's a lot to like on the technical side too, w.r.t. multilingual, context lengths, function calling, multimodal, etc. I'll post about some of the technical notes a bit later, once I make it through all the 92 pages of the paper :)
53
23 Jul 2024
IT HAS ARRIVED
23 Jul 2024

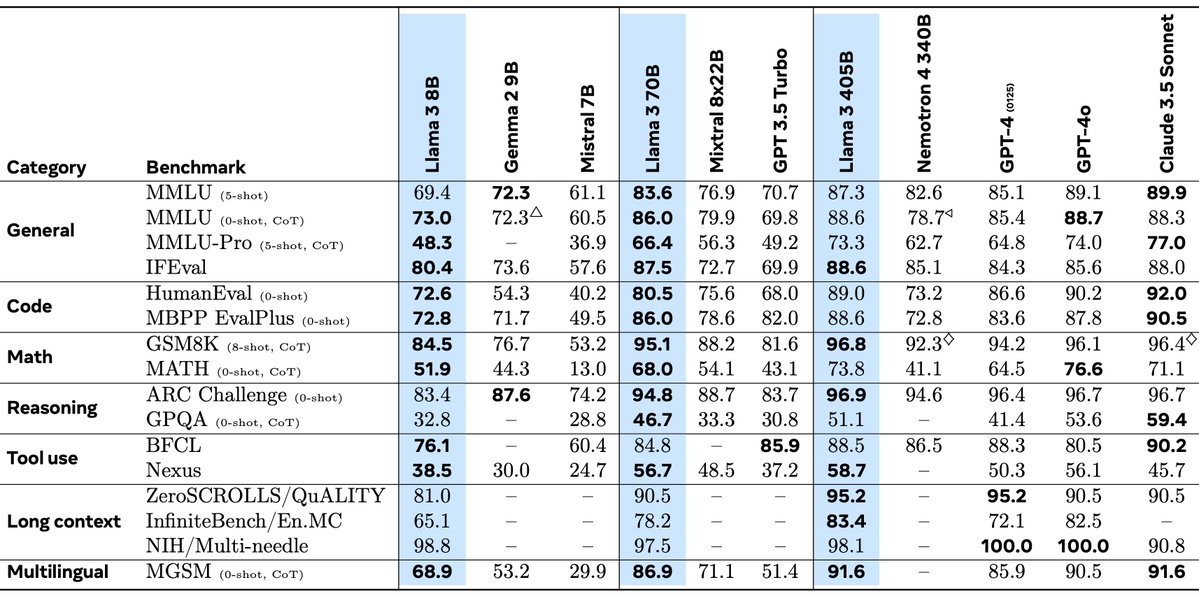
Our Llama 3.1 405B is now openly available! After a year of dedicated effort, from project planning to launch reviews, we are thrilled to open-source the Llama 3 herd of models and share our findings through the paper:
🔹Llama 3.1 405B, continuously trained with a 128K context length following pre-training with an 8K context length, supports multilinguality and tool usage. It offers performance comparable to leading language models, such as GPT-4, across a range of tasks.
🔹Compared to previous Llama models, we have enhanced the preprocessing and curation pipelines for pre-training data, as well as the quality assurance and filtering methods for post-training data.
🔹Pre-training 405B on 15.6T tokens (3.8x10^25 FLOPs) was a significant challenge. We optimized our entire training stack and used over 16K H100 GPUs.
🔹To support large-scale production inference for the 405B model, we quantized from 16-bit (BF16) to 8-bit (FP8), reducing compute requirements and enabling the model to run on a single server node.
🔹We leveraged the 405B model to improve the post-training quality of our 70B and 8B models.
🔹In post-training, we refined chat models with multiple rounds of alignment involving supervised fine-tuning (SFT), rejection sampling, and direct preference optimization. We generate most SFT examples using synthetic data.
🔹We integrated image, video, and speech capabilities into Llama 3 using a compositional approach, enabling models to recognize images and videos and support interaction via speech. They are under development and not yet ready for release.
🔹We've updated our license to allow developers to use outputs from Llama models to enhance other models.
There is nothing more rewarding than working at the forefront of AI development alongside some of the brightest minds in the field and publishing our research transparently. I'm excited about the innovations our open-source models enable and the potential of the future herd of Llamas!
38
22 Jul 2024
This library deserves more attention 👇🏻
21 Jul 2024

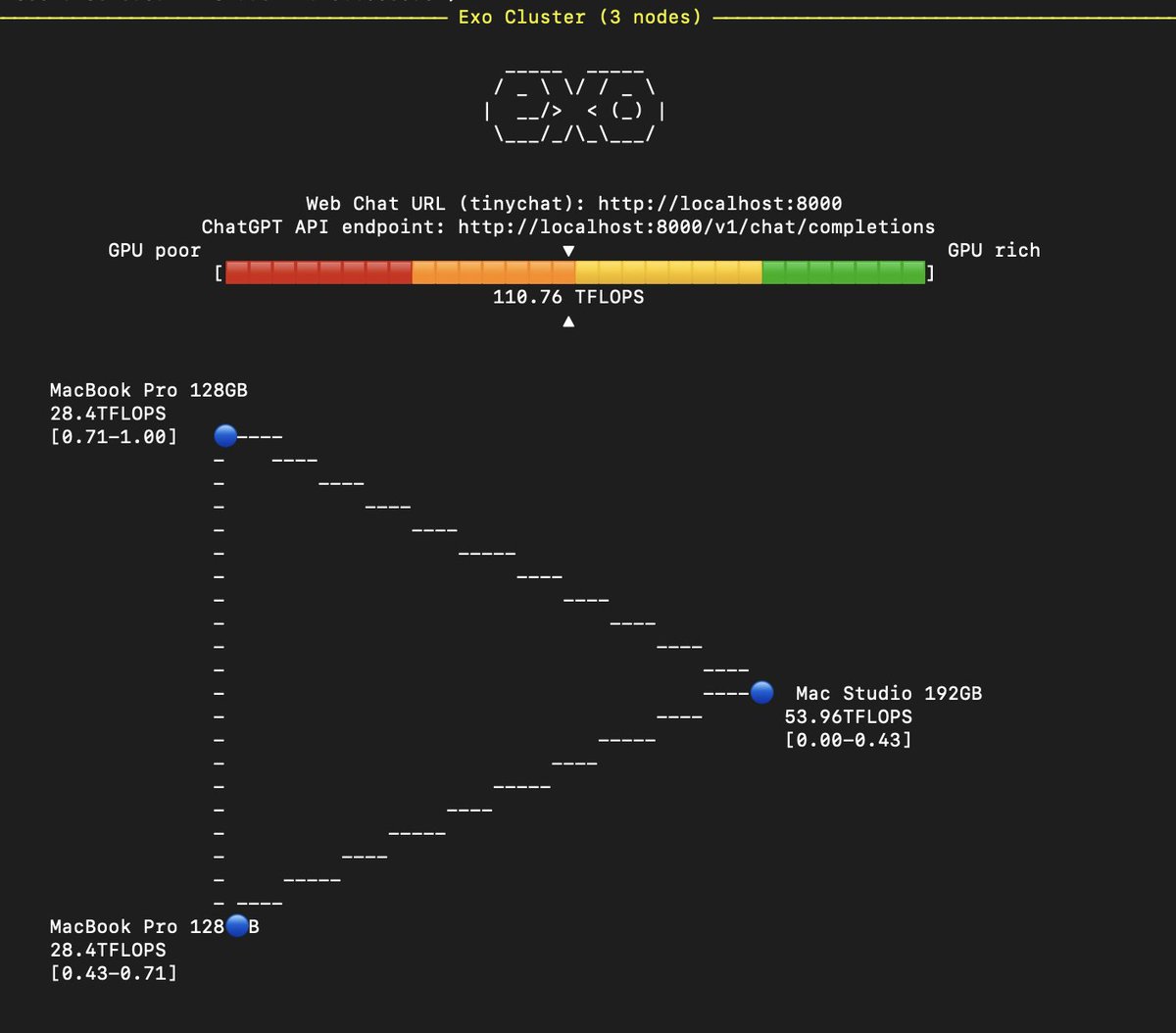
You don't need a H100 to run Llama-3-405b.
2 MacBooks and 1 Mac Studio will do the job, with @exolabs_ to aggregate the memory/compute.
I'm ready for you, Llama-3-405b.
1
2
197
19 Jul 2024
Another open source win ✅
18 Jul 2024

NVIDIA Transitions Fully Towards Open-Source GPU Kernel Modules developer.nvidia.com/blog/nv… #linux
45
17 Jul 2024
This is neat, but IMO all these have a long ways to go before being part of daily workflows for anything beyond startups and indie hackers.
15 Jul 2024

Introducing Claude Engineer 2.0, with agents! 🚀
Biggest update yet with the addition of a code editor and code execution agents, and dynamic editing.
When editing files (especially large ones), Engineer will direct a coding agent, and the agent will provide changes in batches.
Batches are smartly selected based on file complexity.
The code execution agent will run the code and check for issues.
It can even start processes (like live servers) and end them.
It's insanely powerful! 🔥
1
101