
Research Scientist. Generative AI.
Joined January 2014
- Tweets 64
- Following 49
- Followers 772
- Likes 238
20 Photos and videos















Pinned Tweet

Apr 15
Continuous Adversarial Flow Models (CAFMs)
Paper: arxiv.org/abs/2604.11521
Flow matching generates poor samples without guidance because the MSE loss induces incorrect generalization. Instead of an isotropic Euclidean distance, we need a manifold-aware criterion—but how can we obtain it?
CAFMs bring adversarial training to continuous time. Learning velocity with a discriminator induces better generalization because the discriminator as a criterion can learn the manifold!
Also unlike flow matching’s forward KL objective, adversarial training allows optimizing different divergences. CAFMs can generate sharper and higher-quality samples.
Adversarial training in continuous time also avoids the vanishing gradient problem, leading to stable training.
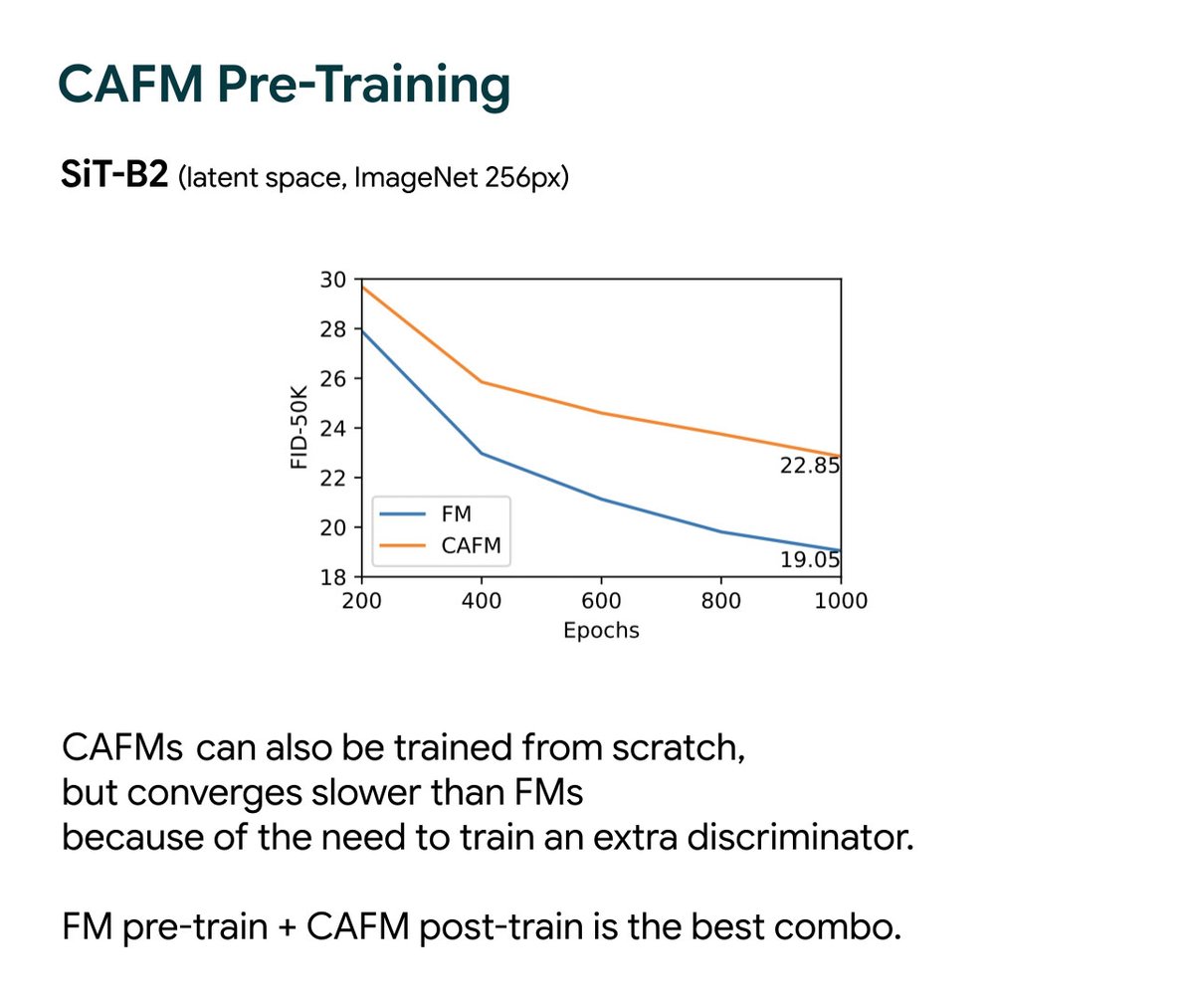
CAFMs can be trained from scratch or used to post-train existing flow models. Post-training SiT/JiT for just 10 epochs yields large FID improvements. We also observe significant GenEval and DPG improvements when post-training text-to-image models.
More details in this thread!
11
66
507
263,499
May 19
More explorations can be done for diffusion in the spectral domain.
What if directly training a diffusion model in the spectral domain? We can use a causal transformer where only high-freq tokens attend to low-freq ones? It is also more natural for super-resolution tasks?
May 19

High-fidelity generation is hitting a scaling crisis as DiT compute grows with image resolution and video length. But do we need high-resolution denoising at every step?
We introduce Spectral Progressive Diffusion, a plug-and-play framework for efficient image and video generation that directly exploits the spectral autoregression property of diffusion to grow resolution during denoising.
[1/7]
2
1
3
433
Peter Lin retweeted

Apr 24
Introducing Omni, one unified model can support any-to-any multimodal modeling, including multimodal understanding, image/video generation and editing, world modeling and 3D reconstruction. All in one that adopts standard mixture-of-experts arch with only 3B activations.
9
27
220
31,057
Apr 15
Continuous Adversarial Flow Models (CAFMs)
Paper: arxiv.org/abs/2604.11521
Flow matching generates poor samples without guidance because the MSE loss induces incorrect generalization. Instead of an isotropic Euclidean distance, we need a manifold-aware criterion—but how can we obtain it?
CAFMs bring adversarial training to continuous time. Learning velocity with a discriminator induces better generalization because the discriminator as a criterion can learn the manifold!
Also unlike flow matching’s forward KL objective, adversarial training allows optimizing different divergences. CAFMs can generate sharper and higher-quality samples.
Adversarial training in continuous time also avoids the vanishing gradient problem, leading to stable training.
CAFMs can be trained from scratch or used to post-train existing flow models. Post-training SiT/JiT for just 10 epochs yields large FID improvements. We also observe significant GenEval and DPG improvements when post-training text-to-image models.
More details in this thread!
11
66
507
263,499
Apr 15
5. Conclusion and thoughts
Our Adversarial Flow line of research explores ways to integrate adversarial modeling and flow modeling, two of the most influential paradigms in generative modeling. Adversarial Flow Models (AFMs) bring adversarial training to discrete-time flow modeling. Now, Continuous Adversarial Flow Models (CAFMs) further extend this idea to continuous time.
I think being able to do adversarial training in continuous time will unlock many more interesting explorations!
Our method is also different from guidance. Both CAFM and FM ensure convergence to the empirical distribution (i.e., the overfitted ground-truth distribution). They differ only in their finite-capacity generalization, while still remaining faithful to the original distribution. In contrast, guidance does not guarantee faithfulness to the original distribution. Guidance can lead to out-of-distribution (OOD) samples, canonical samples, and other distortions. Accurately and faithfully generating the original data distribution remains an important area of research.
We do not claim that CAFMs can always generate high-quality samples without guidance. When training samples are sparse or contain outliers, the manifold learned by the discriminator is not guaranteed to be correct. Guidance can still be applied orthogonally to achieve low-temperature sampling.
Recently, representational latent spaces (RAE) have become a popular research direction. These methods change the data space in which flow matching operates and therefore implicitly affect the model’s generalization. However, they do not directly address the problem of MSE and require operating in latent space. CAFMs directly modify the loss objective to induce different generalization and work effectively even in pixel space. Other representation-alignment approaches (REPA), may also have implicit connections to our work. We hope our work inspires further insights in the research community.
1
1
11
1,516
3 Dec 2025
APT2 is accepted at NeurIPS 2025!
Real-time interactive video generation up to 1 minute @ 720p 24fps through autoregressive adversarial post-training.
Come to our poster at:
- San Diego Convention Center
- Wed, Dec 3, 2025 • 4:30 PM – 7:30 PM PST
- Exhibit Hall C,D,E # 4302
1
16
785
1 Dec 2025
Our research: Adversarial Flow Models (AF)
arxiv.org/abs/2511.22475
AF unifies Adversarial and Flow Models.
Unlike GANs, AF learns optimal transport (stable). Unlike CMs, AF only trains on needed timesteps (save capacity). We can train super-deep 112-layer 1NFE model! SOTA FIDs!
13
79
561
42,287
12 Jun 2025
Introducing Seaweed APT2, a real-time, interactive, streaming video generation model.
seaweed-apt.com/2
Adversarial training for autoregressive modeling!
Streaming 1 minute videos, 1 diffusion step, 24fps real-time on 1xh100, with interactive controls!
14
36
194
20,401
12 Jun 2025
APT2 can also be used for real-time interactive virtual human generation. These human avatars are rendered in real time!
1
2
8
1,406
12 Jun 2025
APT2 is an early research work. We believe it is a promissing direction for real-time interactive video generation.
I am at #CVPR2025 this week in Nashville. Happy to connect and discuss our work in person.
2
1
13
1,113
Peter Lin retweeted

6 Jun 2025
🔥Introducing #SeedVR2, the latest one-step diffusion transformer version of #SeedVR for real-world image and video restoration!
details
- Paper: arxiv.org/abs/2506.05301
- Project: iceclear.github.io/projects/…
- Code (under review): github.com/IceClear/SeedVR2
2
4
17
4,208
Peter Lin retweeted

14 Apr 2025
字节确实变了
居然先发布了新版 Seaweed 视频模型的论文和演示
除了常规文生、图生视频外还支持:
- 音视频同步生成
- 长镜头与多镜头叙事
- 高分辨率超分与实时生成
- 世界建模与相机控制
下面的论文页面有更多演示
5
16
89
18,019
Peter Lin retweeted
14 Apr 2025
Glad to share Seaweed-7B, a cost-effective foundation model for video generation. Our tech report highlights the key designs that significantly improve compute efficiency and performance given limited resources, achieving comparable quality against other industry-level models. To unleash the power of the foundation model, Seaweed-7B further enables a wide range of downstream applications including image-to-video generation, human video generation, subject-consistent video generation, video-audio joint generation, long video generation and storytelling, real-time generation, super-resolution generation, camera controlled generation.
Check out our webpage and report for more details:
Webpage: seaweed.video/
Paper: seaweed.video/seaweed.pdf
It's a wonderful journey of the last year. Thanks to all teammates for their contributions, sincerely.
34
96
515
77,425