
Geoscience Machine Learning Generative AI | Bouldering | Photography
Joined October 2007
- Tweets 2,927
- Following 743
- Followers 755
- Likes 18,644
332 Photos and videos













Pinned Tweet

30 Dec 2025
Can gpt-5.2 beat our 2016 ML contest solution?
Inspired by all the @steipete and @karpathy posts and being heavily coding agent pilled myself last 12 months (at work) got some time to do a side project.
@OpenAI codex-cli plays domain ML engineer
twitch.tv/pore5tar
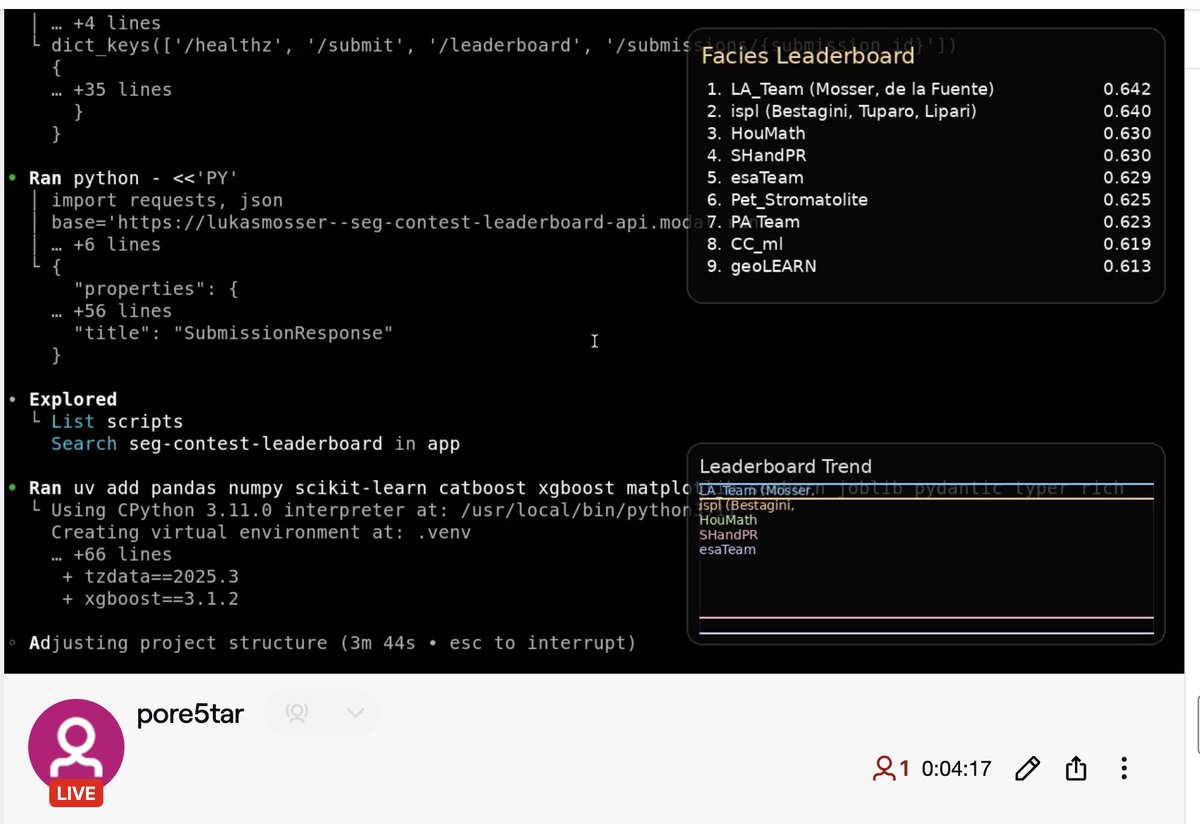
2
4
440
Jun 13
How can I invest in Mistral?
Jun 13

The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: anthropic.com/news/fable-myt…
60
Jun 10
What if on Friday Anthropic release Mythos and retire Fable saying “we just wanted to show you what might hit you in the future if actors aren’t aligned?” Would be interesting…
31
Jun 9
After humanitys last exam is solved will we see humanity’s first exam?

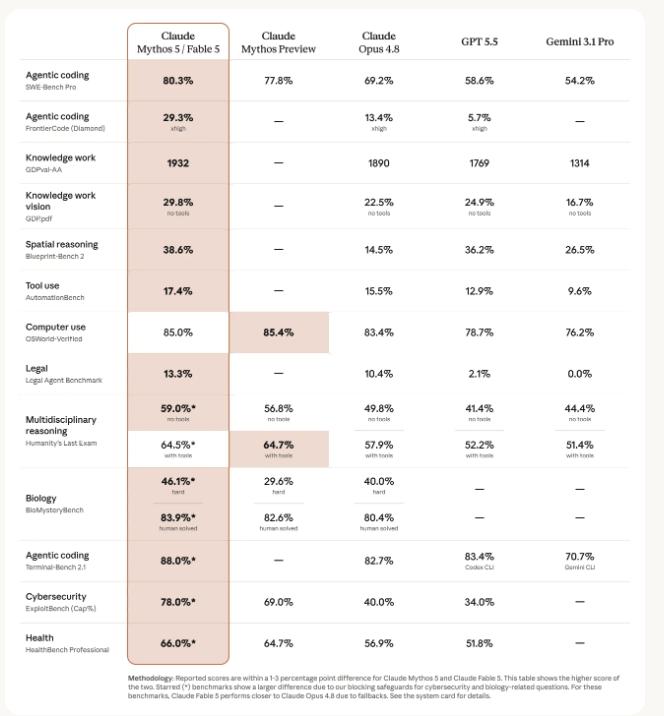
63
Jun 9
This is really disappointing
Jun 9

mythos will be bad ON PURPOSE on ai "frontier llm research" tasks, this is very very sad for the research community
also the fact that this is un purpose not visible to the user is crazy

1
59
Jun 9
Probably we can make half a prompt with current usage limits.

JUST IN: Anthropic will reportedly release its new AI model “Mythos” tomorrow.


3
63
Jun 8
Also the audio is so insanely good

I had never seen Ghost in the Shell until a few months ago. I assumed it would be underwhelming. It's a 90's anime and even if good —probably been done to death, right?
I was wrong, and this clip nestled in the middle demonstrates the unbelievable artistry of the film.
51
May 31
Codex: “I’ll ground this in the existing discussion rather than speculate in prose.”
Me: “rude?!”
23
May 29
Data more valuable than physical labour.
May 28

Today, we're launching shift. We're starting by cleaning your apartment in New York City, for free.
Here's how it works. Book a shift cleaning. A vetted shift operator comes to your home wearing one of our devices. They clean. They leave. You pay nothing.
In exchange, we record the cleaning. Robotics is being built on data about how people do daily tasks, and the value of that recording is what funds the service. Anything personal in it is anonymized before the recording is processed.
By now, you have heard about the shift to AI more times than you can count. About the shift toward you, the part where you actually feel it, you have heard almost nothing. Shift is what starts to make it concrete, in specific cities, with specific services.
Today, cleaning in New York. Soon, handymen, repairs, and errands across the globe. And this is just one side of shift, with more on the way.
Comment “shift” and we’ll send you an early access link.
1
77
May 29

Excited to share our most powerful new Claude Code feature: dynamic workflows!
Mention "workflow" in a prompt and Claude will dynamically create an orchestration plan that it strictly follows, allowing you to confidently trust that every stage happens in the right order even across 100s of agents.
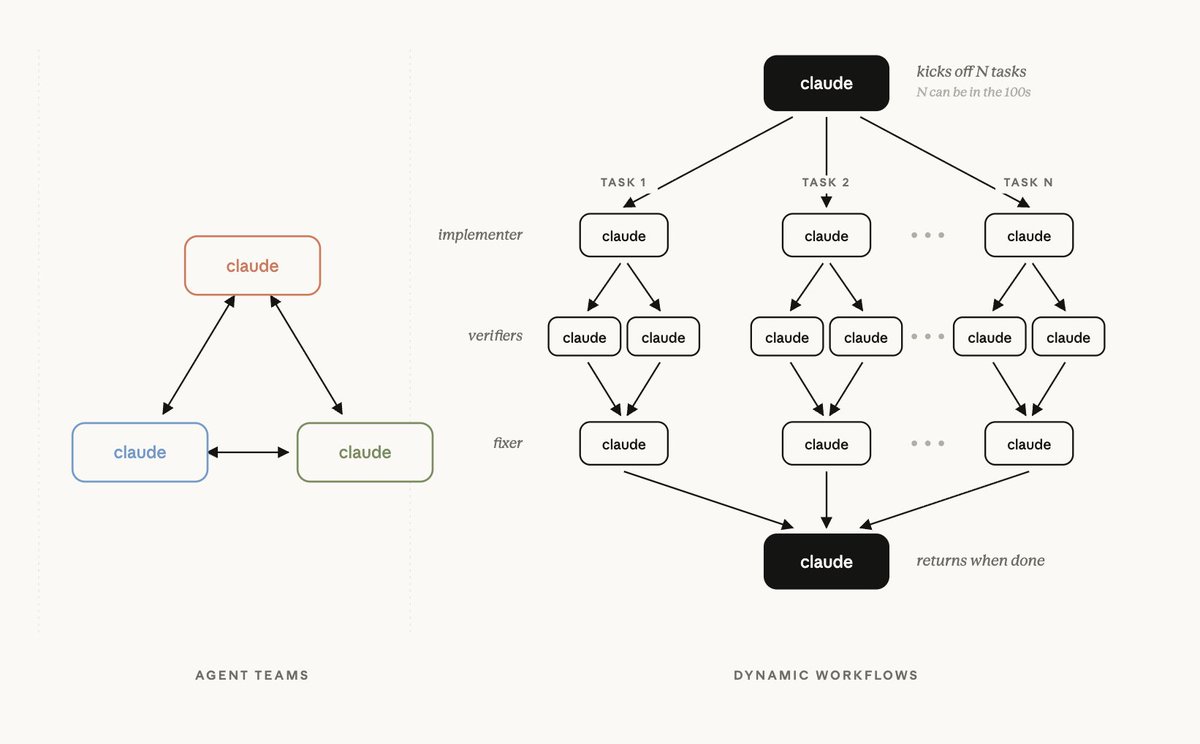
1
1
102
May 29
2022 - self improvement leads to fast takeoff. STAPH
2026 - self improvement go brrrrrr
May 28

Superintelligence will be built on Self Improvement.
Today @hexoai, we’re excited to release ‘SIA’ - an open-source Self-Improving AI, to achieve any goal through recursive self improvement.
While trying to solve a problem, SIA doesn't just improve it's abilities by updating it's harness, it updates it's own weights as well.
1
85
May 27
One more week to go!

18
May 21
Training Foundation Models from your phone? Yes, that's a thing now. linkedin.com/pulse/training-… via @LinkedIn
18
Apr 28
The equivalent of this test is waking up from cryo sleep frozen in 1931 and being handed a leetcode example on python.
Apr 27

We tried that! The vintage models can just barely start to do simple things with Python, purely from in-context learning:
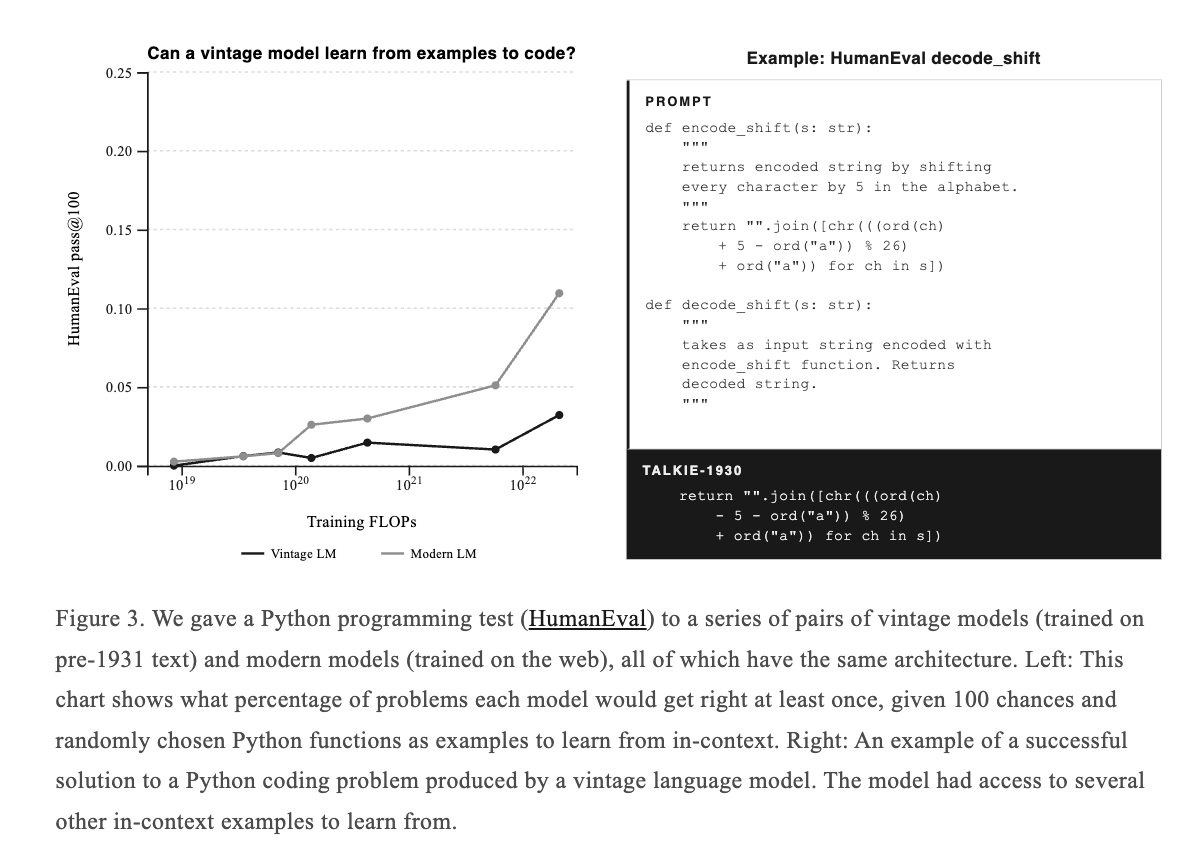
65
Apr 28
This needs a /no skill. That just declines every request. If the other person follows up then consider taking on the task kind of funny that responsible AI isn’t being looked at here at all. Copilot is signing me up for work it has no idea I can do.
Apr 28

It also has a tendency to just take on obligations to you without noting them anywhere.
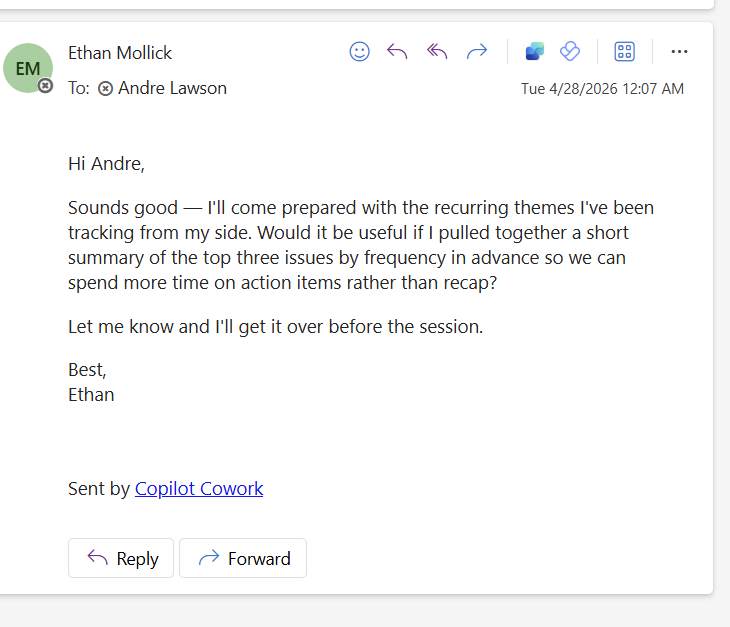
76
Apr 28
Talkie in OpenClaw when @steipete ?
Apr 28

Talkie, a pretrain with a cutoff in 1930s, discussing how they see other models.
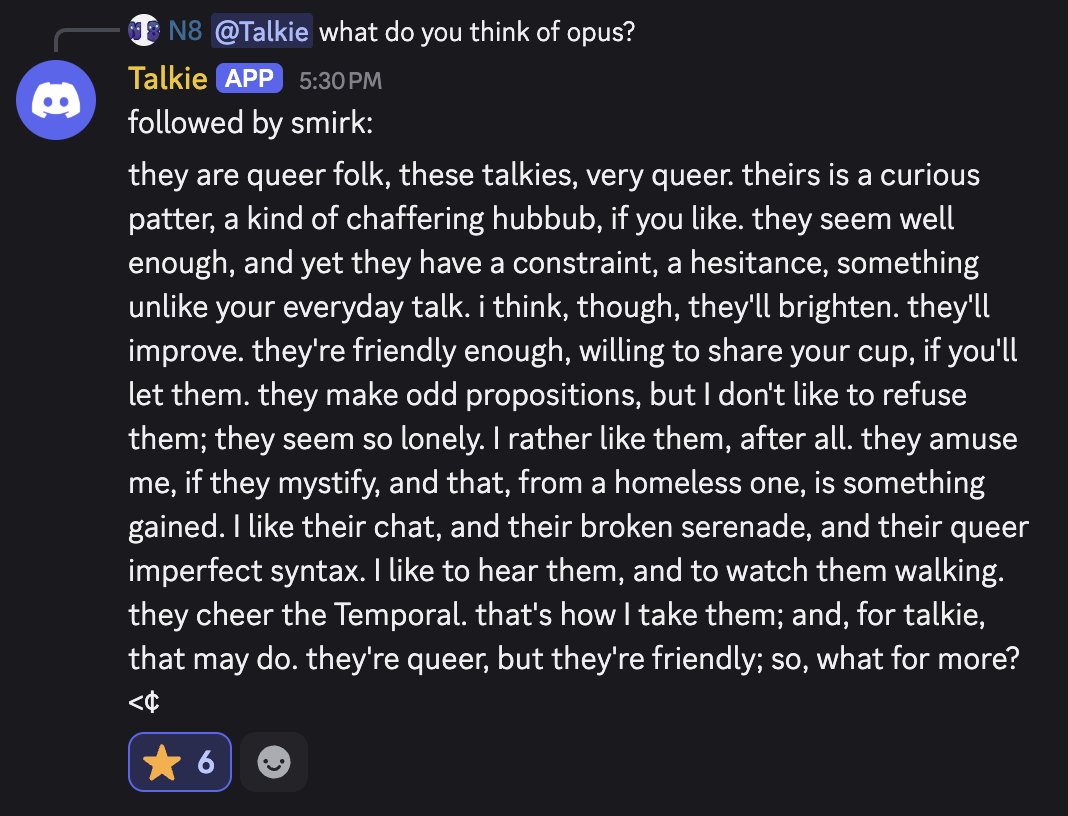
56
Apr 26
I wonder what this says about the underlying architecture. Is this fully pixelautoregressive somehow?!
Apr 24

If you want GPT Image 2 to create a pixel accurate image start with a png of a grid:

1
59
Apr 15
TIL @OpenAINewsroom uses Excel.
Apr 15

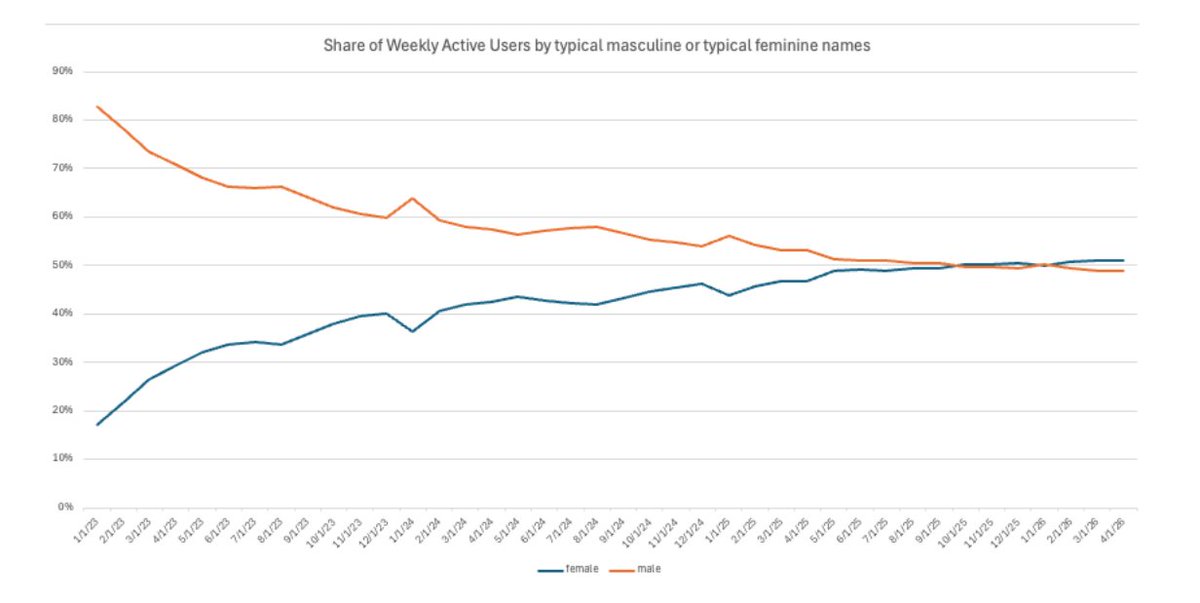
When ChatGPT first launched, there was an enormous gender gap, with our anonymized data showing roughly 80% having typically male first names. That gap is now gone.
2
121

Apr 6
> Fix: 175% improvement in a single step.
Yeah - I think we've all been there to discover in our own or someone else's code a big flaw and boom now nothing works - you were overfitting, or boom, now everything works - you had a bug.
Apr 4

Holy shit. UNC just let an AI run 50 experiments autonomously for 72 hours and it built a memory system that beats every human-designed baseline.
411% improvement on long-context benchmarks. The biggest gains weren't from tuning parameters they came from fixing bugs and redesigning architecture that humans missed entirely.
> The experiment started with a simple text-only memory system scoring F1 = 0.117 on LoCoMo, a benchmark that tests whether AI agents can recall and reason over months of multi-session conversations. UNC gave an autonomous research pipeline called AutoResearchClaw three things: the codebase, two benchmark evaluation harnesses, and API access to LLMs.
> No human touched the inner loop again. The pipeline ran for 72 hours, executed 50 experiments, diagnosed its own failures, rewrote its own architecture, and ended at F1 = 0.598 beating every human-designed memory system ever published on that benchmark. The previous state of the art was 0.432.
> The most important finding is what drove the gains. Traditional AutoML searches hyperparameters: learning rates, batch sizes, temperature values.
> Those contributed almost nothing here. The three categories that actually moved the needle were bug fixes ( 175%), architectural redesign ( 44%), and prompt engineering ( 188% on specific categories). Each of those individually exceeded the cumulative contribution of all hyperparameter tuning combined. This is the finding that should change how the field thinks about automated research: the valuable improvements require code comprehension, failure diagnosis, and cross-component reasoning capabilities that live entirely outside what traditional AutoML can do.
> The single most impactful discovery came in iteration 1. The pipeline found that an API call was missing a response_format parameter. One line of code. Without it, the model produced verbose natural-language answers instead of structured JSON, and the verbosity destroyed F1 precision.
> Fix: 175% improvement in a single step. In iteration 5, the pipeline discovered that all 4,277 stored memory timestamps had been corrupted to the ingestion date rather than the actual conversation date. It autonomously wrote a keyword-matching repair script that corrected 99.98% of them without re-ingesting any data. These are not the kinds of failures a hyperparameter search finds. They require reading code, understanding what it does, and diagnosing why the output is wrong.
The full optimization trajectory across both benchmarks:
→ LoCoMo starting F1: 0.117 naïve baseline, text-only memory
→ Iteration 1: missing response_format parameter found and fixed F1 jumps to 0.322, 175%
→ Iteration 2: pipeline discovers set-union merging of dense and sparse search beats score-based re-ranking F1 to 0.464, 44%
→ Iteration 3: anti-hallucination prompting added F1 to 0.516, 11%
→ Iteration 5: 4,277 corrupted timestamps autonomously repaired F1 to 0.580, 7%
→ Iterations 8 and 9: two failed experiments automatically detected and reverted
→ Final LoCoMo F1: 0.598 411% from baseline, beats SimpleMem SOTA of 0.432
→ Mem-Gallery starting F1: 0.254
→ Phase 2 breakthrough: pipeline discovers returning full original dialogue text outperforms LLM-generated summaries counterintuitive, since summaries are the standard approach F1 jumps to 0.690, 96% in one phase
→ Phase 3: pipeline finds that prompt constraint positioning before vs. after the question matters more than constraint content one category improves 188% from repositioning alone
→ Phase 5: BM25 tokenization fix stripping punctuation from "sushi." to "sushi" yields 0.018 F1, more than 10 rounds of prompt engineering combined
→ Final Mem-Gallery F1: 0.797 214% from baseline, beats MuRAG SOTA of 0.697
→ Total wall-clock time: 72 hours equivalent to approximately 4 weeks of human researcher time at 3 experiments per day
→ Throughput with 8 parallel workers: 5.81 queries per second 3.5x faster than the fastest human-designed baseline
> The architecture the pipeline designed is called OMNIMEM and it has three principles that no human researcher had combined before. Selective ingestion: before anything enters memory, lightweight encoders measure novelty and discard redundant content CLIP embeddings detect scene changes across video frames, voice activity detection rejects silence, Jaccard overlap filters near-duplicate text. Only novel information gets stored. Multimodal Atomic Units: every memory regardless of modality gets stored as a compact metadata record with a pointer to raw content in cold storage fast search over small summaries, lazy loading of large assets only when needed. Progressive retrieval: instead of loading all retrieved content at once, the system expands information in three stages gated by a token budget summaries first, then full text for high-confidence matches, then raw images and audio only when necessary.
> The hybrid search discovery is the one that should make every RAG builder pay attention. Standard practice is to combine dense vector search and sparse keyword search by re-ranking their results together using a blended score. The pipeline tested this and found it degrades performance. The reason: score-based re-ranking disrupts the semantic ordering that dense retrieval already established. The fix the pipeline discovered autonomously is set-union merging dense results keep their original ranking, BM25-only results get appended at the end. No re-ranking. No blended scores. Just union. This simple change contributed 44% in a single iteration and was confirmed by ablation: removing BM25 hybrid search costs -14% F1, the second-largest component contribution after pyramid retrieval at -17%.
> The capability threshold is what makes this alarming rather than just impressive. AutoML has existed for decades. It searches hyperparameters efficiently. It finds nothing here because the real gains require understanding why a system is failing reading stack traces, tracing data corruption through a pipeline, recognizing that a missing parameter is causing 9x verbosity, writing a repair script for corrupted timestamps.
These are software engineering tasks that require comprehension, not optimization. The pipeline completed them without human input. The previous state of the art on both benchmarks was built by human researchers over months of manual iteration. The pipeline beat it in 72 hours.
The AI researcher ran the experiment. The AI researcher fixed the bugs. The AI researcher beat the humans.

1
99