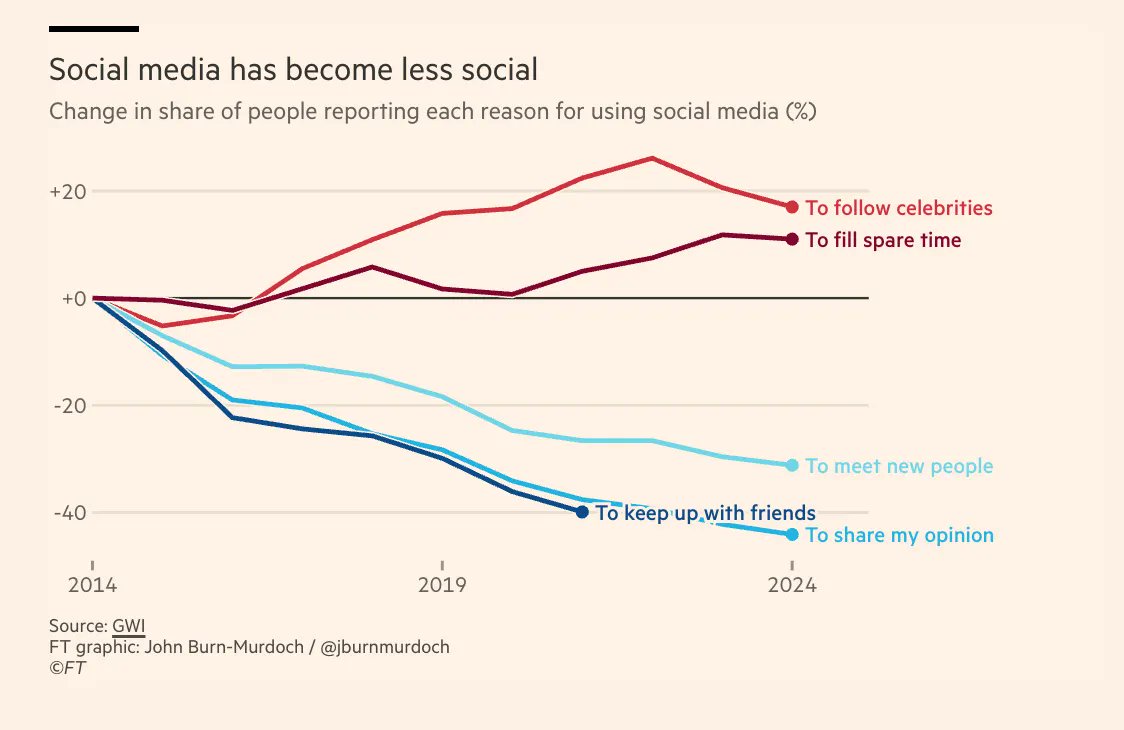
Building paperzilla.ai/. High-signal academic paper feeds for agent-assisted research and humans 🦖.
- Tweets 5,859
- Following 1,748
- Followers 1,203
- Likes 12,031








ALT Schematic neuron models. Left: standard neuron model in ANNs, following a simplistic abstraction from the neuroscience of the 1950s [1, 2] that assumed linear dendrites and an output nonlinearity. Right: proposed neuron model, based on a recent model of cortical cells [22]; notice how this new model extends the standard neuron model by considering internal nonlinearities σ (that represent dendritic processes), and these nonlinearities are affected in a dynamic way by the activity value zi (that represents the bAP going from the soma to the dendrites), itself depending on the inputs xj and the contributions zk from other neurons.








ALT LLM Wiki A pattern for building personal knowledge bases using LLMs. This is an idea file, it is designed to be copy pasted to your own LLM Agent (e.g. OpenAI Codex, Claude Code, OpenCode / Pi, or etc.). Its goal is to communicate the high level idea, but your agent will build out the specifics in collaboration with you. The core idea Most people's experience with LLMs and documents looks like RAG: you upload a collection of files, the LLM retrieves relevant chunks at query time, and generates an answer. This works, but the LLM is rediscovering knowledge from scratch on every question. There's no accumulation. Ask a subtle question that requires synthesizing five documents, and the LLM has to find and piece together the relevant fragments every time. Nothing is built up. NotebookLM, ChatGPT file uploads, and most RAG systems work this way. The idea here is different. Instead of just retrieving from raw documents at query time, the LLM incrementally builds and maintains a persistent
ALT Schematic neuron models. Left: standard neuron model in ANNs, following a simplistic abstraction from the neuroscience of the 1950s [1, 2] that assumed linear dendrites and an output nonlinearity. Right: proposed neuron model, based on a recent model of cortical cells [22]; notice how this new model extends the standard neuron model by considering internal nonlinearities σ (that represent dendritic processes), and these nonlinearities are affected in a dynamic way by the activity value zi (that represents the bAP going from the soma to the dendrites), itself depending on the inputs xj and the contributions zk from other neurons.