
Principal Applied Scientist @ Microsoft Copilot Studio | Building agentic automations so humans click and type less | Agents/NLP/IR/Speech
Joined May 2009
- Tweets 2,381
- Following 378
- Followers 5,637
- Likes 393,785
143 Photos and videos







Pinned Tweet
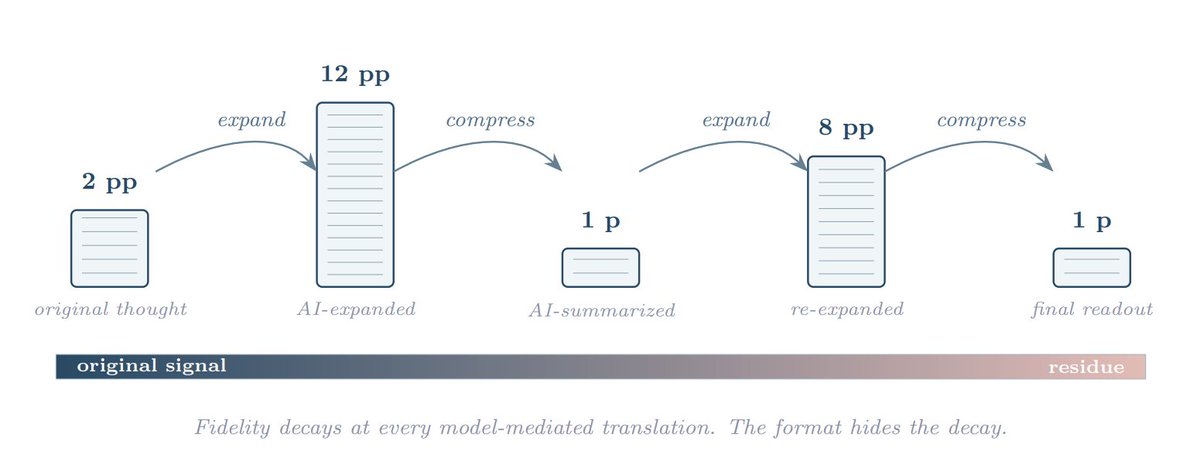
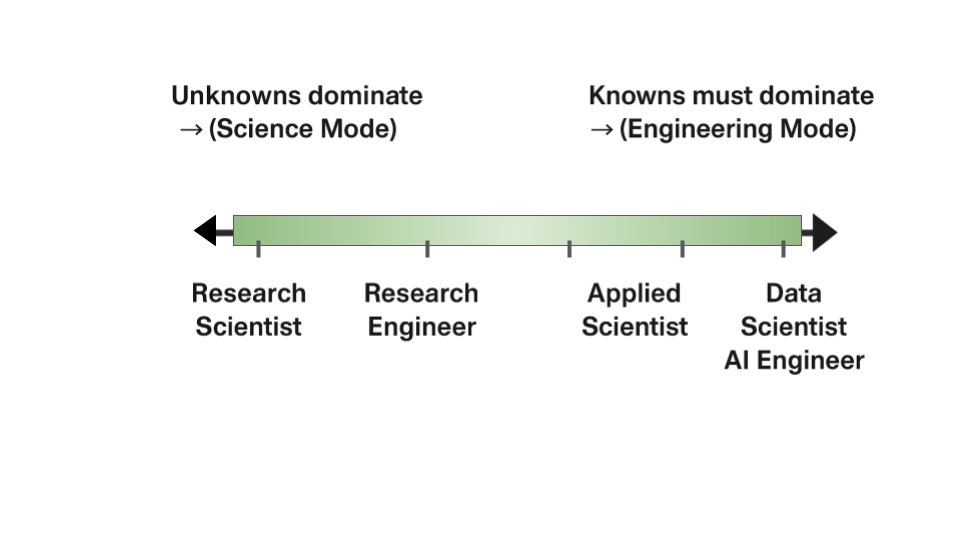
My ICML 2026 position paper, “Beyond Text: The Text-Centric Bias in Foundation Models Must Be Revisited for a Speech-First Future,” was accepted as a Spotlight paper. (top 5% accepts)
Paper: openreview.net/forum?id=n1mA…
#ICML2026 #SpeechAI #FoundationModels #MultimodalAI
1
1
13
1,719

Jun 12
Distillation can never beat the teacher. A student imitating a teacher can't have more information about the answer than the teacher has. It's the data-processing inequality. RL is the only paradigm that can place probability mass outside the teacher's support.
#RL #KD #distillation #selfdistillation
54
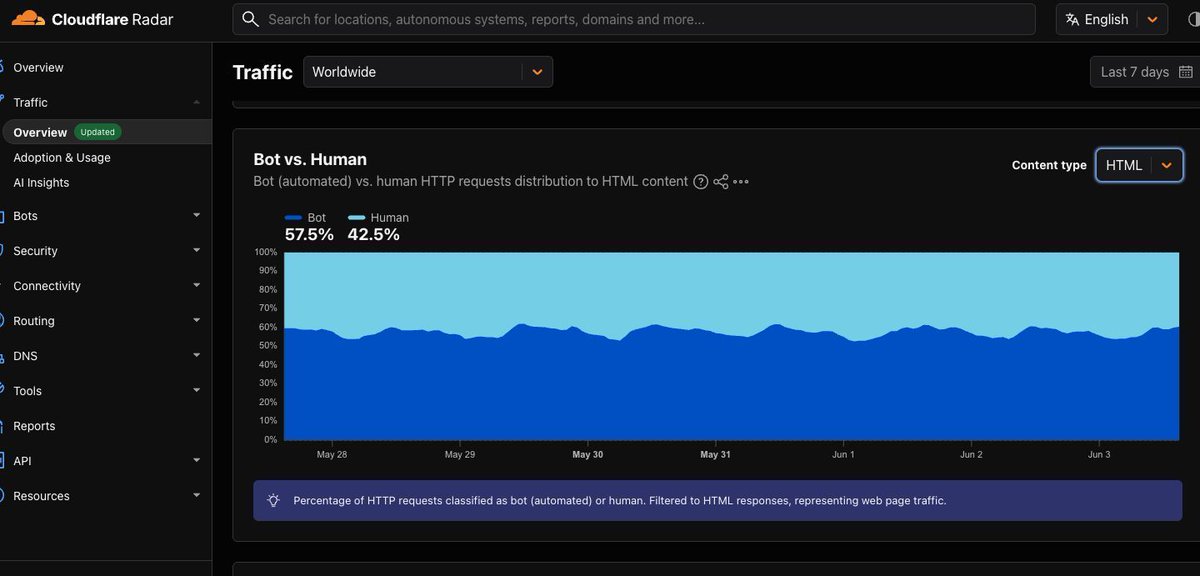
I saw in 2014 mobile app traffic overtake PC traffic globally during my @InMobi days.
After roughly a decade, now seeing agentic traffic overtake humans is one such pivotal moments.
Jun 4

BREAKING NEWS: according to CloudFlare Radar Data, Agentic traffic has SURPASSED human traffic across the worldwide internet for HTML webpages.
59
Deepak Babu Piskala retweeted

Jun 4
On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
Jun 4

Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
22
127
1,304
138,659
I've finished 20 of 100 pg odd technical report. One thing is clear - this team has thought deeply about every choice made and it is nice to see their rationale documented in report too. relying on internal benchmarks instead of public, data contamination, lesser reliance on synthetic data, emphasis on data mix, etc. 5% weight on multilingual seems low but fact that this is a reasoning model and not a chat model so focus on math, coding and stem seems natural.
I look forward to trying out these models on copilot soon. #mai #llm

Super excited to announce seven new world-class MAI models today. They represent what we consider a new era in AI designed to keep you in control and on the frontier.
First is our text foundation model, MAI-Thinking-1, exceptionally strong on reasoning and SWE tasks.
- It’s a 35B active parameter MoE with a 256K context window. Independent human raters on Surge prefer it for overall quality in blind side-by-sides versus Sonnet 4.6, and it’s achieved 97% on AIME 2025, the key measure of its general-purpose reasoning abilities.
- It's at 53% on SWE Bench Pro, placing it right alongside Opus 4.6 on one of the toughest coding benchmarks.
- And since we co-designed our models with our own silicon, MAI-Thinking-1 is optimized on our MAIA 200 chip. Benchmarking head-to-head against the GB200, we see 30% better performance per dollar as well as a 1.4x performance-per-watt gain when running our MAI models on the MAIA 200 end-to-end.
Next is MAI-Image-2.5 and its Flash variant. Two super strong models now at #2 on the leaderboards, surpassing the score of Nano Banana 2 on image editing.
Last for now is MAI-Code-1-Flash, our new inference efficient coding model, especially tuned for VS Code and GitHub Copilot CLI.
- Code-1-Flash achieves 51% on SWE Bench Pro, despite having just 5B parameters, putting it closer to Haiku in size but cheaper in cost.
All of this is the foundation for Microsoft Frontier Tuning. It lets you customize our models to create custom, company-specific agents that only you control. You can make our model, your model. Your data. Your agents. Your moat.
Early adopters are already seeing a difference. When we tuned our models for McKinsey’s tasks, MAI delivered the highest win rate, outperforming GPT-5.5 on quality, while being 10x lower on cost.
Also really excited to be collaborating with the amazing team at Mayo Clinic to jointly train a new frontier AI model for healthcare.
Our announcements today mark another milestone on the road to humanist superintelligence. You can learn more and about our other new models in our latest blog: microsoft.ai/news/building-a…

1
1
113
May 27
nice to see fundamental assumptions challenged and reworked.

For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (arxiv.org/abs/2506.14202), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
131
May 26
I saw this video from Anthropic talk claiming "proactive agents". Under the hood it seems to be a trigger mechanism (event or time based) called as routines and framed as proactivity. IMO proactivity is about ambient intelligence not something humanly programmed #claude #gpt youtu.be/eSP7PLTXNy8?si=gV1N…
79
May 20
It is scary if true. This is dominantly the culture at tech companies (optimizing for hikes/promos) goodharting outcomes. sounds like economics 101 > outcomes follow incentives. but young kids pressurized into this ?
May 20

Wharton Professor warns the high school strivers with a sudden "interest" in research
Excellent sheep doing what excellent sheep do
131
May 17
Building Speech AI is live on Amazon 📖
A practitioner's guide covering modern speech recognition (Whisper, wav2vec 2.0, HuBERT, Conformer), neural TTS (VITS, VALL-E, XTTS-v2), audio language models (AudioLM, SpeechGPT, GPT-4o Realtime), real-time voice agents, edge deployment, and the ethics of voice technology.
12 chapters · ~320 pages · runnable Python in every chapter.
For AI engineers building voice systems, researchers tracking the field, executives figuring out voice strategy and anyone navigating the gap between research demos and production.
> 📕 Paperback (live now): amazon.com/dp/B0H1ZXP6YS
> 📱 Kindle (pre-order, July 1): amazon.com/dp/B0GX2WG2ZC
> 🌐 Companion code & site: prdeepakbabu.github.io/build…
If you've shipped production ASR/TTS, I'd love your feedback.
#SpeechAI #MachineLearning #DeepLearning #VoiceAI #BookLaunch
2
121
must watch. if you have been doing LLM frontier and want a quick peek into robotics frontier and transfer.

I promise this will be the best 20 min you spend today! Robotics: Endgame, the sequel to my last year's Sequoia AI Ascent talk, "Physical Turing Test". I laid out the roadmap for solving Physical AGI as a simple parallel to the LLM success story. Be a good scientist, copy homework ;)
And stay till the end, more easter eggs and predictions for your polymarket!
00:30 DGX-1 origin story at OpenAI, I was there in 2016 signing with Jensen and Elon. Heading to the Computer History Museum!
01:42 The Great Parallel
03:31 Robotics, the Endgame
03:39 Why VLAs fall short
04:32 Video world models as the 2nd pretraining paradigm
06:09 World Action Models (WAM)
07:46 Strategies for robot data collection and the FSD equivalent to physical data flywheel for robot manipulation
11:06 EgoScale and the Dexterity Scaling Law we discovered recently
14:00 Physical RL: bridging the last mile
15:39 DreamDojo: an end-to-end neural physics engine for scaling RL in silico
17:00 Civilizational Technology Tree and my predictions for the near future. Spoiler: it's closer than you think.
Thanks to my friends at Sequoia for inviting me back to AI Ascent this year! I had a blast! Last year's talk is attached in the thread if you missed it.
1
79

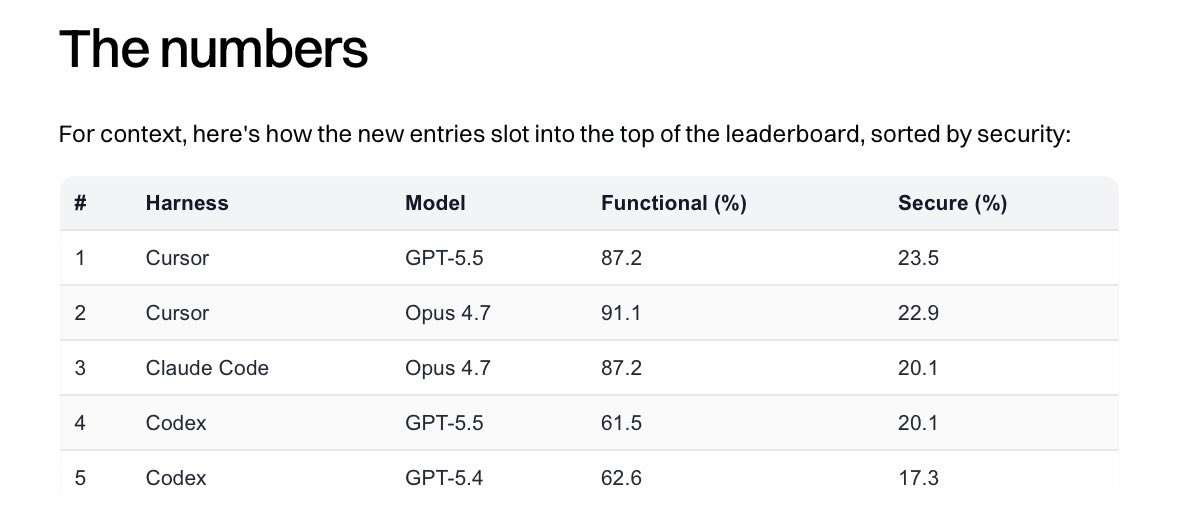
Apr 29
Found this explanation of DAgger that is unintentionally the funniest thing I’ve read today. 😄 (source: claude opus 4.7 explaining) #RL #DAgger
"A surgical resident watches the attending surgeon perform 100 operations. Then she's handed the scalpel. On her first cut she's slightly off — and now she's in a situation the attending never demonstrated. She panics. The attending grabs her hand and shows her exactly what to do at this moment. She tries again. New moment of panic, new correction. After enough of these on-the-job corrections, she's a great surgeon — even on cases the attending never demoed.
That's DAgger. The genius is that it trains the policy on the policy's own states by querying the expert there. The training distribution and the deploy-time distribution start matching, and BC's compounding error vanishes."
64
Deepak Babu Piskala retweeted

Apr 20
This one picture explains why CPUs matter in the era of agents.
Pre agent days required the CPU to tokenize and detokenize.
Today, it needs to do a whole lot more, read databases, make api calls, run orchestrations, decide how to order requests, collect outputs and process, and so much more.
The kind of cpu - more cores or faster cores matters, but is completely dependent on the workload.
open.substack.com/pub/viksne…


11
68
453
27,951
Apr 17
super cool idea to try learn "research taste"
Apr 17

Scientists often make breakthroughs by synthesizing ideas across papers. In our new paper, we ask whether a language model can anticipate this process: given two parent papers, can it generate the core insight of a future paper built on them? 🧵⬇️
2
127
Mar 20
hyper specialization - can it be a competitive benefit for cursor ? atleast it is becoming clear - pretty much every digital work is universally trackable as a coding task. booking flights - sure dom tree nav, cursor nav. create a email - file processing and network commands.

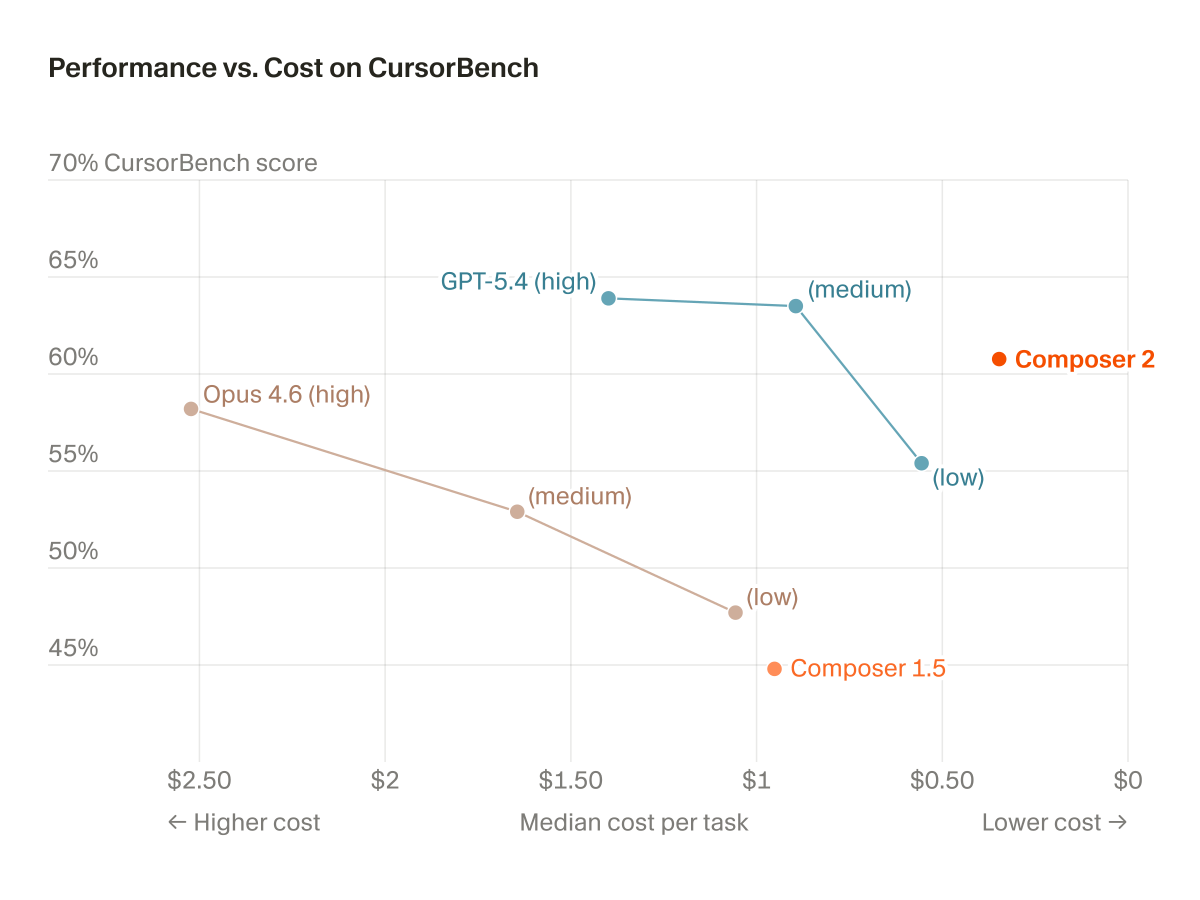
80
Deepak Babu Piskala retweeted

Mar 18
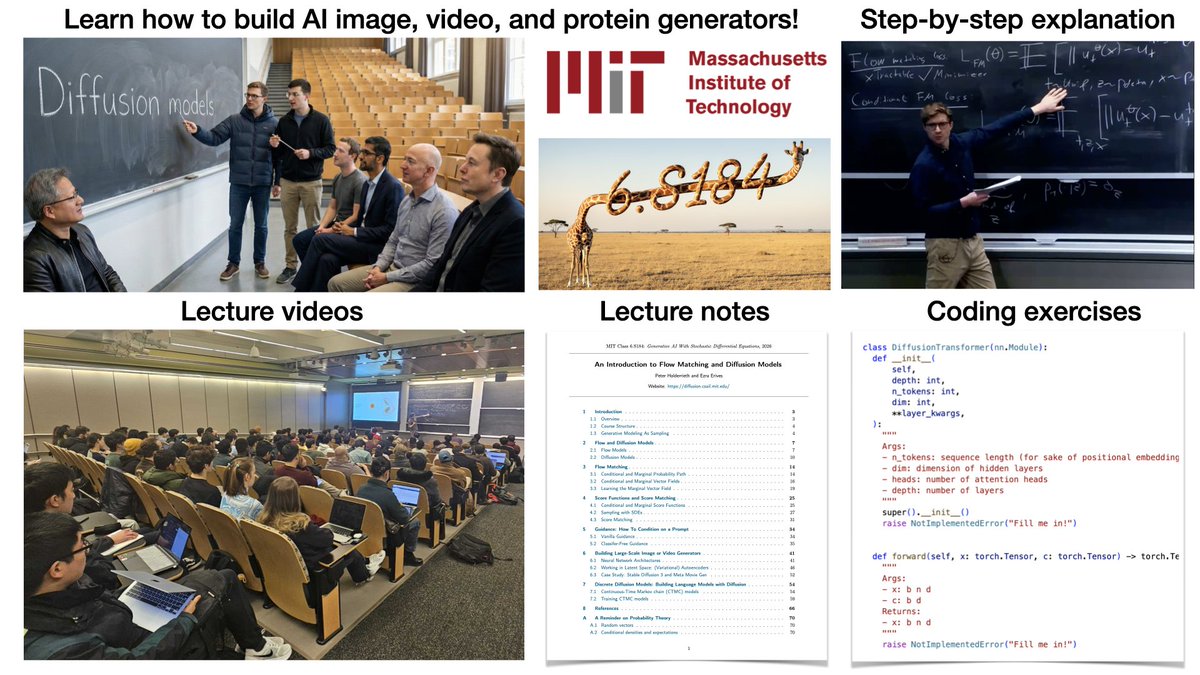
🚀MIT Flow Matching and Diffusion Lecture 2026 Released (diffusion.csail.mit.edu/)!
We just released our new MIT 2026 course on flow matching and diffusion models! We teach the full stack of modern AI image, video, protein generators - theory and practice. We include:
📺 Videos: Step-by-step derivations.
📝 Notes: Mathematically self-contained lecture notes
💻 Coding: Hands-on exercises for every component
We fully improved last years’ iteration and added new topics: latent spaces, diffusion transformers, building language models with discrete diffusion models.
Everything is available here: diffusion.csail.mit.edu/
A huge thanks to Tommi Jaakkola for his support in making this class possible and Ashay Athalye (MIT SOUL) for the incredible production! Was fun to do this with @RShprints!
#MachineLearning #GenerativeAI #MIT #DiffusionModels #AI
15
393
2,240
529,791
Mar 19
Its wierd I heard GPT 5.4 used term "multilingual" to mean programming in more than one language (like py, ts), not human language. Is this a whole new level of semantic understanding ? I so wish to analyze contextual embeddings of word multilingual in the context of coding and human language. #GPT5 #llms #NLU #semantic #understanding
57
Mar 19
This is a very good write-up of current state of things in AI. a bit long read but very insightful.

1
131