
Canadian game developer
Joined July 2008
- Tweets 2,672
- Following 535
- Followers 4,297
- Likes 5,898
109 Photos and videos


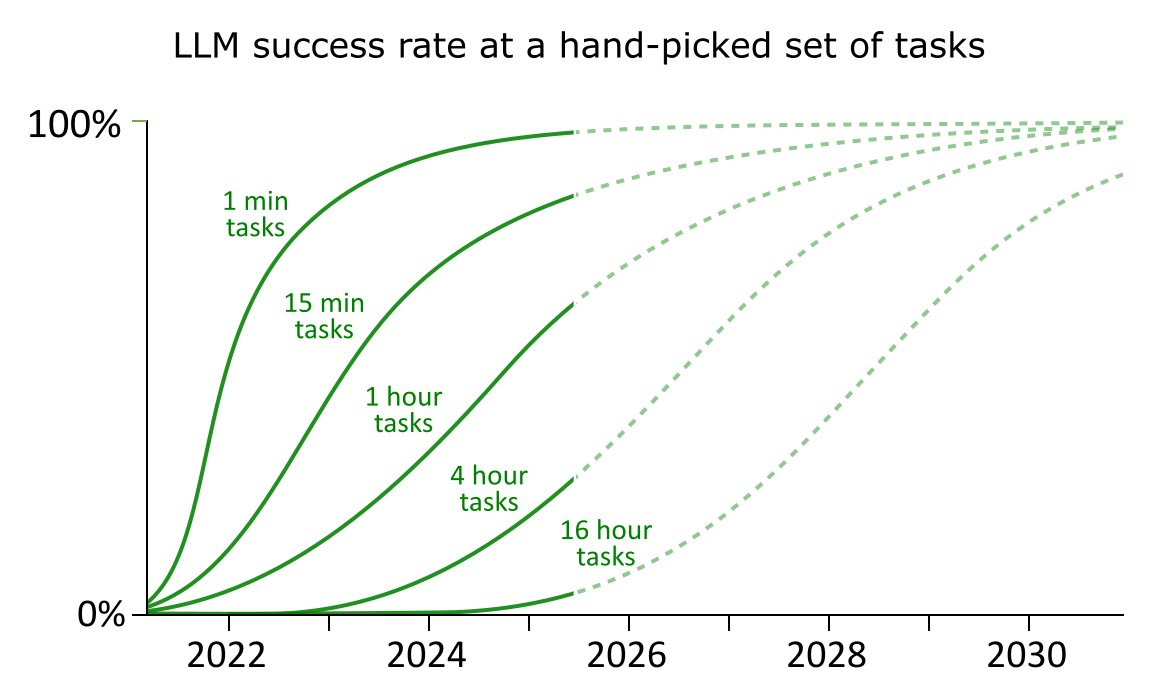










Jeff Preshing retweeted

We’ve been saying this for a while. For the first time, an overwhelming majority of economically valuable tasks people are using LLMs for have been unlocked for open source by the rising tide of open source intelligence. I often offer people a bet that they can’t tell the difference between a kimi we post-train for their complex main agent task and opus 4.8/gpt-5.5, and these days the only time I lose is when they can tell the difference because the FT kimi is so much better

AI advantage is shifting from raw model scale to deep integration with unique organizational data, workflows, and human expertise through continual learning loops. Ideally, this will result in distributed, defensible value rather than winner-take-all dynamics around general models.
We're fully aligned around building the tools necessary (world-class inference, post-training, etc.) to make this a reality for every enterprise.
4
50
4,538
Jeff Preshing retweeted

Jun 11
One shots are nonsense when the corpus is well documented. Try that again, but you can’t use the word Minecraft. x.com/shanselman/status/2019…
Jun 9

Claude 5 Fable (high)
“Make a Minecraft clone”
I’m stunned.. it made this in 20 minutes, one shot.
Multiple Biomes, day time/night time, different ores, Caves & more!
28
20
430
64,830

Jun 11
What's the point of using smarter models if "smarter" means 10% better at finding obscure bugs and having a sassy attitude?
Most of the true productivity gains that coding agents have to offer, which are finite, can be obtained using open-weight models for literally 1/100 of the price. The catch is that you actually need to understand the code you are working on.
At the same time, I still think there's a viable business serving proprietary models. People are willing to pay for Dropbox even though FTP is free, and it's nice to throw a tough problem at a stronger model occasionally (if intellectual property limitations allow it). Plus, there's a whole frontier productizing this stuff.
Unfortunately, Anthropic is currently in the business of spreading tall tales about future improvements, then shaking down enterprise customers. Most of it is based on 2010s LessWrong posts full of category errors, some of which I remember reading back in those days. And their recent hostility toward users in the name of safety is a result of the same ideological recklessness.
1
13
574
Jun 10
I'd rather have faster, more affordable models at existing capability levels.
Jun 10

Fable is a very impressive model. But it is also
- Expensive
- Slow
- Rate limited
- Nerfed for important R&D tasks
- Not private (retains prompts/responses even for enterprise users)
The difference between owned and rented intelligence gets clearer by the day.
4
771
Jun 9
Coding by hand isn't over. I'm building a multithreaded system in C and agents are NO HELP WHATSOEVER. Writing the API, data structures and main loops by hand is the only way to think the problem through! Fortunately, my brain hasn't been completely fried by agents (yet), so I still have a chance to get it right.
Once everything is up and running, I'll gladly use agents to extend it. They work great on code that already exists.
9
4
54
5,131
Jun 9
And by "work great", I mean they generate acceptable (or nearly acceptable) code if you specify what you want clearly enough. That doesn't always mean the work gets done faster, better or cheaper. Those require human skill and agents have introduced a whole new learning curve.
1
4
616
Jun 7
People have been speculating that recursively self-improving AI could lead to loss of human control since the 1960s. Does anyone really believe this anymore?
AI labs are already using AI to improve their own products, and have been for a long time. They're even running agent swarms to search for new optimization ideas and automatically test those ideas end-to-end. So in a sense, recursive self-improvement is already here. Maintaining control of these systems is trivial.
What about the future, you might ask? Well, what does it mean to improve an LLM? It means making an LLM that is faster, cheaper, or better at problem-solving (higher benchmark scores). What difference does it make how those improvements get made? If the process works, it should output a better LLM at the end. This LLM will have the same API as every other LLM that came before it. It's a drop-in replacement. Where is the loss of control?
The only "loss of control" that software companies should worry about is delegating too much responsibility to coding agents and ending up with a messy, unmaintainable codebase, causing their own productivity to plummet. If Anthropic were to talk about that risk, I would have no objection. Instead, they're appearing on CNN and spreading needless alarmism by making comparisons to nuclear weapons. cnn.com/2026/06/05/business/…
2
6
567
Jun 6
If recursive self-improvement can make AI faster, cheaper and more dependable, then by all means please bring it on, because right now it is way too expensive for what you get!
Jun 4

Anthropic is calling for top AI labs to weigh slowing the pace of development, suggesting that AI systems are advancing so rapidly that they may soon be able to improve themselves without human intervention in ways that could pose societal risks. on.wsj.com/4ulkmFh
3
1
6
1,154
Jun 5
"AI will be a return to realness and physicality." (17:28)
Jun 4

Second for second, @tylercowen packs more substance into a talk than anyone I'm aware of. This is a clear, non-hysterical, and somewhat soothing discussion of our AI future.
1
531
May 21
I believe it was Von Neumann who originally said this
May 21

it's important, i think, to resist the temptation to ship garbage
8
1,962
May 17
These are all great use cases for LLMs, but I don't see why it should cost more than a few hundred bucks a month!
May 15

People freaking out over my AI spend. What nobody sees: Part of what excites me so much about working on OpenClaw is that I'm trying to answer the question:
How would we build software in the future if tokens don't matter?
We constant run ~100 codex in the cloud, reviewing every PR, every issue. If a fix on main lands, @clawsweeper will eventually find that 6 month old issue and close it with an exact reference.
We run codex on every commit to review for security issues (as it's far too easy to miss).
We run codex to de-duplicate issues and find clusters and send reports for the most pressing issues.
We have agents that can recreate complex setups, spin up ephemeral crabbox.sh machines, log into e.g. Telegram, make a video and post before/after fix on the PR.
There's codex that watch new issues and - if it fits our documented vision well, automatically create a PR of it. (that then another codex reviews)
We have codex running that scans comments for spam and blocks people.
We have codex instances running that verify performance benchmarks and report regressions into Discord.
We have agents that listen on our meetings and proactively start work, e.g. create PRs when we discuss new features while we discuss them.
We build clawpatch.ai to split all our projects into functional units to review and find bugs and regresssions.
We do the same split for security with Vercel's deepsec and Codex Security to find regressions and vulnerabilities.
All that automation allows us to run this project extremely lean.
3
886
May 5
It's not true that nobody reviews compiler output. In game development and other fields, the ability to read and understand compiler output is pretty common. The popularity of godbolt.org is evidence of this.
Sometimes there's an issue to fix and symbols are missing, the debugger isn't displaying something correctly, or all you have is a crash dump with limited information. At those moments, reading disassembly is a big advantage.
I'm open to arguments about the viability of vibe coding, but not arguments based on falsehoods.

Interesting article on treating agent output like compiler output (and why)
skiplabs.io/blog/codegen_as_…

1
1
17
1,617
Apr 30
If companies want to keep restricting access to their best models, that's fine by me. Open models are already powerful enough to act as excellent coding agents and will only get better from here. I still reach for Codex when I want the best answer, but I think relying on cutting edge models for extended periods of time is generally not a good sign, not to mention very expensive.
Apr 30

I worry deeply already about companies controlling access to very powerful AI, which will come in a soft form with very expensive subscriptions.
This is a step further, with the government confusingly exerting control without clear explanation.
This control of AI can create massive dystopian societies. It’ll rapidly lead to concentration of power.
Having open models follow closely in capabilities is a great way to minimize political and power games here.
1
3
794

all the best programmers i know spent effort testing the practical limits of AI. they identified a sweet spot that delivers productivity improvements while retaining control of design, implementation, and cognitive ownership so they could remain responsible and accountable.
Apr 25

All the best programmers I know are starting to write code by hand again
21
38
414
21,610
Jeff Preshing retweeted

Apr 25
almost hesitating to post this so as not to sound like a broken record, but yeah folks I've been saying this for months now - no production software where people are on call for downtime is being written overnight unattended by AI agents. If it is, those pager incidents are increasing at a troubling rate.
please someone prove me wrong but I'm pretty sure its all side projects / zero-to-one teams.
Even the best founders I know are eyes on the model outputs to fend off the slop. Still locked in, still using coding agents for 99% of code, and still shipping like crazy. There's a broad spectrum between "code by hand" and "claude take the wheel"
Apr 23

Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit.
Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe.
But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope.
I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit?
Nope. Not buying it.
PS: it may also be that I have an IQ of 82 and can't figure it out.
37
27
439
49,474
Apr 23
There are only two hard things in Computer Science: cache invalidation and naming things. - Phil Karlton
Apr 23

It's crazy to me how much of software development is 'finding the right way to describe something that doesn't exist yet'.
It's a language problem. Figure out the right nouns and verbs, and you can build a system.
And LLM's are GREAT at helping you with this.
1
1
2
653
Apr 21
One could argue that as models grow stronger, narrowing the scope of a task will matter less and less, because agents will eventually figure out all the details. Sure, I can see that trend continuing, and I welcome it, but I don't think Murphy's Law is about to disappear either.
Apr 21

From now on, nobody should be allowed to say anything about AI unless they've watched @badlogicgames's talk: youtube.com/watch?v=RjfbvDXp…
This slide in particular is gold. There are good ways to use coding agents and there are bad ways. These are the good ways! Other people on Twitter are gradually reaching the same conclusions, so save yourself some time and just watch Mario's talk. (I don't think this list will fundamentally change with future models, either — even if the benchmarks reach 100%. Disagree? Tell me why.)
1
2
690
Apr 21
"Being gaslit every step of the way makes the process stressful as hell." 😲
The trick is to keep your agents on a short leash. They're great at automating well-scoped, well-specified knowledge work, but you never want to be in the dark as to what's going on because dragons can show up very quickly.
I do believe coding agents will make programmers more productive in the long run (though Parkinson's Law will surely remain a thing), but I think it'll only end up working out to about ~25% faster than our previous velocity overall.
Apr 20

I've been using Claude Code exclusively for 6 months and I'm still not convinced on this whole AI thing.
There are some *seriously* insidious problems that worry me, and I don't see them being fixed any time soon.
Every release of a new model, I see hundreds of posts where people think because they one-shotted X or Y, software jobs are cooked (I've probably made one or two of these posts myself).
But none of those examples are actually representative of real-world software.
If I set it to work on an ambiguous or highly complex problem that has a lot of branching in the solution space, I've noticed the following:
- It can often generate a working solution in one-shot, which gives me a false sense of confidence that the AI knows exactly what it's doing.
- As I continue to work the problem, I've noticed the AI will start to narrow its focus more and more, not considering how a fix or solution plays into the big picture.
- The quality of a solution depends on *how* I prompt it, which is really, really bad. Software engineering should be deterministic, not a dice roll.
- It will often ignore instructions I have explicitly stated in the rules file, which removes any confidence I have in the code it generates.
- It consistently overstates its confidence in a solution. I literally just got this response from Claude: "I overstated that. Honest answer: it depends on the scene and implementation; the 2–4× figure was too confident." If I had never pushed back, I would have been operating on incorrect information.
- It is far too agreeable. If I'm not careful in my wording, the AI will blindly follow my instructions, even if they are suboptimal. I want a real coding partner that challenges my ideas, not an ass-kisser.
Don't get me wrong—AI has helped me build some amazing things faster than I ever could without it.
But the more I use it, the more I begin to question the direction things are headed.
If the AI was more direct about what it (not) capable of, it'd be a lot easier to work with. But being gaslit every step of the way makes the process stressful as hell.
Going back to manual coding isn't even an option since the value of having AI *potentially* generating the correct code in 1/10 or 1/100 of the time is literally too good to pass up on.
Sorry for the rant, drank way too much cold brew this morning.
1
3
816
Apr 21
From now on, nobody should be allowed to say anything about AI unless they've watched @badlogicgames's talk: youtube.com/watch?v=RjfbvDXp…
This slide in particular is gold. There are good ways to use coding agents and there are bad ways. These are the good ways! Other people on Twitter are gradually reaching the same conclusions, so save yourself some time and just watch Mario's talk. (I don't think this list will fundamentally change with future models, either — even if the benchmarks reach 100%. Disagree? Tell me why.)
3
8
1,607