
Scientist at Amazon Alexa AI. I’m interested in applied machine learning and building software systems. Views are my own.
Joined May 2011
- Tweets 609
- Following 93
- Followers 347
- Likes 286
29 Photos and videos













Peter Schulam retweeted

31 Dec 2021
Check out work by @david_sontag @ShalitUri in this area. Also @pschulam @suchisaria who use Gaussian processes instead of neural nets.
1
1
2
Peter Schulam retweeted

5 May 2021
Gotta love that sweet sweet irony

1
2
13

4 May 2021
For some classification problems, a first analysis usually uncovers several heuristics that would work ~50-75% of the time. My gut reaction to this is often: “Do we really need to use machine learning here?” After all, I don’t want to be the fool with a hammer looking for nails.
1
1
4 May 2021
In fact, ML can be especially impactful in situations like this. The heuristics make excellent features for a linear model. The result is often good enough (or is a strong baseline). Keeping this in mind gives me a nice “playbook” for kicking off work on a new project.
1

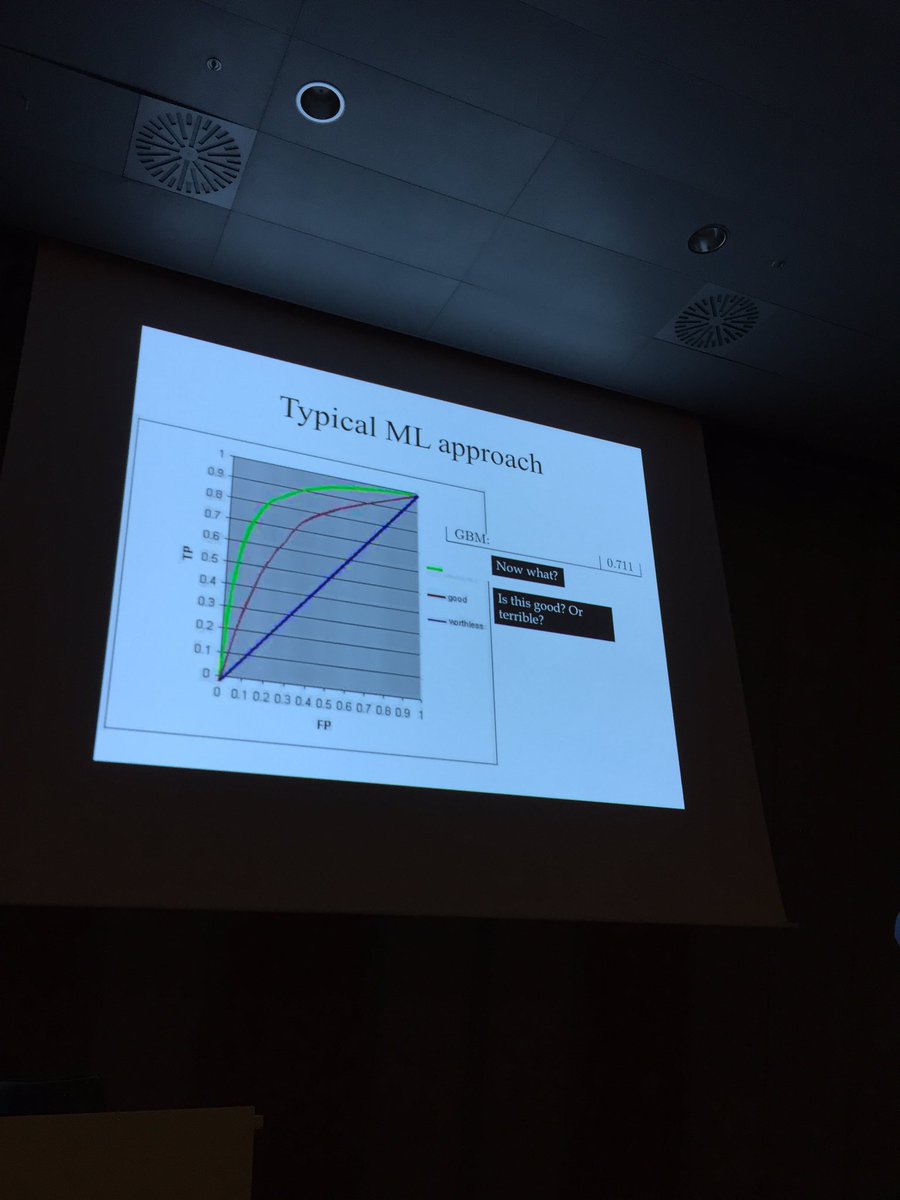
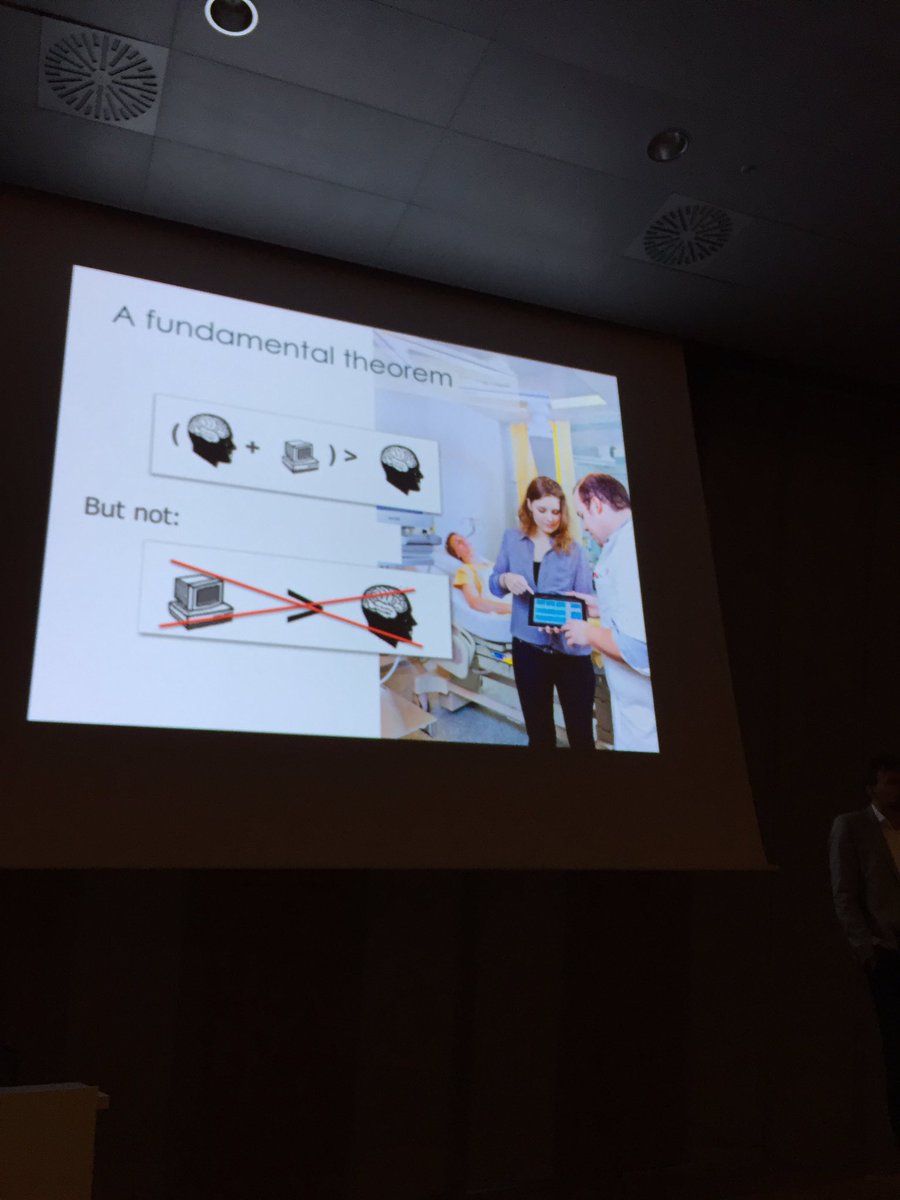
3 May 2021
The majority of ML case studies floating around the internet are, unfortunately, fast food. I think this is a problem because we can’t share, learn from, and discuss our “recipes” as practitioners.
1
3
2 May 2021
There are lots of recent papers in the ML literature that look at how to detect when we can’t make reliable predictions. I often see this described as detecting “out of distribution” samples. This is unusual to me, though. The same value can come from two different distributions.
2
13
2 May 2021
When we talk about covariate shift, the support of the train and test distributions may be the same but the frequency of seeing a given input may have changed. This is important when we use low-capacity models, but maybe less so with the richer classes we use today.
1
3
2 May 2021
I think this might follow from results reported by Jonathan Byrd and @zacharylipton in this great paper:
arxiv.org/abs/1812.03372
2
1 May 2021
Stats journals often have a separate “applications” track. Does something like this exist for machine learning? I’m looking for good write ups of the nitty gritty details behind successful ML applications.
2
1
8
2 May 2021
The thread below is the kind of thing that we need more of in “applied ML literature”. In this case, they didn’t really need a model, but I would love to read more about this kind of clever detective work.
30 Mar 2021

After 17 years, we finally “cracked” a $100M churn problem at PayPal. Zero fancy tech. Just a spreadsheet, some simple SQL, and a physicist named Ben. 👇🏼
1
1
2 May 2021
This reminds me of what @lawrennd calls “decomposition” in his three D’s of ML system design.
inverseprobability.com/talks…
1
2 May 2021
Very interesting paper from @laurence_ai:
openreview.net/pdf?id=Rd138p…
Not the intended message, I think, but brought one thing into focus for me:
1
1
2 May 2021
In statistics, the data is the object of interest. Models are only useful if they help us learn about the process that generated it. In machine learning, the model is the object of interest. Data is only useful if it helps us to learn a function that does the job we need.
1
2
6
Peter Schulam retweeted

3 Jun 2020
We've heard lots about #MachineLearning in healthcare, but usually with few specifics. A new paper in @AnnalsofIM, featuring our very own @suchisaria & @pschulam, cuts through the buzz and discusses the real applications and real benefits of clinical #AI: acpjournals.org/doi/10.7326/…
2
10
Peter Schulam retweeted

2 Jun 2020
Excited about this paper on reporting and implementing interventions Involving Machine Learning and AI. Hope is to get past some of the hype. @ADAuerbachMD @suchisaria Adam Wright and Peter Schulam acpjournals.org/doi/10.7326/…
2
9
Peter Schulam retweeted
22 May 2020
We've just published our first of many blog posts!
Using our proprietary dataset and analytic capabilities, we explored the uncertainties & issues around initially triaging #COVID patients.
medium.com/@BayesianHealth/f…
#Coronavirus #Hospitals
1
3
Peter Schulam retweeted
17 Apr 2020
Great article in IEEE Spectrum about how hospitals are using #AI and #MachineLearning tools like ours to triage #COVID19 patients.
Excellent quotes from our own Director of #CriticalCare Solutions, Dr. Dan Burke!
spectrum.ieee.org/the-human-…
2
5