
6 Photos and videos




Pub2Post retweeted

🚀 Thrilled to announce that @Pub2Post is now part of the Discovery & Delivery partners together with giants like @ResearchGate @webofscience @medrxivpreprint (and many others) on the @silverchairnews platform!
An incredible milestone for this new tool — empowering scholars everywhere to share their work with confidence and introduce a fresh, lightweight approach to academic communication ✨📚
pub2post.com
@JenniferARegala

2
10
1,435
Pub2Post retweeted
🚀 @Pub2Post dominates the field in oncology and patient education!
📊 Highest FRE Score (76.1) ✅
📉 Lowest SMOG Index (4.9) ✅
Outperforming OpenAI, Claude, Gemini others in readability.
🔬 #LLMs in #OncologyEducation just got a new benchmark.
#AI #MedEd #Pub2Post #ISMTE2025 #HealthTech @Urology_AI @USC_Urology

1
9
16
1,777
Pub2Post retweeted
[🔊podcast] Revolutionizing Neobladder Surgery?
This new study published in @EurUrolOpen led by @MariaChiaraMCS @bernardorocco73 @AgileGroupUro offers insights into robotic-assisted neobladder reconstruction, addressing its challenges and techniques for improvement
🔧 Key Techniques - Strategies enhance ileal descent toward tension-free anastomosis
🤝 Surgeons' Consensus - 86% find ileourethral approximation demanding
📽️ Video Insights - Visual guide for safer, effective reconstruction
tnyp.me/3CoTA6SM/x
Podcast powered by @Pub2Post
9
15
1,673
Pub2Post retweeted

24 May 2025
This is pretty cool and I can definitely see the value - nice work @Cacciamani_MD and team!
Look forward to seeing it in action

Pub2Post to Showcase Media Content Innovation at the 47th Annual Society for Scholarly Publishing Meeting
#Pub2Post is excited to announce its participation in the 47th Annual Meeting of the Society for Scholarly Publishing (SSP), taking place May 28–30, 2025.
This year’s theme, Reimagining the Future, speaks directly to our mission of redefining how scholarly content is translated into dynamic, engaging media.
At #Pub2Post, we specialize in transforming academic and scientific publications into a variety of rich media formats—including social media posts, videos, podcasts, infographics, and interactive visuals—within seconds. Our presence at #SSP2025 will highlight how our platform empowers publishers and researchers to extend the reach and impact of their work through innovative content creation tools.
Attendees of #SSP2025 will have the opportunity to explore how Pub2Post can streamline media production, improve audience engagement, and enhance knowledge dissemination across disciplines.
We look forward to connecting with the scholarly publishing community and demonstrating how Pub2Post is helping to shape the future of academic communication.
For more information or to arrange a meeting during the conference, please visit us!
@JenniferARegala @Cacciamani_MD @karangill96
1
2
4
1,063

Pub2Post to Showcase Media Content Innovation at the 47th Annual Society for Scholarly Publishing Meeting
#Pub2Post is excited to announce its participation in the 47th Annual Meeting of the Society for Scholarly Publishing (SSP), taking place May 28–30, 2025.
This year’s theme, Reimagining the Future, speaks directly to our mission of redefining how scholarly content is translated into dynamic, engaging media.
At #Pub2Post, we specialize in transforming academic and scientific publications into a variety of rich media formats—including social media posts, videos, podcasts, infographics, and interactive visuals—within seconds. Our presence at #SSP2025 will highlight how our platform empowers publishers and researchers to extend the reach and impact of their work through innovative content creation tools.
Attendees of #SSP2025 will have the opportunity to explore how Pub2Post can streamline media production, improve audience engagement, and enhance knowledge dissemination across disciplines.
We look forward to connecting with the scholarly publishing community and demonstrating how Pub2Post is helping to shape the future of academic communication.
For more information or to arrange a meeting during the conference, please visit us!
@JenniferARegala @Cacciamani_MD @karangill96
2
4
1,647
Pub2Post retweeted

21 May 2025
🔍 How Can AI Improve Urology Research Readability?
🤖 AI Tools models can significantly improve text clarity
📚 Enhanced readability increase research accessibility tnyp.me/kV3BWguM
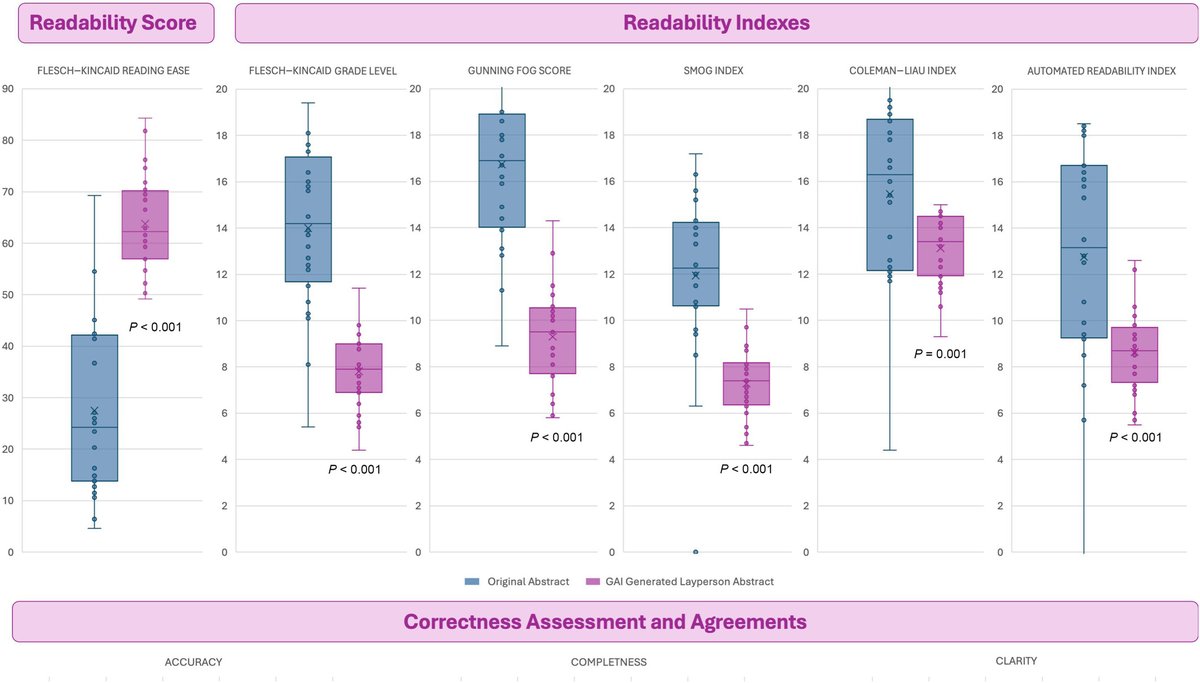
1
7
22
2,001
Pub2Post retweeted
🤖 Will AI Transform Outpatient Urology? tnyp.me/5DAB1UsW/x
AI is reshaping outpatient urology by enhancing clinical workflows and reducing administrative burdens
🩺 Clinical Support - AI aids decision-making from prediagnosis to posttreatment
📈 Efficiency Boost - Automates routine tasks, freeing clinicians for patient care
🛠️ Remaining Hurdles - Workflow adaptation and validation needed for smooth adoption
#HealthcareAI #Urology #AI #Pub2Post
@JacobHershen @USC_Urology @Urology_AI @Current_Urology @shariat
post powered by @pub2post

6
7
1,200
Pub2Post retweeted
🤖 Can AI Chatbots Educate Patients? tnyp.me/HdjPOeyX/x
This study reviews AI chatbots' role in urology education, highlighting their potential benefits and challenges
💡 Emerging Role - AI chatbots can complement patient education if prompted for readability
📄 Rapid Creation - Potential to quickly generate lay research summaries and materials
👁️🗨️ Expert Review - Final validation by experts is crucial for accuracy and reliability
@NYUUrology @LoebStacy @Current_Urology @DrShariat
#AI #HealthEducation #Chatbots #Urology #Pub2Post
post powered by @pub2post

5
3
706
Pub2Post retweeted
🤖 Can AI Chatbots Revolutionize Urology?tnyp.me/7kZq1Zou/x
A study reviews the role of generative AI chatbots in urology, offering insights into benefits and hurdles
📚 Patient Education - AI chatbots enhance patient knowledge and accessibility
😊 Satisfaction Boost - Improved patient satisfaction and reduced clinic burden
🔒 Privacy Concerns - Data privacy and accuracy still pose challenges
#Urology #AI #Healthcare #Pub2Post #GAI
post powered by @pub2post @DrShariat @Current_Urology @kgbyrnes

4
3
453
Pub2Post retweeted
📢 New Special Issue from Current Urology:
"Practical AI for Practicing Physicians" 🤖🩺
Explore how AI is transforming urology — from clinical trial matching and patient education to men's health, pediatrics, ethics & more.
🔍 must-read articles
✍️ Leading experts
📈 Real-world applications
Read now 👉 shorturl.at/2cA68
#AIinUrology #DigitalHealth #MedEd #ChatGPT #LLM #MensHealth #Oncology @DrShariat @EthanLayne20 @LoebStacy @ConnerGanjavi @kgbyrnes @JacobHershen @karangill96 @justindubinmd @CaseySeidemanMD @prokarurol

7
18
1,374
Pub2Post retweeted
🔬 How is AI Transforming Cancer Care? tnyp.me/MZUfQeeJ/x
New research explores how generative AI (GAI) is reshaping oncology from diagnosis to treatment
🖼️ Enhanced Imaging - GAI integrates multimodal data for better diagnostics
💡 Smart Decisions - Optimizes clinical guidelines & treatments
📈 Future Potential - Could boost research and patient care
#AIinOncology #Pub2Post @ConnerGanjavi @EthanLayne20 @DrShariat @Current_Urology @USC_Urology @Urology_AI @MichaelEppler7 @RodlerSeverin @melamedmd
post powered by @pub2post

4
4
599
Pub2Post retweeted
🚨 Just dropped: Special Issue on "Practical AI for Practicing Physicians" shorturl.at/2cA68
💡 AI won’t replace physicians — but those who use AI will replace those who don’t
Explore how AI is transforming clinical care, workflows, and decision-making @Cacciamani_MD in @Current_Urology @DrShariat @EthanLayne20 @LoebStacy @ConnerGanjavi @kgbyrnes @JacobHershen @karangill96 @justindubinmd
@CaseySeidemanMD @prokarurol

1
4
10
948
Pub2Post retweeted
🤖 How Are GPTs Transforming Urology?
Our study analyzes GenAI usage in urology, noting shifting attitudes over 1 year
📈 Academic Growth - 86% now use GPTs for academic tasks, up from 52% last year
🔄 Clinical Hesitance - Use in clinical tasks like treatment decisions has dropped
👨⚕️ Human-Centered - Insights guide future AI development in healthcare
#GenerativeAI #Healthcare #AIInUrology #Pub2Post @MUN_journal
tnyp.me/cpEqPqkj/x
post powered by @Pub2Post

1
15
18
2,273
Meet Pub2Post, your GAI-powered assistant designed to revolutionize content dissemination for journals and publishers. 🚀 Seamlessly integrate it into your workflow to enhance global reach, engagement, and impact—all in just one click!
✨ Key Features:
🔹 Pub2Social – Automatically generate and post content across multiple social media platforms, tailored for different audiences and languages.
🔹 Pub2People – Adapt research for lay audiences with readability-enhanced summaries and text-to-voice features.
🔹 Pub2Press – Effortlessly create and distribute press releases to maximize media coverage and visibility.
🔹 Pub2Blog – Instantly transform research findings into blog-friendly formats for broader outreach.
🔹 Pub2Pod – Convert academic content into engaging podcast episodes to reach auditory learners.
🔹 Pub2Pic – Generate compelling visuals and infographics to simplify complex research and boost engagement.
With unique features such as fact-checking, summarization, translation, and accessibility tools, Pub2Post ensures your scholarly content reaches the right audience—accurately and effectively.
📢 Ready to revolutionize academic content sharing? Try Pub2Post today!
Schedule your demo support@pub2post.com
2
4
342
Pub2Post retweeted
🔊Survey on ChatGPT awareness among U.S medical students:
🔍 96% heard of ChatGPT
✍️ 52% used for coursework
📚 Common in pre-clerkship for concepts
🚨 Concerns: inaccuracy, privacy, plagiarism
#LLMs #MedicalEducation #GenerativeAI #ChatGPT #Pub2Post @ConnerGanjavi @MichaelEppler7 @USC_Urology @Pub2Post @PLOS @Urology_AI
1
6
19
3,438
Pub2Post retweeted
🔊Framework Aims to Enhance Evaluation of Language Models in Healthcare
Pittsburgh, October 2024 - A newly proposed framework seeks to enhance the evaluation of large language models (LLMs) in healthcare by emphasizing human evaluation processes. This comprehensive framework, known as QUEST, is designed to address current gaps in the reliability and applicability of these models, which are increasingly used in medical decision-making support and patient education.
The surge in the use of generative artificial intelligence (#GenAI) and LLMs, such as #gpt4, in healthcare necessitates robust evaluation methods to ensure these technologies are safe, accurate, and effective. This study identifies significant gaps in the current evaluation methodologies through a literature review of 142 studies. To bridge these gaps, the researchers propose #QUEST—a framework subdivided into planning, implementation, and adjudication phases, focusing on five core evaluation principles, namely Quality of Information, Understanding and Reasoning, Expression Style and Persona, Safety and Harm, and Trust and Confidence.
The context for this study is set against the backdrop of the rapid adoption of LLMs in healthcare. #LLMs possess the potential to transform patient care by integrating vast medical knowledge into healthcare workflows, acting as clinical decision support systems, and enhancing health literacy. However, existing evaluation practices often rely on automated metrics that lack the depth necessary to fully capture the human-like interactions these models are intended to replicate.
The methods employed in this review involved a detailed examination of various human evaluation strategies across medical specialties. The findings highlighted the prevalent reliance on automated metrics, underscoring the need for human evaluators to assess key qualities such as empathy, bias, and logical reasoning which are better captured through human judgment.
The study's authors suggest that QUEST will enable more consistent, high-quality evaluations that align closely with the safety and effectiveness benchmarks required in healthcare. "Adopting standardized human evaluation practices is critical for advancing the use of LLMs in medicine," writes @yanshan_wang , the study's principal investigators. "QUEST provides a structured approach to systematically evaluate these models, ensuring they meet the unique challenges presented by medical applications."
This framework not only seeks to improve current evaluation practices but also to catalyze further research in this burgeoning field of #GenAI and healthcare, aiming to enrich future developments with reliable, reproducible human assessment methodologies.
As healthcare systems increasingly turn to artificial intelligence for support, this study highlights the importance of a comprehensive and practical evaluation framework like #QUEST, which promises to align the current LLM evaluations with high standards of patient safety and clinical effectiveness. Future directions will explore the integration of this framework across diverse medical domains, further innovating on the intersection of technology and healthcare.
Tam, T. Y. C., Sivarajkumar, S., Kapoor, S., Stolyar, A. V., Polanska, K., McCarthy, K. R., Osterhoudt, H., Wu, X., Visweswaran, S., Fu, S., Mathur, P., Cacciamani, G. E., Sun, C., Peng, Y., & Wang, Y. (2024). A framework for human evaluation of large language models in healthcare derived from literature review. npj Digital Medicine, 7(258). tnyp.me/GsldjHvW @npjDigitalMed @Pub2Post
1
6
10
3,502
Pub2Post retweeted
20 Aug 2024
Effects of Long and Short Ejaculatory Abstinence on Sperm Parameters
📊 Longer abstinence boosts sperm concentration (MD: 8.19; p <0.01)
💧 Increases sperm volume (MD: 0.96; p <0.01)
🔍 Short abstinence improves progressive motility (MD: -1.83; p <0.01)
tinyurl.com/bde5ratw
1
4
10
1,332
Ready for the next academic revolution?
Create automatically engaging and accurate social media posts to share scientific knowledge
pub2post.com
1
5
485