
The only Python IDE you need. Built by @JetBrains, part of @JetBrainsData
Joined January 2010
- Tweets 7,839
- Following 28
- Followers 71,547
- Likes 4,867
1,434 Photos and videos














Pinned Tweet
PyCharm debugging just got a serious upgrade in 2026.1 🚀
Introducing debugpy – Microsoft’s open-source debugger. It’s now available as a debugger backend in PyCharm and offers:
✅ DAP-based communication
✅ Better async debugging
✅ Improved “Attach to Process” support
✅ Stronger alignment with the Python ecosystem
Enable it via:
Settings | Python | Debugger | debugpy
Explore what’s new in PyCharm 2026.1 → jb.gg/pcwn
2
2
23
1,853

Jun 11
Choosing a Python AI framework is easier when you start with one question:
What are you building?
Here’s how to choose the right Python framework for your project:
📊 Working with structured data?
• Use scikit-learn for quick classical ML workflows.
• Use XGBoost when accuracy on tabular data is the priority.
Best for: forecasting, classification, risk scoring, business analytics.
🧠 Building deep learning models?
• Use PyTorch for research, experimentation, and custom architectures.
• Use TensorFlow when production deployment matters most.
• Use Keras when you need fast prototyping.
💬 Building LLM-powered apps?
• Use LangChain for RAG, agents, memory, and tool use.
• Use Hugging Face to access and fine-tune pre-trained models.
🎯A simple rule of thumb:
• Structured data → scikit-learn / XGBoost
• Deep learning research → PyTorch
• Production deployment → TensorFlow
• Fast prototyping → Keras
• LLM apps → LangChain / Hugging Face
Read the full guide: 🔗 jb.gg/py-ai 🔗
#Python #MachineLearning #AI #DataScience #PyCharm
2
2
26
1,606
FastAPI Claude Code sounds like a shortcut.
But in this workflow, the agent doesn’t just get a prompt. It gets a project setup:
✅ uv for the environment
✅ Ruff for linting
✅ ty for type checking
✅ Project rules for direction
✅ PyCharm for review and validation
▶️ Watch the full video on building a FastAPI app with Claude Code, PyCharm, and Astral tools: youtube.com/watch?v=V3_c4kCo…
2
2
28
2,184
Which agentic AI framework fits your project?
Choose based on what your agent needs to do – not just what’s popular.
Start with the biggest requirement:
1. Control and reliability 🧭
Use graph-based frameworks for structured workflows, checkpoints, and predictable paths.
Best fit: LangGraph, OpenAI Agents SDK
2. Teamwork and flexibility 🤝
Use role-based or chain-based frameworks when agents need to collaborate or decide the next steps dynamically.
Best fit: AutoGen, CrewAI, LangChain
3. Knowledge-heavy agents 📚
Use retrieval-based frameworks when accurate context matters more than autonomous action.
Best fit: LlamaIndex, Haystack
4. Governance 🛡️
For enterprise oversight, auditability, and HITL workflows.
Best fit: Semantic Kernel
5. Speed ⚡
For lightweight demos, experiments, and early ideas.
Best fit: smolagents
6. Tool and data access 🔌
For API and data workflows.
Best fit: Phidata
A quick rule of thumb:
• Costly mistakes? Prioritize control.
• Poor context? Prioritize retrieval.
• Strict oversight? Prioritize governance.
• Early idea? Prioritize simplicity.
Read the full comparison: 🔗 jb.gg/ag-frameworks 🔗
3
1
15
3,600
The best AI coding advice might be: Don’t code yet.
1️⃣ Make a branch
2️⃣ Read the roadmap
3️⃣ Write the feature spec
4️⃣ Ask questions
5️⃣ Define validation
Then build.
That’s how spec-driven development keeps agentic coding small, reviewable, and yours.
Watch the full video on #FastAPI #ClaudeCode PyCharm: 🔗 youtube.com/watch?v=V3_c4kCo… 🔗
2
1
10
849
Not every agentic AI framework solves the same problem.
The simplest way to narrow your choice is to start with your project type.
Do you need reliable branching workflows, agent teamwork, knowledge retrieval, enterprise governance, lightweight experiments, or API-heavy automation?
This table maps each use case to the orchestration model and frameworks that fit best.
Read the full comparison: jb.gg/ag-frameworks
1
6
15
1,302
At #PyConUS 2026, the PyCharm team brought live demos, AI agent talks, and plenty of coffee to the JetBrains booth! ☕
It was great meeting so many Python developers, sharing new features, and hearing how you use PyCharm every day.
Thanks to everyone who stopped by!
Watch the full tour here → youtube.com/watch?v=fv8eFmww…
3
10
746
Before your agent writes code, give it a constitution:
✅ Mission
✅ Tech stack
✅ Roadmap
✅ Rules for what comes next
That’s spec-driven development – turning “build this” into a workflow the agent can follow and you can review.
Watch the full video on #FastAPI Claude Code PyCharm, with spec-driven guardrails: ▶️ youtube.com/watch?v=V3_c4kCo…
2
2
14
1,119
Building an AI agent? Don’t start by asking “Which framework is best?”
Start by asking “What kind of system am I building?”
Agentic AI frameworks are becoming a core layer for building autonomous apps, but choosing one depends on what you need most:
• Control → LangGraph, OpenAI Agents SDK
• Fast prototyping → LangChain, CrewAI
• Knowledge-heavy agents → LlamaIndex, Haystack
• Enterprise governance → Semantic Kernel
• Lightweight experiments → smolagents
• Tool-heavy workflows → Phidata
Compare the top agentic AI frameworks for 2026 and find the right fit for your project: jb.gg/ag-frameworks
1
22
1,592
Looking for a practical AI project that is more than just another classifier?
Build a real-time object detection app with #TensorFlow and PyCharm!
You’ll start with your laptop webcam, use a pretrained SSD MobileNet V2 model, draw live bounding boxes with OpenCV, and validate the pipeline in a PyCharm notebook.
Then, as an optional next step, deploy it to #ReachyMini and turn detections into object tracking, antenna reactions, and a live dashboard.
Read the tutorial: 🔗 jb.gg/obj-det 🔗
1
9
1,129
May 30
AI agent costs don’t always explode overnight.
Sometimes they creep up quietly:
• Extra reasoning steps
• Repeated retrievals
• Unnecessary tool calls
• Verbose prompts
• Slow model responses
• Workflows that take longer than expected
In a demo, this may be invisible.
In production, it becomes a budget and user experience problem.
That’s why cost and latency should be part of agent evaluation from the start – not something teams discover through surprise bills or user complaints.
👉 Read the full guide to learn which production metrics you should monitor: 🔗 jb.gg/llm-evaluation 🔗
2
1
12
1,307
May 28
“What should we actually measure?” is where AI agent evaluation often gets messy.
There isn’t one “quality” score.
We break down 8 metrics you can use to make AI agents easier to test, monitor, and improve:
1. Hallucination rate
Does the agent generate claims that are unsupported or factually wrong?
Use it to evaluate factual accuracy and user trust.
2. Toxicity scores
Could the system produce harmful, offensive, biased, or inappropriate content?
Use toxicity checks as a safety guardrail for public-facing agents.
3. RAGAS
For RAG-based systems, check:
• Did it retrieve relevant documents?
• Did it generate an answer grounded in those documents?
4. DeepEval
Use evaluation frameworks to test more than basic accuracy.
DeepEval can help evaluate safety, RAG pipelines, chatbots, agent behavior, and security risks.
5. Task completion rate
Did the agent actually complete the task?
A workflow can fail even if one step succeeds.
6. Tool usage correctness
• Did the agent choose the right tool?
• Did it pass the right parameters?
• Did it use the result correctly?
7. Reasoning quality
Were the steps logical, necessary, and correctly ordered?
A correct answer can still come from a weak process.
8. Cost, latency, and regressions
Track what happens in production:
• Token usage
• Response time
• Cost per interaction
• Changes after model or prompt updates
Different metrics answer different questions. That’s why agent evaluation needs more than one score.
Read the full blog post for more details: 🔗 jb.gg/llm-evaluation 🔗
1
1
7
756
PyCharm, a JetBrains IDE retweeted

May 27
Our full conversation with Andrew Kelley, creator of Zig, is out now.
No AI policy, leaving GitHub, a $670K nonprofit, and why there's no 1.0 (yet).
14
62
563
170,398
May 28
Attending PyCon Italy this week? Come say hi 👋
We're sponsoring the event in Bologna on May 28–30:
💬 Find our team onsite to talk about the IDE, Python, or just to chat.
🧠 Take our quiz to test your Python knowledge – look for screens around the venue.
🎨 Grab PyCharm stickers before they're gone.
☕ Enjoy a coffee break (our treat!).
See you there!
#PyConIT #PyConIT26
7
767
May 27
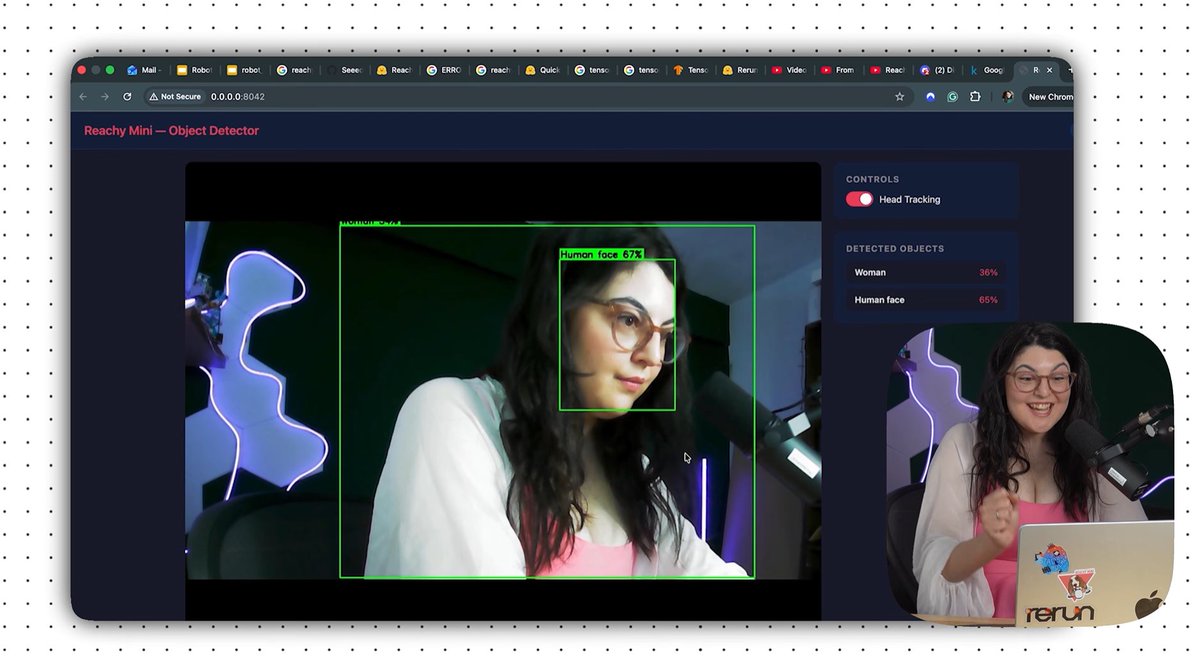
Turn your webcam into a real-time object detection app with TensorFlow and PyCharm.
In this tutorial by @iuliaferoli, you’ll use a laptop webcam and PyCharm notebook to:
1️⃣ Capture webcam frames.
2️⃣ Convert them into TensorFlow tensors.
3️⃣ Run SSD MobileNet V2 inference from TensorFlow Hub.
4️⃣ Filter detections by confidence score.
5️⃣ Draw bounding boxes with OpenCV.
6️⃣ Validate everything locally.
Then you can deploy the same pipeline to #ReachyMini by @huggingface and @pollenrobotics – allowing the robot to follow detected objects, react with its antennas, and show the results on a live dashboard.
Code snippets and the full GitHub repo are provided, so you can follow along or adapt your own project.
➡️ Read the tutorial: jb.gg/obj-det
2
19
1,209
May 26
Before you ship an AI agent, don’t just ask: “Does the answer look good?”
Ask: “Can we trust how it got there?”
Read these 7 practical checks before putting an AI agent in front of users:
1. Test the full task
An agent can complete one step and still fail the workflow.
Check whether it reaches the actual end goal.
2. Check tool choice
Did the agent pick the right tool for the job?
Wrong tool = unreliable result.
3. Inspect the inputs
The right tool is not enough.
Check IDs, filters, formats, parameters, and context passed to the tool.
4. Verify groundedness
For RAG-based agents, ask:
Is the answer supported by the retrieved sources?
Plausible ≠ grounded.
5. Trace the reasoning path
A correct answer can hide bad decision-making.
Log the steps, tool calls, retrieved data, and intermediate outputs.
6. Monitor cost and latency
Agents can get expensive quickly.
Track token usage, response time, and cost per interaction.
7. Watch for regressions
- New model?
- New prompt?
- Updated workflow?
Re-test completion rate, groundedness, latency, and cost.
Want the full guide? 👉 Read the blog post for more details: jb.gg/llm-evaluation
1
1
12
1,006
May 23
What do you enjoy most about coding?
For Johannes Rüschel, it’s seeing a problem being solved.
He also enjoys that software is never really finished. There’s always an opportunity to improve the design, handle new edge cases, or rethink a solution.
Watch the full interview about building better developer tools: 🔗 youtube.com/watch?v=HHRrKlEh… 🔗
1
16
1,901
May 21
LLMs don’t just need text. They need context.
Parsing PDFs isn’t just extracting words. It’s capturing structure, sidebars, and relationships between sections.
That’s where many AI systems still fall short.
▶️ Watch our Python conference recap: youtube.com/watch?v=eBc1dA9N…
2
16
1,258
May 21
Python monorepos can quickly turn into absolute dependency chaos.
Here are five ways PyCharm makes working with uv workspaces easier:
1️⃣ Detects when you open a workspace
2️⃣ Sets up or detects the workspace virtual environment
3️⃣ Syncs dependencies directly from pyproject.toml
4️⃣ Supports navigation and refactoring across workspace members
5️⃣ Runs and debugs projects using the workspace interpreter
It works with #uv, #Hatch, and #Poetry workspaces, too!
👉 Watch the full video to see the full workflow in action: youtube.com/watch?v=h_LiJjP6…
1
4
27
2,104
May 20
“Coding is only a means to an end.”
Johannes Rüschel – software engineer, technical coach, open-source contributor, and longtime PyCharm power user – shared his perspectives on software engineering with us.
▶️ Watch the full conversation: 🔗 youtube.com/watch?v=HHRrKlEh… 🔗
1
4
19
2,051