
"the best way to complain is to make things"
Joined June 2009
- Tweets 4,555
- Following 944
- Followers 270
- Likes 9,089
101 Photos and videos
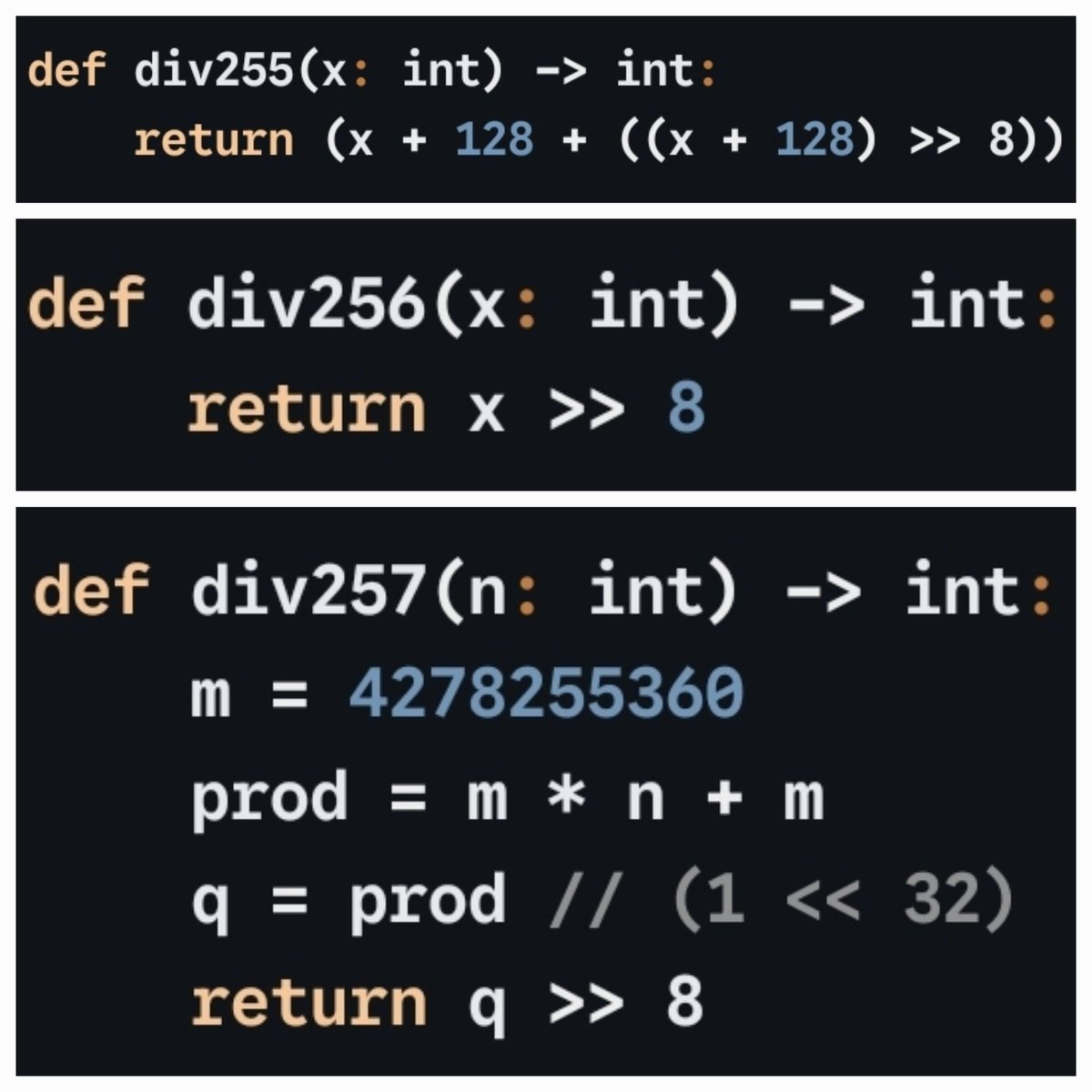










Security scanner for AI agent skills. Detect vulnerabilities, malicious patterns, and security risks before installing agent skills.
github.com/NVIDIA/SkillSpect…
21

Jun 12
Simple, unified interface to multiple Generative AI providers
github.com/andrewyng/aisuite
19
pentulohryz retweeted

Jun 8
A French engineer who lives quietly in Paris has spent 30 years writing software that the entire internet now runs on without knowing his name.
He wrote the code that streams every YouTube video, every Netflix show, every TikTok clip. He wrote the code that runs the virtual servers underneath AWS, Google Cloud, and Microsoft Azure. He calculated more digits of pi than anyone in history. He has no Twitter. He has no marketing. He just keeps shipping.
His name is Fabrice Bellard.
Here is the story, because almost nobody outside the systems programming world knows what one man has built.
Fabrice was born in 1972 in Grenoble, France. He studied at École Polytechnique, the top French engineering school. He never went to Silicon Valley. He never built a startup empire. He just wrote code.
In 2000 he started a project called FFmpeg, an open-source multimedia framework for encoding, decoding, and streaming video. He was 28. The project did one thing nobody else had done well. It handled every video and audio format that existed, in one library, on every operating system. He led it himself for years.
Today FFmpeg is the invisible engine of the internet. YouTube uses it. Netflix uses it. VLC uses it. Chrome and Firefox use parts of it. Every Android phone, every iPhone, every smart TV, every video editing tool you have ever touched runs FFmpeg somewhere underneath. If you have watched a video on a screen in the last 20 years, Fabrice's code processed it.
He was not done.
In 2003 he started QEMU, a machine emulator and virtualizer. He wrote it solo until version 0.7.1 in 2005. QEMU lets you run any operating system on any other operating system. It became the foundation of modern virtualization. KVM, the Linux kernel hypervisor, runs on top of QEMU. Every major cloud provider, AWS, Google Cloud, Microsoft Azure, IBM Cloud, runs virtual machines on infrastructure built around it. The Quick Emulator is the most cited piece of cloud infrastructure code on Earth.
He kept going.
In 2001 he won the International Obfuscated C Code Contest with a small C compiler that grew into TCC, the Tiny C Compiler. TCC can compile and boot a Linux kernel from source in under 15 seconds. In 2004 he calculated the most digits of pi ever computed at the time, using a personal desktop computer and an algorithm he derived himself called Bellard's formula. In 2011 he wrote a complete PC emulator in pure JavaScript that runs Linux in your browser, a project called JSLinux that engineers still cannot believe is real.
In 2019 he released QuickJS, a small but complete JavaScript engine that fits where V8 cannot. In 2021 he released NNCP, a neural network based lossless data compressor that immediately took the lead on the Large Text Compression Benchmark.
Then he turned his attention to large language models. He built TextSynth Server, a web server with a REST API for running LLMs locally. He released ts_zip and ts_sms, compression utilities that use language models to compress text and short messages at ratios traditional algorithms cannot reach. He released TSAC, a very low bitrate audio compression system. In December 2025 he released Micro QuickJS, a new JavaScript engine for microcontrollers, separate from QuickJS, designed for environments with almost no memory.
Fabrice co-founded a telecom company called Amarisoft in 2012, where he serves as CTO. Amarisoft builds 4G and 5G base station software used by carriers and labs around the world. He has been running it for over a decade while continuing to ship personal projects from his own home page at bellard dot org
He has no Twitter. He has no Instagram. He gives almost no interviews. His personal website is a flat list of projects with no styling, no fonts, no marketing copy. Just titles and links.
A quiet French engineer who never moved to Silicon Valley wrote the code that quietly runs the internet.
He is still shipping.

379
4,512
25,142
3,050,676
pentulohryz retweeted

Jun 8
Our statement on the UK government’s demand that all content on all devices sold or used in the country be scanned, on the presumption of nudity, using a dystopian combination of age verification and content scanning. This proposal will not safeguard children. It endangers us all.
signal.org/blog/pdfs/2026-06…
738
8,549
41,335
2,734,694
pentulohryz retweeted

.@Apple Planned Obsolescence
The “Truth” about why the headphone jack was removed.
I wonder how much damage has been done to the human brain with bluetooth tech?

948
5,879
61,715
720,771
pentulohryz retweeted

Jun 3
i just ran Google's brand new Unsloth Gemma4 12B dense GGUF on my RTX 4060 using llama.cpp CUDA 13.2
21 tokens per second. on a budget consumer GPU. locally.
no API. no cloud. no subscription.
and the benchmarks are absolutely cooked
# first let's talk architecture because this is genuinely different
every multimodal model you've used has a frozen vision encoder frozen audio encoder LLM backbone glued together
Gemma 4 12B is different
it's a single decoder only transformer. that's it. vision? raw 48×48 pixel patches → one matmul → projected directly into the LLM
audio? raw 16kHz signal sliced into 40ms frames → linear projection → same LLM input space
no encoder tax. no latency penalty. no fragmented memory
to put the encoder savings in perspective:
old Gemma 4 26B approach:
- 550M param vision encoder (frozen)
- 300M param audio encoder (frozen)
- LLM backbone
Gemma 4 12B:
- 35M param vision embedder (a single matmul)
- no audio encoder at all
- LLM backbone handles EVERYTHING 550M → 35M for vision alone. that's a 15x reduction
this is why the gemma-4-12b-it-Q4_K_M.gguf is just 6.6 GBs!!!
and it has 256K native context context
# Benchmarks:
AIME 2026 (math olympiad): 77.5%
GPQA Diamond (expert science): 78.8% LiveCodeBench v6 (real code): 72%
Codeforces ELO: 1659
MMLU Pro: 77.2%
MATH-Vision: 79.7%
BigBench Extra Hard: 53%
inference → llama.cpp, LM Studio, vLLM, SGLang
llamacpp flags:
-m "gemma-4-12b-it-Q4_K_M.gguf" -ngl 99 -c 8000 -v --port 8080
Available on huggingface now! Link below
Jun 3

Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇

59
90
974
274,161
May 26
AI Infrastructure Engineer Learning Track - Production ML infrastructure curriculum (2-4 years experience) github.com/ai-infra-curricul…
20
May 25
The world's best AI personal assistant for email. Open source app to help you reach inbox zero fast.
github.com/elie222/inbox-zer…
23
pentulohryz retweeted

May 19
ByteDance just dropped an open-source model called Lance—and get this: it runs on just 3B active parameters! 🤯 Yet it can take in text, images, and videos, and simultaneously generate all three! Absolutely mind-blowing!
huggingface.co/bytedance-res…
20
93
765
42,895
May 18
Store, compress, and retrieve long-term memories with semantic lossless compression. Now with multimodal support for text, image, audio & video. Works across Claude, Cursor, LM Studio, and more. github.com/aiming-lab/Simple…
1
27
May 18
Any agent Skill: generate beautiful architecture diagrams with dark/light theme toggle and PNG/JPEG/WebP/SVG export
github.com/tt-a1i/archify
1
1
232
May 18
What are the principles we can use to build LLM-powered software that is actually good enough to put in the hands of production customers? github.com/humanlayer/12-fac…
1
7

Un youtuber brasileño le acaba de clavar un puñal a la suscripción de Photoshop.
Se llama PhotoGIMP: un parche gratuito (GPL-3.0) que convierte GIMP en una copia casi idéntica de Photoshop.
Misma interfaz, mismos paneles, mismos atajos de teclado y muchísimo más espacio para tu lienzo. Tus manos ya saben usarlo sin aprender nada nuevo.
¿Por qué está explotando?
- $0 en vez de $276 al año
- Sin cuenta Adobe ni login
- Todo se guarda en tu PC (nada en la nube)
- Compatible con Windows, Mac y Linux
- Se desinstala borrando una carpeta (sin rastro)
Instalación ridículamente fácil: copias 9 archivos y listo. 8.8k estrellas en GitHub y traducciones de la comunidad.
Uso personal y comercial 100% permitido.

Community note
PhotoGIMP is not new and has been around since 2020: github.com/Diolinux/Photo…
This account and multiple others have been using similar posts to engagement farm over the last few weeks:
x.com/heynavtoor/sta…
x.com/AiwithZoaina/s…
This post from 3rd May was even community noted as such:
x.com/HowToAI_/statu…
211
6,975
39,417
2,306,901
pentulohryz retweeted

May 17
13 open-source tools for foundation model deployment
▪️ vLLM
▪️ Ollama
▪️ Hugging Face TGI
▪️ BentoML
▪️ Seldon Core
▪️ Kubeflow
▪️ MLflow
▪️ MLRun
▪️ Metaflow
▪️ TensorFlow Serving
▪️ TorchServe
▪️ SGLang
▪️ llama.cpp
Save the list and learn where to use each of them here → turingpost.com/p/tools-for-m…
6
88
441
18,784