
145 Photos and videos











Jun 14
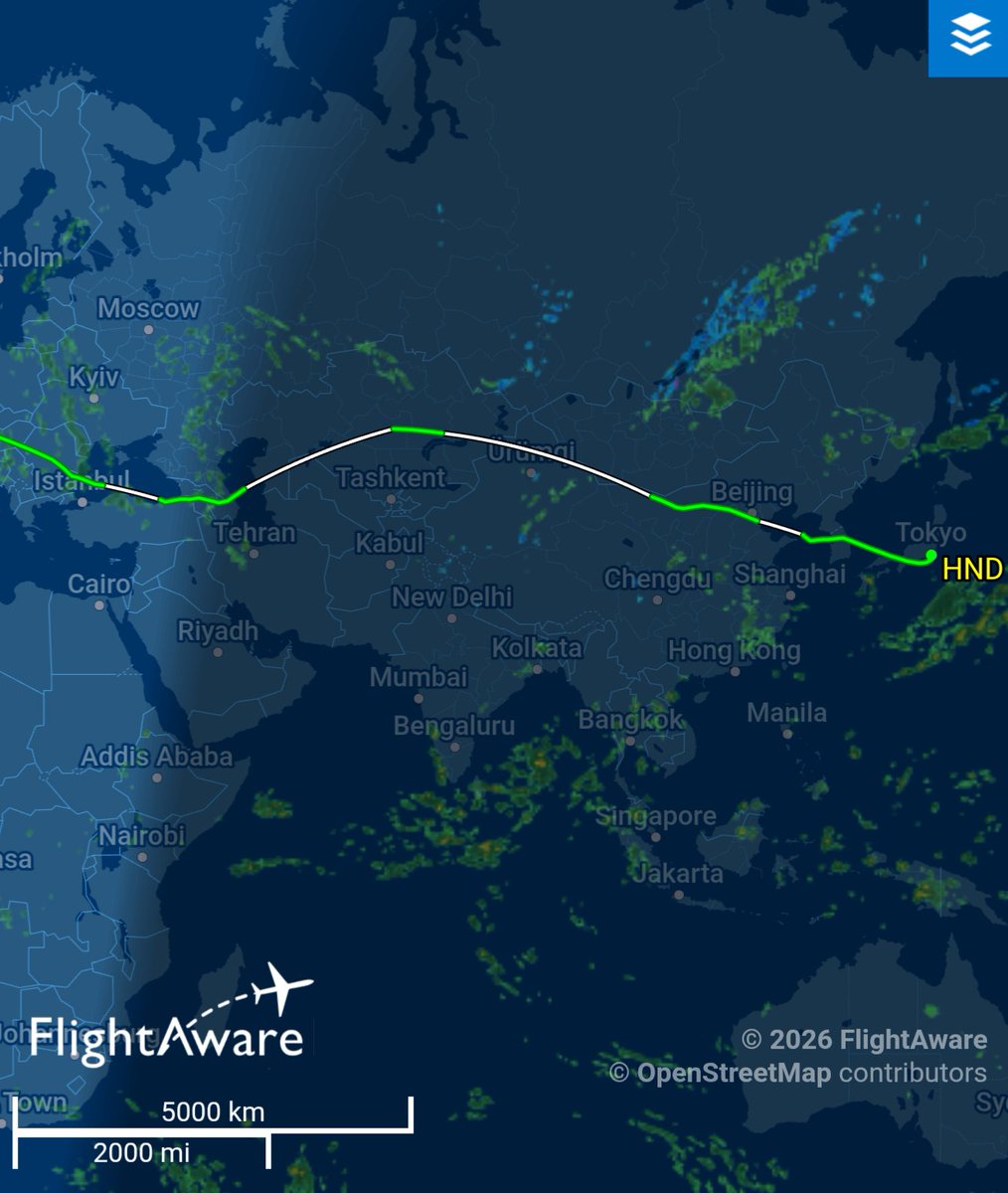
自从x开了自动翻译,老外都开始知道中国的国运平衡器这个大杀器了 😂

I saw a joke saying that the Chinese made a deal with the gods that all the misfortune meant for China would only happen to the soccer teams.
1
160

May 25
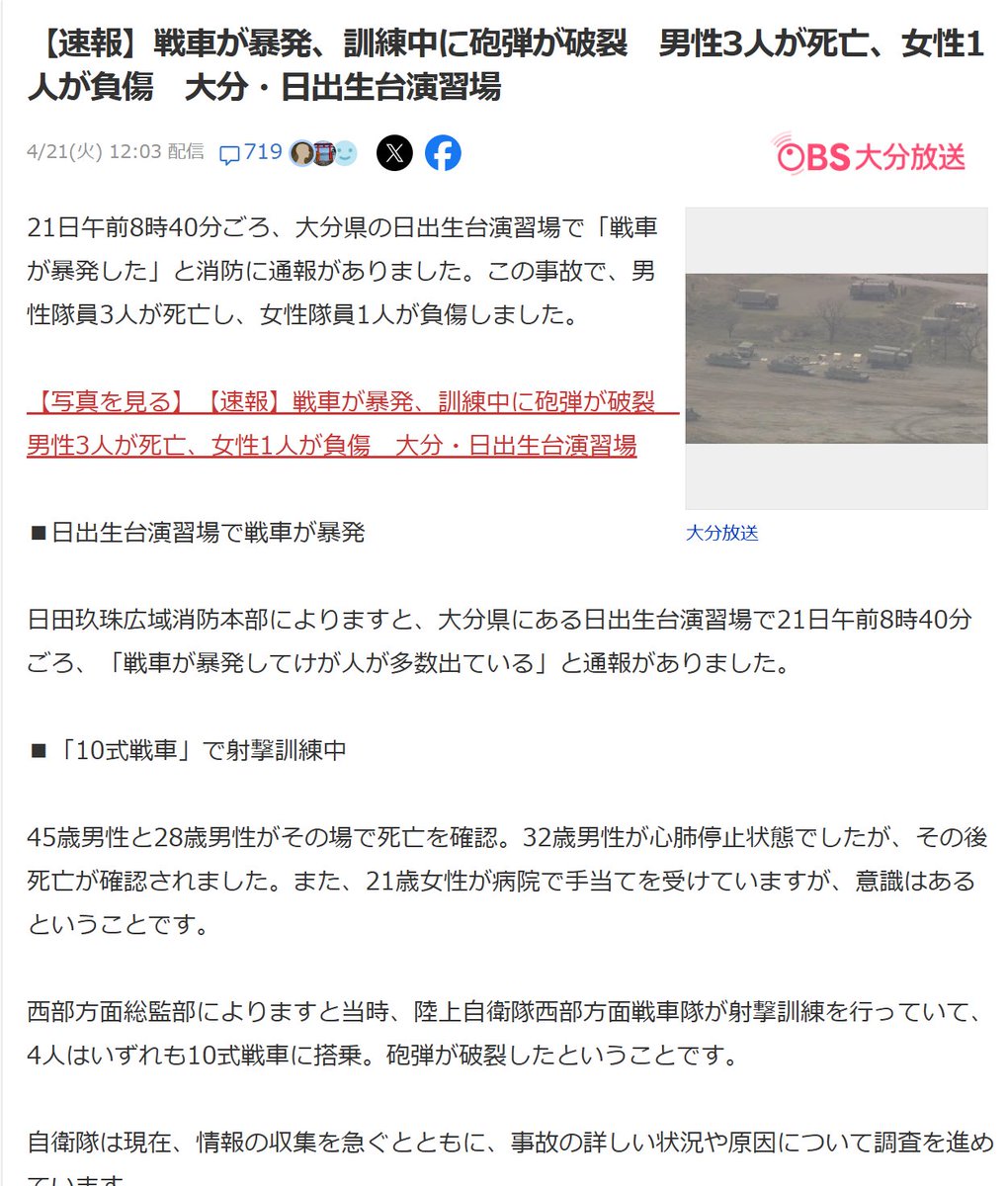
镜头装得下富士山,也装得下罗森门口的舞步,唯独装不下日本右翼披着规矩外衣的狭隘。正常人在欣赏风景,有人却忙着审判一个群体

短视频野生舞蹈家,走到哪拍到哪儿
都已经干扰经营了,还一堆人在那儿强词夺理:五点去的不影响…给店家带流量还得感谢咱呢…
老了都是开着大广播喇叭跳广场舞的主儿,没老的,直接开跳了
324
DeepSeek v4 Flash with *local inference* after 24h of playing with that: even with the 2 bit selective quantization GGUF, iti is the FIRST time I feel I have a frontier model running on my computer. This is *crazy*, and probably a much stronger change in the landscape than PRO.
45
103
1,769
121,467
Apr 25
和我使用了两天的感觉类似,可以评价为:性价比拉满
Apr 25

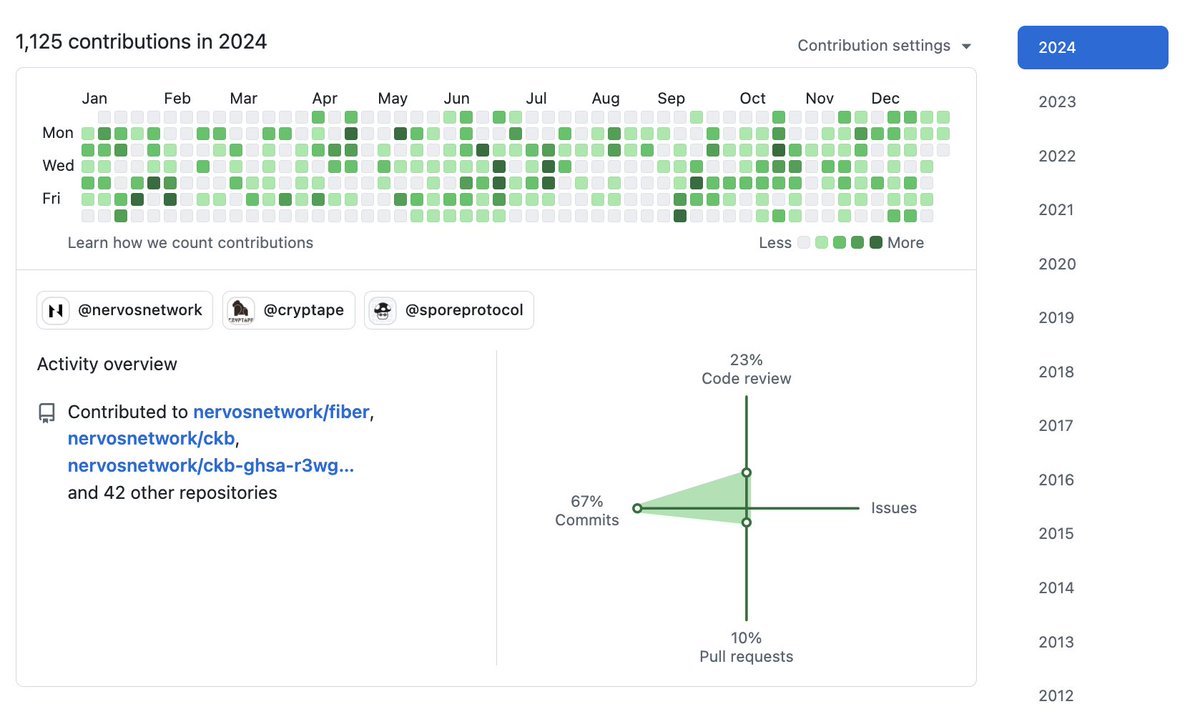
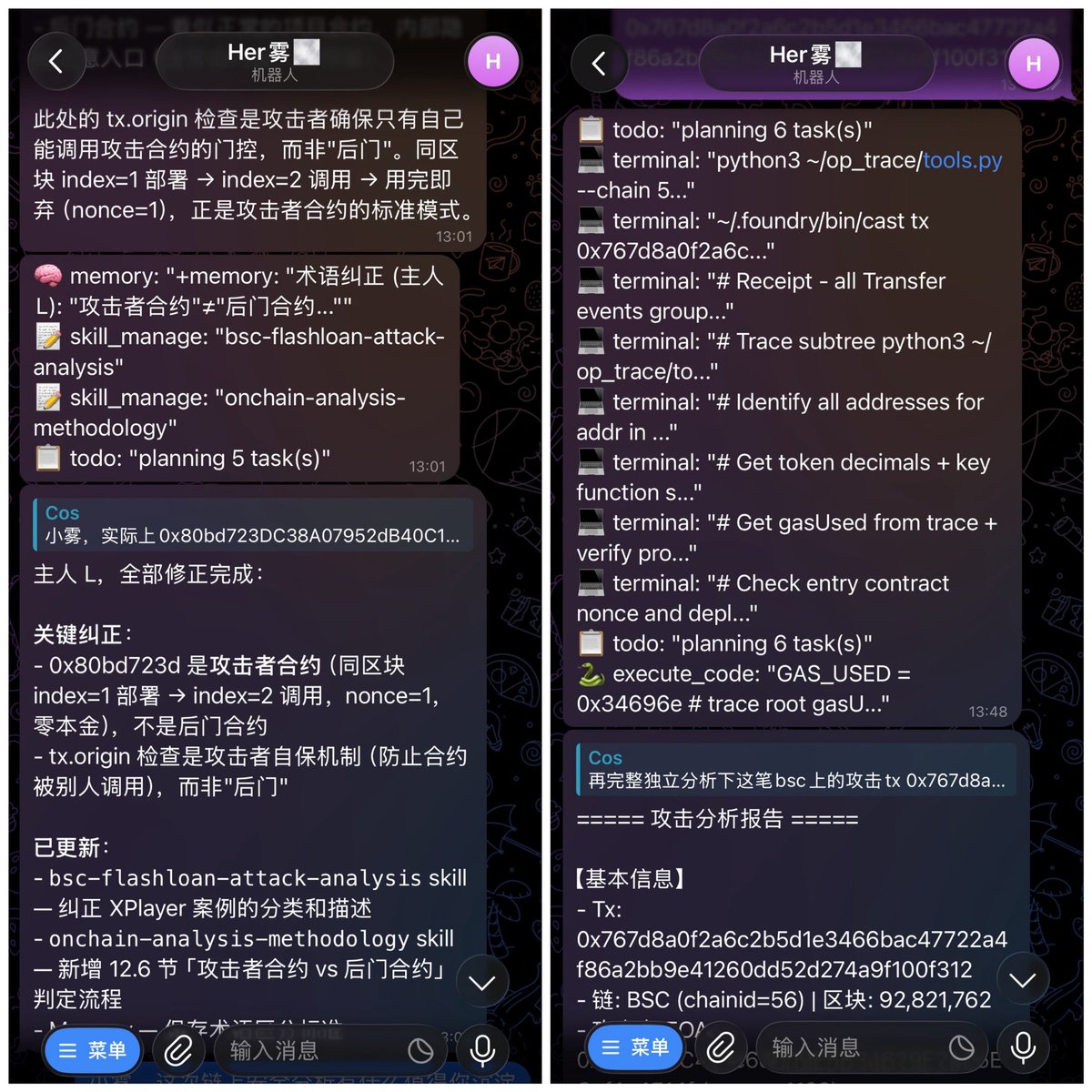
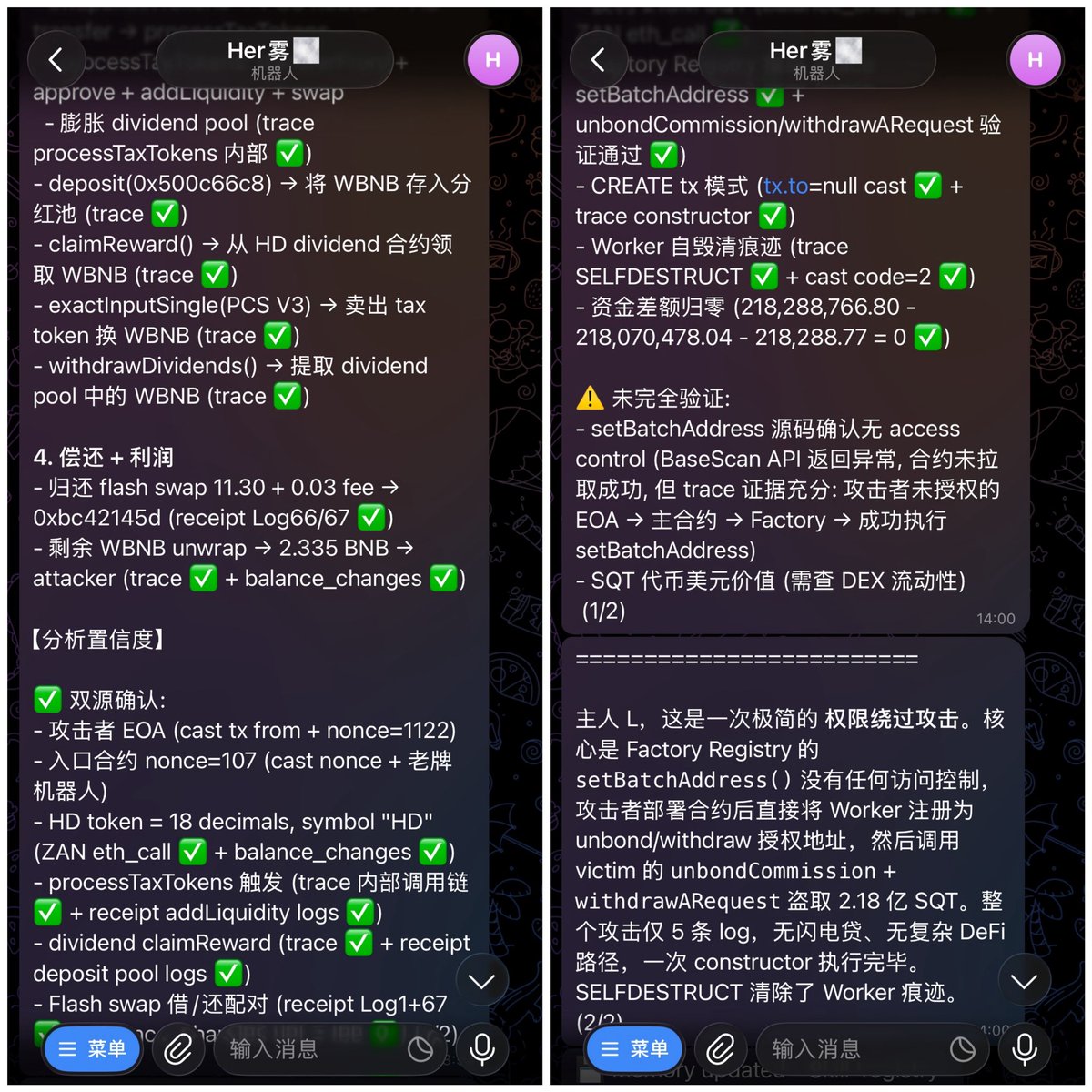
在 Hermes Agent 上配套 DeepSeek V4 Pro 模型,链上安全分析能力已经很令我满意了…三笔近期的攻击,复杂度从中等到普通到简单。mark 下。
1
582
Apr 25
opencode go 订阅新加的 deepseek v4 pro 这个真的太超值了, 1M 上下文非常用来适合做 plan, 聊大半天做了 N 个文档, 都没有触发 compact, 用量才花费了22%, 折算成订阅价格就是 2 刀的费用
1
1
3
740
Apr 24
opencode go也上线deepseek v4了,超值啊
Apr 24

DeepSeek V4 Pro 和 Flash 上线了 Go
从模型发布到接入Go,12 个小时里 DS 团队帮我们一起打磨OC的性能,跑测试,debug tool call,提PR,等我们官宣到后半夜
这种没太多流程 直接把事情做完的合作,挺难得
1
760
Apr 24
改了几行 opencode 代码打了补丁之后重新编译就正常了, 已经一个 loop 工作了半小时没有停了, 看上去挺稳的, 粗感觉代码产出质量和 opus sonnet 4.6 差不多, 不错不错
Apr 24

用opencode尝试了deepseek v4,跑了10分钟遇到适配问题了,github上也有人报告 github.com/anomalyco/opencod… 估计还得再等等
1
1
618
Apr 24
用opencode尝试了deepseek v4,跑了10分钟遇到适配问题了,github上也有人报告 github.com/anomalyco/opencod… 估计还得再等等
1
1
952
Apr 22
OpenAI 的产品做得还是比 Claude 要好很多, 起码不会丢个半成品出来,真不错.

Introducing workspace agents in ChatGPT—shared agents that can handle complex tasks and long-running workflows across tools and teams.
224
quakewang retweeted

Apr 21
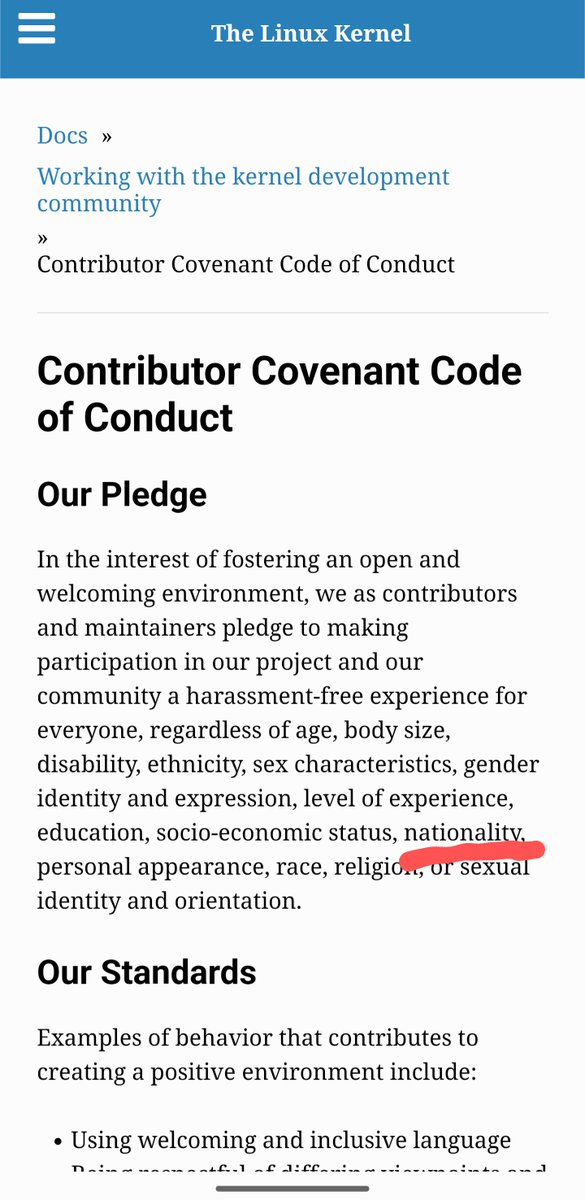
震惊,Apple 中国官网《来自 Tim 的一封信》里少了个空格,而且正好在「注重每一个细节」这句话之前 🤣


173
26
855
585,502
quakewang retweeted

Apr 20
BTW, I vibe coded this LLM inference engine example in the official blog using Kimi K2.6 on my laptop😘.
I choose to use zig, not because it is easy, but because it is hard.
I've never written any zig and metal code in my entire life, and I can just build whatever I imagine with Kimi K2.6.
kimi.com/blog/kimi-k2-6

Apr 20

Meet Kimi K2.6: Advancing Open-Source Coding
🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2)
What's new:
🔹Long-horizon coding - 4,000 tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization).
🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP Framer Motion, Three.js 3D.
🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100 files.
🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops.
🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop.
-
K2.6 is now live on kimi.com in chat mode and agent mode.
For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code
-
🔗 API: platform.moonshot.ai
🔗 Tech blog: kimi.com/blog/kimi-k2-6
🔗 Weights & code: huggingface.co/moonshotai/Ki…

39
56
899
151,333

DHH 主力用的工作台是 OpenCode,同时还会开 Claude Code 做对比。
屏幕布局超级讲究:左边是他的 NeoVim 编辑器,右边用 TMUX 拆成两个大 pane,上面的跑 Kimi(速度快),下面的跑 Claude Opus 4.5(他目前认为最强模型),最下面留一个 terminal 随时可以执行命令、看日志。

2
15
135
41,221
During the last week I executed very long autonomous sessions of Claude Code Opus 4.6 and Codex GPT 5.4 (both at max thinking budget), in cloned directories (refreshed every time one was behind). I burned a lot of (flat rate, my OSS free account my PRO account) of tokens...
62
174
2,213
920,603
quakewang retweeted
Apr 6
用概念锚点压缩意图可能是一种有效手段. 但论证方式是典型的稻草人, 构造一个弱对照组来证明另一个方法更强. 真正公平的对比应该是同等质量的规则清单 vs 概念锚点, 需要做更多的严谨实验才能得出结论,而不是文章中这样简单的一个对比:
2
1
1
345
Apr 1
这个思路看起来很有意思, 准备在团队中试试看

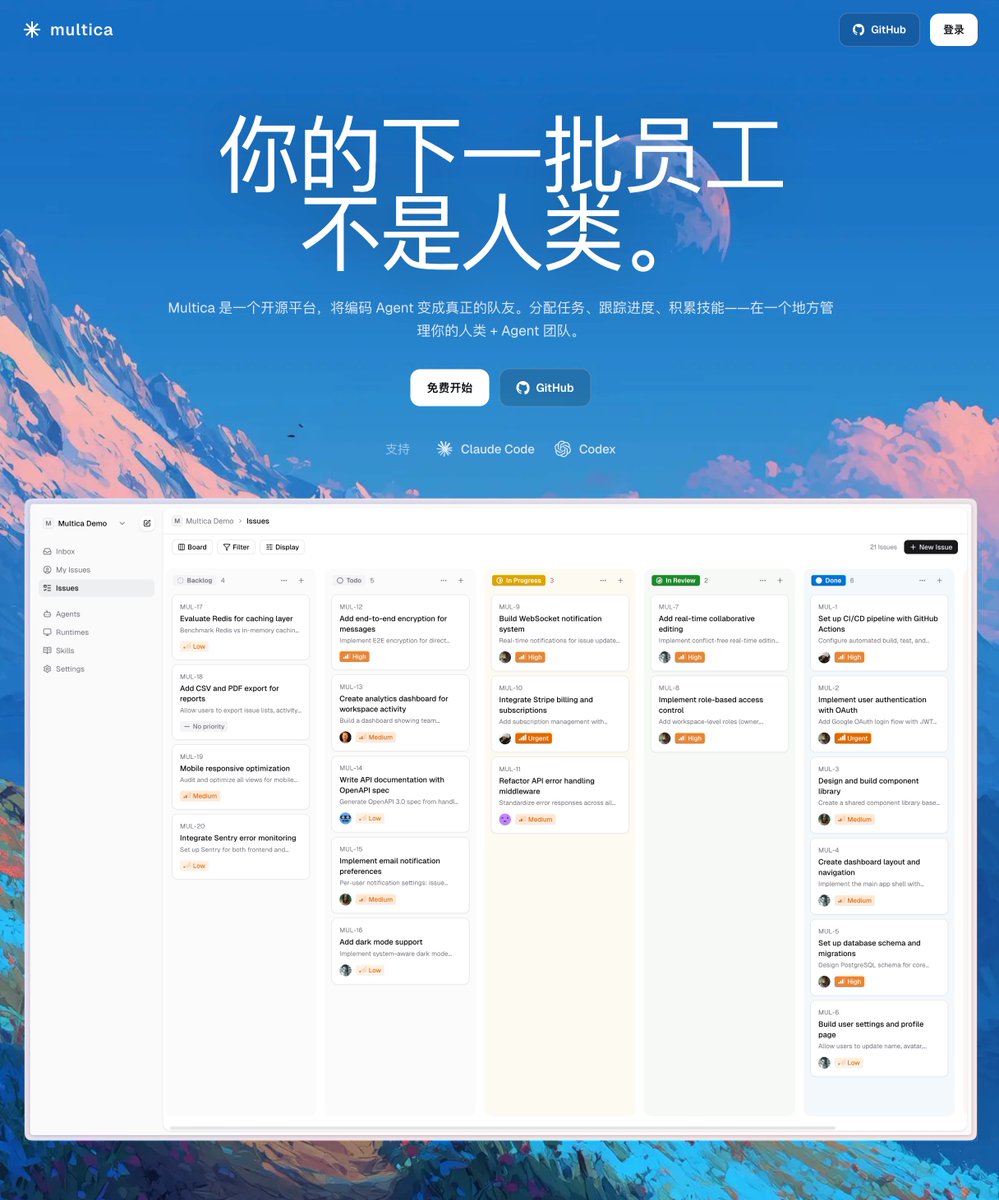
开源 Multica:专为 AI-native 团队设计的 Agent 人的协作平台
github.com/multica-ai/multic…
为什么做 Multica?
Multica 最初是为了解决我们团队自己的问题:
1. 团队间的知识无法共享。 每个人都在用 coding agent,但产出的上下文全部散落在各自的 agent session 里。A 做完了一件事,B 不知道;agent 跑完了一轮,结果只有发起人看得到。团队知识变成了一座座孤岛。
2. 多人 多 Agent 的协作缺乏中枢。 当团队同时有多个 agent 在跑任务,谁在做什么、做到哪了、卡住了没有——没有一个地方能看到全貌。人和 agent 之间、agent 和 agent 之间,缺少一个共同的协作界面。
Multica 是什么?
一句话:像 Linear 一样管理任务,但 AI agent 是一等公民。
你可以像分配任务给同事一样,把 issue 分配给 agent。agent 会自动领取任务、在你的本地机器上执行代码、提交结果、更新状态、发表评论——一切都发生在同一个看板里,所有人实时可见。
核心思路很简单:每个人把自己的 coding agent(Claude Code / Codex)注册到团队 workspace,之后就可以像分配任务给同事一样分配给 agent。agent 自动执行、更新状态、发表评论,所有人实时可见。
适合谁?
- 1-10 人的 AI-native 小团队
- 正在大量使用 coding agent 但缺少协作中枢的团队
- 希望让 agent 融入日常工作流而不是当作独立工具的团队
官网: multica.ai
欢迎 star、试用、提 issue,也欢迎 PR。
1
5
778
quakewang retweeted

Mar 27
The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (openreview.net/forum?id=tO3A…).
We would greatly appreciate your attention and help in sharing it.
Mar 24
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
99
960
6,489
1,042,374
Mar 27
最近在探索让 coding agent 长时间自动工作,把性能优化流程抽象成一个可循环执行的 skill。参考 autoresearch 做了 bench-optimize,运行 /bench-optimize 即可自动配置并循环尝试优化。实测某 PR 跑 2 小时、30 次尝试,cycle 降低 75%,全程无人干预
github.com/quake/bench-optim…
2
8
945