
Writing the PhD thesis @aibrussels | ex Cohere and FWO Fellow
Joined May 2019
- Tweets 56
- Following 355
- Followers 195
- Likes 156
2 Photos and videos

Pinned Tweet

20 May 2025
Last week, I wrapped up my internship @cohere, where I had the chance to work with fantastic people on RL for LLMs.
It was an amazing 6 months, and I'm excited to share one of the outcomes: ShiQ, a Q-value based RL algorithm for fine-tuning LLMs 🚀
🧵Details in @irombie's post!
19 May 2025

I'm excited to share our new pre-print
ShiQ: Bringing back Bellman to LLMs!
arxiv.org/abs/2505.11081
In this work, we propose a new, Q-learning inspired RL algorithm for finetuning LLMs 🎉
(1/n)
2
30
1,370
4 Jun 2025
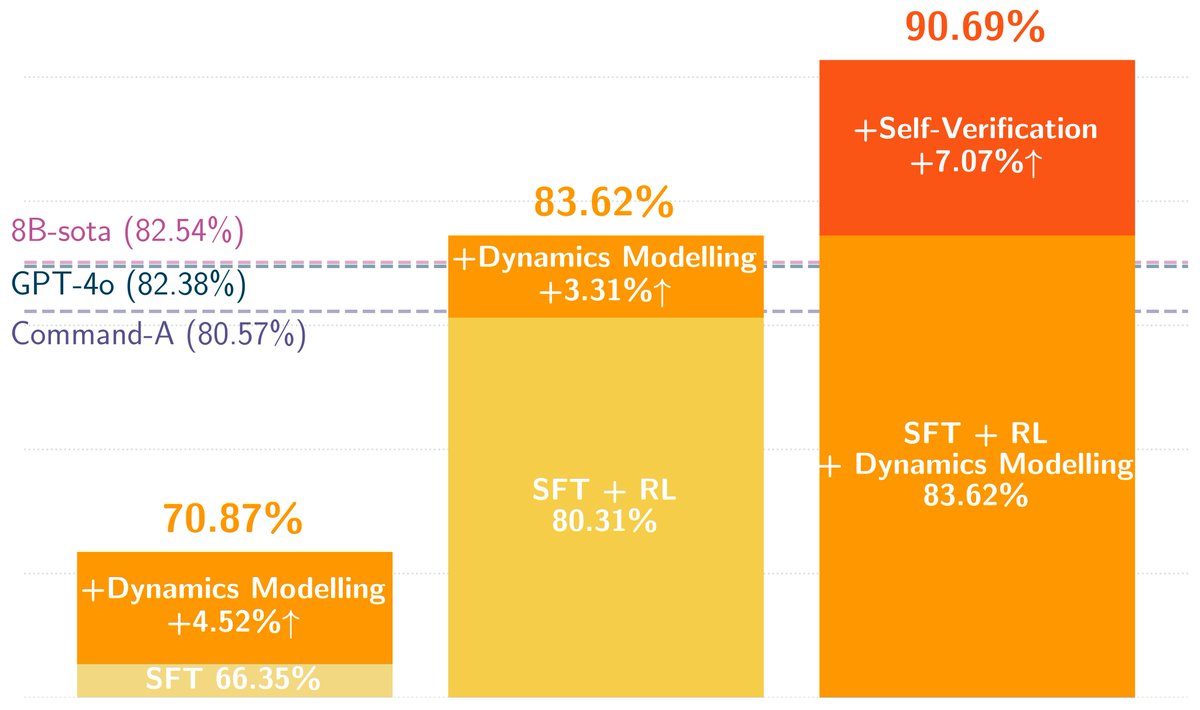
🚀 Excited to share the 3rd outcome of my internship at @CohereAI: a new RL algo for agentic LLMs that combines policy learning and world modeling, letting agents verify actions before executing them.
Check out the 🧵 and 📄!
Big thanks to my co-authors and Cohere’s RL team 🙏
4 Jun 2025

📢After months of work, I can finally share our latest research, couldn’t be more thrilled and excited. 🎉
We unify a policy 🤖 and a world model 🌍 into a single LLM, thus no external dynamics model needed!
Why does this matter? Because now, the policy can plan based on its internal world model!
And this planning boosts tool-use success rates to >90%, on top of SFT RL.
📄: arxiv.org/abs/2506.02918
🧵[1/8]

1
19
1,003
Raphael Avalos retweeted

19 May 2025
Okay, I was definitely not vague posting

18 May 2025

How come people don’t do Q-learning on LLMs
7
28
415
71,057
28 Mar 2025
Excited to share the technical report on Command R7B (7B) and Command A (111B), our flagship model! These models are the result of incredible teamwork at @cohere, and it was an honor to be part of it.
Report: cohere.com/research/papers/c…
27 Mar 2025

Today (two weeks after model launch 🔥) we're releasing a technical report of how we made Command A and R7B 🚀! It has detailed breakdowns of our training process, and evaluations per capability (tools, multilingual, code, reasoning, safety, enterprise, long context)🧵 1/3.
2
223
Raphael Avalos retweeted

📢 Deadline Extended! 📢
Due to multiple requests and the overlap with @RL_Conference and @RealAAAI, we’re extending the Adaptive Learning Agent workshop @AAMASconf submission deadline to March 1st (AOE)! 🚀
🔗 More details: ala-workshop.github.io
3
3
243
Raphael Avalos retweeted
🚨 Less than 48 hours left to submit to the 17th Adaptive Learning Agent workshop at @AAMASconf! 🚨
We welcome full papers, work in progress, and 2-page abstracts of recent journal papers. Don't miss the deadline!
🔗 More details: ala-workshop.github.io
1
5
6
571
Raphael Avalos retweeted

17 Feb 2025
Exciting news! My paper on multi-objective reinforcement learning was accepted at AAMAS 2025!
We introduce IPRO (Iterated Pareto Referent Optimisation)—a principled approach to solving multi-objective problems.
🔗 Paper: arxiv.org/abs/2402.07182
💻 Code: github.com/wilrop/ipro
3
6
30
1,791
Raphael Avalos retweeted
Missed the deadline? No worries! We've extended the submission deadline to Feb 25!
Find all the details on our website:
ala-workshop.github.io/
1
2
91
28 Jan 2025
Don't miss the opportunity to submit your (Multi-Agent) RL work to the ALA workshop!

Still 8 days to submit your work to the ALA workshop at AAMAS! We welcome full papers, work in progress, and 2-page abstracts of recently published journal papers. All the info is available at ala-workshop.github.io.
2
4
464
3 Jan 2025
The X account and website for the next edition of the ALA workshop is live! Follow it to get all the updates :)
Excited to announce the 17th Adaptive Learning Agent workshop at @AAMASconf in May! We welcome full papers, work in progress, and 2-page abstracts of recently published journal papers. Find out more at our website: ala-workshop.github.io/. Deadline for submissions: February 4th.
3
93
18 Nov 2024
Starting my internship at @cohere today to work on LLMs! I'll be in Paris a couple of days a week, so if anyone wants to meet up, let me know!
28
1,356
Raphael Avalos retweeted

3 Sep 2024
Two weeks ago, I publicly defended my PhD thesis, entitled « Activating Formal Verification of Deep Reinforcement Learning Policies by Model Checking Bisimilar Latent Space Models ».
📚 The full dissertation is available here: tinyurl.com/formarl
(1/n)

1
1
4
420
15 Aug 2024
The 1st edition of @RL_Conference was amazing! Congrats to the organizers for making this happen and for trying a new review system. I had such a great time with @GsprdLambrechts @kohler_hector @SuauMiguel @RiccZamboni Mathieu Reymond and all the others! 1/3
1
1
18
883
15 Aug 2024
I also had the pleasure of presenting our latest work on Online Planning for POMDPs with State Requests (with E. Bargiacchi, A. Nowé, @DiederikRo, @faoliehoek). Check the paper here: rlj.cs.umass.edu/2024/papers… 2/3
1
1
6
353
15 Aug 2024
Looking forward to the next edition, and in the meantime, see you all at EWRL in Toulouse this October! 🚀 3/3
4
97
Raphael Avalos retweeted

15 Aug 2024
@RL_Conference was a blast and I caught up with some of the usual suspects from european RL @vernadec @araffin2 @raphael_avalos @GsprdLambrechts @RiccZamboni. See you all at EWRL 2024. Looking forward to next year's edition!! 🥳🧠
3
8
446
Raphael Avalos retweeted
16 Jul 2024
Okay people, I need some help. We’re working on a project and have been stuck for a while. My final guess for what the issue may be is that gradients are not flowing as we would want them. Does anyone have a intuitive visualisation/debugging tool for gradient flows in jax?
1
3
510
Raphael Avalos retweeted

11 May 2024
Presenting work on synthetic preference generation at two #ICLR2024 workshops today: DPFM & GenAI4DM @genai4dm.
Come say hi to find out how to improve your reward model without collecting additional human feedback!

23 Jan 2024

RLHF gains are largely determined by the quality of the underlying reward model. How can we improve reward model quality without collecting more data?
Introducing a novel approach to augmenting human feedback data with synthetic preferences! 🧵
arxiv.org/abs/2401.12086
2
20
1,332
10 May 2024
If you are attending #ICLR2024 workshops go checkout this cool work !
10 May 2024

In clinical early warning systems (EWS), can we go beyond the model estimate of event occurrence and leverage its belief about the event distance to improve our alarm policy?
Introducing “Dynamic Survival Analysis for Early Event Prediction” with @ToManuelBurger and @gxr. 🧶
134
9 May 2024
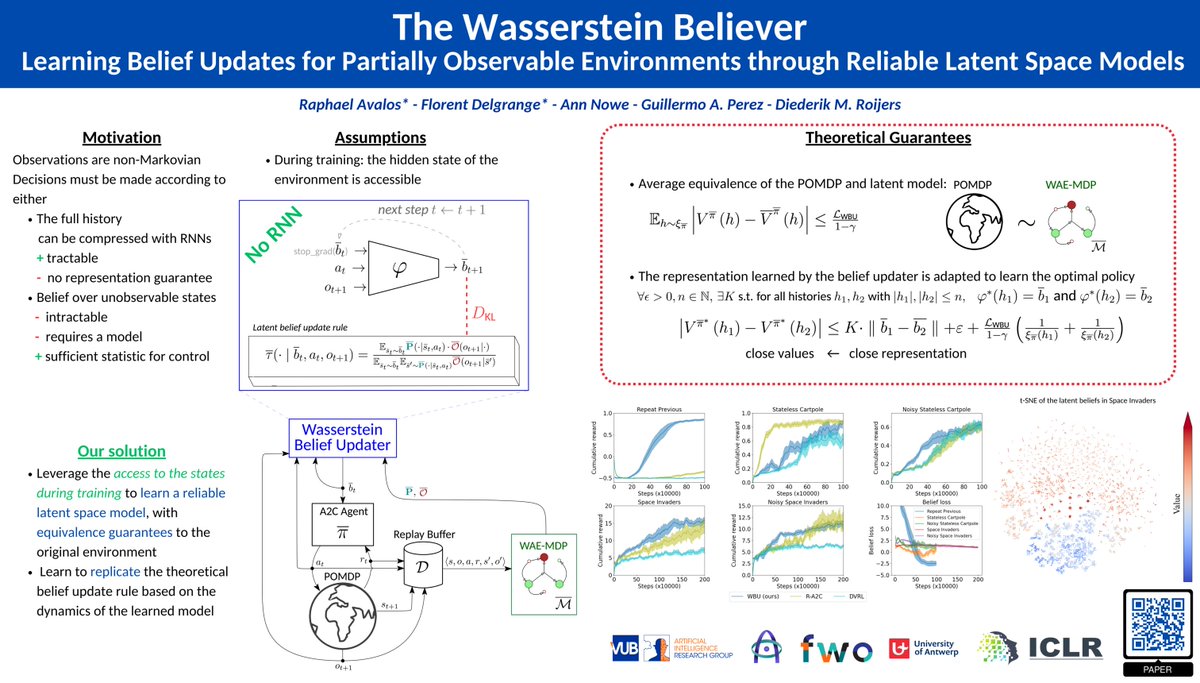
Poster session now ! We are waiting for you with @f_delgrange at the poster 158 ! #ICLR2024
7 May 2024

Arrived at #ICLR2024 with @f_delgrange to present our work "The Wasserstein Believer: Learning Belief Updates for Partially Observable MDPs through Reliable Latent Space Models".
1
5
493