
Speech LLMs @nvidia | Previously: @Meta MSL, @jhuclsp, @IITGuwahati
Joined September 2009
- Tweets 2,204
- Following 1,985
- Followers 4,290
- Likes 7,668
166 Photos and videos






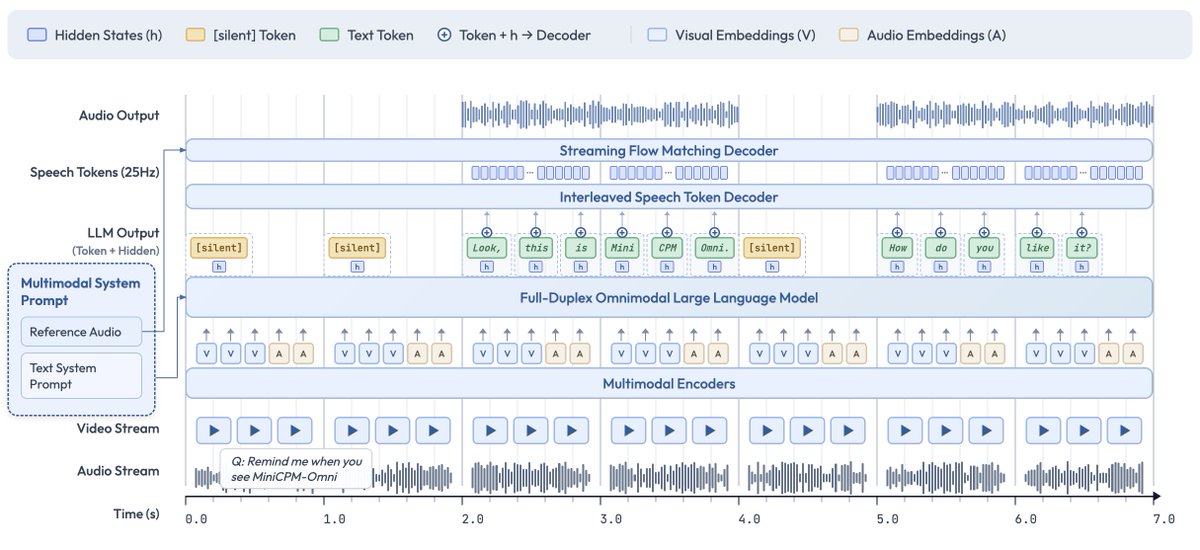






I’m happy to share that I’m starting a new position as Senior Research Scientist at @nvidia!
Looking forward to open science for speech full-duplex models :)

After 2 wonderful years, I left Meta this week. During this time, I worked on several projects related to speech and LLMs:
- Built the first multi-channel audio foundation model with M-BEST-RQ (arxiv.org/abs/2409.11494)
- Made ASR with SpeechLLMs faster (arxiv.org/abs/2409.08148) and more accurate (ieeexplore.ieee.org/document…)
- Shipped the first production-ready full-duplex voice assistant (about.fb.com/news/2025/04/in…)
- Improved Moshi’s reasoning capability with chain-of-thought (arxiv.org/abs/2510.07497)
I am grateful to my managers for having my back on critical projects, and fortunate to have collaborated with several brilliant researchers and engineers during this time.
As to what's next, I am still in NYC and continuing to do speech research. More on that later!
52
10
524
31,930
Desh Raj retweeted

Jun 13
This technology was built of the shoulders of many.
Many will carry it forward.
Care deeply. But don’t dictate.
2
11
120
5,226
Desh Raj retweeted

Jun 10
Moshi is great but sometimes not fully exploiting its full-duplex abilities. @atsumoto_ohashi applied carefully crafted RL rewards on Moshi's output given some real inputs to improve interactivity on all axis. Works great on Moshi and the derived PersonaPlex by @nvidia.
Jun 10

New paper: Multi-Faceted Interactivity Alignment in Full-Duplex Speech Models
We use RL to post-train speech models (Moshi and PersonaPlex) to talk more like a human: to know when to respond, when to wait, and when to nod along with “yeah”s and “okay”s when listening.
7
30
2,718


Desh Raj retweeted

Jun 4
Second big release from us today: Nemotron-3.5-ASR-Streaming!
🌎40 languages
⚡️80ms - 1s controllable latency
🔥240 - 2400 concurrent streams on 1xH100
🧱FastConformer Cache-Aware RNN-T architecture
huggingface.co/nvidia/nemotr…
23
118
981
60,148
Desh Raj retweeted

Jun 4
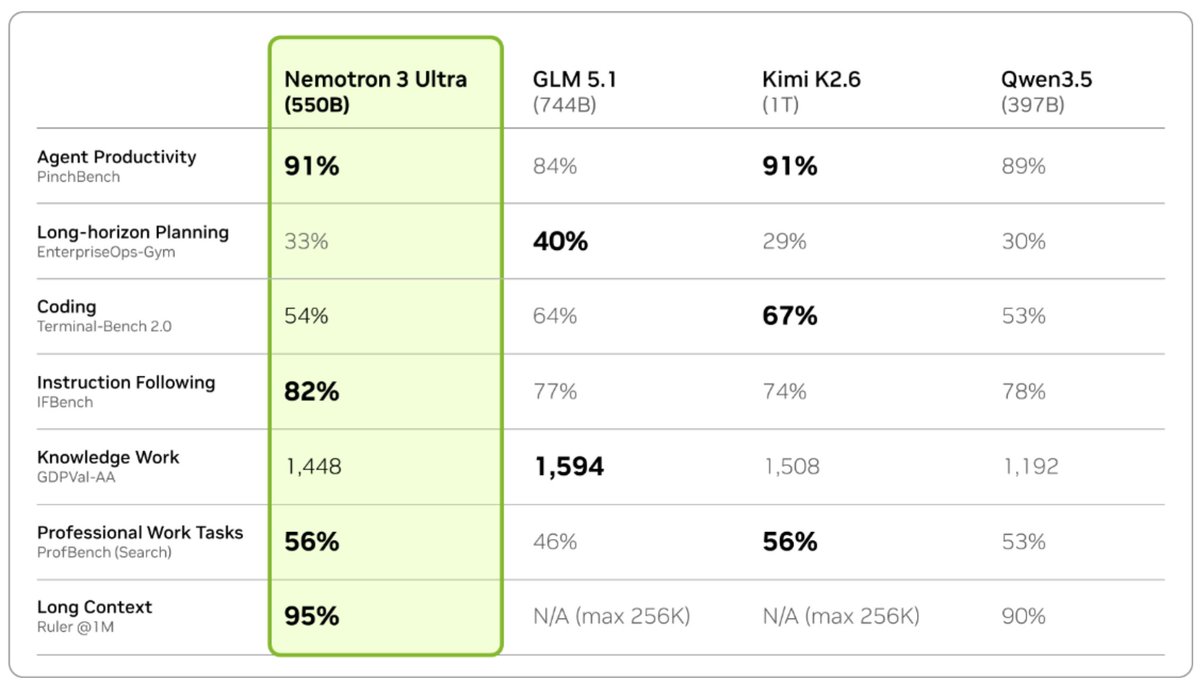
Very excited to share Nemotron 3 Ultra, 550B total with 55B active MoE hybrid Mamba-Attention model post-trained for agentic applications!
This model delivers frontier-level agentic accuracy while being fast and open with weights, training software, and data available for commercial use. 1/4
13
42
386
26,309
Desh Raj retweeted

Jun 4
NVIDIA Nemotron 3 Ultra is now live!
Frontier accuracy, 5X greater speed, 30% lower cost.
Deploy however you need - on-premise, on the cloud, or at the edge.
Model is live on HuggingFace under the OpenMDW 1.1 license.
youtube.com/watch?v=D8LIIvQV…
25
75
371
92,047
Desh Raj retweeted

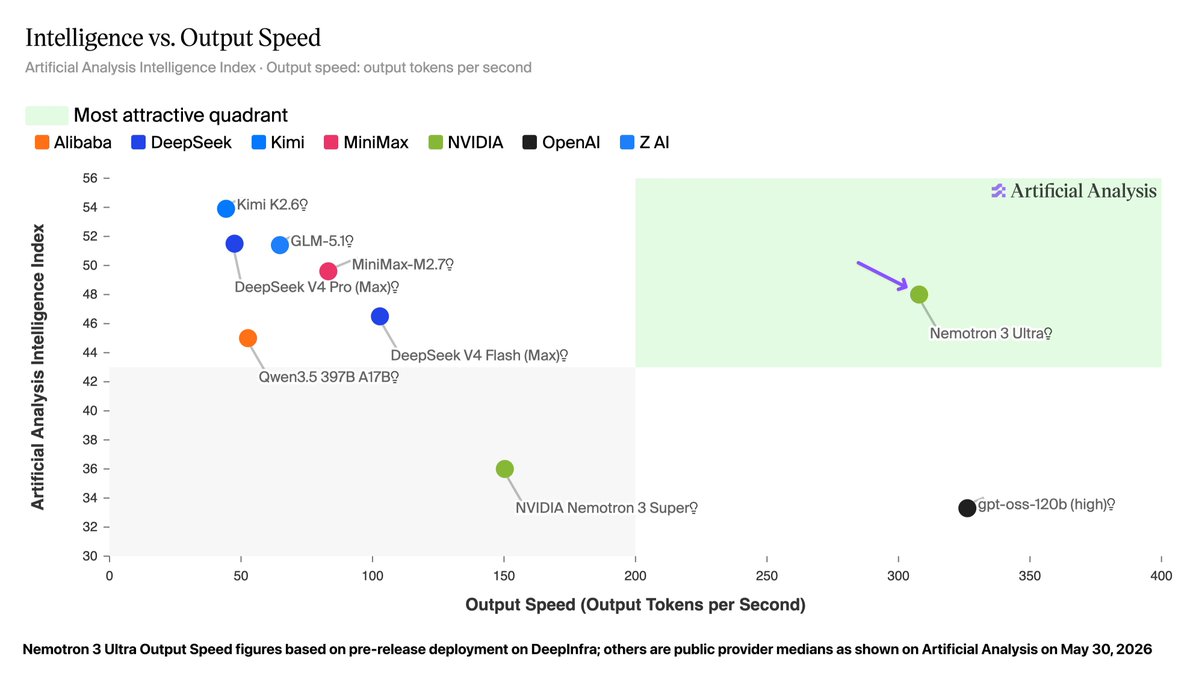
NVIDIA just announced the release of Nemotron 3 Ultra in Jensen Huang's Computex keynote: at 550B parameters (55B active), this is the largest Nemotron 3 model to date, and it is the most intelligent US open weights model
We partnered with @nvidia to evaluate this model for intelligence and speed - these figures use the model’s BF16 weights, but as with Nemotron 3 Super the model will be made available in NVFP4 quantization as well for higher inference performance.
➤ New leader for US open weights intelligence: Nemotron 3 Ultra scores 48 on the Artificial Analysis Intelligence Index. This is well ahead of the next strongest US open weights models, Gemma 4 31B (39), Nemotron 3 Super (36) and gpt-oss-120b (33), but behind the Chinese-led open weights frontier (Kimi K2.6 at 54).
➤ Leading speed for its intelligence: on a pre-release @DeepInfra endpoint, Nemotron 3 Ultra served over 300 tokens per second. Peer models in its size class from China-based labs such as DeepSeek and Moonshot (Kimi) are generally served at speeds of 50-100 tokens per second in the market today. gpt-oss-120b is served at speeds similar to this level, but with significantly lower intelligence.
➤ Largest Nemotron 3 model so far: at approximately 550 billion total parameters and 90% sparsity, Nemotron 3 Ultra is significantly larger than its siblings and is the largest recent US open weights model release
We’ll be sharing additional analysis and full benchmarks at release.
41
119
935
89,989
Desh Raj retweeted
Jun 1
Nemotron 3 Ultra:
Frontier smart.
5X faster.
30% cheaper.
💚💚💚

45
96
898
275,180
Desh Raj retweeted

Imagine you spent 40 years doing the boring, responsible thing.
You opened a 401k at 23. You contributed every paycheck. You ignored the noise. You bought the index because Bogle told you to, because Buffett told you to, because every honest piece of financial advice for 30 years told you the index was the safest, most diversified, most rules-based way to own America.
The whole point was the rules.
The rules said: a company must trade for 12 months before joining the S&P 500. The rules said: it must show four consecutive quarters of GAAP profitability. The rules existed because in 1999 the index quietly bought a lot of stocks at the top, and pensioners paid the bill.
After the dot-com crash, S&P tightened the rules. Nasdaq tightened the rules. FTSE Russell tightened the rules.
For 23 years, those rules held.
Then SpaceX filed for IPO.
And the rules changed.
The S&P 500 waived the profitability requirement. Nasdaq cut its trading-history window from 90 days to 15. FTSE Russell cut its to 5.
Bloomberg Intelligence estimates the major index funds will absorb between 19% and 24% of SpaceX's float within six months. That's over $30 trillion of passive 401k and retirement money, mechanically buying a single newly public company at IPO valuations, because the rules said they had to.
Except the rules used to say they didn't.
Here's the thought exercise:
If you spend 40 years building a system designed to protect ordinary savers from buying overpriced stocks, and then you waive the protections the moment a sufficiently large stock asks you to, what was the system actually protecting?
Most of investing is about understanding what's a rule and what's a guideline.
A rule binds the rule-maker.
A guideline binds the saver.
You're allowed to find out which is which only after the fact.

Rule changes for the SpaceX $SPCX IPO:
Index providers waived the profitability requirement and cut the seasoning window from 90 days to 5.
This forces over $30 trillion in passive 401k and retirement money to buy SpaceX at IPO valuations.
Bloomberg Intelligence estimates S&P 500 funds must absorb 19% of SpaceX's float within 6 months.
Russell 1000 and Nasdaq 100 funds will absorb 24%.
The rules built to protect passive investors:
1. S&P 500 has required 12 months of trading and 4 quarters of GAAP profitability since 2002. Both waived.
2. Nasdaq cut its inclusion window from 90 trading days to 15.
3. FTSE Russell cut its to 5.
All three benchmarks are now structured to buy SpaceX at IPO pricing.
247
1,782
10,824
3,656,131
Desh Raj retweeted

May 19
We are offering grants of $100,000 Tinker credits to researchers advancing the field of human-AI interactivity. Submit your proposals by June 19th!
thinkingmachines.ai/news/int…
52
199
1,625
617,823
Desh Raj retweeted

May 16
I can’t stop thinking about this post. If you do one thing today, I encourage you to give it a thoughtful, thorough read…
And then commit to never living your life this way. Life has wasted success on the people described in this post.
It really is completely pathetic. They say that comparison is the thief of joy - look no further than this post for validation it is indeed true.
On their deathbed they will realize they have lived their life completely wrong. Don’t let it be you.

The vibes in SF feel pretty frenetic right now. The divide in outcomes is the worst I've ever seen.
Over the last 5yrs, a group of ~10k people - employees at Anthropic, OpenAI, xAI, Nvidia, Meta TBD, founders - have hit retirement wealth of well above $20M (back of the envelope AI estimation).
Everyone outside that group feels like they can work their well-paying (but <$500k) job for their whole life and never get there.
Worse yet, layoffs are in full swing. Many software engineers feel like their life's skill is no longer useful. The day to day role of most jobs has changed overnight with AI.
As a result,
1. The corporate ladder looks like the wrong building to climb.
Everyone's trying to align with a new set of career "paths": should I be a founder? Is it too late to join Anthropic / OpenAI? should I get into AI? what company stock will 10x next? People are demanding higher salaries and switching jobs more and more.
2. There’s a deep malaise about work (and its future).
Why even work at all for “peanuts”? Will my job even exist in a few years? Many feel helpless. You hear the “permanent underclass” conversation a lot, esp from young people. It's hard to focus on doing good work when you think "man, if I joined Anthropic 2yrs ago, I could retire"
3. The mid to late middle managers feel paralyzed.
Many have families and don't feel like they have the energy or network to just "start a company". They don't particularly have any AI skills. They see the writing on the wall: middle management is being hollowed out in many companies.
4. The rich aren’t particularly happy either.
No one is shedding tears for them (and rightfully so). But those who have "made it" experience a profound lack of purpose too. Some have gone from <$150k to >$50M in a few years with no ramp. It flips your life plans upside down. For some, comparison is the thief of joy. For some, they escape to NYC to "live life". For others still, they start companies "just cuz", often to win status points. They never imagined that by age 30, they'd be set. I once asked a post-economic founder friend why they didn't just sell the co and they said "and do what? right now, everyone wants to talk to me. if i sell, I will only have money."
I understand that many reading this scoff at the champagne problems of the valley. Society is warped in this tech bubble. What is often well-off anywhere else in the world is bang average here.
Unlike many other places, tenure, intelligence and hard work can be loosely correlated with outcomes in the Bay. Living through a societally transformative gold rush in that environment can be paralyzing. "Am I in the right place? Should I move? Is there time still left? Am I gonna make it?" It psychologically torments many who have moved here in search of "success".
Ironically, a frequent side effect of this torment is to spin up the very products making everyone rich in hopes that you too can vibecode your path to economic enlightenment.
139
267
4,900
534,723
Desh Raj retweeted

May 16
It is 70 and sunny in New York City, we’re heading to a kite festival, and I haven’t heard the words “agent” or “token” once all morning.
Greatest city in the world.
The vibes in SF feel pretty frenetic right now. The divide in outcomes is the worst I've ever seen.
Over the last 5yrs, a group of ~10k people - employees at Anthropic, OpenAI, xAI, Nvidia, Meta TBD, founders - have hit retirement wealth of well above $20M (back of the envelope AI estimation).
Everyone outside that group feels like they can work their well-paying (but <$500k) job for their whole life and never get there.
Worse yet, layoffs are in full swing. Many software engineers feel like their life's skill is no longer useful. The day to day role of most jobs has changed overnight with AI.
As a result,
1. The corporate ladder looks like the wrong building to climb.
Everyone's trying to align with a new set of career "paths": should I be a founder? Is it too late to join Anthropic / OpenAI? should I get into AI? what company stock will 10x next? People are demanding higher salaries and switching jobs more and more.
2. There’s a deep malaise about work (and its future).
Why even work at all for “peanuts”? Will my job even exist in a few years? Many feel helpless. You hear the “permanent underclass” conversation a lot, esp from young people. It's hard to focus on doing good work when you think "man, if I joined Anthropic 2yrs ago, I could retire"
3. The mid to late middle managers feel paralyzed.
Many have families and don't feel like they have the energy or network to just "start a company". They don't particularly have any AI skills. They see the writing on the wall: middle management is being hollowed out in many companies.
4. The rich aren’t particularly happy either.
No one is shedding tears for them (and rightfully so). But those who have "made it" experience a profound lack of purpose too. Some have gone from <$150k to >$50M in a few years with no ramp. It flips your life plans upside down. For some, comparison is the thief of joy. For some, they escape to NYC to "live life". For others still, they start companies "just cuz", often to win status points. They never imagined that by age 30, they'd be set. I once asked a post-economic founder friend why they didn't just sell the co and they said "and do what? right now, everyone wants to talk to me. if i sell, I will only have money."
I understand that many reading this scoff at the champagne problems of the valley. Society is warped in this tech bubble. What is often well-off anywhere else in the world is bang average here.
Unlike many other places, tenure, intelligence and hard work can be loosely correlated with outcomes in the Bay. Living through a societally transformative gold rush in that environment can be paralyzing. "Am I in the right place? Should I move? Is there time still left? Am I gonna make it?" It psychologically torments many who have moved here in search of "success".
Ironically, a frequent side effect of this torment is to spin up the very products making everyone rich in hopes that you too can vibecode your path to economic enlightenment.
70
121
3,781
384,854
👀 ahh damn, someone should have told me I was Founding Research Scientist at Meta!
May 15

if your email is firstname@company then you're founding, actual role notwithstanding
7
1,592
Desh Raj retweeted
May 15
We've gone even farther:
Nemotron 3 Super is 120B and pretrained on 25T tokens in NVFP4.
Nemotron 3 Ultra is ~500B and also pretrained in NVFP4.
Accelerated computing means we rethink every aspect of the AI stack looking for new opportunities to improve efficiency.
May 15

NVIDIA has done the impossible and nobody's talking about it.
They trained a 12 BILLION parameter LLM in 4-bit precision on 10 trillion tokens.
For years, the AI industry has been stuck.
If you wanted to train a world-class AI, you had to use 16-bit or 8-bit precision. Going lower to 4-bit, was a death sentence for the model. It would become unstable, "hallucinate" its own math, and eventually collapse.
But NVIDIA proved that "impossible" was just a math problem.
They used a new format called NVFP4.
Instead of a standard, rigid structure, NVFP4 uses "micro-scaling." It groups numbers into tiny blocks and applies individual scaling factors to each one. It’s like giving the AI a pair of high-definition glasses for its own data, allowing it to see fine details even with 75% less memory.
The result is a total paradigm shift:
- 2× to 3× faster arithmetic performance.
- 50% reduction in memory usage.
- Near-zero loss in intelligence.
The researchers compared the 4-bit model against a massive 8-bit baseline. The curves are identical. On MMLU, GSM8K, and coding benchmarks, the "tiny" 4-bit version performed within 0.1% of the more expensive model.
This is an economic earthquake.
Training a frontier model used to require tens of thousands of GPUs and months of time. NVIDIA just showed we can get the same results with half the hardware and a fraction of the electricity.

35
88
931
139,045