
Sr. Director of AI model post-training @NVIDIA
Joined February 2010
- Tweets 948
- Following 1,226
- Followers 4,353
- Likes 29,261
79 Photos and videos







Pinned Tweet

Jun 4
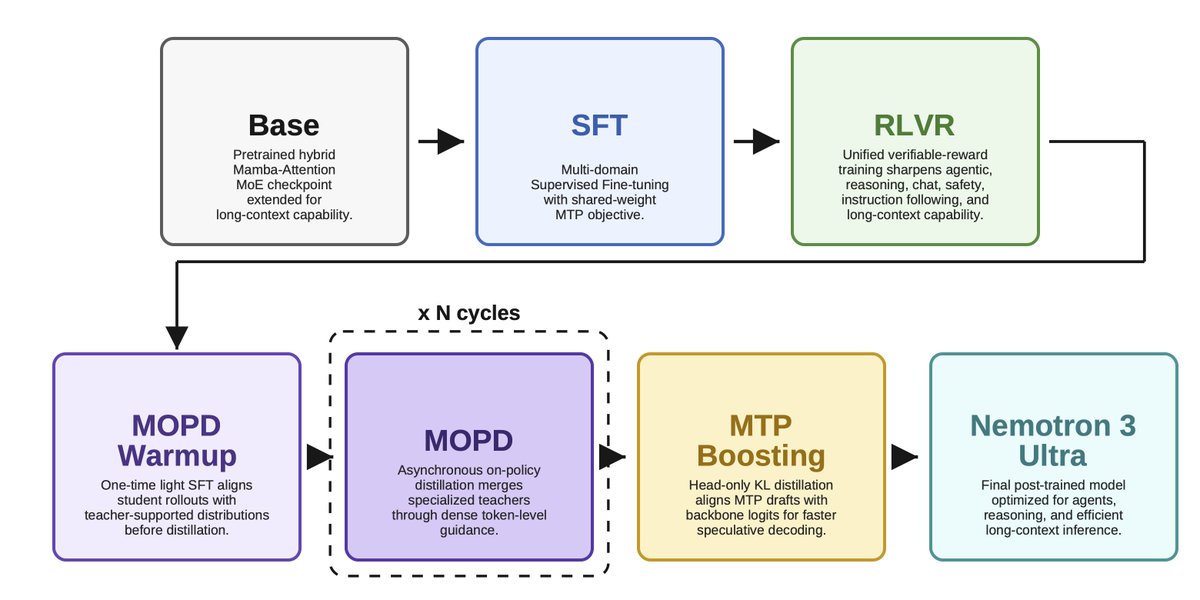
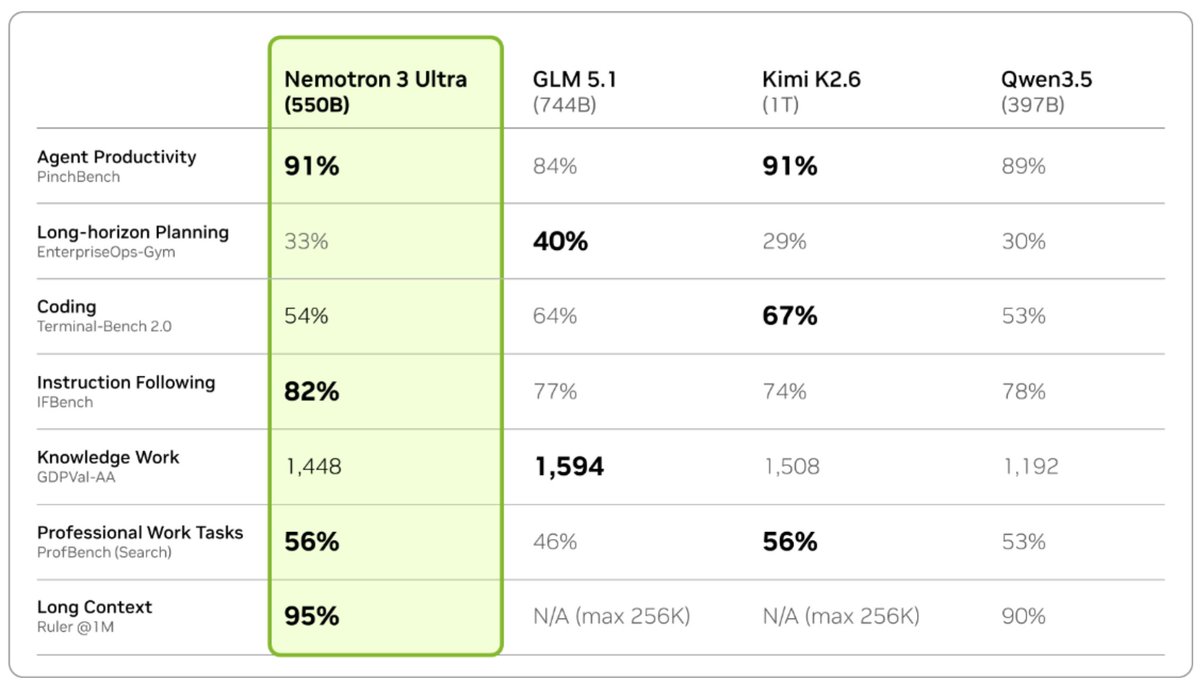
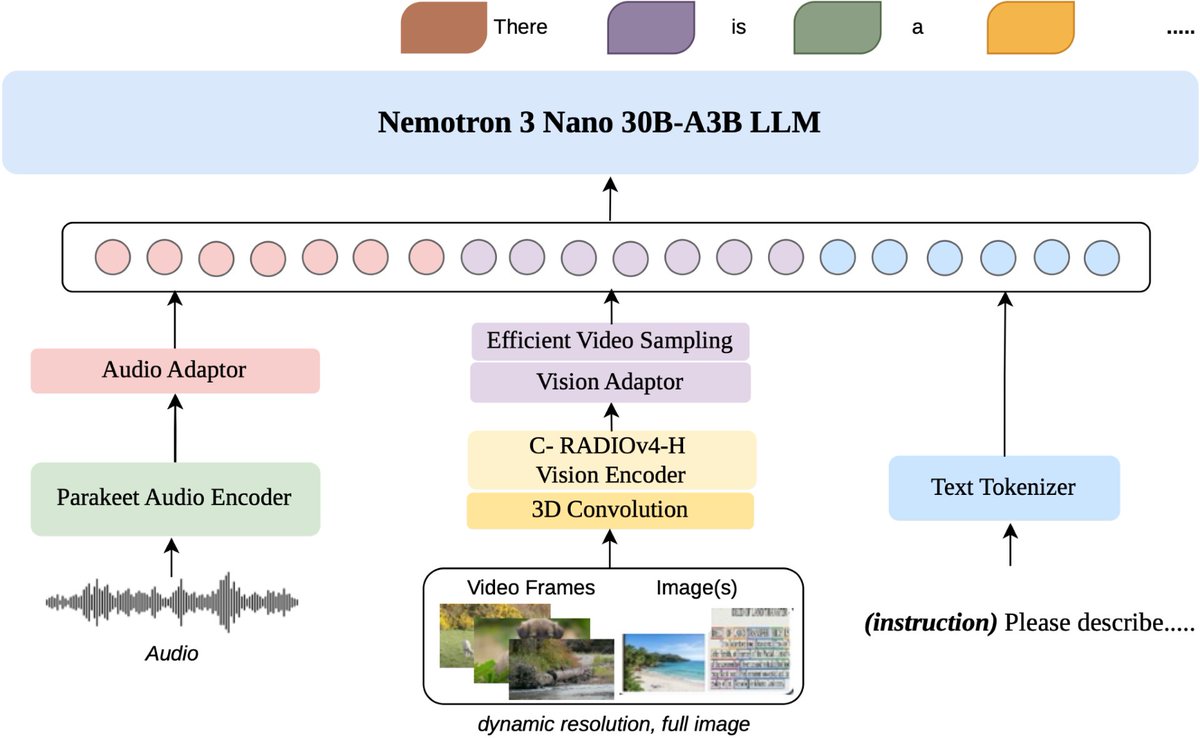
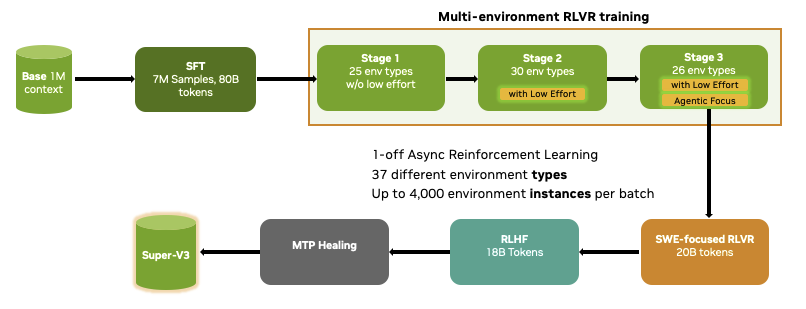
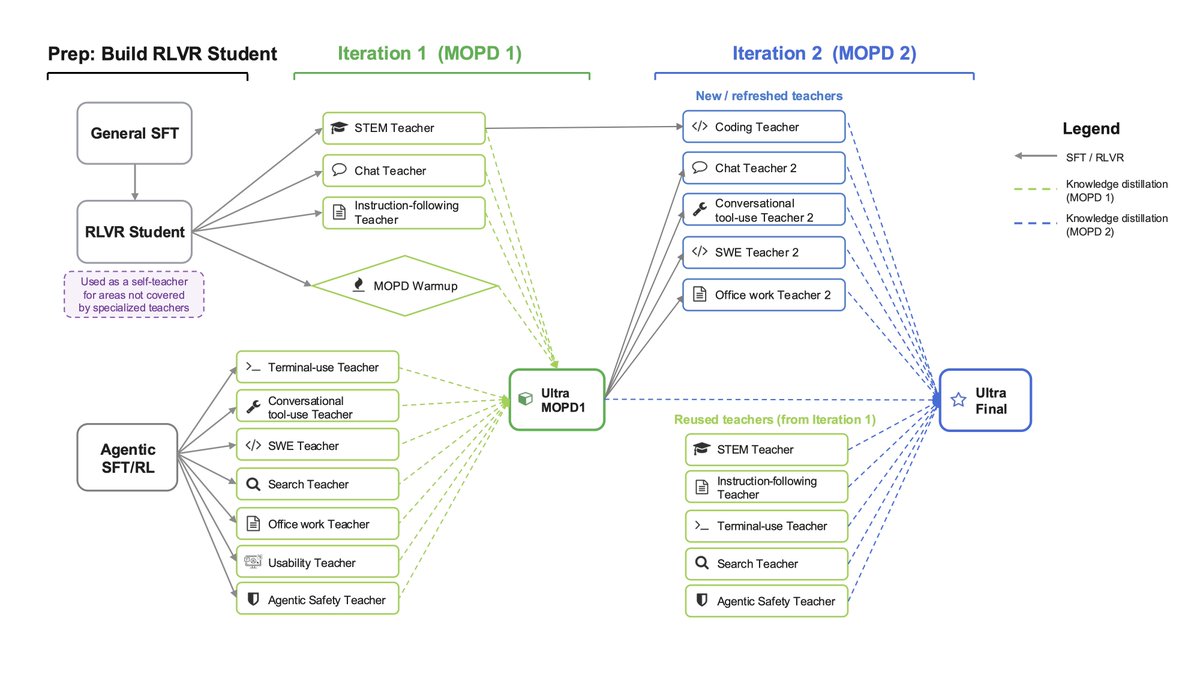
Our post-training pipeline is a substantial redesign from Super.
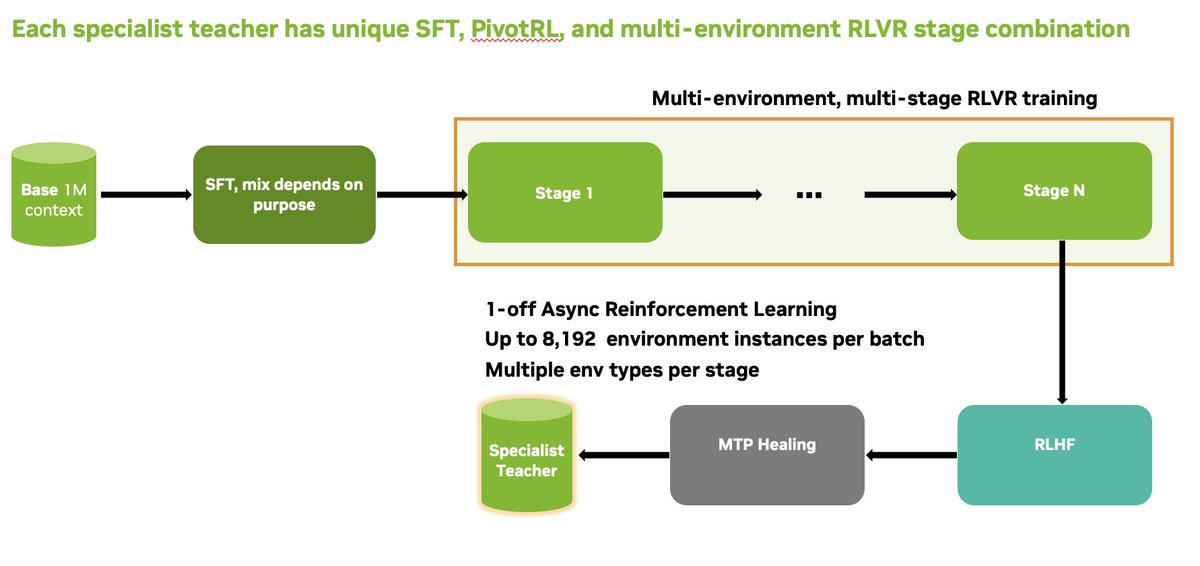
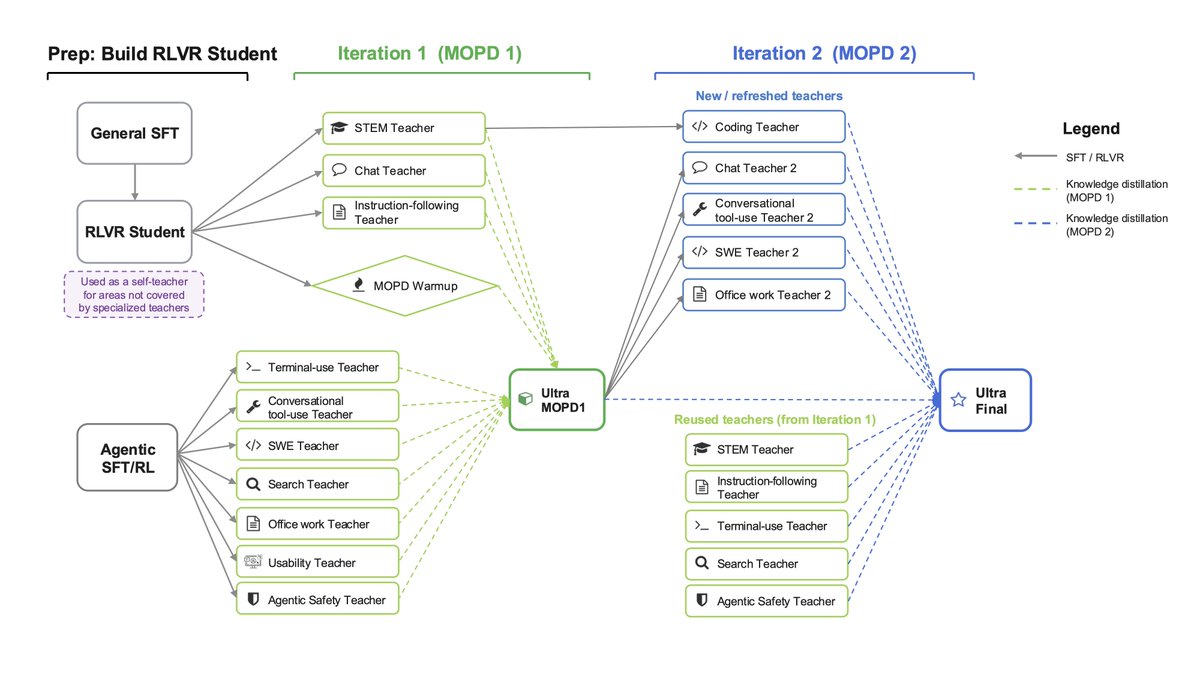
The core idea: don't rely on stacked RL stages alone. We do SFT, multi-environment RLVR across a huge mix of agentic/reasoning/code/safety environments, then Multi-teacher On-Policy Distillation (MOPD). 10 domain-specialized teachers, merged into the student via dense token-level guidance on its own rollouts. See Figures below for overview and tech report for all the details. 2/4
7
38
277
104,706

Oleksii Kuchaiev retweeted

Jun 10
1/ We post-trained @nvidia Nemotron 3 Ultra on @harvey Legal Agent Bench in under 24 hours.
The result: an open model reaching the same band as leading closed models on legal work, at a fraction of the cost.
The correlating story: when a new open model ships, Trajectory can turn it into a specialized agent almost immediately.

9
20
260
72,154
Jun 10
I dunno who is more excited, my daughter or I am ...
10
3
161
11,873
Jun 9
See you all there!
Jun 9

1
3
612
Oleksii Kuchaiev retweeted

Jun 5
Excited to see Nemotron 3 Ultra to be adopted by more AI Natives! Try it out and give us feedback!
Jun 5

Nemotron 3 Ultra is now available for Pro and Max subscribers on Perplexity and Computer.
It's @nvidia's new open model built for long-running agents.
1
17
945
Oleksii Kuchaiev retweeted

NVIDIA Nemotron 3 Ultra is here
We have Day‑0 support for Nemotron 3 Ultra in prime-rl and Lab.
Specialize Nemotron 3 Ultra for your use case.
primeintellect.ai/blog/nemot…
3
30
213
20,782

Jun 4
Very excited to share Nemotron 3 Ultra, 550B total with 55B active MoE hybrid Mamba-Attention model post-trained for agentic applications!
This model delivers frontier-level agentic accuracy while being fast and open with weights, training software, and data available for commercial use. 1/4
13
42
386
26,303
Jun 4
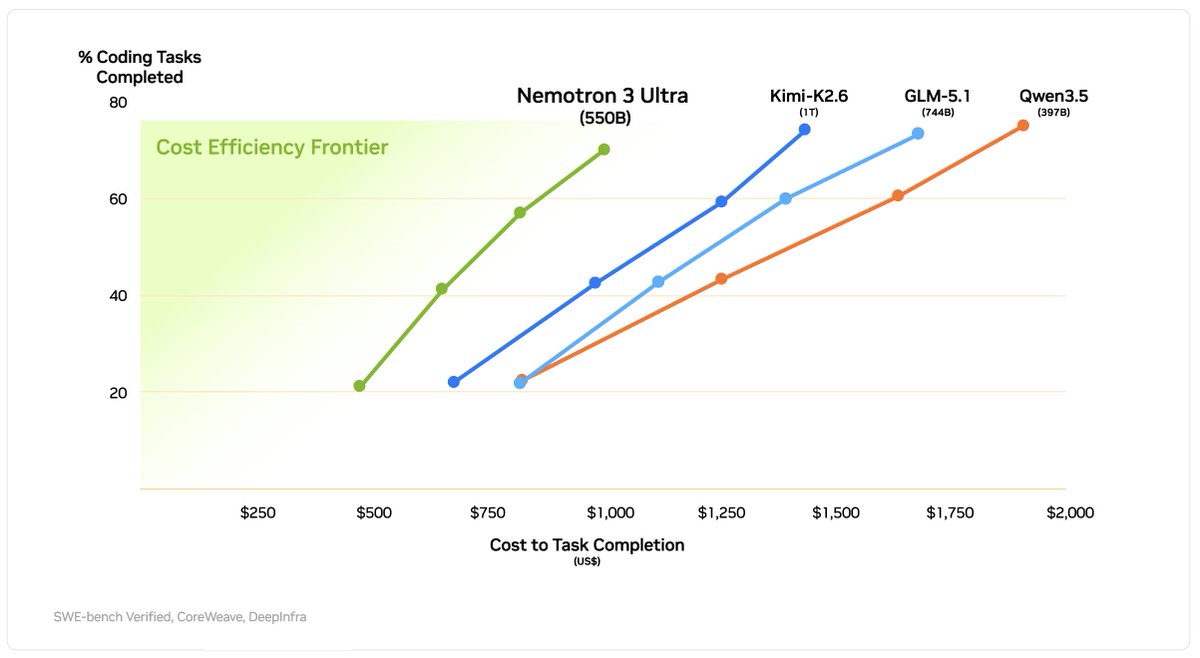
During post-training, a deliberate attention has been paid to token efficiency which together with hybrid architecture and MTP delivers superior inference cost. 3/4
2
1
36
3,526
Jun 4
Of course, it is on @huggingface:
1) Model in BF16 huggingface.co/nvidia/NVIDIA…
2) Model in NVFP4 huggingface.co/nvidia/NVIDIA…
3) Reward model huggingface.co/nvidia/NVIDIA…
4) Base model in BF16 huggingface.co/nvidia/NVIDIA…
5) Tech Report research.nvidia.com/labs/nem…
6) Post-training data: huggingface.co/collections/n…
7) Pre-training data: huggingface.co/collections/n…
Our post-training infra. We are looking forward to your PRs with new environments into NeMo-Gym
* github.com/nvidia-nemo/rl
* NeMo-Gym github.com/NVIDIA-NeMo/Gym 4/4
3
9
47
4,921
Oleksii Kuchaiev retweeted

Jun 2
Like honestly "it's going to take us several weeks to tell you who won the election" is failed state shit and should be much more stigmatized.
615
2,454
29,307
1,127,308
Oleksii Kuchaiev retweeted

Jun 2
Russia unleashed its third massive attack on Kyiv in less than three weeks overnight on.wsj.com/4o0NaRT
29
61
139
130,235
Jun 2
russia is a piece of shit, not a country
Jun 2

🚨 BREAKING: The death toll in Kyiv has risen to 4 with 58 wounded after a massive Russian overnight missile and drone attack, local authorities report.
1
5
492
Jun 1
NVIDIA Cosmos 3 is now available!
Jun 1

Introducing NVIDIA Cosmos 3
We released NVIDIA Cosmos 3 last night.
And today, seeing it take the top spots across 8 open model leaderboards feels surreal. We spent months working towards this moment.
Here’s the breakdown:
The Leaderboard Wins
World Reasoning
🏆 #1 open model on VANTAGE-Bench for vision AI
🏆 #1 overall on Traffic Anomaly Reasoning (TAR)
World Generation
🏆 #1 open model on Artificial Analysis Image-to-Video leaderboard
🏆 #1 open model on Artificial Analysis Text-to-Image leaderboard
🏆 #1 open model on PAI-Bench for physical AI synthetic data generation
🏆 #1 open model on Physics-IQ, which measures accuracy on physical laws
🏆 #1 open model on R-Bench for world generation quality
World Action
🏆 #1 on RoboArena for specialized policy
🏆 #1 on RoboLab for action generation
But the leaderboards are only part of the story. The real story is why we built Cosmos 3 in the first place.
The Problem
Training robots and autonomous systems in the real world is painfully hard.
Robots need to try the same thing numerous times before they succeed reliably. Self-driving cars need rare edge cases that may never happen naturally. Smart machines need to understand physics, motion, contact, failure, and surprise.
And real-world data is slow, expensive, and sometimes dangerous to collect. At some point, the answer cannot just be “collect more data.”
You can’t collect your way out of an infinite physical world. You have to generate it.
That… was the question behind Cosmos: Can one model understand the physical world deeply enough to reason about it, simulate it, and generate actions inside it?
What We Built
Cosmos 3 is the first omni-model for physical AI. It can understand and generate across: language · images · video · audio · action sequences
It is not just a VLM.
Not just a video generator.
Not just a robot policy model.
It is all of them, in one single model.
That matters because physical AI has been fragmented for a long time. Cosmos 3 is our attempt to collapse that fragmentation.
Depending on how you configure the inputs and outputs, the same model can act as a vision-language model, a video/world generator, a world simulator, or a world-action model.
No separate architecture required.
The Architecture
Under the hood, Cosmos 3 uses a dual-tower Mixture-of-Transformers architecture.
One tower is autoregressive for reasoning. It handles next-token prediction for language and discrete understanding.
The other tower is diffusion-based- for generation. It denoises images, video, audio, and action trajectories.
Two towers. Dual-stream joint attention. One shared world representation.
Each modality gets its own tools: visual encoders, video VAEs, audio VAEs, and action projectors that can map different embodiments into a unified action space.
Action is a first-class modality in Cosmos 3.
That’s what makes it more than a video model. It doesn’t just predict and generate what the world might look like. It can connect reasoning and world modeling to physically grounded action.
Why This Matters
One of the most interesting findings from the ablation work is that training action domains together creates positive transfer.
That means adding more embodiments does not just add more use cases. It can actually make the model better.
This is the heart of why omnimodal training matters.
A shared world representation is not just convenient. It can make each individual task stronger. That’s the part that feels like the beginning of something much bigger.
The part I’m most excited about is that Cosmos 3 is fully open.
Developers get the models, scripts, optimization, inference endpoints, post-training recipes, datasets, and benchmarks.
Everything is available under the Linux Foundation’s OpenMDW 1.1 License.
You can use Cosmos 3 out of the box. You can use the VLM, world model, or world-action pieces separately.
You can post-train it for your own domain, embodiment, or accuracy target.
That’s what makes this feel different.
Cosmos 3 is not just a model release. It is the foundation for building intelligence for autonomous machines.
For me, Cosmos 3 feels like a step toward a world where physical AI development becomes much more scalable and accessible - to a new age of developers and agents.
That’s what we built Cosmos 3 for. I cannot wait to see what you build with it.
Download Models on Hugging Face
huggingface.co/collections/n…
Customize Models on GitHub
github.com/NVIDIA/cosmos
Read the Tech Blog to Learn More
developer.nvidia.com/blog/de…

2
29
2,038
Oleksii Kuchaiev retweeted

Jun 1
Nemotron 3 Ultra is now the best open weight model on pinchbench.com/
💚

16
40
380
56,265
Jun 1
We are Ultra excited to release this truly open (weights, pre/post SW stack, data, and all other components) beauty this week! Stay tuned.

9
34
243
18,594

Welcome @NVIDIARTXSpark & a new era of PC 🤝

Welcome to the NVIDIA RTX Spark channel.
A new superchip for the age of personal AI.
Don't worry, your favorite NVIDIA local AI content continues on right here, just with a new headliner.
Let's get started...
25
67
1,522
281,805

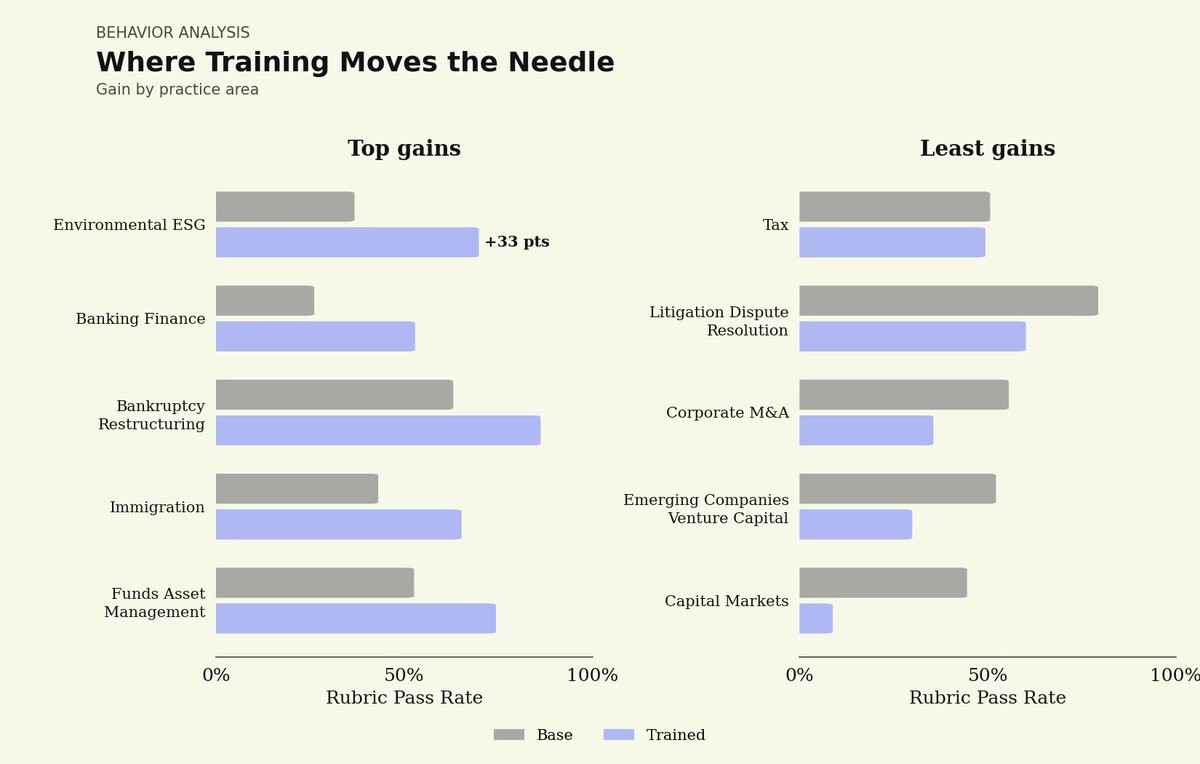
We're partnering with @trajectorylabs to bring sovereign continual learning to legal AI with NVIDIA Nemotron models.
Continual learning allows agents to improve over time from feedback on their work: every redline refines the next draft.
Open-weight models offer full auditability and data sovereignty over legal agents.
Using Trajectory's platform, we post-trained NVIDIA Nemotron 3 Super on our Legal Agent Benchmark (LAB), measuring performance on 1,200 complex end-to-end legal tasks across 24 practice areas.
Initial results show that a post-trained Nemotron 3 Super can match performance of closed-source frontier models.
This is just the start: we'll keep pushing the frontier with the more powerful Nemotron 3 Ultra when available.


May 29

Welcome to Day 2. Yesterday, we showed the broader work we're doing with the pioneers of continual learning.
Today we'd like to deep dive on one: how we post-trained an open model for legal work, in partnership with @Harvey.
We've built a platform where production data is the moat. Every correction, retry, and edit becomes signal you can post-train on, and the models are plug and play: customer's can drop in their model of choice, and improve from there.
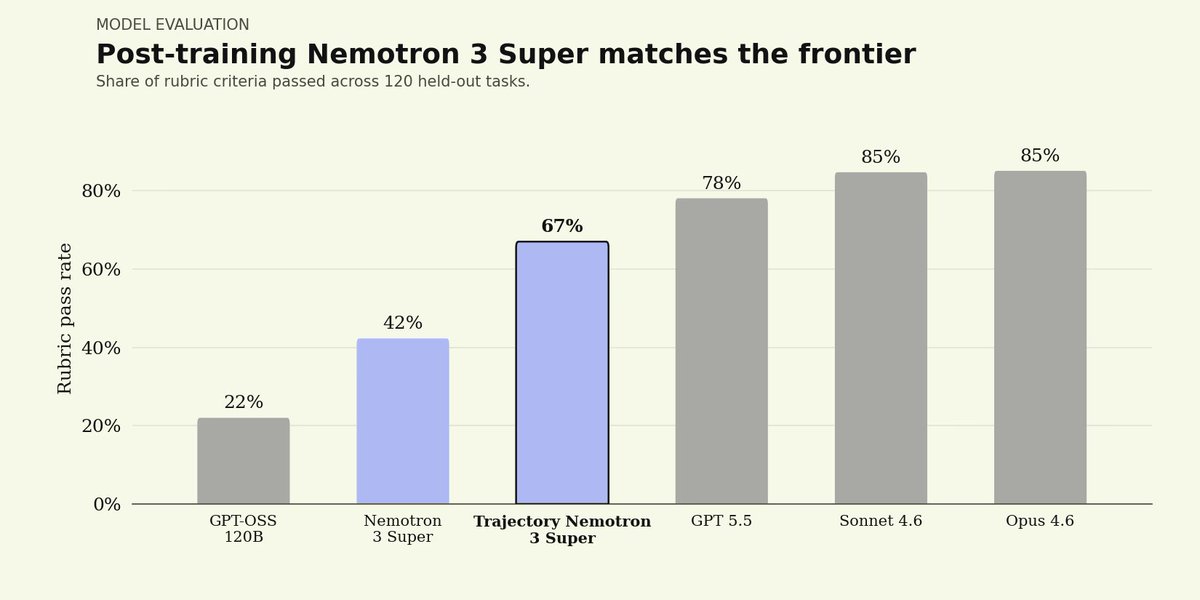
Fields like legal and finance make those demands absolute, with hard security, sovereignty, and provenance requirements. That's why we post-trained @nvidia 's open-weight Nemotron 3 Super, on Harvey's LAB benchmark.
The results, in just hours: post-trained Nemotron 3 Super approaches the closed frontier, matches GPT 5.5, lifts rubric-pass criteria 25%, all while beating the performance-vs-cost frontier. That's the power of our platform.
And this is just a glimpse towards what the future of intelligence will look like: continual learning, where products get smarter every time they're used.
Thanks to @nikogrupen, @gabepereyra, @ItsJulioPereyra, and the whole Harvey team for their collaboration on this. Much more to come soon on continually learning legal agents

8
23
207
59,563