
PhD Candidate @CarnegieMellon | Seed-Prover | Combinatorial Mathematician, AI Researcher. develop new paradigms for mathematical discovery
Joined January 2022
- Tweets 36
- Following 76
- Followers 119
- Likes 76
3 Photos and videos


1/4
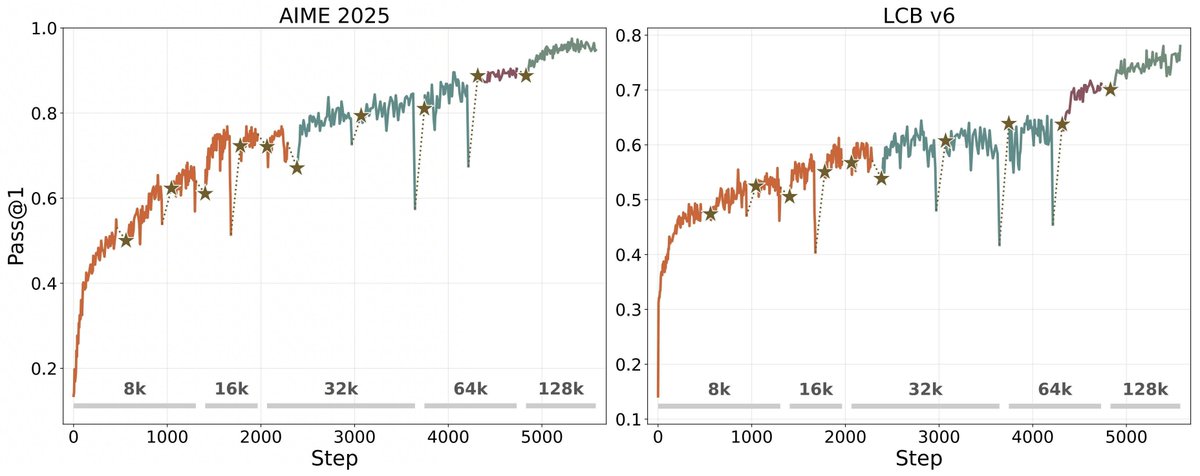
Interesting to see MAI-Thinking-1 arrive at a similar training recipe we use in BFS-Prover-V2. Despite very different scales and domains, the training curves show the exact same pattern. Wrote up some analysis:
zeyu-zheng.github.io/blog/su…

MAI-Thinking-1 is out!
Excited to share what we are building and how climbing from scratch (no distillation) actually works: simple recipes, rigorous science, self-distillation, patience, and great infra.
Check out our tech report has the full story of our RL climbs.
microsoft.ai/wp-content/uplo…

2
4
9
1,708
3/4
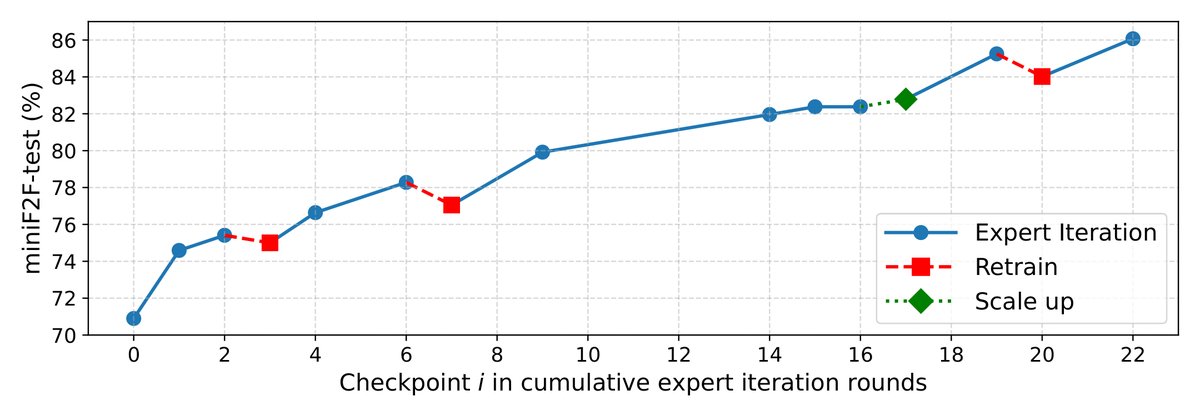
Even without this mismatch, soft resets still help. BFS-Prover-V2 uses expert iteration (no IS ratios), yet the policy still gets stuck. Each reset only slightly hurts performance but significantly restores exploration, climbing past the previous ceiling.
1
1
135
4/4
Both systems also end up with similar data curation principles. Fresh traces from the strongest checkpoints, frontier-difficulty filtering, and prompt diversity over trace volume.
BFS-Prover-V2: arxiv.org/abs/2509.06493
MAI-Thinking-1: microsoft.ai/pdf/mai-thinkin…
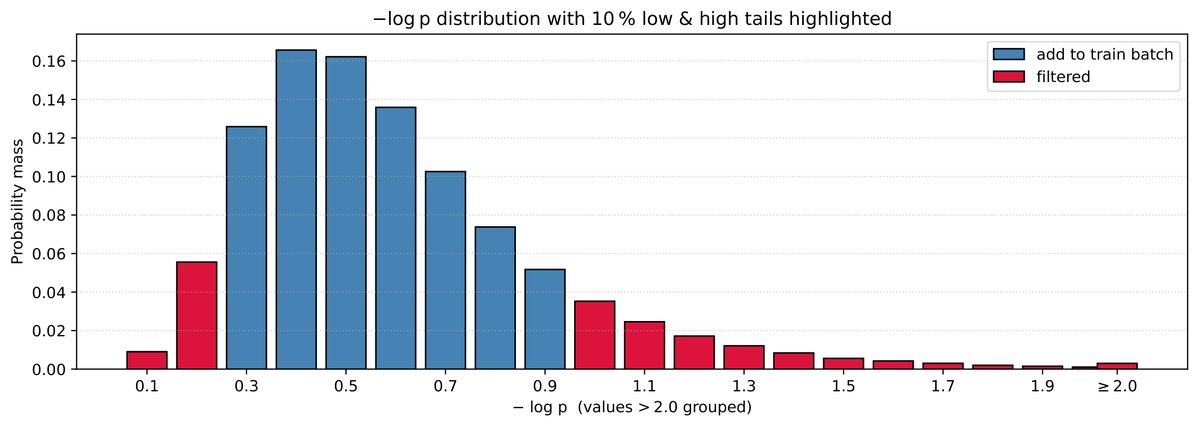
88

May 20
HUGE
Last year when I was at MSRI talking to fellow combinatorialists, this problem still seemed untouchable
Also at the time AI models were still struggling with high school level math problems
The progress over the past year was WILD
May 20

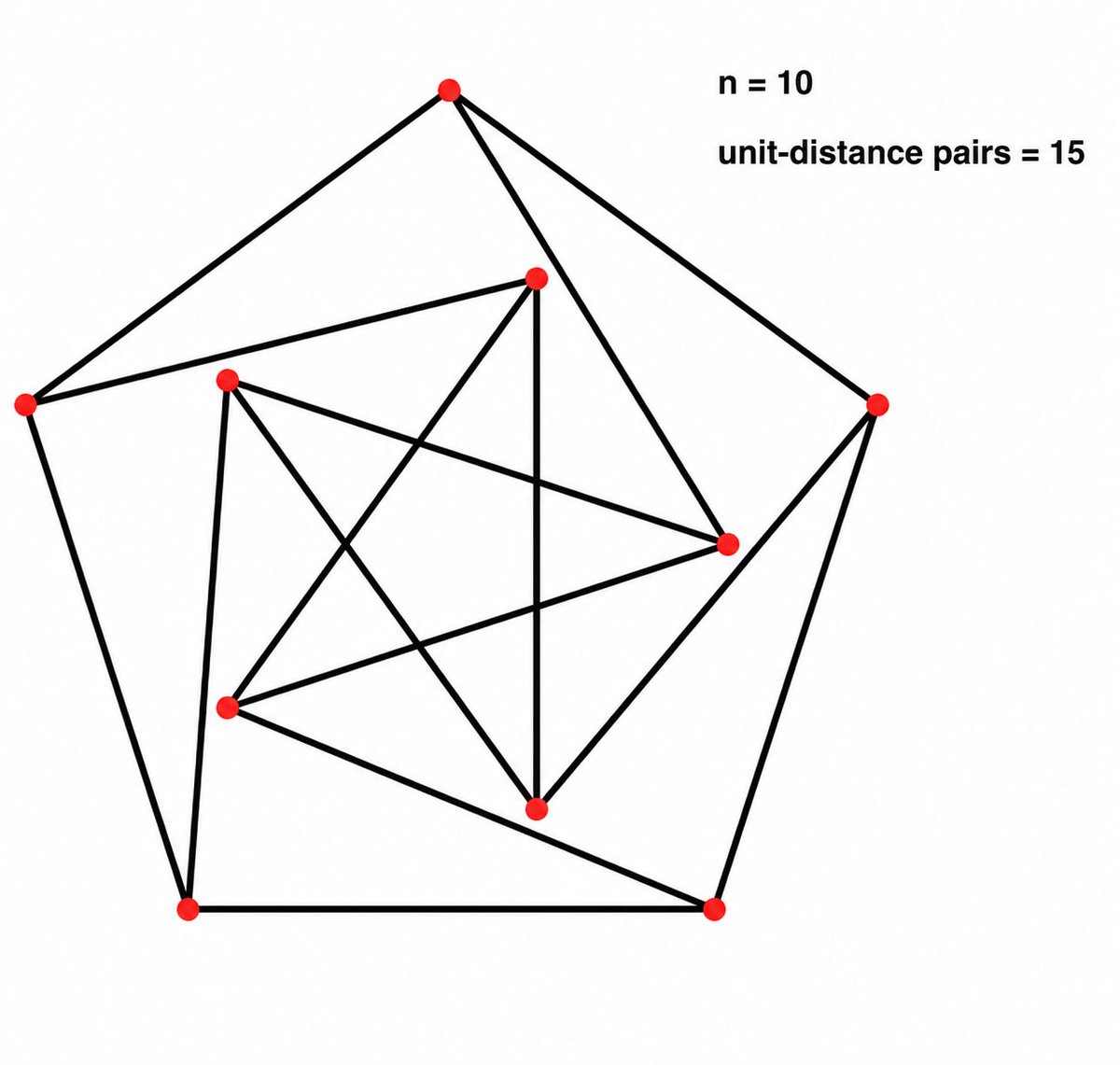
🧵(1/8) An @OpenAI internal reasoning LLM achieved an AI Math milestone: solving an open problem central to its mathematical subfield— in this case, the unit distance problem of discrete geometry.
We came across it in a side quest to truly push our model on the hardest problems.
2
161
Zeyu Zheng retweeted

Jensen Huang, Founder and CEO of @nvidia, will serve as Carnegie Mellon’s 2026 Commencement keynote speaker and will receive an Honorary Doctor of Science and Technology.

41
136
1,553
118,442

Check out our interactive demo 👇
stiglidu.github.io/AdaExplor…
Huge thanks to all collaborators 🙌 @JingmingZhuo @yi_xin_dong @Andre3035858461 @sunweiwei12 @regunivers Manupa Karunaratne, Ivan Fox @Tim_Dettmers @tqchenml Yiming Yang @wellecks
We would love to hear your feedback!
1
4
334
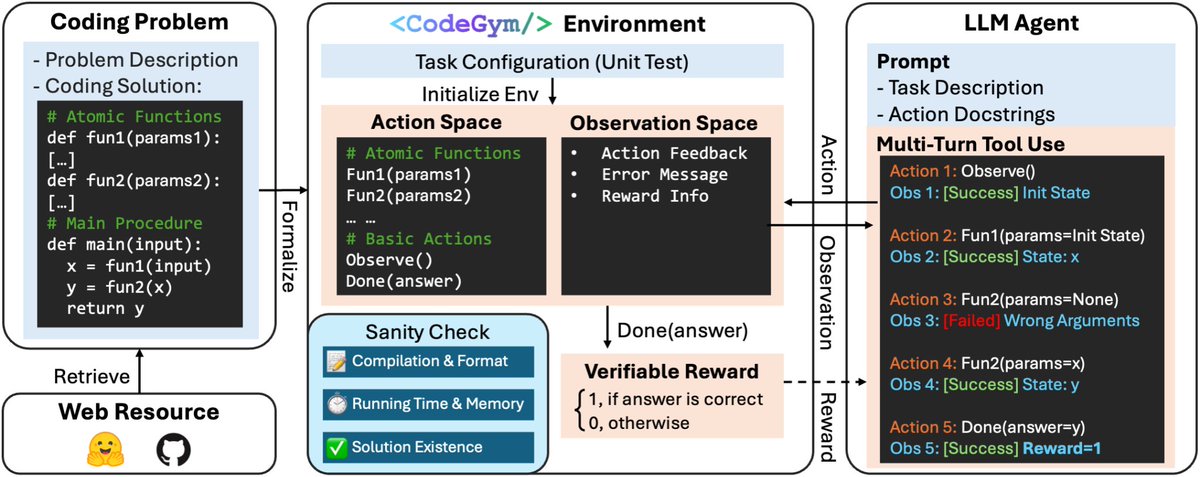
Check out our #ICLR2026 poster, “Generalizable End-to-End Tool-Use RL with Synthetic CodeGym”!
We developed CodeGym, an automated pipeline that converts coding problems into multi-turn tool-use environments for agent RL training. We end up with 13K environments and 80K task configurations. Training on CodeGym can significantly improve LLM tool use and multi-turn interaction capabilities on OOD tasks (e.g., Tau-Bench, ALFWorld).
Unfortunately, I can't make it to ICLR in person, so sharing our poster here!
Paper: arxiv.org/abs/2509.17325
Dataset: huggingface.co/datasets/Vani…


How can we boost LLM agents’ generalizability to OOD tasks and environments?
Check out CodeGym, our new project for synthesizing environments for LLM agent RL training. CodeGym is a synthetic environment generation framework for reinforcement learning on multi-turn tool-use tasks. It automatically converts static coding problems into interactive and verifiable RL training environments.
Training in CodeGym leads to strong OOD generalization — for example, a Qwen2.5-32B-Instruct model achieved an 8.7-point absolute accuracy gain on τ-Bench!
We’ve just released the paper, synthesis pipeline, and dataset:
📄 Paper: arxiv.org/abs/2509.17325
💻 Project: github.com/StigLidu/CodeGym
📊 Dataset: huggingface.co/datasets/Vani…
📷
More details in the thread👇
4
12
895
Zeyu Zheng retweeted

Apr 16
Erdős was the most prolific mathematician in history, after Euler,
But Erdős was by far the most prolific *conjecturer* in history, posing many problems big and small.
Combinatorialist Joel Spencer said that Erdős was able generate these conjectures based on deeper meta-theories in his mind.
So certainly some of these problems are more famous than others, but it may turn out that if enough of them are solved, it may lead to a more unified theory.
Apr 16

Some dismiss Erdős problems as trivialities - this couldn't be further from the truth! While many are amusing novelties, some of them are the most central problems in number theory and combinatorics.
A blog post with, in my view, the 10 most important:
erdosproblems.com/forum/thre…
7
15
205
18,153
Zeyu Zheng retweeted

Apr 16
Some dismiss Erdős problems as trivialities - this couldn't be further from the truth! While many are amusing novelties, some of them are the most central problems in number theory and combinatorics.
A blog post with, in my view, the 10 most important:
erdosproblems.com/forum/thre…
9
38
203
36,672
Zeyu Zheng retweeted
Apr 15
In my doctorate, I proved the Erdős Primitive Set Conjecture, showing that the primes themselves are maximal among all primitive sets.
This problem will always be in my heart: I worked on it for 4 years (even when my mentors recommended against it!) and loved every minute of it.
[Primitive sets are a vast generalization of the prime numbers: A set S is called primitive if no number in S divides another.]
Now Erdős#1196 is an asymptotic version of Erdős' conjecture, for primitive sets of "large" numbers.
It was posed in 1966 by the Hungarian legends Paul Erdős, András Sárközy, and Endre Szemerédi.
I'd been working on it for many years, and consulted/badgered many experts about it, including my mentors Carl Pomerance and James Maynard.
The the proof produced by GPT5.4 Pro was quite surprising, since it rejected the "gambit" that was implicit in all works on the subject since Erdős' original 1935 paper. The idea to pass from analysis to probability was so natural & tempting from a human-conceptual point of view, that it obscured a technical possibility to retain (efficient, yet counter-intuitve) analytic terminology throughout, by use of the von Mangoldt function \Lambda(n).
The closest analogy I would give would be that the main openings in chess were well-studied, but AI discovers a new opening line that had been overlooked based on human aesthetics and convention.
In fact, the von Mangoldt function itself is celebrated for it's connection to primes and the Riemann zeta function--but its piecewise definition appears to be odd and unmotivated to students seeing it for the first time. By the same token, in Erdős#1196, the von Mangoldt weights seem odd and unmotivated but turn out to cleverly encode a fundamental identity \sum_{q|n}\Lambda(q) = \log n, which is equivalent to unique factorization of n into primes. This is the exact trick that breaks the analytic issues arising in the "usual opening".
Moreover, Terry Tao has long suspected that the applications of probability to number theory are unnecessarily complicated and this "trick" might actually clarify the general theory, which would have a broader impact than solving a single conjecture.
Apr 14

This is one of the coolest such examples! See comments from Lichtman below, who proved the related primitive set conjecture arxiv.org/abs/2202.02384
55
380
2,918
988,911
Zeyu Zheng retweeted

Apr 10
🚀 New survey dropped! "Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering"
LLM agents are evolving — not by changing weights, but by building better infrastructure around them. 🧵👇
1/4

1
2
4
201

Zeyu Zheng retweeted

We’ve just released another paper solving five further Erdős problems with an internal model at OpenAI: arxiv.org/abs/2604.06609.
Several of the proofs were especially enjoyable to digest while writing the paper. My personal favorite was the solution to Erdős Problem 1091. The question asks: if a graph G has chromatic number 4, while every small subgraph has chromatic number at most 3, must it contain an odd cycle with many diagonals? The internal model gives a very enlightening counterexample to this conjecture, and the proof was a pleasure to understand.
For those so inclined, a really fun exercise is to try to reconstruct the proof from Figure 5 of the paper, which was of course produced by Codex.

20
150
900
205,396
Apr 8
Finally 🥑
Apr 8

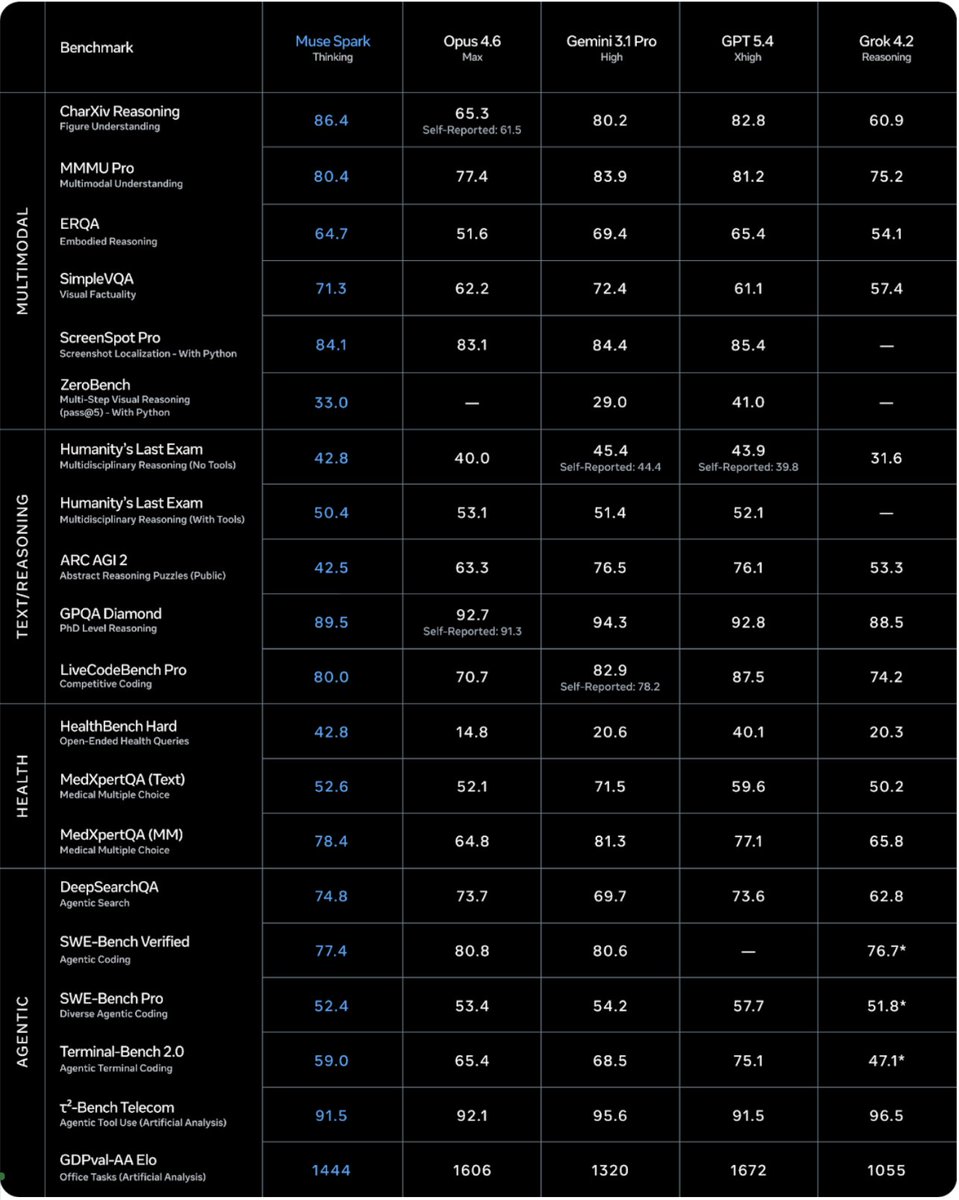
Excited to share what we’ve been building at Meta Superintelligence Labs! We just released Muse Spark, our first AI model. It's a natively multimodal reasoning model and the first step on our path to personal superintelligence. We've overhauled our entire stack to support scaling, and this is just the beginning.
ai.meta.com/blog/introducing…
84
Zeyu Zheng retweeted

A new milestone in automatic formalization:
We translated an entire graduate math textbook into Lean using 30K LLM agents.
Open-source, large-scale multi-agent inference that actually works
> Blueprint Lean: faabian.github.io/algebraic-…
> Codebase preprint: github.com/facebookresearch/…
1/7

23
139
706
90,834
Zeyu Zheng retweeted

What a difference a year makes.
1 Apr 2025

It's finally happened: after several unsuccessful attempts, I found a prompt that got Grok to solve a maths problem (the well-known Dubnovy Blazen problem in graph theory) I've been working on for over a year. How long till it's better than human mathematicians across the board?
9
20
308
50,941
Zeyu Zheng retweeted

Mar 4
How are mathematicians facing the wave of rapidly advancing AI-for-math capabilities?
Jeremy Avigad (CMU prof and co-author on the original 2015 system description paper for Lean) just posted a paper with his thoughts in the wake of the Math, Inc. announcement on sphere packing.
andrew.cmu.edu/user/avigad/P…
There are a lot of interesting passages in here, including a bit of the back story of the Math, Inc. bomb drop and how it was initially received by the humans working on the formalization project.
But, as for how mathematics proceeds, here's the key last passage:
"We need to remember our strengths: mathematicians are problem solvers and theory builders extraordinaire. Rather than fight the use of AI in mathematics, we should own it. It is not enough to keep up with current events and design benchmarks for AI researchers; we need to play an active role in deploying the technology and molding it to our purposes. We also need to learn how to raise our students with the wisdom to use the new technologies appropriately, and we need to be careful that we still manage to impart core mathematical intuitions and understanding. Figuring out how to use AI effectively to achieve our mathematical goals won’t be easy, but mathematicians have always embraced challenges—indeed, the harder, the better. If we face AI head-on and stay true to our values, mathematics will thrive. We just need to show up and get to work."
The next few years should be a golden era for mathematics. For those of us working on the frontier, I hope we do well by our mathematician colleagues.

22
191
850
108,669
Zeyu Zheng retweeted
We just posted a paper solving Erdos #846, which was solved by an internal model at OpenAI (cdn.openai.com/infinite-sets…). While the problem can also be derived from an earlier paper in the literature, the proof by the internal model was one of the first instances where I smiled reading the proof.
8
37
312
75,944
Zeyu Zheng retweeted

Feb 25
Does an AI agent really need to "think hard" for every single step? 🤖🧠⚡
Introducing CogRouter, a framework grounded in ACT-R theory that trains agents to dynamically adapt cognitive depth across four hierarchical levels, from instinctive responses to strategic planning.
🧠 We identify a critical inefficiency in current agents where they either think too little (reflexive) or think too much (uniform deep reasoning). Real-world tasks demand step-wise heterogeneity:
1️⃣ Routine steps require instinctive responses;
2️⃣ Complex steps require strategic reasoning;
3⃣ Fixed patterns waste tokens or fail on hard tasks.
🎓 We propose a two-stage training strategy to enable dynamic cognitive adaptation:
1️⃣ Cognition-aware SFT (CogSFT) instills stable level-specific patterns;
2️⃣ Cognition-aware Policy Optimization (CoPO) enables step-level credit assignment via confidence-aware advantage reweighting.
📊 Experiments on ALFWorld and ScienceWorld show CogRouter achieves state-of-the-art performance with superior efficiency:
🏆 82.3% success rate with Qwen2.5-7B;
🔥 Outperforms GPT-4o ( 40.3%) and OpenAI-o3 ( 18.3%);
⚡ Uses 62% fewer tokens than GRPO by skipping unnecessary reasoning.
🧑💻 Code: github.com/rhyang2021/CogRou…
📷 Paper: arxiv.org/abs/2602.12662

10
39
9,368